
人工智能在肝移植中的应用
2022-02-12 03:15梁智星叶林森
临床肝胆病杂志 2022年1期
梁智星, 叶林森, 杨 扬
中山大学附属第三医院 肝脏外科暨肝移植中心, 中山大学器官移植研究所,广东省器官移植研究中心, 广州 510630
医院信息系统的进步极大地增加了医疗机构收集的患者数据量,据估计,2020年全球将产生2314兆字节的医疗数据[1],这为使用数据分析技术实现个性化医疗及改善患者预后提供了可能。然而,如何把庞大的数据转化为可实践的知识仍然是一个重大的挑战,这一点在肝移植领域尤为明显。自 1963年Starzl教授首次将肝移植应用于临床以来,经过半个多世纪的发展和完善,肝移植已成为治疗各种终末期肝病最有效的方法。与其他领域的“单患者”数据分析不同,肝移植通常需要考虑供体和受体“双患者”的特征以及移植过程中的变量,所涉及的大量因素使用传统生物统计学分析显得非常困难。人工智能(artificial intelligence,AI)的核心是通过机器学习算法挖掘大型数据中的隐藏联系,其优势在于能从现有的数据中学习,找到变量之间的新联系并产生预测,相比传统方法更有效地生产预测模型。基于这一优势,越来越多学者将AI方法应用于肝移植领域,尤其是在预后预测和器官分配方面。
1 常用的AI算法
从概念上而言,AI并不新鲜,最早由阿兰·图灵在1937年提出,受限于当时的计算机技术,AI技术的发展曾一度停滞。直到20世纪后期,数据量的爆发性增长和计算能力的提升使得这一领域重新得到关注,自1998年以来,医学AI领域的研究数量成倍增长[2]。在实践中,AI算法通常区分为机器学习(machine learning, ML)和深度学习(deep learning, DL)。
ML可分为监督学习方法(如支持向量机、决策树、随机森林、朴素贝叶斯等算法)和非监督学习方法(如主成分分析)。监督学习即用一部分已知结果的样本训练机器,让其学习输入数据(如患者特征、图像等)与结果(如发生并发症、死亡等)之间的联系,从而预测患者是否发生某一终点事件。非监督学习即是让机器学习数据中的潜在分布或联系,根据样本的相似性进行聚类。ML在医学领域中通常使用的都是监督学习算法[3](表1)。
DL是ML的一个子集,包含人工神经网络(artificial neural networks, ANN)、卷层神经网络(convolutional neural networks, CNN)、 循环神经网络(recurrent neural networks, RNN)等算法模型。神经网络是模拟大脑神经元组成的仿生模型,能够挖掘数据中复杂的非线性关系,允许更复杂的监督和无监督学习任务(表1)。与其他ML算法相比,DL特别适用于大规模复杂或高维度的数据,能够处理一些环境信息十分复杂、知识背景不清楚和推理规则不明确的问题[4],通常用于影像识别、病理诊断、预后预测等。
纵观当前AI算法在肝移植领域的应用主要有以下2个方面:(1)缓和日趋严重的器官供需矛盾问题——使用分类技术评估供肝,减少经验性误判导致的供肝废弃,扩大供体池;(2)制订最佳的器官分配方案,避免因分配不佳导致的不良预后,提升供体池的整体获益,提高捐献器官的有效利用率及移植患者生存获益——使用回归模型预测移植肝存活及受体预后。利用AI算法在复杂和高维度数据中的优势,扩大供体池,提高供受体匹配成功率,为肝移植患者长期生存提供有力支持。
