
基于深度强化学习的多无人机电力巡检任务规划
2022-02-12 02:49:08欧阳权吴兆香丛玉华王志胜
计算机与现代化 2022年1期
马 瑞,欧阳权,吴兆香,丛玉华,王志胜
(1.南京航空航天大学自动化学院,江苏 南京 211106; 2.南京理工大学紫金学院计算机学院,江苏 南京 210023)
0 引 言
由于大规模电网的空间距离较远,人工巡检效率低下,因此很多电力企业开始使用无人机对电力系统进行巡检[1]。无人机凭借其成本低、灵活性高、操控性强等特点,在电力巡检任务中发挥了重要的作用[2]。在应对大范围电力系统巡检任务时,由于电塔与电力设施数量较多,结构复杂,设施之间距离较远,会采用多无人机同时进行巡检[3]。多架无人机协作可以为重要电力设施带来多角度、全方位的观测信息,也可以分别对不同的电力设施进行巡视,提高巡检任务的效率。因而针对多无人机、多目标的任务场景,无人机的任务规划是研究的重点[4-6]。
目前多无人机任务规划的方法可分为传统方法[7-9]和人工智能[10]方法。传统算法是在已有的任务模型基础上,将任务规划转化为一个多目标优化问题,进而利用智能优化算法或随机优化算法如蚁群算法[11]、遗传算法[12-15]、启发式算法[16]等对其进行在线的求解计算,如文献[17]将多目标任务序列转化为TSP问题并利用遗传算法求解。文献[18]利用群算法求解动态任务分配问题。在面对多无人机多目标的优化问题时往往需要耗费较大的算力与时间,满足不了对任务动态实时分配的要求。随着深度学习的发展,神经网络为强化学习带来了新的生命力。深度强化学习算法是在马尔科夫决策这一框架下,通过观测环境的状态做出自身的动作决策,并反作用于环境以达到最高累计回报的智能算法[19]。深度网络的引入提高了强化学习对于不同状态信息的解析与记忆学习能力,使得其在面对多目标任务规划问题时展现了较为优秀的实时决策能力,减少了优化计算的过程[20]。
由于单智能体强化学习算法在解决多无人机协同问题时,会引起动作空间的维度爆炸与环境状态的不确定问题,增加了网络的收敛难度[21]。而基于值函数的多智能体强化学习算法可以将每个智能体的动作值函数融合,利用联合动作值函数将多智能体的联合动作价值表征出来并指导训练,取得了很好的效果[22]。
在多无人机电力巡检这一任务场景下,关键需求是多架无人机协作巡视同一个电力设施以达到多角度巡视的目的,这要求无人机在多智能体强化学习算法下激发其协作完成任务的能力。因此本文设计多智能体强化学习算法与协作任务奖赏函数,使得多无人机在集中训练后,执行任务时可以在分布式框架下根据不同的环境状态与自身观测做出协作完成任务的动作,使任务完成时间减少,最大化任务收益。
1 问题概述与建模
1.1 问题概述
本文基于大范围电力巡检的任务分配场景如图1所示,大范围电力巡检由输电线路巡查、设施巡检这2个部分组成。多个无人机部署在起点处,区域内随机分布多个电力设施,多无人机通过任务规划来对目标进行抵近巡视,获取电力设施的信息。假设每个设施的任务复杂度不同,导致无人机巡检所需时间也不同。当多个无人机同时对某个目标进行巡检时,可以实现多角度的电力设施巡检,相较于单一无人机巡检,任务时间明显缩短。

图1 多无人机大范围电力巡检示意图
1.2 问题建模
本任务是要求在上述任务场景下,多个无人机从起点出发,尽可能在最短的时间内,对多个电力设施进行抵近侦察。用TG={TG1,TG2,…,TGN}表示电力目标设施,无人机群表示为Drone={Drone1,Drone2,…,DroneM},其中,N表示目标个数,M表示无人机个数。di表示目标TGi的复杂程度。无人机Dronej在t时刻是否对目标TGi进行抵近侦察由xj,i,t表示,xj,i,t∈{0,1},其中,1表示正在巡检,0表示未巡检。设定总体飞行时间为T个单位时间,无人机Dronej对目标的巡查速率用τj来表示。综上可得约束为:
(1)


