
磷灰石Eu/Y-Ce:基于大数据的源区类型判别新图解 *
2022-02-14 03:13:10周统邱昆峰王瑀于皓丞侯照亮
岩石学报 2022年1期
周统 邱昆峰, 2 王瑀 于皓丞 侯照亮
1. 中国地质大学(北京)地球科学与资源学院,北京 100083 2. 中国地质大学地质过程与矿产资源国家重点实验室,北京 100083 3. 维也纳大学地质系,维也纳 1090
磷灰石广泛分布于火成岩、沉积岩和变质岩中(Chew and Donelick, 2012; Henrichsetal., 2018; 赵振华和严爽, 2019),属六方晶系,其分子式为M10(Z4O6)X2,式中M=Ca、Sr、Pb、Na、REE、Ba、Mn等;Z=P、As、Si、V、Cr、S、B、N、Ge等;X=F、OH、Cl、Br、I等。微量元素通常以类质同象的形式进入磷灰石晶格,在不同形成环境下其微量元素特征存在显著差异(朱笑青等, 2004; Deng and Wang, 2016; Anderssonetal., 2019; O’Sullivanetal., 2020; Qiuetal., 2020)。因此磷灰石微量元素特征被视为追踪物质来源和演化的有力工具,在反演岩石成因过程中具有关键作用。(Chewetal., 2011; Hughes and Rakovan, 2015; Webster and Piccoli, 2015; Dengetal., 2020b, 2021; Yuetal., 2021; 苏建超等, 2021)。Belousovaetal.(2002)总结并提出了Sr-Y、Sr-Mn、Y-(Eu/Eu*)和(Ce/Yb)N-REE判别图解(图1),用于区分花岗岩、花岗伟晶岩、辉绿岩、歪碱正长岩、二辉橄榄岩、碳酸岩、钛铁霞辉岩和镁铁质岩石等常见岩石中磷灰石母岩类型。张硕等(2018)进一步提出了(Gd/Yb)N-δEu、(La/Sm)N-(La/Yb)N和(La/Yb)N-REE图解,用于判别碳酸岩、二辉橄榄岩、辉绿岩、正长岩、花岗岩、花岗伟晶岩、岩浆型铁矿床、热液流体相关的铁矿床、榴辉岩、角闪岩和磷块岩中的磷灰石母岩类型。
现研究表明,数据量和图解端元的不足,极大制约了运用判别图解对磷灰石母岩类型进行准确判别。Belousovaetal.(2002)的图解仅针对岩浆岩中的磷灰石类型进行了区分判定,并且部分已知类型的磷灰石微量元素数据不能与其对应区域准确吻合,平均准确率仅为59%(表1),如中-低级变质岩和高级变质岩中的磷灰石数据没有与其相对应的判别类型区域,而与岩浆岩中的磷灰石数据严重重合;镁铁质火成岩和富碱性岩石的数据分布不仅与该图解所划定的判别区域差异大,而且两种类型重合现象亦严重(图1)。这些已有的经典判别图解已经逐渐无法满足学者们对于更多磷灰石母岩类型准确判别的需求。
地球大数据是一种典型的科学大数据,是具有空间属性的地球科学领域大数据,它一方面具有海量、多源、多时相、异构、多尺度、非平稳等大数据的一般性质,同时具有很强的时空关联和物理关联(郭华东, 2018)。近年来,微区测试技术日益成熟,地球化学数据大量积累,传统分析方法已逐渐无法有效利用这些数据所携带的信息。数据的丰富和大数据技术的发展,为以大数据为依托的分析方法应用到地质学研究中提供了可能。通过开发出智能的数据处理方法可以极大提升现有数据判别的准确度、可信度和效率(周永章等, 2018)。