2 供肝评估
移植肝脂肪变性(hepatic steatosis,HS)被认为是影响移植物功能的最重要因素之一[5],移植肝组织的病理学活检是评估HS的金标准。然而病理检查通常在器官获取后进行,其结果一般在移植手术前难以获得,因此供肝的HS评估常依赖于获取人员视觉和触觉上的经验性判断。然而有研究[6]表明超过90%的器官获取人员对供肝移植物衰竭发生风险的预测存在很大差异,特别是低估了高风险供肝的移植物衰竭发生风险,说明依赖经验性的判断是不够准确的。
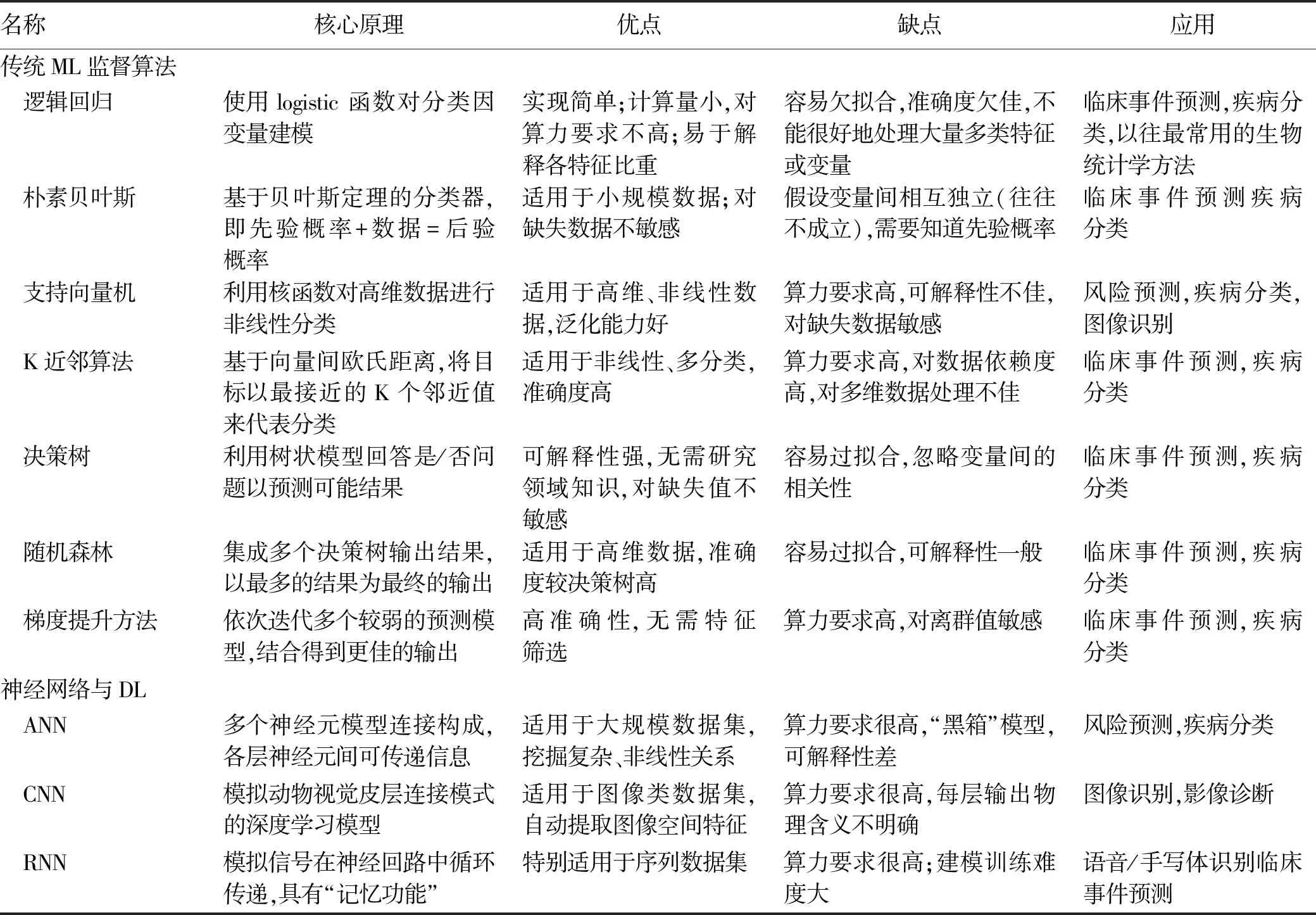
表1 常用的AI算法
Kuppili等[7]利用极限学习机算法构建的脂肪肝诊断模型,能够根据肝脏超声图像快速诊断HS,准确率高达96.75%。而Byra等[8]提出的CNN模型能更进一步地从超声图像中自动评估HS的程度。此外,支持向量机算法[9]还能够根据数字化的病理图像对HS进行自动分类,并能以高准确率(≥95%)区分大泡性和小泡性HS。Moccia等[10]和Cesaretti等[11]更是创造性地使用手机拍摄的供肝图像进行半监督训练,取得了88%的准确度、95%的灵敏度和81%的特异度,实现了在手术室快速评估供肝HS,为评估HS提供了一个全新的视野。这些研究表明,AI算法在供肝HS评估中表现出良好的性能,使获取术中的供肝客观评估成为可能。
临床供肝评估是一个动态的过程,涉及供体情况、获取及转运过程等多个变量,这是一个随时间变化、非常复杂的多维度非线性关系。传统的生物统计方法需要假设解释变量和结果变量之间是独立的和线性的关系,并且无法纳入大量的临床变量进行分析,而这正是AI算法的优势。笔者团队利用ML算法构建供肝评估模型,纳入供体基本特征、获取前各项实验室检查结果、获取/移植手术特征以及受体基本特征共67项变量数据,较传统生物统计学方法具有更优的预测评估效能(AUC:0.85 vs 0.73; NRI=0.368 5, 95%CI: 0.321 0~0.415 9,P<0.001),相关经验正在进一步总结当中。除了对供肝客观、全面、精准的评估,AI技术还有望应用于供肝能否劈离的精准识别、活体肝移植供肝分割容量的判断等方面,为外科医生的临床决策提供支持。
3 器官分配
目前在世界大部分地区,对等待移植名单患者进行优先排序的金标准仍然是终末期肝病模型,但这种基于“病重患者优先”原则的分配政策存在一定缺陷[12]。肝移植中最佳器官分配的关键是准确预测特定供受体组合的移植结果,因此一个能最大限度考虑到所有供体和受体因素的可重复预测模型,无疑能最大限度地提高现有供体池的整体效益。目前已有许多学者尝试利用AI技术建立器官分配模型[13-20]。
