
利用序列模型实现基于影片简介的相似影片推荐
2022-02-15 08:12王雅懿
现代电影技术 2022年1期
王雅懿
(中央宣传部电影数字节目管理中心,北京 100866)
1 引言
农村电影放映工程作为文化惠民工程的重要组成部分,承担着弘扬主旋律、传播正能量的重要使命。当前,农村电影市场年供应影片已达4000 余部,需要持续加强技术服务能力以便用户从海量影片中快速挑选出想要订购的影片。在以前,选片订购的用户主要是农村院线,为了打通选片订片的最后一公里,中央宣传部电影数字节目管理中心(以下简称“电影数字中心”)着力推动订购用户下沉,让放映员也能直接参与到选片订购工作中。对于农村院线,农村公益电影业务运营与监管服务平台已积累了大量的用户行为数据,可使用协同过滤算法为用户推荐影片;对于放映员,在首次选片时由于缺少行为数据,无法用协同过滤算法对用户的喜好进行预测,可使用相似性推荐算法为用户推荐影片。相似性推荐算法适用于缺少用户行为数据的场景,该算法通过对影片本身的特性进行分析,找出类似影片推荐给用户。
如何将影片信息转化为特征向量,如何计算影片相似性是相似性推荐算法要集中解决的关键问题。传统的影片信息转化方式是将导演、主演、影片类型等信息直接用数字表示,从而实现将影片信息向量化。文章利用影片简介作为素材,根据序列模型编码部分能够对数据特征进行提取的特点,将影片简介作为样本输入到训练好的文本摘要序列模型中,从而得到影片简介的特征向量。影片的相似性计算选用了欧式距离和皮尔逊相关系数作为计算方法,既考量了向量间的距离又兼顾了向量间的角度,实现对影片特征向量的综合评估。
2 序列模型
2.1 序列模型的架构
序列模型是一种自然语言模型,它利用神经网络技术实现将任意长度的词序列映射成另一个任意长度的词序列,常被应用于机器翻译领域。序列模型的思想非常像加密和解密的过程,模型通常由编码部分(Encoder)和解码部分(Decoder)两部分组成,编码部分负责将输入的词序列加密形成一个特征向量,解码部分负责将特征向量解密成另一组词序列。
2.2 循环神经网络
编码部分和解码部分都是由循环神经网络(RNN)结构组成。循环神经网络是一种专门用于解决序列问题的特殊神经网络。自然语言语句的前后词语是有关联的,但是传统神经无法表示这种关联,在循环神经网络中当前词语的预测与前面词语是有关系的,循环神经网络会对前面的语句信息进行记忆并应用于当前语句的预测计算中。

图1 传统神经网络词序列预测
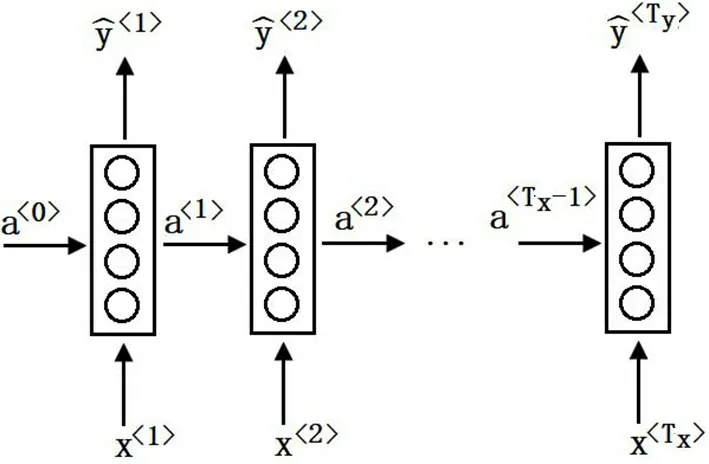
图2 循环神经网络词序列预测
循环神经网络根据输入词序列长度T和输出词序列长度T的不同,可以呈现出五种形式,如图3所示。本次实验搭建的序列模型编码部分使用的是“多对一型”,将输入的词序列提取成一个特征向量;解码部分使用的是“一对多型”,将特征向量解码成另一串词序列。