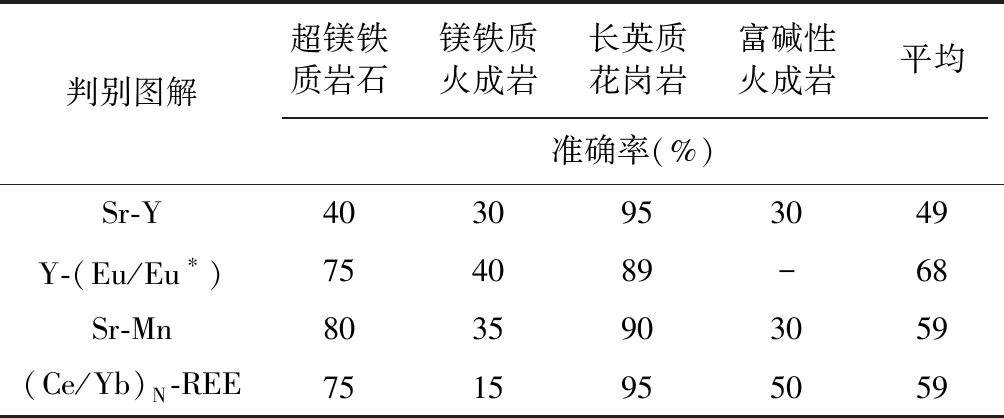
表1 已发表的磷灰石母岩类型判别图解准确率
本文收集了全球已发表的1925个典型磷灰石样品测试点数据,依照O’Sullivanetal.(2020)的分类方式将所有数据分为富碱性火成岩(ALK)、超镁铁质岩石(UM)、镁铁质火成岩(IM)、长英质花岗岩(S)、中-低级变质岩(LM)、高级变质岩(HM)和自生磷灰石(AUT)七种类型。在前人研究的基础上,利用穷举法,研究不同磷灰石微量元素对物源判别的贡献,寻找与评估磷灰石物源判别图解的最佳端元,建立了新的磷灰石物源判别图解。

图1 不同岩石类型的磷灰石微量元素散点图(底图分区据Belousova et al., 2002)Fig.1 Scatterplots of published apatite trace element data of different rock types (base map after Belousova et al., 2002)
1 磷灰石微量元素数据预处理
1.1 数据收集
本研究收集了近三十年来,已经发表的20篇经典文献,整理出了全球典型磷灰石微量元素数据集(图2)。数据集中收集了不同母岩类型的610个磷灰石样品,包括1925个测试点的微量元素数据,共计34628个元素值。其中测试点的微量元素数据包括:富碱性火成岩测试点数据263个(Zirneretal., 2015; Maoetal., 2016),超镁铁质岩石测试点数据121个(O’Reilly and Griffin, 2000; Ihlenetal., 2014; Maoetal., 2016; Chakhmouradianetal., 2017),镁铁质火成岩测试点数据843个(Sha and Chappell, 1999; Belousovaetal., 2002; Hsiehetal., 2008; Tollarietal., 2008; Chuetal., 2009; Tangetal., 2012; Ihlenetal., 2014; Maoetal., 2016),长英质花岗岩测试点数据90个(Dill, 1994; Sha and Chappell, 1999; Hsiehetal., 2008; Chuetal., 2009),中-低级变质岩测试点数据272个(Nishizawaetal., 2005; El Korhetal., 2009; Maoetal., 2016; Henrichsetal., 2018),高级变质岩测试点数据172个(Beaetal., 1994; Bea and Montero, 1999; Belousovaetal., 2002; Nutman, 2007; Henrichsetal., 2018)和自生磷灰石测试点数据164个(Dill, 1994; Shields and Stille, 2001; Nishizawaetal., 2005; Joosuetal., 2015, 2016)。
