
基于弹性融合的人群密度估算技术的应用
2022-02-09 02:34曹思聪
沈阳师范大学学报(自然科学版) 2022年5期
曹 思 聪
(中国人民解放军32683部队, 沈阳 110001)
0 引 言
人群密度检测被越来越多的人所关注,尤其是近2年全球新冠肺炎疫情形势异常严峻,按照国家防疫要求,很多人口聚集的场所要求人口密度不得超过1个固定的数值。在拥挤的人群中,由于彼此的遮挡、视角扭曲、尺度变化和人员密度变化等因素的影响,依据输入图像准确计算出人群的密度是一项极具挑战性的任务。
针对该问题,学者提出了许多人群计数算法。早期方法[1]采用检测式框架,在视频序列的2个连续帧上扫描检测器,根据增强的运动特征和外观来对行人数量进行估计;文献[2]使用了类似的基于检测的框架进行行人计数;在基于检测的群组计数方法中,人们通常假设群组由单个实体组成,这些实体可以被一些给定的检测器检测[3-4]。这种基于检测的方法的局限性在于,集群环境中或密集人群中遮挡会显著影响检测器的性能,从而影响最终的估计精度。
人群计数最广泛使用的方法是特征回归法[5-6],主要操作步骤为:从图像中将前景分割出来;在前景中提取需要的特征,例如遮盖人群[7-8]、边缘特征[9]或纹理特征[10];使用回归函数估计人群中人的数量。线性函数[11]和分段线性函数是相对简单的模型,且性能较好。其他更有效的方法有岭回归(RR)[13]、高斯回归[14]和神经网络(NN)[15]等。也有一些文献侧重于根据静止的图像计算人群中的人数[16-18]。
本研究提出了一种新的深度检测网络,利用YOLOv3网络,并将结果密度图估计融合,最后进行了参数调优,结果表明该方法能取得较好的效果。
1 目标检测和融合策略
在深度学习中用于图像目标检测的网络有很多,如SPPNet,Fast R-CNN,Faster R-CNN,YOLO,SSD等。YOLO网络借鉴了GoogLe Net网络的结构,如图1所示。YOLOv3是在YOLOv1和YOLOv2的基础上,在保持检测效率优势的前提下,提升了预测准确度,尤其是加强了对小物体和遮挡物的识别能力。

图1 YOLO网络结构图
YOLOv3设计了一个新的网络结构Darknet-19,它包含19个卷积层,5个池化层。如图1网络结构所示,它通过这个新的分类网络来进行特征的提取,YOLOv3在检测的速度和精度上都有所提升。计算公式如下:
其中:a代表每个神经元的激活;n代表一个位置上临近特征图的数目;N代表特征图总数;k代表预设的超参数。由此可见,这种方法是多个特征图在同一位置上的归一化,属于特征图之间的局部归一化,可以小幅度提高识别效率和准确度。另外,还使用了Dropout技术,这样一些神经元不再参与前向传播与反向传播,每次输入一个样本都相当于网络对新结构进行了尝试,通过共享权值,降低了神经元的计算复杂度,有效降低过拟合。
2 人群密度检测设计和实践
2.1 融合策略
项目综合了2种主流人群密度检测方法。第1种基于目标检测的方法,设计了头部检测器(head)与行人检测器(person)2个检测器,其特点是在低密度场景下有着较高的准确率,但是高密度场景漏检率较高。第2种方法基于密度图生成的人群计数,其特点是在高密度场景下有着较高的准确率,但是低密度场景准确度较低。本文提出的方法融合上述2种方案,实现了更高精度的人群计数。具体融合策略如图2所示。

图2 融合策略
2.2 项目结构图实验方法
项目采用百度的paddle框架,利用百度提供的编辑器codelab进行实验,采用python语言。
1)参数调整
采用Adam优化器对一些参数进行了调整。学习率策略:lr=1e-4;权重衰减:L2Decay(1e-4);loss function:L1 smooth(huber)更加鲁棒,兼有L1和L2的优点;训练时长:200epochs左右;Momentum优化器base_lr=1e-3;训练时长:90 000iters左右;Max_box:505,其余参数不变。
2)数据集处理
根据对数据集分析可知图片标注共分2种情况:人身的框标注1 253张,人头的点标注747张。选择对这2种标注分别建立人身识别器(person-人身框标注)和人头识别器(head-人头点标注),分开训练。这里对于人头点标记,涉及由点变框,并且要框住头,而不同图片中头的大小是不一样的。因此,提出一种针对图片大小的点变框的方法:根据图片分辨率的不同建立不同的人头大小,经检验,这种方法比常规的统一大小变框方法可以提升0.1~0.15的成绩。通过可视化数据发现,数据集有主要分为3种尺寸的图片:1)大尺寸img_shape[0]>1 000,采用43×43的anchor;2)1 000>中尺寸img_shape[0]>700,采用32×32的anchor;3)小尺寸img_shape[0]<700,采用20×20的anchor。针对以上3种尺寸的图片设计了不同尺度的头部标记anchor。
2.3 实验结果
用近一个星期的时间训练了多个person & head检测器,然后对实验结果进行加权平均融合(weighted average fusion)。通过数据分析,决定用4个结果较好的person & head检测器融合后的结果进行融合,融合的策略为加权平均融合,权重为1-score。基本思想是通过融合多个弱检测器的结果,得到一个有更低的bias和variance的结果。加权融合之后得分为0.117 82,比起最优的单个head+person的结果0.123 87提升了5%。图3和图4是0~30人和50~450人的预测结果。