一项西班牙多中心的回顾性研究[13]使用ANN算法提出了一个创新的供体-受体匹配模型,其纳入了1003对肝移植供体-受体,以及供体、受体和移植过程中的64个变量信息,准确预测移植后3个月的移植物存活率(AUC=0.81)和移植物丢失率(AUC=0.82),为临床决策提供参考,以使肝脏分配更加公平、高效。此外,Bertsimas等[18]使用贝叶斯最优分类器预测候选者在移植等待名单上的3个月病死率或除名风险,开发了病死率优化预测模型(optimized prediction of mortality, OPOM)。OPOM可以根据疾病的严重程度,更准确和客观地确定等待移植名单患者的优先次序,使器官的分配更加公平。在肝脏模拟分配中,与MELD相比,OPOM分配可使等待移植名单上的死亡人数大幅减少418例。
器官分配的目的是最大程度地降低移植物丢失的风险以及提高移植物存活的可能性,需要对特定的供-受体分配进行精准的预测。要清楚的意识到,在未来利用AI技术根据供体来源(脑死亡、循环死亡、活体供肝)和受体原发病(良性终末期肝病、肝恶性肿瘤)建立分组预测模型,指导肝移植临床决策,有望实现脑死亡器官捐献/心脏死亡器官捐献整肝供肝的精准分配。另一方面,笔者单位是全国最大的劈离式肝移植中心,利用AI技术在劈离方式、劈离后供体分配等方面实现精准分配,建立本中心的数据库,为国家的器官分配政策提供参考。
4 移植肝存活和预后预测
AI技术在评估移植肝存活及患者预后方面同样发挥着巨大作用,使用ML和神经网络算法构建的预测模型可以更准确地预测移植预后[21-34]。Liu等[22]根据患者的术前生理测量值,设计一个预测模型来预测术后30 d内的患者生存率,该研究利用随机森林算法评估特征的重要性,结果显示,年龄、BMI、白细胞及淋巴细胞数量、血小板、国际标准化比值以及钠镁离子浓度是移植术后早期生存的重要影响因素。Hoot等[24]利用器官共享联系网络的数据库建立贝叶斯模型预测早期移植物存活率,通过对29个移植前变量进行学习分析,该模型90 d移植物存活的预测准确度可达91%。另一项大型研究[25]回顾性分析了62 294例肝移植患者术后10年内的生存情况,从超过600个变量信息中筛选出97个预测因子构建模型,结果显示,使用ANN算法构建的预测模型对移植术后远期生存的预测性能明显优于传统的Cox回归模型。
急性肾损伤、移植后糖尿病(post-transplant diabetes mellitus, PTDM)、皮肤癌等是移植术后的重要并发症,与移植物丢失及患者生存相关。梯度提升机[27]对各阶段的急性肾损伤预测效能明显优于其他常用的机器学习方法(AUC=0.90),相比之下,传统的生物统计学方法logistic回归的AUC为0.61。Bhat等[29]使用多种机器学习方法发现高龄、男性和肥胖的受者是PTDM的高危因素,以西罗莫司为主要免疫抑制剂的患者术后1年内发生PTDM的风险较他克莫司高33%,提示了对这部分受者应该采取更积极的预防策略和更密切的随访。Jain等[33]建立的机器学习模型能够准确预测肝移植术后心血管事件的发生率和病死率,帮助临床医生筛选出可能发生心血管不良事件的移植受者。
笔者团队率先在基于放射学特征、放射组学特征、临床变量机器组合构建XGBoost算法模型,以及基于医学图像识别构建CNN模型,能够在术前准确识别肝细胞癌患者肿瘤微血管侵犯(AUC分别为0.952、0.980),为预测肝癌患者术后复发提供参考[35]。随着肝移植病例数据量的不断增长、影像学和病理学等多学科评估的加入,以及前瞻性研究的验证,AI预测模型将更能发挥出其在处理高维度、多种类数据方面的优势,最终真正应用到临床诊疗实践当中,为肝移植患者提供更好的生存获益。