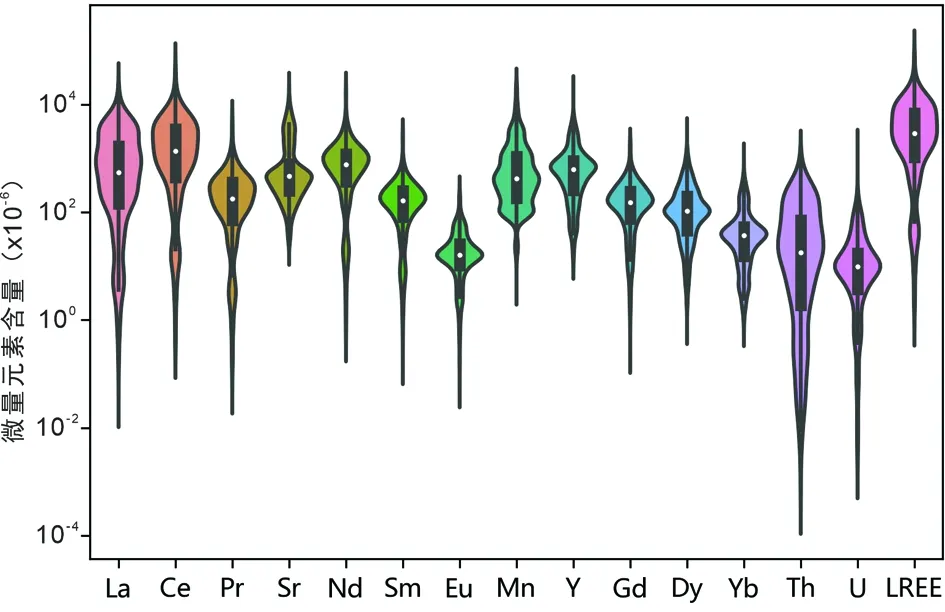
图3 磷灰石微量元素含量提琴图Fig.3 Violin plot of apatite trace element data
论文数据不同的来源,不同的测试项目与检测元素,导致每组数据的缺失值不同。综合已整理的数据集,本文选用了各文献中交集最多的14个元素及LREE(La+Ce+Pr+Nd)含量值进行最佳判别端元穷举工作,服务于判别图解的端元建立(见下文)。这14种元素包括La、Ce、Pr、Nd、Sr、Sm、Eu、Mn、Y、Gd、Dy、Yb、Th和U。该数据集La值含量变化从0.03×10-6到20488×10-6,平均值为1341×10-6;Ce值含量变化从0.22×10-6到53005×10-6,平均值为2484×10-6;Pr值含量变化从0.04×10-6到5121×10-6,平均值为259.66×10-6;Sr值含量变化从18.6×10-6到22498×10-6,平均值为1130×10-6;Nd值含量变化从0.37×10-6到18436×10-6,平均值为992.45×10-6;Sm值含量变化从0.12×10-6到2829×10-6,平均值为193.73×10-6;Eu值含量变化从0.04×10-6到278.4×10-6,平均值为23.1×10-6;Gd值含量变化从0.19×10-6到2031×10-6,平均值为187.93×10-6;Dy值含量变化从0.63×10-6到3232×10-6,平均值为158.34×10-6;Y值含量变化从10.02×10-6到19970×10-6,平均值为814.74×10-6;Yb值含量变化从0.58×10-6到1094×10-6,平均值为54.99×10-6;Mn值含量变化从3.50×10-6到26102×10-6,平均值为1097×10-6;Th值含量变化从0.0004×10-6到899.41×10-6,平均值为59.59×10-6;U值含量变化从0.001×10-6到1421×10-6,平均值为19.88×10-6;LREE值含量变化从0.83×10-6到97051×10-6,平均值为5077×10-6。微量元素含量提琴图展示了该磷灰石微量元素数据集的分布与数据交集情况(图3)。
1.2 数据清洗
数据清洗能够最大程度地消除所构建数据集的统计学偏差。对所选取15个特征端元进行数据清洗,删除特征元素为空值、负值和异常值的磷灰石数据。由于自生磷灰石类型缺少Sr、Th、U等多种元素的数据,因此所选取的研究对象为富碱性火成岩、超镁铁质岩石、镁铁质火成岩、长英质花岗岩、中-低级变质岩和高级变质岩共六种类型。数据集中各端元的数值大范围分布(如,Ce:0.22×10-6~53004×10-6;U:0.001×10-6~1421×10-6)可通过对数处理使数据分布更加集中(Aitchison, 1982; Thomas and Aitchison, 2006; Wangetal., 2021)。清洗后磷灰石微量元素数据进行对数转换,相较于原始数据,更利于数据分析和研究。