图3 循环神经网络的五种形式
另外,由于语句中当前词语不仅与前面的词语有关,与后面词语也有关,为了描述这种关系在编码部分使用了双向循环网络。双向循环网络在单向循环网络的基础上增加了反向传播的过程,可以将后面语句信息反馈给当前词语的时序神经元结构。
自然语言中,某个词语可能与相距较远的另一个词语有着较强的依赖关系。循环神经网络神经元激活函数使用的是tanh 函数,在模型优化的过程中,距离较远词语的梯度会消失,导致词语的预测结果只受周围附近的词语影响。
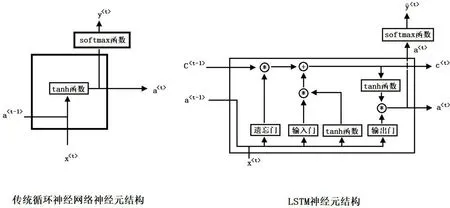
图4 传统循环神经网络神经元结构和LSTM 神经元结构
3 相似度计算
将语句转化为向量后,就可以通过向量的相似性计算来判断两个语句的相似性。常见的相似性计算方法有余弦相似度(Cosine)、欧式距离(Euclidean)、皮尔逊相关系数(Pearson Correlation Coefficient)等。
余弦相似度以向量的夹角为考量角度。假设两部影片的特征向量为A 和B,那么它们的余弦相似度如式(1)所示。
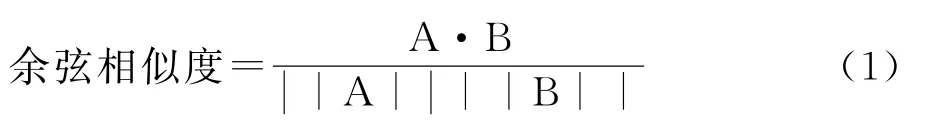
由于余弦相似度表示方向上的差距,对距离并不敏感,为了增强对距离的差异性描述,一般会对余弦相似度进行调整:每个值都减去一个均值,这样调整的余弦相似度被称为皮尔逊相关系数,如式(2)所示。
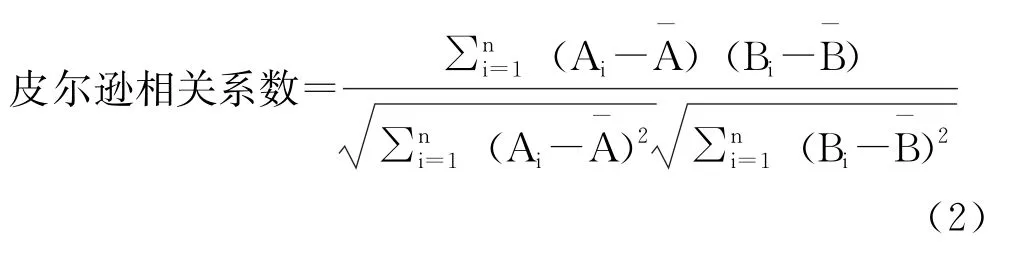
欧式距离以向量的空间距离为考量角度,能够体现个体数值的绝对差异,弥补余弦相似度对距离不敏感问题,如式(3)所示。
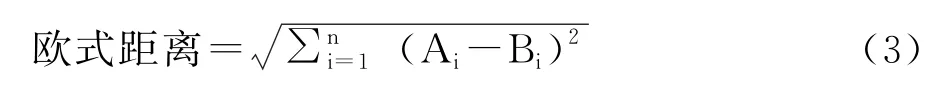
在本实验中为了从向量的夹角和向量的距离两方面衡量样本特征向量的相似程度,采用皮尔逊相关系数和欧式距离两种方式分别考量。
4 基于影片简介的相似影片推荐
本次实验模型设计的整体思路是先利用开源的文本摘要数据集训练序列模型,这样得到的序列模型除了能够将文本转化为向量外,还可以提取文本中的关键信息,再利用序列模型对影片简介进行摘要提取,取序列模型编码部分输出的特征向量进行影片相似性计算。模型由六个模块组成:数据清洗模块、词向量制作模块、数据编码化模块、序列模型训练模块、影片简介特征向量计算模块、影片相似性计算模块,见图5。
