
医疗材料光学字符识别要素提取数据集MedOCR
2022-02-13 11:37刘利锋常德杰赵晓龙王铁虎杨锦新郭龙杰陈漠沙
医学信息学杂志 2022年12期
刘利锋 常德杰 赵晓龙 王铁虎 杨锦新 郭龙杰 陈漠沙
(北京环球医疗救援 北京 100020) (阿里巴巴 杭州 310000)
汤步洲
(哈尔滨工业大学(深圳)鹏城实验室 深圳 518055)
1 引言
1.1 MedOCR设计目的和标注过程
1.1.1 设计目的 医疗行业、保险行业中的电子病历、照片等材料含有很多隐藏信息。基于人工智能技术合理利用这些信息,将在商业应用和科研领域产生很高的价值。这些信息(如客户信息、诊断信息、用药信息、费用信息等)需要进行结构化才能进一步使用。使用传统的文本识别方法,首先需要用计算机视觉(Computer Vision,CV)领域算法将图片材料进行文本化,其中包含目标检测和目标识别,如使用可微分二值化(Differentiable Binarization,DB)[1]算法进行目标检测,再使用卷积循环神经网络(Convolutional Recurrent Neural Network,CRNN)[2]进行目标识别,或者使用检测和识别结合的算法,例如点集网络(Point Gathering Network,PGnet)[3]进行文本化后,再使用自然语言处理(Natural Language Processing,NLP)领域的一些算法将这些文本信息结构化,例如使用双向编码器表征(Bidirectional Encoder Representations from Transformers,BERT)[4]进行文本分类,使用长短期记忆人工神经网络(Long-Short Term Memory,LSTM)[5]参与序列标注等一系列方法将文本结构化后根据需求使用。但是相较于传统机器学习,这些深度学习方法需要更多标注数据,如何获取高质量的标注数据成为相关研究进展的最大障碍,MedOCR由此诞生,其目的在于提供高质量的标注数据以供材料信息提取相关研究使用。
1.1.2 标注过程 由业务专家设计标注指南,1名主标注员和1名副标注员参考标注指南历时1个月标注完成。该数据集包含出院小结、购药发票、门诊发票、住院发票4类材料共1 700张图片,涉及87个属性字段。
1.2 MedOCR特点
1.2.1 数据特殊性 首先,相较于以往的光学字符识别(Optical Character Recognition,OCR)数据集(如 ICDAR 2017-RCTW[6]采用四点标注),在MedOCR中,标注数据不涉及坐标,直接采用图片到值标注,拓展了研究方向,打破了传统文本识别的局限。其次,相较于以往的数据集,MedOCR使用了医疗门诊发票、住院发票、购药发票、出院小结等4类病历材料。
1.2.2 数据复杂多样性 主要体现在两个方面,一是OCR场景复杂,包含打印模糊、打印偏斜、套打偏斜、套打覆盖、阴影覆盖等多种实际业务中会遇到的场景,对常规的OCR模型提出挑战;二是文本结构复杂,有上下结构文本、左右结构文本、无属性名、多种近似且非规范化属性名等复杂文本结构,这也是近年来结构化文本理解及命名实体识别(Named Entity Recognition,NER)的研究热点。
2 资料与方法
2.1 数据来源
MedOCR的原始数据集数据源自互联网,将数据集分成训练集、评估A榜和评估B榜共3份,其中对应的材料类别数量,见表1。

表1 MedOCR构成
2.2 标注方法
第1步:先从公开的互联网渠道找到1 700张4类病历材料,其中包括出院小结340张、购药发票340张、门诊发票340张、住院发票680张。第2步:选择特定字段,如购药发票特定提取字段:票据代码、票据号码、校验码、开票日期、收款人、复核人、价税合计(大写)、价税合计(小写)。第3步:进行严格的人工审核。第4步:得到图片对应的重要信息内容并以表格形式保存,见表2、图1。

表2 购药发票提取字段格式

图1 数据集标注流程
2.3 各类材料数据示例说明
材料共有4类,分别是出院小结、购药发票、门诊发票和住院发票。每类材料标注数据文件结构基本一致,是由序号、图名、材料类型、属性名和正确值作为列名组成的5列数据,区别在于每类材料对应的属性名不同,出院小结共有8个属性名,购药发票共有8个属性名,门诊发票共有34个属性名,住院发票共有37个属性名,每个属性名对应1个正确值,即标注值,其根据图片上属性名对应的真实值标注而来。在正确值这列中有两个特殊值,分别为“无”和“-”,“无”代表图片中未出现该字段,“-” 代表图片中出现该字段但没有对应值,见表3。