所建数据集中,镁铁质火成岩测试点数据843个,长英质花岗岩测试点数据90个,数据存在类间不平衡。本文故引入随机抽样法,最大限度平衡数据集中的数据。随机抽样法包括随机过采样法和随机欠采样法。随机过采样法通过复制少数样本,并添加到原样本中扩充原始数据集;随机欠采样法通过随机选择并删除多数样本的数据,以减小样本(He and Garcia, 2009)。本文通过随机过采样的方法将长英质花岗岩数据完整复制2次、超镁铁质岩石数据完整复制1次和高级变质岩数据随机选取一半复制1次;通过随机欠采样的方法处理富碱性火成岩数据、镁铁质火成岩数据和中-低级变质岩数据,以得到数据量相对平衡的数据集。
数据清洗后的磷灰石微量元素数据集符合大数据7V特征,即规模大(Volume)、多样化(Variety)、动态性(Vitality)、准确性(Veracity)、价值化(Value)、高速性(Velocity)和可视化(Visualization),更适用于大数据分析应用。该数据集包含磷灰石测试点的微量元素数据共1241个,其中富碱性火成岩测试点数据185个,超镁铁质岩石测试点数据186个,镁铁质火成岩测试点数据253个,长英质花岗岩测试点数据174个,中-低级变质岩测试点数据232个和高级变质岩测试点数据211个。此数据集为建立新判别图解奠定了数据基础。
2 构建磷灰石判别图解
2.1 穷举法筛选二元图解端元
通过穷举的方式,计算预处理后的磷灰石微量元素数据集中15个特征(La、Ce、Pr、Nd、Sr、Sm、Eu、Mn、Y、Gd、Dy、Yb、Th、U和LREE)任意两特征间的比值,得到La/Ce、La/Pr、La/Nd等105种元素含量比值。联合这15种元素含量值与所得105种元素含量比值,得到120个构建图解的端元。再将这120个图解端元中任意两个端元进行组合,构建二元图解,得到共7140个图解。
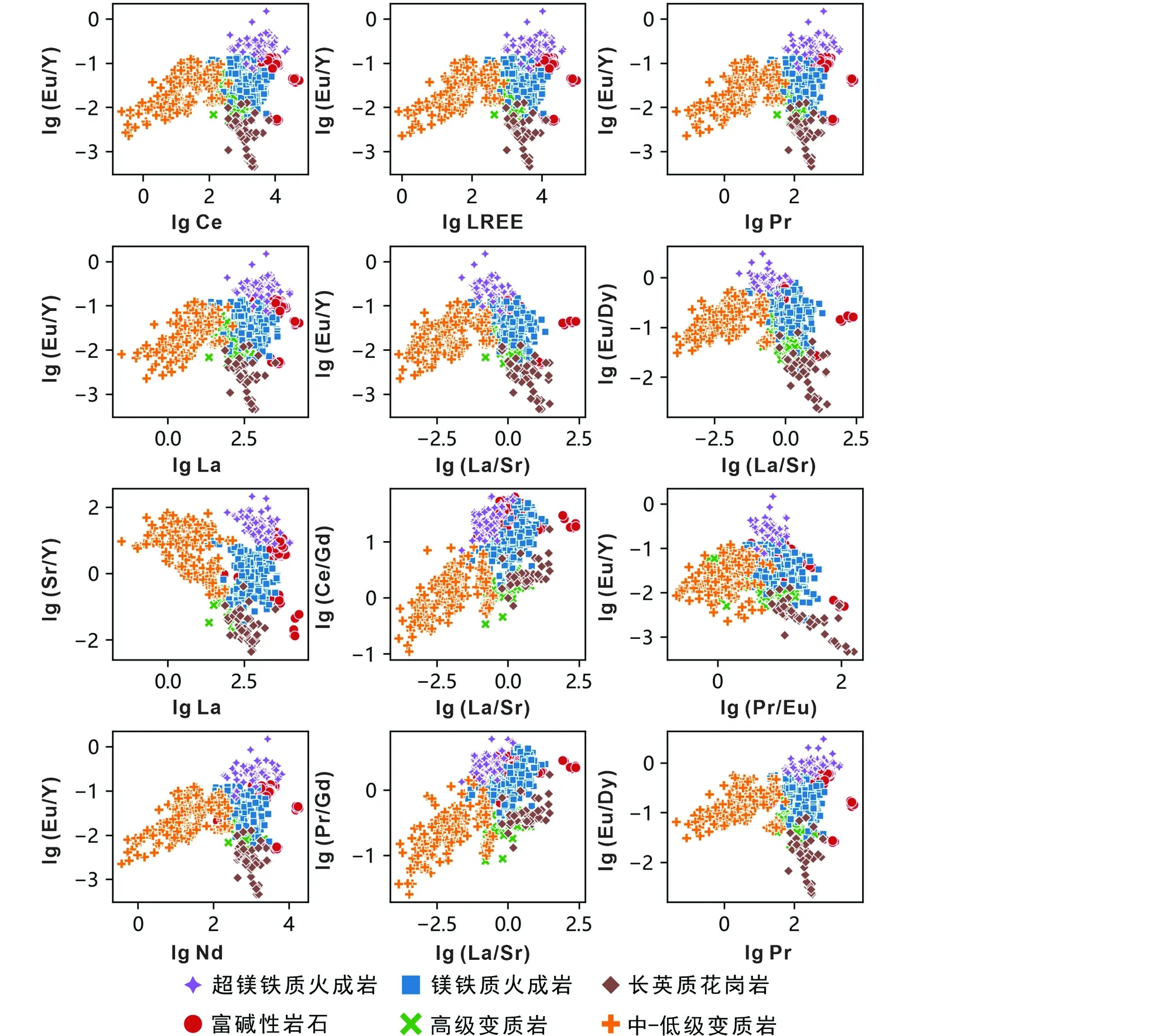
图4 轮廓系数排名前12的磷灰石母岩类型判别图解Fig.4 Top 12 biplots of apatite in deifferent rock types from the dataset
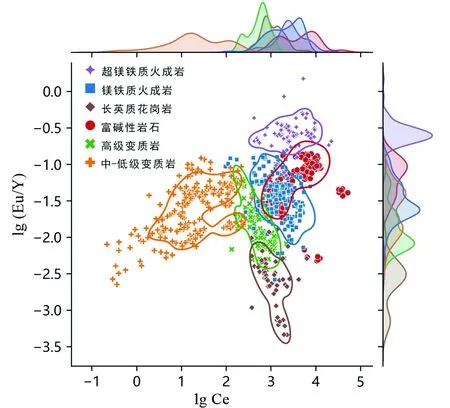
图5 磷灰石Eu/Y-Ce判别图解的核密度估计图Fig.5 Kernel density estimation of apatite Eu/Y vs. Ce discrimination diagram
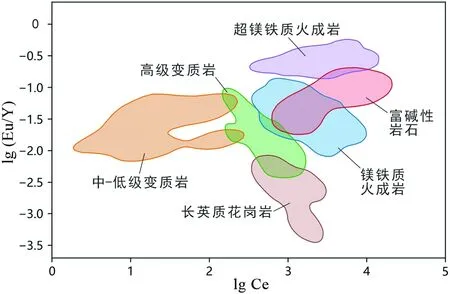
图6 磷灰石物源类型Eu/Y-Ce判别图解Fig.6 Eu/Y vs. Ce discrimination diagram for apatite provenance classification
