
基于命名实体识别与Neo4j的中文电子病历知识图谱构建和应用
2022-02-13 11:37许思特
医学信息学杂志 2022年12期
许思特 孙 木
(上海交通大学医学院附属瑞金医院 上海 200020)
1 引言
电子病历是指医疗活动过程中,实现存储、管理、传输和重现的数字化医疗记录[1]。对其填写质量进行审核纠正,形成体系化知识图谱,是医院统计信息部门日常工作之一。随着大数据时代来临,电子病历质量日益重要,知识关联脉络日益庞杂。对审核工作的要求、构建知识图谱的难度,都有了显著的提高。同时,专业人才的稀缺,使得引入技术手段的需求更为迫切。因此,为辅助统计部门进行审核工作、构建可视化知识图谱,尝试引入人工智能技术,对中文电子病历中的有效信息进行识别,并将实体内容进行可视化,从而达到提高审核工作效率、构建专业知识脉络的目的。大量自然语言处理(Natural Language Processing, NLP)学者聚焦命名实体识别(Name Entity Recognition,NER)和知识图谱(Knowledge Graph,KG),尝试高效识别包括中文病历在内的各领域关键信息,并构建相关专业的知识图谱。Liu K等[2]对比模型实体识别效率,探索最佳的电子病历特征模板。Ouyang E[3]结合分词、词性标注、医学词汇等语料特征,搭建实体识别系统。2019年,Liu Y[4]等建立RoBERTa,修改BERT中的关键超参数,使其更好地推广到下游任务中。KG的搭建也逐步渗透至各个领域,如星河军事KG、沃森健康(Watson Health)医疗KG、海致星图金融KG、海信交管云脑KG等[5]。为满足当下工作要求,将RoBERTa-BiLSTM-CRF的模型构建方式,引入中文病案NER领域中,达到有效识别中文病历关键信息,提高病案审核工作效率的目的。同时爬取网络数据,采取Neo4j属性图模型为相关实体建立成体系的KG,具象化地展现医药领域的知识脉络。最终,搭建问答系统,针对不同病历提出参考建议。
2 资料与方法
2.1 数据来源
数据来源由3部分组成:全国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,CCKS)2019评测数据、上海交通大学医学院附属瑞金医院真实病历、网络爬取数据。其中,CCKS 2019病历数据1 379条,瑞金医院病历相关数据21条,网络爬取数据8 808条。CCKS是由中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议,CCKS 2019包含6个评测任务。其中,实体识别任务由清华大学知识工程实验室组织,所涉及中文电子病历数据由专业人员进行标注,并严格脱敏[6]。
2.2 NER数据预处理
基于经审核的病历数据,采用联合标签方法实现序列标注。该方法通过将标签集对象的分段标签与命名实体的标签集进行联合生成新的标签集,常见的分段标签集有BIO和BIOES两种,其中,BIO将实体边界分为两类,B代表实体中的首个词,I代表实体中的非首个词,O代表目标实体类别外。BIOES进一步细分实体边界,增加实体结尾词E和单个实体词S两种边界类型。具体构造方法,见表1。BIOES较BIO提供更多分段信息,识别度更高。在BiLSTM模型下, BIOES较BIO效果更优。因此,字粒度序列标注模型均采用BIOES联合标签编码模式。
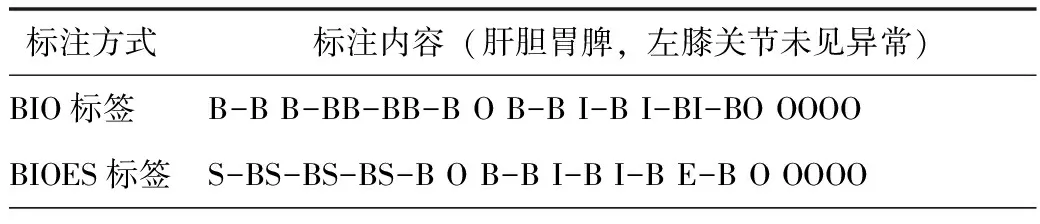
表1 标注对比
将CCKS 2019病历数据分为6种主要命名实体标签。爬取的数据以json格式存储,对后续识别的实体进行KG构建。按6∶2∶2的比例,将CCKS 2019数据集分为训练集、验证集、测试集。训练集用以训练算法,验证集用以调整参数,测试集用以评估最优模型。
2.3 NER建模方法
KG的关键技术在于运用图模型描述知识和对关系进行建模[7]。在构建KG的过程中,需要从大量的数据中抽取知识并建立联系,纯文本数据是知识的主要来源。实现从纯文本数据中获取实体信息依赖于实体抽取技术,KG高适用性和准确度的保障是高精度的NER技术[8]。为了有效地进行实体识别,采取RoBERTa-BiLSTM-CRF的NER建模方式。BERT使用堆叠的Transformer作为模型的主要架构[9],通过在大规模语料上的预训练,获得强有力的句子语义提取能力。RoBERTa基于BERT,两者在模型层面基本一致,但RoBERTa更为精细。具体变化如下:取消NSP任务;使用更大的mini-batch、训练数据、更长时间的训练;将BERT的静态掩码(mask)策略替换成动态掩码。
长短时记忆模型(Long Short-Term Memory,LSTM)是一种特殊的循环神经网络[10]。该模型引入储存单元、输入门、遗忘门和输出门的控制机制,解决长序列的梯度消失和梯度爆炸问题。BiLSTM即双向LSTM,由于LSTM只能单向编码,所以一般使用BiLSTM对隐藏层拼接后得到的向量作为融合上下文信息的词向量。条件随机场(Conditional Random Field,CRF)用以对序列标注进行建模。与隐马尔科夫模型相比,CRF引入特征函数,信息获取更加全面,能够获得更优的序列标注效果[11]。
采用RoBERTa-BiLSTM-CRF的模型构建方式,将处理好的文本序列输入到RoBERTa中,输出每个位置并与原标签序列对齐,继而输入到BiLSTM中进行处理。随后,将处理结果输入到CRF中,得到预测序列,见图1。