5 AI的局限性
尽管许多研究已经证明AI算法模型具有更佳的预测作用,但正如其发展历史那样,AI的应用极依赖于高质量的数据库。事实上,AI算法并非总能得出比传统生物统计学方法(如线性回归、logistic回归等)更好的结果[36],只有当数据集庞大且各变量间隐含非线性关系时,AI算法的表现才能达到预期,这一限制在肝移植领域更为明显。尽管独特的“双患者”模式能够提供更多的临床资料信息,但单中心的移植病例数量仍远少于其他疾病,这在一定程度上局限了AI模型的准确性与可信度。多中心的合作有望弥补这一缺陷,但各中心在数据产生、收集以及分析过程中采取策略的不同,导致了部分特征的数据缺失,这对于某些AI算法来说可能是致命的。
此外,严谨的研究设计、数据预处理策略、模型的选择及该模型与临床研究的适配性都是影响AI模型的关键因素,某些类型的AI模型可能更适合于特定类型的数据,比如CNN适用于图像识别、RNN适用于有时序先后顺序的数据。模型构建的过程中还应该注意不要让模型与训练数据过度拟合,这是AI算法特别是神经网络最容易发生的错误,模型能否泛化应用要比数据拟合更为重要。AI技术的另一大挑战源于其本身的不透明性,AI算法的高精确度可能是以失去对工作原理的可解释性为代价,尽管已有研究[37]尝试使模型更具解释性,但算法在输入数据-输出结果的学习过程仍难以被完全理解,因此AI经常被认为是“黑箱”模型。这也许是AI技术真正应用到临床决策的最后障碍——当部分的决定权从人类手中移交给机器算法时,患者及其临床医生对算法的可接受性和信任程度。
6 展望
肝移植的过程通常产生大量的供-受体数据信息,这与AI技术依赖于庞大数据的特性尤为匹配。比传统方法更为精准的AI预测模型,能够帮助临床医生采取干预来改善患者的预后,比如对脂肪变性供肝缩短特定的缺血时间、对移植术后肝癌复发高风险的患者采取预防性综合治疗等。5G网络与AI技术的结合还有望实现供肝运输过程中的在线实时评估、实时分配,更加公平、高效地选择最优受体,提高现有供体池的整体效益。随着AI技术在肝移植领域的广泛应用,基于AI算法构建临床模型,实现对器官的公平分配、对移植术后生存和预后的预测,成为帮助临床医生及患者作出关键决策的宝贵工具,使外科医生做出更多基于证据的决策,并帮助患者了解接受特定肝移植的风险/效益比,更好地为肝移植患者服务。
利益冲突声明:所有作者均声明不存在利益冲突。
作者贡献声明:梁智星负责撰写论文;叶林森负责修改论文;杨扬负责拟定写作思路,指导撰写文章并最后定稿。
猜你喜欢
传染病信息(2022年3期)2022-07-15
中国典型病例大全(2022年9期)2022-04-19
昆明医科大学学报(2022年2期)2022-03-29
中国听力语言康复科学杂志(2021年6期)2021-12-21
华人时刊(2020年21期)2021-01-14
法制博览(2018年1期)2018-02-24
职工法律天地·下半月(2016年6期)2017-05-24
中国实用医药(2016年29期)2016-12-26
中国经济周刊(2016年18期)2016-05-14
浙江中医杂志(2004年3期)2004-11-20