为评估上述7140个二元图解的判别效果,本研究引入轮廓系数(Silhouette Coefficient),以评估构建判别图解的最适端元。轮廓系数是评价聚类效果好坏的一种量化方式(Rousseeuw, 1987),由数据内聚度和分离度两种因素所决定。内聚度评估同一分类簇内,数据分布的紧密程度。分离度评估不同分类簇之间,数据的分离程度。轮廓系数数学表达式为(1):
(1)
其中a(i)为对象i与同一簇内所有其他对象的平均相异度(相异度:研究对象的差异程度),b(i)为对象i与其最近的簇内所有对象的平均相异度。轮廓系数的范围为[-1, 1],当轮廓系数s(i)接近1时,“内部”差异a(i)远小于“相邻”差异b(i),聚类效果良好;当s(i)接近-1时,“内部”差异a(i)远大于“相邻”差异b(i),样品i应被分类到“相邻”簇内,聚类方式错误;当s(i)为0时,“内部”差异a(i)与“相邻”差异b(i)相等,聚类无(明显)关联性(Rousseeuw, 1987)。
通过轮廓系数量化数据簇内部相异度与数据簇之间的相异度,对所有组合的图解按照轮廓系数值降序排序。轮廓系数越大,表示该二元图解判别磷灰石母岩类型的效果越好。基于轮廓系数,本文筛选出效果最好的端元,来构建二元图解。
2.2 核密度估计圈定数据分布
为了进一步精确和量化磷灰石物源判别图解,在穷举法得到的最优端元图解基础上,本文运用核密度估计,圈定磷灰石微量元素数据分布。核密度估计(Kernel Density Estimation, KDE),属于非参数检验方法,由Rosenblatt (1956)和Parzen (1962)提出,又名Parzen-Rosenbaltt窗(Parzen-Rosenblatt window),是概率论中估计位置密度的函数。核密度由核和带宽决定,数学表达式为(2):
(2)
其中K为非负函数,代表核;h为平滑参数,代表带宽。核密度估计方法不对数据分布增加任何假定,而是根据数据本身的特点和性质进行分布拟合(Rosenblatt, 1956)。基于核密度估计,可更准确的圈定最优判别图解中不同磷灰石母岩类型的位置分布。
3 结果
通过评估轮廓系数,得到磷灰石物源判别效果最好的前12个图解分别为Eu/Y-Ce图解(SC=0.26929)、Eu/Y-LREE图解(SC=0.26847)、Eu/Y-Pr图解(SC=0.26826)、Eu/Y-La图解(SC=0.26585)、Eu/Y-La/Sr图解(SC=0.25959)、Eu/Dy-La/Sr图解(SC=0.25036)、Sr/Y-La图解(SC=0.25001)、Ce/Gd-La/Sr图解(SC=0.24855)、Eu/Y-Pr/Eu图解(SC=0.24772)、Eu/Y-Nd图解(SC=0.24713)、Pr/Gd-La/Sr图解(SC=0.24684)和Eu/Dy-Pr图解(SC=0.24654)(图4)。其中磷灰石物源判别效果最好的图解为Eu/Y-Ce图解,其轮廓系数为0.2629。为了更详细的展示Eu/Y-Ce图解中数据的分布情况,绘制了Eu/Y-Ce图解的核密度估计图(图5)。
4 讨论
4.1 数据处理