图1 整体模型
2.4 NER统计分析
NER的相关深度学习算法基于Tensorflow1.14实现编写,模型效果从准确率、召回率、F值3方面进行展示。具体计算如下:

2.5 知识图谱
KG指使用语义检索,从多种来源收集信息,以提高搜索质量的知识库。本质上KG是将各种客观实体、概念及其关系构成语义网络图,以此形式化地描述真实世界中存在的关系。其主要内容为知识的数据结构,包括实体、关系、属性等知识类的层次结构和层级关系定义,约束数据层具体形式。随着信息时代数据量急剧增长,KG的规模与日俱增,对知识存储提出更高要求。现有研究中KG大多采用基于图的数据结构,常见方式包括三元组图数据库、传统关系型数据库和图数据库。其中,基于图数据库的存储是目前主流方式。其优点是以节点和边表示数据,明确列出数据节点间依赖关系,具有完善的图查询语言且支持各种图挖掘算法,在深度关联查询速度上优于传统关系型数据库。常见图数据库包括Neo4j、JanusGraph和HugeGraph等[5]。采用Neo4j,在RoBERTa-BiLSTM-CRF模型对中文电子病历进行关键实体抽取的基础上,利用爬取的外延数据,直观呈现实体的知识关系网络,形成中文电子病历KG。其中,实体类型包括疾病诊断、操作检查、症状体征、药物、食物、科室类别等;实体关系包括属于、常用药物、所需操作、常见症状、常见并发症、宜吃食物、忌吃食物等。
2.6 问答系统(图2)
由于中文电子病历涉及的医疗场景问答属于封闭域任务,且病历数据相对规范,对关系精准度有较高保证。因而关系抽取不采用远监督模型与联合抽取,而是采取基于规则的关键词匹配,对问题进行穷举并分类。继而采用Neo4j的Cypher语法进行数据匹配查询,根据返回数据进行回答组装并输出。
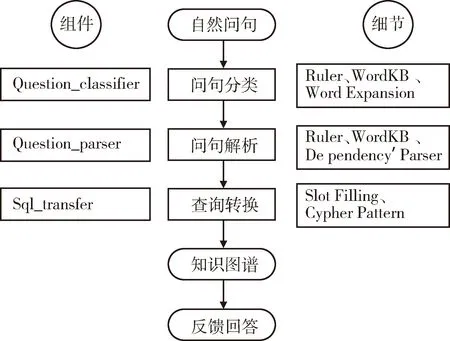
图2 问答框架
3 实验结果
3.1 数据情况
实体识别模型基于CCKS 2019数据集进行搭建。CCKS 2019病历数据重点聚焦疾病诊断、解剖部位、影像检查、实验室检验、手术以及药物6种标注的命名实体,其中疾病诊断2 798个、解剖部位1 933个、影像检查313个、实验室检验511个、手术905个,药物719个。按6∶2∶2的比例,将数据集分为训练集、验证集、测试集。训练集用以训练算法,验证集用以调整参数,测试集用以评估最优模型,见表2。

表2 实体识别模型数据分布(个)
KG基于中文电子病历与网络爬取数据进行搭建,共获取8 000条json格式的扩展医疗数据。KG的主要实体中,疾病诊断8 000个、操作检查2 813个、症状体征5 123个、药物3 118个、食物4 057个、科室类别50个,见表3。
KG的主要实体关系中,属于8 015个、常用药物13 758个、所需操作36 852个、常见症状5 766个、常见并发症11 496个、宜吃食物38 156个、忌吃食物21 945个,见表4。KG属性类型主要包括疾病名称、疾病简介、疾病病因、预防措施、治疗方式、治疗周期、易感人群等。

