
改进的YOLOv3算法在视频分析中的应用
2022-02-15 02:48康金龙谢祎霖
信息记录材料 2022年12期
康金龙 ,刘 涛 ,谢祎霖 ,许 涛 ,宫 胜
(1 西北大学经济管理学院 陕西 西安 710000)
(2 西北大学网络与数据中心 陕西 西安 710000)
(3 西北大学后勤集团 陕西 西安 710000)
0 引言
多目标检测是计算机视觉领域亟待解决的基本任务之一,也是视频监控技术的基本任务[1-2]。由于视频中的物体有不同的姿态,经常出现被阻挡的情况,所以它们的运动是不规则的[3]。同时,考虑到视频监控的分辨率、天气、光线等条件和场景的多样性,目标检测算法的结果将直接影响后续跟踪、分类、动作识别和行为描述的效果[4]。多目标检测仍然是一个非常具有挑战性的任务,有很大的潜力和改进空间。
1 多目标检测的基本思想
Fast-rcnn通过建立多任务模型,利用神经网络对操作进行分类,实现了实时端到端联合训练[5]。同时,Fast-rcnn实现了网络终端同步训练,提高了准确率,但分类步骤的性能没有明显提高。Faster-rcnn在Fastrcnn的基础上增加了区域建议网络(region proposal network,RPN),提取候选框并合并到深度神经网络中[6]。通过交替训练,建立了统一的深度神经网络框架,既减少了重复计算,还大大提高了运行速度。YOLO的思想是用单个神经网络直接训练整个输入图像作为输入,从而更快速地区分背景区域和目标,以更简单、更快的方式对目标对象进行实时监控[7]。该方法将输入图像划分为S×S大小的网格,每个网格单元预测边界框和这些边界框的可靠性。YOLO本质上解决了目标检测的实时性问题,真正实现了“端到端”的CNN结构。YOLOv3的思想是通过特征提取网络从输入图像中提取一定大小的特征映射,例如13×13[7]。然后将输入的图像划分为13×13格。如果ground truth中一个对象的中心坐标落在网格单元格中,网格单元格将预测该对象,因为每个网格单元格预测固定数量的边界框。在这些边界框中,只有那些具有最大限度和ground truth的IOU被用来预测这些对象。可以看出,预测的输出特征图具有提取特征的两个维度。其中一个维度是平面,例如13×13,还有一个维度是深度,例如B×(5+C),其中B表示每个单元格预测边界框的数量,C表示边界框对应的类别数。
2 改进的YOLOv3算法YOLOv3-ANV
现在流行的图像检测算法和视频检测算法有很多,它们都有各自的特点和优势,适用于不同的情况。在YOLOv3和Faster-RCNN模型和人口密度估计下,对一般场景的人体检测进行计数统计实验。研究人员发现,当人数较少时,YOLOv3模型更准确。人群密度估计是在大量人群中必不可少的检测方法[8-9]。人群计数的方法可以分为三种。第一种是行人检测:这种方法比较直接,在人群较稀疏的场景中,通过检测视频中的每一个行人,进而得到人群计数的结果,一般是用基于外观和运动特征的提升方法(boosting),贝叶斯模型为基础的分割,或集成的自顶向下和自底向上的处理,但是这种方法在人群拥挤情况下不大奏效。第二种是视觉特征轨迹聚类:对于视频监控,一般用跟踪和聚类的方法,通过轨迹聚类得到的数目来估计人数。第三种是基于特征的回归:建立图像特征和图像人数的回归模型,通过测量图像特征从而估计场景中的人数。在人口密度较高的情况下,人群密度估计算法常被认为是计算人口数量的有效方法。该算法采用基于像素的种群密度估计算法,通过图像和背景相减得到运动前景,然后根据前景像素面积和前景边缘进行线性回归或分类[10]。在这些方法中,从图像中提取前景的效果直接影响算法的性能。因为在视频中,人相对于背景总是在移动,因此可以利用一种视频帧差法获取自适应背景。该方法利用时间轴上每个像素的变化信息,生成不含目标种群的背景图像。基于像素的处理方法如图1所示。