随机抽样方法的使用,能有效的提高判别图解的准确率。当数据集存在类间不平衡时,分类结果更偏向于样本容量大的类型,因此样本容量小的类型分类结果不准确(Zhongetal., 2021)。He and Garcia (2009)提出,对于大多数不平衡的数据集,采样技术的应用有助于提高分类器的准确性。但在数据预处理阶段,过采样与欠采样的方法都可能会存在相应的问题。欠采样方法从多数样本随机删除对象时可能会导致多数类相关信息缺失,过采样方法将少数样本复制的数据添加到原始数据集中可能会导致过度拟合(He and Garcia, 2009)。本研究针对清洗后的镁铁质火成岩类型数据使用欠采样方法时,按照磷灰石区域与类型,随机删除三分之二的数据,确保每种区域与类型均有信息保留。数据平衡前后的Eu/Y-Ce轮廓系数从0.1750增加到0.2693,磷灰石物源判别显示出更好的结果,证明过采样与欠采样方法在本研究中的有效性。
4.2 筛选判别图解端元
磷灰石物源判别图解的端元穷举结果显示(图4),相较于单元素,元素比值具有更好的表现性。本研究中,单元素作为端元区分效果最优的组合为Sr-La,但其轮廓系数0.2202,在所有端元组合中排名仅为68位,且各类型磷灰石均有严重重合现象,尤其是高级变质岩与长英质岩石和镁铁质火成岩几乎完全重合(图1)。加入元素比值后得到磷灰石物源判别图解端元最优组合为Eu/Y-Ce,轮廓系数为0.2693,Eu/Y-Ce图解显示出了更好的磷灰石物源判别效果(图5)。
在穷举法评估指标问题上,耿厅等(2019)在穷举不同矿床类型锆石图解工作中引入了Calinski-Harabasz(CH)指标,CH指标亦为聚类效果评价常用的一种指标。本研究在进行此工作时发现CH指标在不同物源类型簇之间分离程度评判上表现较差,内部紧密但分离程度较差的结果会被给予过高分数,此结果不能充分利用有限的二维空间划分数据分布。相比之下,轮廓系数在不同类型之间则显示出更好的分离度。
4.3 核密度估计
核密度估计图是观测研究数据分布的有效方法,在数据可视化中,以一个或多个维度的连续概率密度曲线来表示数据分布。本研究将所得的最优磷灰石物源判别图解,即Eu/Y-Ce图解,通过二维核密度估计,确定不同物源类型的数据分布,得到更加准确的磷灰石微量元素数据分布范围。为了最大程度排除异常值干扰,本文选取了82%的密度进行磷灰石母岩类型划分(图6)。所得磷灰石物源判别图解,相较于其他图解更加全面,更加准确。
4.4 地球化学分析
随着岩浆分异程度的增加,磷灰石微量成分Sr含量降低,Y含量增加,但是结果显示,Sr和Y作为端元时对不同磷灰石母岩类型的区分效果较差,在Belousovaetal.(2002)的判别图解(图1)中Sr与Y所在的维度也有很大的重叠部分,说明Sr和Y作为单元素端元所携带的信息不能有效区分磷灰石母岩类型。斜长石是强烈富集Eu的矿物,随着岩浆分异程度的增加,体系中斜长石的大量生成,Eu大量进入斜长石晶格中,导致磷灰石中Eu含量的降低(Dengetal., 2020a; Qiuetal., 2021)。岩浆分异过程中,Eu和Y这种负相关的变化表明Eu/Y能有效地区分不同磷灰石母岩类型。Belousovaetal.(2002)认为Y和Eu的比值是有用的磷灰石判别指标。