表3 实体情况

表4 实体关系情况
3.2 NER模型效能
采用CCKS 2019数据集,进行RoBERTa实体识别模型实验。在CCKS 2019数据集中,RoBERTa-BiLSTM-CRF模型效能如下:总体准确率81.91%、召回率83.03%、F值0.83;实验室检验中识别效能最佳,准确率88.24%、召回率86.35%、F值0.87;解剖部位中识别效能最差,准确率78.22%、召回率81.24%、F值0.79,见表5。

表5 模型效能
对比传统基于Word2Vec(总体准确率77.44%、召回率84.90%、F值0.81)、BERT(总体准确率79.18%、召回率84.66%、F值0.82)的实体识别模型,RoBERTa-BiLSTM-CRF拥有更优的效能。
3.3 Neo4j知识图谱
基于NER模型识别的重点实体,采用Neo4j进行KG可视化呈现。以主疾病窦性心动过缓为例,从药品、食物、操作等角度搭建KG进行直观展现,见图3。

图3 窦性心动过缓知识图谱
KG搭建完成后,可根据需要对重点关注的实体及其关系进行聚焦。以利巴韦林胶囊为例,对该药物可治疗的疾病、生产厂家等信息进行可视化呈现,见图4。

图4 利巴韦林胶囊知识图谱
3.4 问答系统
基于KG数据库,进行问答系统搭建。以探究主疾病窦性心动过缓原因为例,进行展示。整个问答系统逻辑过程由以下几步完成:关键词匹配、关键词对问句分类、对问句解析、数据查询、反馈组装回答。以疾病原因为例,关键伪代码如下。
#关键词匹配
if 原因关键词=[‘原因’,‘成因’,‘为什么’,‘怎么会’,‘怎样才’,‘咋样才’,‘怎样会’,‘如何会’,‘为啥’,‘为何’,‘如何才会’,‘怎么才会’, ‘会导致’,‘会造成’]
则关键词匹配→原因
#关键词对问句分类
if 原因关键词, 且问句包含疾病实体
则确认问句类型分类→疾病原因
#对问句解析
sql_transfer(问句类型, 疾病实体)
#数据查询
“MATCH疾病实体return疾病名称, 疾病原因” for i in entities
#反馈组装回答
answer=‘{0}原因可能有:{1}’.format(疾病名称,‘;’.join(list(set(疾病原因))))
以窦性心动过缓原因为例进行问答展示。提问“为什么会窦性心动过缓”,得到回答“窦性心动过缓原因可能有:迷走神经兴奋;窦房结功能受损;急性心肌梗死;自主神经张力改变”。
4 结论
4.1 不足与改进方向
基于NER与Neo4j的方式能有效构建中文电子病历KG,但该方法仍有不足值得探究完善。针对实体识别,识别效能仍有进步空间,可考虑改进词典、引入ALBERT模型[12]、融合字形[13]等方式。由于RoBERTa等预训练模式最初为英文设计,而汉语作为符号语言,符号包含了一些额外的语义信息。因此原始预训练语言模型形式缺失了字形信息和拼音信息。而将字形和拼音信息融入到预训练语言模型中的方式,已在中文多个领域都达到了最优,后续将以此作为探索方向。针对关系抽取,主要基于规则模板的匹配方式,会导致信息缺乏覆盖率、规则冲突等问题,可考虑引入更为前沿的抽取方法,如远监督关系抽取、实体关系联合抽取[14-16]等。针对KG仅涉及知识抽取阶段,后续知识融合、加工、推理仍有较大挖掘空间。另外对于可视化的展现,后续研究将以知识超图作为切入点。
4.2 未来展望
现阶段国内病案相关信息化工作主要集中在软件开发、无纸化阶段。后续对于人工智能技术在病案审核、监管、分类中的应用应该保持开放态度,积极进行成果融合。NER、KG作为NLP中的基础工作,在中文电子病历中应用效果良好。在未来,实体识别与实体链接联合任务、深度迁移学习、利用辅助资源进行基于深度学习的非正式文本分析等,都会是相关病案信息化发展中的有效助力。KG能够提高医疗信息系统智能化水平,为医疗领域提供从海量医学文本和图像信息中抽取结构化知识的手段。基于医疗KG,可以实现医疗知识问答、智能辅助诊疗、医疗质量控制及疾病风险评估等,具有广阔发展前景。总体而言,KG将赋能认知智能,具有广泛且多样的应用需求,能够产生巨大的社会价值,对社会结构产生深远影响。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
少先队活动(2020年12期)2021-01-14
数学小灵通·3-4年级(2020年9期)2020-10-27
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国卫生(2016年10期)2016-11-13
领导科学论坛(2016年9期)2016-06-05