(2)
xj,i,t∈{0,1}
2 基于QMIX的任务规划算法
本文将任务环境抽象概括成一个部分可观的马尔科夫决策过程,将无人机飞向电力目标并进行信息收集与传递的过程综合为一个抽象动作,在此基础上对该任务进行分析建模,并通过基于QMIX的多智能体强化学习算法来解决多机规划问题,具体过程如下。
2.1 多无人机多目标场景下的DEC-POMDP模型
本文建立的分布式部分马尔可夫决策过程(DEC-POMDP)模型主要由元组G=〈S,U,P,r,O〉组成。其中多智能体P、环境状态S、智能体观测状态O、动作U以及奖励r等要素阐述如下。
1)多智能体:多无人机可以看做多智能体。在任务过程中,每个无人机Dronej将从当前环境总体状态st中获取自身的状态观测ot,j,按照自身内部策略πt,j得到输出动作ut,j,多个智能体的动作结合形成联合动作ut,环境将根据状态转换函数P(st+1|st,ut)做出对应的环境状态转移,得到下一时刻状态st+1,并且以此循环往复,直至任务结束。
2)状态与观测:设定每一时刻的环境总体状态为st=(ynt,loct),其中ynt为任务区域中全部电力设施的巡检情况,ynt=(ynt,1,ynt,2,…,ynt,N),ynt,i∈{0,1},0表示未巡检或正在巡检,1表示巡检完毕,loct表示多无人机自身位置信息,即loct=(loct,1,loct,2,…,loct,M)。由于是该任务为部分可观模型,因此设定每个智能体的观测量为ot,j=(dynt,j,loct,j),其中dynt,j表示Dronej在t时刻自身距离X范围内的所有设施TGi的当前巡检状态,loct,j为每个无人机自身当前时刻的位置状态。
3)动作:将单个无人机巡检的动作过程集合成一个抽象动作,即将向设施飞行,对设施进行抵近巡视、信息采集集合为动作ut,TG,将多个无人机的动作集合为一个联合动作ut,作用于环境并引起状态转移。每一个动作的结束条件为完成抵近巡视、目标信息采集2个步骤。完成当前动作后进行下一步动作决策。
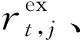
(3)
协作奖惩指的是相邻无人机协作巡检同一电力设施的奖赏,即:
(4)
路程奖惩与无人机飞过的路程距离成反比,以引导无人机用最短的路程、最少的时间来完成巡检任务,即:
(5)
综上所述,对于单个无人机来说,即时奖励表示为3种奖励之和,即:
(6)
2.2 QMIX算法
传统的基于值函数的单智能体算法Deep Q Network(DQN),是利用深度学习网络表示值函数,并利用经验回放池储存经验元组〈st,ut,rt,st+1〉,其中状态st+1是在状态st时采用动作ut后转移到的,同时会得到回报rt。通过最小化TD误差来训练神经网络参数θ。
(7)
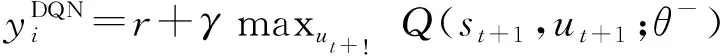
但是当DQN算法应用到多智能体环境中时,智能体的动作会使环境改变,单纯地对每个智能体使用DQN算法训练效果并不好。相比之下,VDN旨在学习一种联合动作价值函数Qtot(τ,u),其中τ∈T≡TN为动作-观测对的历史记录,u为联合动作。它代表每个智能体的独立值函数之和,即:
(8)
用Qtot(τ,u)代替式(7)中的Q,可以通过每个智能体的局部值函数得到联合值函数。
为了能够提取出与集中式的策略完全一致的去中心化策略,需确保每个独立智能体Qj的结果最优,即满足下式:
(9)
进一步,在VDN的基础上做出更充分的假设[23],只需要满足如下的单调性:
(10)
QMIX使用一个体系结构来表示Qtot以实现上述单调性,该结构由智能体网络和混合网络构成,如图2(a)所示。将环境的总体状态信息st作为超网络的输入量,输出得到该混合网络的权值与偏置。通过这样的方式,将环境的总体状态信息混入联合状态值函数Qtot(τ,u)中,在集中式的训练中取得更好的全局效果,更好地指导分布式多智能体网络处理整体任务需求下的并行与顺序逻辑关系。
QMIX旨在通过训练使以下损失函数最小:
(11)

本文提出利用QMIX算法来解决多无人机目标侦查问题。QMIX的算法架构如图2所示,将t时刻的多无人机的联合动作ut作用于区域环境,环境状态由st转移至st+1,并给予每个无人机对应的奖励rt,j。st包括目标的侦查情况ynt、多无人机自身位置loct,但是每个无人机在训练结束后的执行过程中只能观测到部分信息ot,j=(dynt,j,loct,j)。

图2 QMIX训练网络框架
首先为每个智能体建立一个Deep Recurrent Q-Learning Network(DRQN)网络,该DRQN网络由输入全连接层、门控循环网络层、输出全连接层构成。输入全连接层采用ReLU激活函数,网络可以表示为:
(12)
其中W1、b1分别为输入层的权重参数和偏置。然后进入门控循环网络(GRU),该网络由更新门和重置门构成,输入为X1,输出表达式为:
(13)
循环更新T次,输出hT,进而输出全连接层,采用softmax激活函数,网络可以表示为:
(14)
其中W3、b3分别为输出层的权重参数和偏置。网络结构如图3所示。