数据清洗模块,序列模型使用了哈尔滨工业大学智能计算研究中心提供的文本摘要数据集(LCSTS)第二部分的数据进行训练,该部分共有短评论数据10666条,每条样本数据都有正文和摘要两部分,可用于序列模型的有监督训练。影片简介数据集用于在序列模型预测摘要的过程中提取特征向量,数据集共有33602条数据,每条样本数据只有正文没有摘要部分。两个数据集都没有缺失值,但是仍然存在一些格式问题,数据清洗阶段将对数据格式进行统一,去掉英文和数字只保留中文,对文本进行分词和去停用词的处理,为文本的向量化做准备。
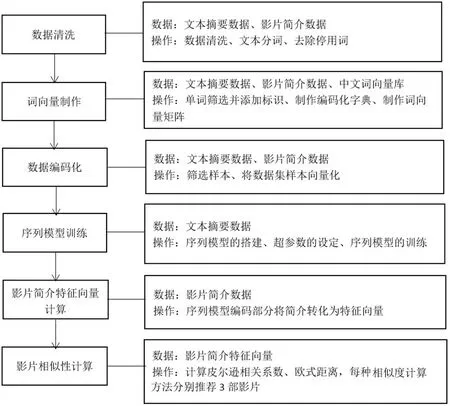
图5 基于影片简介的相似影片推荐模型结构
词向量制作模块,机器无法直接对中文文本进行处理,在训练模型之前需要对中文数据集进行向量化。本实验使用了由北京师范大学中文信息处理研究所与人民大学DB-IIR 实验室共同制作的中文词向量语料库,该语料库实现了将常用的195202个中文单词转化为300维的向量,文本摘要数据集和影片简介数据集共有单词数量203579个,经过测算语料库对两个数据集的单词覆盖率达到92.4%,可以在该语料库的基础上建立本模型的词向量矩阵。为了筛去一些小频率的单词,减少训练压力提高精度,本实验只保留了词频大于3的单词,将去掉的单词用<UNK>标识。由于数据集每条文本数据的长度是不同的,用<GO>和<EOS>分别标识文本的开头和结束位置,能够更好地让机器识别。
数据编码化模块,文本摘要数据集的文本单词数量均值、最小值、最大值分别为:32个、10个、52个;影片简介数据集的文本单词数量均值、最小值、最大值分别为:61个、1个、3009个。为了统一两个数据集的文本单词数量分布,需要对两个数据集样本进行筛选,使得文本最大单词数量不超过54个,最小单词数量不超过10个,<UNK>单词数量最多为2个,并且只保留国产影片作为本次的相似影片计算样本。最终文本摘要数据集样本数量9226条,影片简介数据集样本数量9216条。数据筛选完成后,利用上一模块制作的词向量矩阵对文本摘要和影片简介数据集向量化。
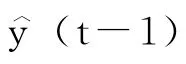
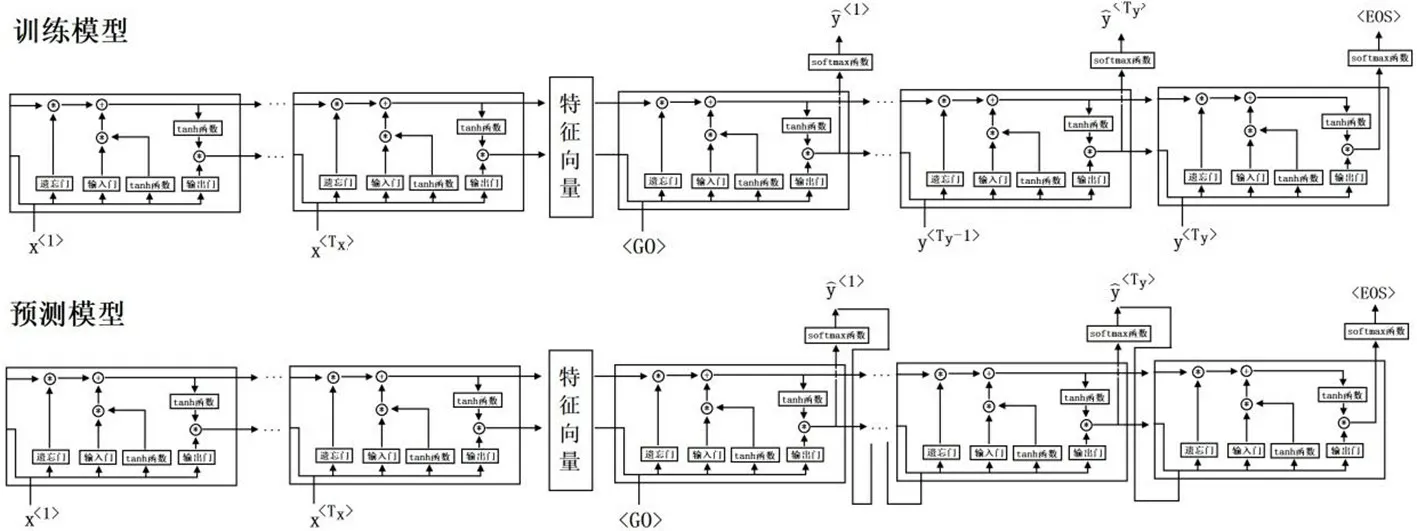
图6 序列模型解码部分训练和预测模式下模型结构
影片相似性计算模块,将影片简介数据集9216部国产影片特征向量两两分别计算皮尔逊相关系数、欧式距离。皮尔逊相关性系数分值越高影片越相似,欧式距离则是分值越低影片越相似。根据两种相似度计算得分,为每部影片分别推荐最相似的三部影片作为推荐结果。
5 结果分析
欧式距离得分越小表示两部影片越相近,将9216部影片两两计算相似度,得到的最小得分为0(即影片本身),最大得分17,数值分布如图7 所示。根据分数的分布情况将影片的相关性分为:强、较强、中等、较弱、弱五个等级,分数区间分别为[0,8],[8,10],[10,12],[12,14],[14,17]。

图7 欧式距离数值分布