Ce与Eu均为变价稀土元素,具有不同的化合价态:Ce3+/Ce4+和Eu2+/Eu3+,可以反映形成体系的氧逸度变化(Ballardetal., 2002; Watsonetal., 2006; 张红等, 2018; 邢凯等, 2018; Dengetal., 2018)。Ce3+和Eu3+作为亲磷灰石元素价态,更容易替代磷灰石中的Ca2+进入晶格中,磷灰石显示出更高的Ce和Eu含量。Eu/Y-Ce判别图(图6)中可以看出,相比于高级变质岩,中-低级变质岩的形成处于偏氧化的环境,Ce3+转变为Ce4+,从磷灰石中释放出来,显示出偏低的Ce含量;相比于长英质花岗岩,镁铁质火成岩与超镁铁质岩石的形成处于偏还原的环境,Ce4+转变为Ce3+进入磷灰石晶格中,磷灰石显示出更高的Ce含量。邢凯等(2018)认为磷灰石中Ce和Eu这两个具有相反分配行为的元素,对说明母岩浆的氧化还原环境具有重要意义。所以本文构建的Eu/Y-Ce图解能够显示最优的磷灰石物源判别效果。
5 结论
(1)磷灰石Eu/Y-Ce判别图解是通过穷举所有特征元素组合,引入轮廓系数筛选最优端元组合,辅之以核密度估计方法,选取82%的密度划分不同物源区域所得到的最优图解。相比于其他判别图解,本文提出的磷灰石Eu/Y-Ce判别图解更加准确,可涵盖更加全面的岩石类型,是有效的磷灰石物源判别图解。
(2)本次研究结果表明,影响磷灰石物源判别效果的主要因素可能包括磷灰石形成时的氧化还原状态和微量元素在共生矿物组合变化过程中的不同配分行为。氧化环境中,Eu2+转变为Eu3+,进入磷灰石晶格中,显示出更高的Eu含量;Ce3+转变为Ce4+,从磷灰石中释放出来,显示出更低的Ce含量。同时,斜长石的生成导致大量Eu进入斜长石,磷灰石也会显示出更低的Eu含量。
(3)本文通过大数据技术,分析指示矿物的性质来识别矿物物质来源。本研究对磷灰石微量元素的数据挖掘工作,是将大数据技术运用在地球科学研究中初步探索。随着未来磷灰石地球化学数据的更加丰富,结合更多算法,高纬度元素判别图解的建立值得进一步探索。
致谢论文的完成得益于邓军院士的指导。感谢俞良军老师对本文细心的审阅;感谢两位匿名审稿人对本文提出了详细的建设性意见;感谢中国地质大学(北京)的李珊珊博士后、龙政宇博士、朱紫怡和周飞为本文提供宝贵的修改意见。
猜你喜欢
机电信息(2023年24期)2023-12-26 10:55:38
石材(2022年4期)2023-01-07 10:47:04
土壤学报(2022年3期)2022-08-27 08:41:30
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
上海大学学报(自然科学版)(2020年4期)2020-05-24 07:29:38
土壤学报(2019年2期)2019-04-25 06:39:58
小猕猴学习画刊(2018年11期)2018-12-06 00:00:00
基础医学与临床(2018年11期)2018-02-13 07:15:06
基础医学与临床(2018年9期)2018-02-11 19:56:54
浙江农业科学(2016年11期)2016-05-04 04:16:43