图3 DRQN网络结构图
最后DRQN网络的输出是该智能体每个动作的概率,然后通过ε-greedy算法来选择动作,即以ε的概率进行随机选择,以1-ε的概率使用贪心算法选择最大Q值的动作。将多无人机组成的联合动作ut=(ut,1,ut,2,…,ut,M)与环境进行交互,并将经验存于经验池D=〈st,ut,rt,st+1〉中。
2.3 QMIX训练
通过利用DRQN的经验回放训练网络,DRQN中的门控循环网络对一段时间内的连续动作观测对的信息进行处理,解决了多智能体中部分马尔科夫可观问题。
将每个智能体DRQN网络输出的(Q1(τ1,u1),Q2(τ2,u2),…,QM(τM,uM))送入Mixing网络,该网络可以将部分动作值函数混合为联合动作值函数。设θP为DRQN的评估网络参数,θT为DRQN的目标网络参数,训练时端对端的最小化损失函数为:
(15)
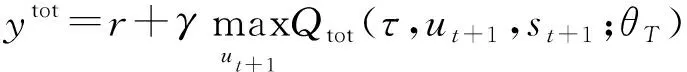
3 实验结果与分析
对所提出的任务分配算法进行仿真验证,并与传统的VDN算法、基于DQN的IQL算法进行对比实验,验证所提算法的有效性。
设定大范围电力系统的区域面积为2.5 km×2.5 km,区域中随机分布着12座电力设施,3架无人机在起点位置出发,且在分布式执行过程中只能感受到距离自身1.5 km的电力设施。无人机飞行速度限定在5 m/s。分别采用本文设计的QMIX算法和传统的VDN、IQL算法对该任务环境进行训练,仿真平台采用的CPU为I7-9700,GPU为RTX2080Ti,内存为16 GB,在OpenAI Gym环境下训练。每个算法训练6000回合,经验池大小设置为50000,采样训练样本大小为32,回报折扣率为0.9,学习率为0.005,ε值为0.05,网络更新速率β为0.01。3种算法的训练过程累计回报如图4所示。
从图4可以看出,QMIX算法在训练开始后回合累计回报开始逐渐升高,并在1300回合左右就完成了收敛,而VDN算法由于其对多智能体问题的表征能力欠缺,因此在2500回合左右才收敛。而IQL算法会导致智能体之间互相影响,智能体难以通过统一的联合动作值函数协同行动,因此难以适应多智能体问题。进一步,所提出的QMIX算法由于采用了协同奖赏函数,可以激发无人机之间的协作能力,仿真结果与轨迹如表1、图5所示。
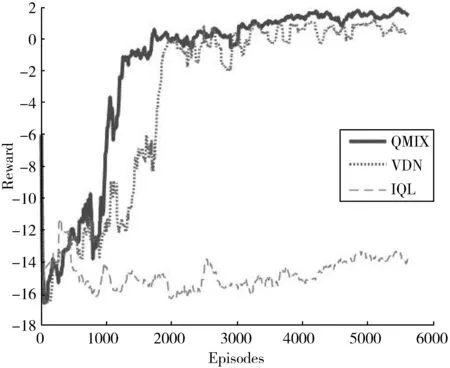
图4 算法训练过程累计回报

表1 QMIX与VDN、IQL算法结果对比

图5 多无人机巡检结果轨迹图
由图5可以看出,3架无人机在获得自身观测量后,各自执行不同电力设施的巡检任务以实现最短时间合作完成整体巡检任务。并且1号、2号无人机在遇到2号电力设施时激发了智能体间协作能力,2架无人机共同协作完成同一目标巡检任务,缩短了任务完成时间,使得任务时间相比于VDN算法缩短了350.4 s。
4 结束语
本文结合多智能体强化学习理论提出了一种基于QMIX的多无人机大规模电力巡检的任务分配算法,仿真实验验证了算法能有效地激发无人机之间的协作能力。在集中式训练、分布式执行的框架下,每架无人机根据自身对环境的观测进行动作选择,实现了多无人机协作快速完成巡检。此外,多架无人机能够同时巡检同一目标,与传统算法相比加快了任务完成速度,提高了智能体间的协作能力。
猜你喜欢
经济技术协作信息(2022年28期)2022-11-24 07:02:51
消费电子(2022年6期)2022-08-25 09:47:40
作文成功之路·小学版(2019年8期)2019-09-18 01:12:04
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
读者(2017年14期)2017-06-27 12:27:06
家庭百事通(2016年3期)2016-03-14 08:07:17
山东青年(2016年3期)2016-02-28 14:25:52
读写算(下)(2016年9期)2016-02-27 08:46:31
电子工业专用设备(2015年4期)2015-05-26 09:10:39