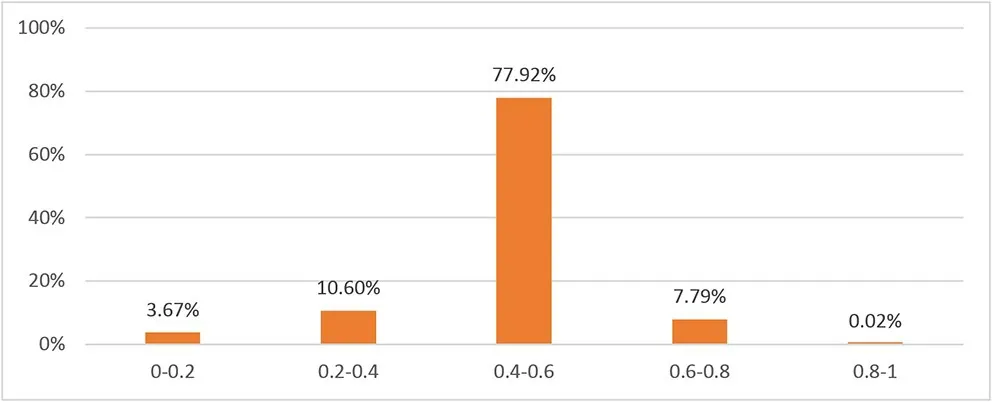
图8 皮尔逊相关系数数值分布
皮尔逊相关系数得分越大表示两部影片越相近,将影片两两计算相似度得分在[0,1]区间内。与欧式距离相似,将皮尔逊相关系数由弱到强分为五个等级。[0.8,1]、[0.6,0.8]、[0.4,0.6]、[0.2,0.4]、[0,0.2]五个分数区间分别表示影片间强、较强、中等、较弱、弱的相关程度,各区间的数量分布如图8所示。
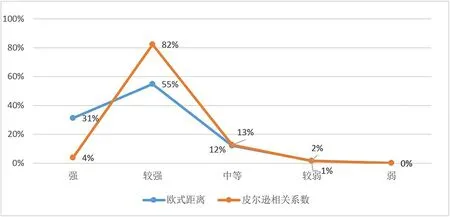
图9 两种相似性计算方法推荐影片的相关性等级占比情况
为每部影片分别用欧式距离和皮尔逊相关系数推荐三部影片,推荐影片相关性等级如图9 所示,欧式距离推荐影片相关性大都处于强和较强区域内,皮尔逊相关系数推荐影片相关性大都处于较强区域。该结果说明利用两种相似性计算方法都可以得到较好的推荐效果,欧式距离对强相关的影片更敏感。
随机从影片样本中抽取《百团大战》《唐人街探案3》《宠爱》《北京爱情故事》四部票房过亿的热片,分析个体影片的推荐结果,如表1所示。

表1 抽样热门影片预测结果
使用序列模型抽取影片特征向量再进行相似度计算的方法,容易匹配到具有相同关键词的影片。如表1所示,影片《宠爱》讲述了六段人与狗的温馨故事,推荐得到的影片《那人那狗》《萌宠入殓师》《降落好》影片简介中都多次出现流浪狗的关键词。模型的缺点也很明显,影片的推荐结果完全依靠影片简介来决定,因此对影片简介的质量要求很高。
6 结束语
本文实验性地将序列模型应用于影片简介特征提取上,再利用相似性计算方法得到相似度较高的影片作为推荐结果,实现基于影片本身特征的推荐方法。在农村公益电影订购中,利用相似性影片推荐算法,在缺少用户订购历史数据的应用场景下,建立面向放映员的个性化影片推荐模型。序列模型使用的文本摘要数据集样本数量只有近万条,导致训练得到的模型精度有限,下阶段将使用百万级的文本摘要数据集,进一步优化序列模型。另外在相似性计算阶段,将影片类型、导演、主演等相关信息也作为特征向量加入到相似性计算中,进一步提高推荐系统的准确性。
猜你喜欢
中学生理科应试(2021年11期)2021-12-09
上海工艺美术(2021年4期)2021-04-24
数学学习与研究(2018年15期)2018-11-12
戏剧之家(2018年12期)2018-06-13
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
现代商贸工业(2016年23期)2017-02-04
文艺生活·下旬刊(2016年12期)2017-01-11
电脑知识与技术(2016年22期)2016-10-31
数理化学习·高一二版(2009年2期)2009-03-30