图1 基于像素的处理方法示意图
在现实生活中,异常的视频片段可以保存为片段,用于回放,验证当时的情况。研究人员的目标是提取一个超出视频段中异常数量阈值范围的视频段。为了实现这一目标,研究人员需要得到帧序列图片中的确切帧数。首先,运行IO流读取采集到的视频数据,IO流将检测视频的帧率并从视频中提取帧序列,将这些帧和帧率的结果保存在本地。然后使用训练后的分类器(在已标记的训练数据集中)对图像数据(来自视频序列帧)进行识别,最终得到一系列标记区域(bound-box regression识别为人体区域)。通过统计标记区域的数量,研究人员可以得到对应图像中的人数,并根据设置的“异常人数阈值”来判断是否超过阈值,这样就可以从原始视频中截获异常人数段的视频。最后,根据检测抖动算法,对识别结果进行优化。研究人员将原始图像帧的识别结果作为标签组合放到图像中,然后使用FFMPEG程序(FFMPEG是一个开源的计算机程序,可以用来记录、转换数字音频、视频,并将其转换为流)来重新生成视频。生成的视频对应一系列的标签帧的数量。同时,研究人员将生成的图像中包含人数的信息上传到远程系统,供显示系统进行分析和显示。
即使YOLOv3对小物体(包括人)的检测效果很好,但在单帧图像中也会有一定的漏检。YOLOv3对大目标检测不好,并且当待检测的人数较多时,YOLOv3的检测效果不理想。针对这种情况,为了在模型下获得更好的结果,研究人员设置一个最大阈值N(在实验中,N的值为25,在20人左右的情况下,模型的准确率可以达到90%以上)。一旦使用模型对一帧进行检测的结果大于阈值N,将采用人群密度估计算法进行检测,从而使检测效果更加准确。为此,提出了YOLOv3-ANV算法,该算法的框架图如图2所示。
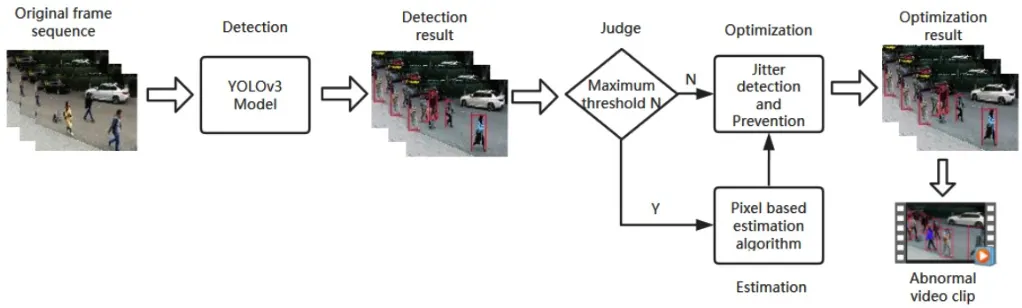
图2 YOLOv3-ANV算法框架示意图
由于模型本身具有一定的泛化能力,用训练数据训练的YOLOv3模型可以检测到各种场景中的种群,但由于帧之间的变化,模型的检测效果会变得不稳定,被称之为不稳定变化:检测抖动。因为视频中出现的跳帧情况而导致生成的异常视频片段不连续,因此检测抖动会降低连续变化图片的检测精度(参考DME计算指标)。
假设研究人员找到一个与检测结果前后不同的帧序列号,将其识别为x,并自定义一个纠错区域(长度)的范围,在实验中,长度占视频帧率的1/3。可由式(1)表示:

其中N为视频帧率。并提取前后长度范围的检测结果进行统计。可由式(2)表示:
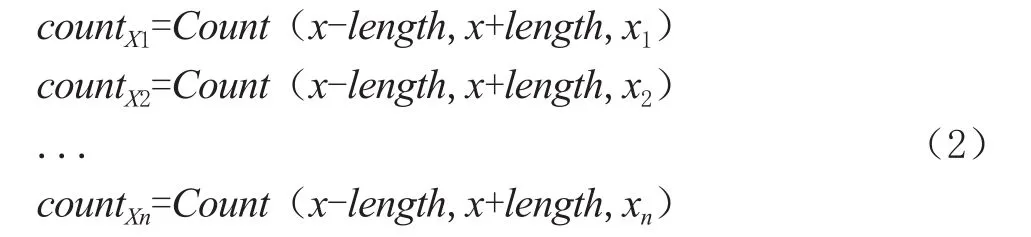
其中Count()表示计数的函数,x-length,x+length表示计数的范围。x1,x2,...,xn表示该范围内的各种检测结果。取最大值r,然后用r替换x的检测结果值,用来稳定检测结果序列。同时,利用稳定的帧序列也可以获得阈值外范围内稳定的异常视频片段。可由式(3)表示:

3 实验部分
3.1 实验数据集
本文采用万方体育竞赛数据集作为YOLOv3-ANV的主要测试数据集。它由7 h 16 min的体育视频组成。研究人员使用Microsoft COCO训练集来训练YOLOv3-ANV。COCO的全称是common objects in context,是微软团队提供的一个可以用来进行图像识别的数据集,COCO是当前目标识别,目标检测领域最重要,最权威的一个标杆数据集,在COCO数据集上可以做多种任务。2014版本的COCO数据集包括82 783个训练图像、40 504个验证图像以及40 775个测试图像,其中有270 k是分割出来的人,以及有886 k是分割出来的物体。万方体育竞赛数据集包括:
(1)2016年美国大学生橄榄球联盟:3 h 28 min 24 s的橄榄球比赛。
(2)2017年美国曲棍球联赛:1 h 40 min 41 s的曲棍球比赛。
(3)2017年 NCAA篮球锦标赛:比赛时长1 h 54 min 57 s。
(4)赛马:4 min 10 s的赛马比赛。
3.2 实验环境与实验结果
研究人员在实验室用的GPU为NVIDIA GeForce 1 080 Ti,显存为8 GB;操作系统为Ubuntu 16.04 LTS。研究人员使用Python3.6版本;配置了NVIDIA CUDA 10.0和Cudnn7.4.1进行加速GPU运算;并且安装了Tensorflow1.13.2和Numpy1.17.4等一系列第三方数据库来支持代码的运行。研究人员用aria2下载COCO数据集,采取weights参数传递模式,基于预训练模型对COCO 2014数据集进行训练,使用多尺度训练完整的图像,每经过10次迭代就随机从320至608这10个输入大小(以32为间隔)中选择一个新的数作为网络的输入进行训练。训练采用动量因子为0.9的梯度下降法,共进行100个周期训练。网络设置不同大小的学习率,每25个周期分别设置学习率为0.001、0.000 1、0.000 01。研究人员对万方体育竞赛数据集进行了测试。使用faster-rcnn、YOLOv3和提出的模型(YOLOv3-ANV)对所有万方体育比赛数据集进行测试。其中,检测到的美国曲棍球联赛的结果如图3所示。
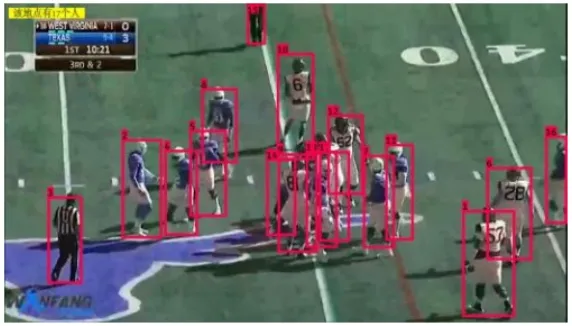
图3 检测美国曲棍球联赛的结果
为了更好地反映检测平均精度,使用如下公式(4)进行计算:

其中mL为检测到的具有相同物体数的帧数,m2为具有相同物体数的真实帧数,p1、p2为检测到的物体数和真实物体数,APd为检测平均精度。结果如表1所示。根据表格可以得出,检测精度得到了提高。
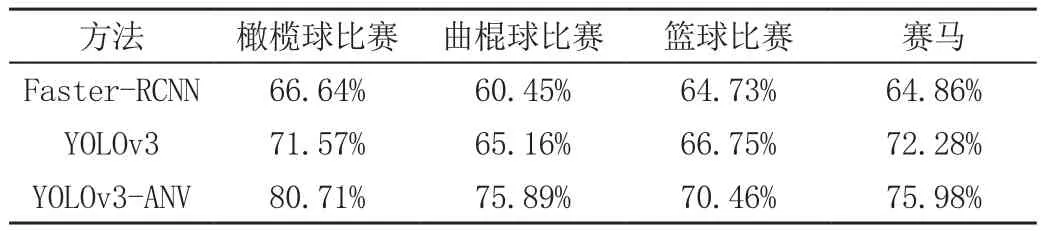
表1 不同方法对各个运动项目的计算精度
4 结语
本文提出了YOLOv3-ANV算法,该算法具有多尺度估计机制和检测抖动预防机制,在多目标检测中具有良好的应用前景。如体育比赛和公共区域的多人检测。研究人员进行了相关实验,实验结果表明,YOLOv3-ANV在体育竞赛数据集的多人检测中具有较好的检测精度。高分辨率相机记录的特定图像对任务更有帮助。最后,本研究还可以用于公安领域、交通安全领域、智慧化工领域、智慧加油站领域等。可降低资源与人员配置,对多目标进行识别,并进行分析判断及时对异常行为做出反应,有效地对群体行为进行相应分析,从而保障监控区域的安全,减少不良事件发生,降低管理成本,具有一定的可拓展性。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
人民调解(2019年2期)2019-03-15
红土地(2017年2期)2017-06-22
中国卫生(2014年5期)2014-11-10
自然资源遥感(2014年3期)2014-02-27
中国会计年鉴(2014年00期)2014-02-03
意林(2011年10期)2011-05-14
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