图3 0~30人的2种网络预测人数

图4 50~450人的2种网络预测人数
经过训练后的单独的人身检测器在测试集上的正确率为65.32%,单独的人头检测器在测试集上的正确率为80.72%,双检测器在测试集上的正确率为83.82%,crowdnet在测试集上的正确率为87.84%。从理论上讲,单纯的检测模型在低密度人群下因为目标之间距离大,相互遮掩少会有更好的效果,对高密度相互遮掩情况效果较差;而密度图方法,因为使用高斯核生成密度图时使用的假设是人头的大小=相邻k个人头的平均距离,即在高密度人群下会更准,而在低密度人群彼此相隔较远时误差较大。实际效果如图5和图6所示。

图5 0~50人的2种网络预测人数

图6 50~250人的2种网络预测人数
2.4 实验分析
通过上述可视化分析,发现YOLOv3对低密度人群结果预测较好,而对高密度人群预测时容易出现漏检。因此,在操作中,预测人数大于60人时,取密度图的预测结果加以补偿;预测时当预测人数为15~60人时,取YOLO和密度图预测的最大值;当预测人数为0~15人时,用YOLO自身的预测结果。
密度图的损失来自于: 1)将高斯核叠加在GT的点标注上产生的损失; 2)在生成密度图时,提取特征的网络进行了降采样,大小为原图的1/8,部分小目标语义信息在高层特征图中已经丢失。
故在不改变模型结构的情况下使用以下融合策略:1)弹性融合策略(elastic fusion strategy);2)以head+person检测结果为基准,其中“+”表示补偿值,补偿密度图生成的损失,其补偿值通过训练集密度图和GT的差距进行估计;Max(crowdnet,head+person)表示取YOLO和密度图预测的最大值;only use head+person用YOLO自己预测结果。人口数量和采用的策略关系见表1。
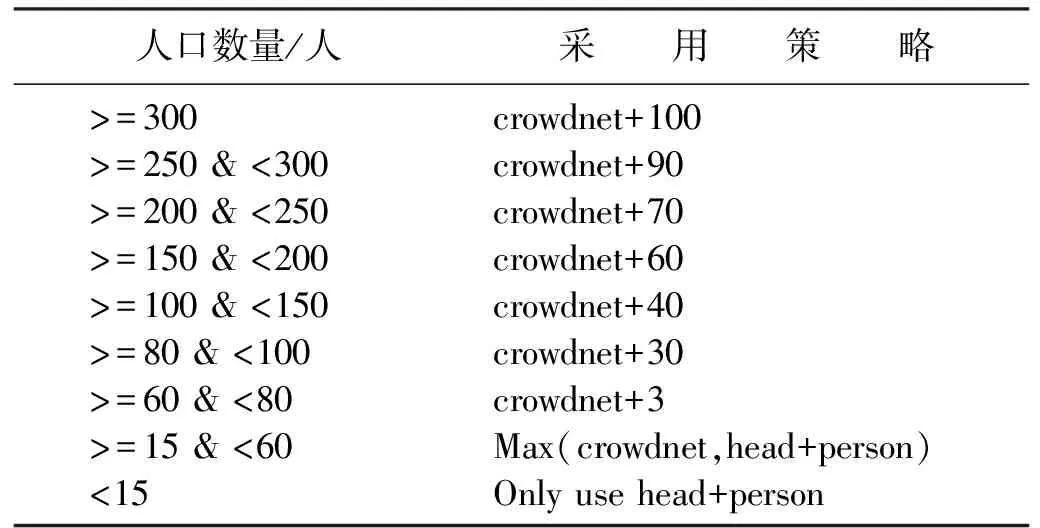
表1 人口数量和采用的策略关系
3 结 语
不同场景下进行人口密度统计需要使用不同的方法。实际操作中可以参考经典的方法进行统计,但要根据具体的场景对经典方法进行优化。本项目中遇到了密度图生成crowdnet训练中可能会出现内存溢出的问题,解决方案是减小batchsize,使用momentum优化器。未来还需要作进一步研究,如使用精度更高的模型、使用anchor框加速收敛、根据场景的不同训练不同的检测器等。
猜你喜欢
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
恋爱婚姻家庭(2020年27期)2020-10-09
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
火力与指挥控制(2018年10期)2018-11-13
百花洲(2018年1期)2018-02-07
瞭望东方周刊(2017年45期)2017-12-08
中国交通信息化(2017年9期)2017-06-06
电子制作(2017年10期)2017-04-18