表3 部分标注数据
3 结果评测
MedOCR 采用准确率作为评测指标。假如预测了一批字段,设预测正确的字段数量为correct,预测错误的字段数量为error,准确率就是预测正确字段数量占预测正确字段数量与预测错误字段数量之和的比例,当预测值和正确值皆为“无”时,则此值不计入计算,当预测值与正确值完全一致则判定为预测正确,否则判定为预测错误。具体计算方法见公式(1)。评估结果示例,见表4,评估结果中correct为3,error为4,则准确率为0.42。

准确率 (1)
4 数据集应用
4.1 应用方法及结果
正常未经过训练的模型对生活场景下病历材料图片内的文本识别效果普遍不佳,而且提取内容连贯性较差,丧失原本语义,因此需要在提取时考虑其原有内容完整性。评测组织者的基线方法(baseline)使用DB[1]进行文本检测和CRNN[2]进行文本识别的两阶段算法实现OCR。为解决图片不规整造成的提取困难,使用BERT进行文本分类以及LSTM+CRF进行命名实体识别的方法处理OCR提取后的文本部分。利用上述优化后的模型对此数据集进行测试,见表5。
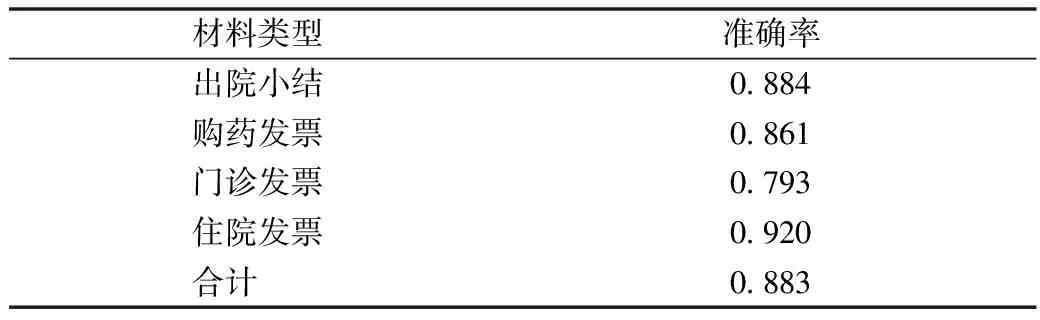
表5 模型测验结果
4.2 主要错误类型
经过对原数据图片和输出值的对比,主要错误类型可以总结为以下几类。第1类是印章对底版的信息遮挡导致目标提取有误,在各类发票中,各机构会盖上红色或蓝色公章,这些公章掩盖了部分底版信息,导致信息不能正确提取。第2类是底版背景颜色深对显示不清晰的信息造成影响,部分发票底版为深色背景,同样会导致信息提取产生误差。第3类是票据中常出现套打情况,即打印非一次完成而是票据内容打印在印好的票据底版上。套打时会因放置票据偏斜造成票据内容覆盖打印在底版文字上和打印内容偏离指定区域两种情况。第4类是信息内容不清晰,造成检测识别模型准确率低。第5类是检测模型误差造成识别模型识别不准确。第6类是识别模型混淆相近字造成识别结果不正确。第7类是文本结构不统一,且其中各省市票据字符、语义信息排列不规律造成NER模型训练提取难度提升。第8类是前置处理流程中检测识别模型结果不正确,造成错别字和文本位置信息错误,导致BERT结构化模型提取失败。从整体实验结果及错误类型分析中可以看到,目前模型性能相比人工标注结果还有较大的提升空间,信息抽取效果有待提高。
5 结语
本文介绍了专门用于医疗病历材料标注的特殊数据集。通过认真严格的标注过程获得了高质量数据集。实验结果证明医疗标注任务数据集具有一定实用性,但其信息抽取效果有待提高。该数据集的发布有助于推进医疗信息提取OCR模型的优化,并促进人工智能技术在医疗领域的应用。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
艺术评论(2020年3期)2020-02-06
制造技术与机床(2019年10期)2019-10-26
中国外汇(2019年21期)2019-05-21
恋爱婚姻家庭·养生版(2019年3期)2019-03-29
电子制作(2018年18期)2018-11-14
首席财务官(2018年8期)2018-04-26
中国总会计师(2017年1期)2017-03-10
中国防伪报道(2017年4期)2017-01-27
中国卫生政策研究(2014年1期)2014-02-03
