
融合字词语义信息的猕猴桃种植领域命名实体识别研究
2022-02-08 13:31李书琴张明美
农业机械学报 2022年12期
李书琴 张明美 刘 斌
(西北农林科技大学信息工程学院, 陕西杨凌 712100)
0 引言
受病虫害的侵害和种植人员对种植技术掌握不全面的影响,我国猕猴桃果实品质整体水平不高[1]。基于知识图谱的猕猴桃种植领域问答系统利用知识图谱可以准确快速回答猕猴桃种植人员的专业问题,而命名实体识别(Named entity recognition,NER)是知识图谱构建任务中重要且关键的步骤[2],因此,如何准确快速识别出猕猴桃种植领域命名实体对于确保猕猴桃种植业健康发展具有重要作用。
早期基于统计机器学习的条件随机场(Conditional random field,CRF)方法将实体识别看作序列标注问题,充分利用了内部和上下文信息,在农业领域得到广泛应用[3-4]。但该方法过于依赖人工特征,特征的设计需要很多专家知识,特征选择的好坏更是直接影响到命名实体识别系统的性能[5]。近年来,基于深度学习的方法在NER任务中取得了显著效果。深度学习可以自动学习文本特征,从而摆脱对人工特征的依赖,其中,卷积神经网络、循环神经网络以及注意力机制等常用的深度学习方法与机器学习联合使用的方式已经被成功地应用到农业垂直领域的命名实体识别任务中[6-7]。
但以上方法在处理猕猴桃种植领域文本时,需要先进行中文分词(Chinese word split,CWS),CWS的准确性直接影响到中文命名实体识别效果。且猕猴桃种植领域命名实体识别任务主要关注猕猴桃种植文本中的猕猴桃品种、病虫害、危害部位、药剂、种植技术等实体,由于猕猴桃种植领域文本中涉及的病虫害、药剂及种植技术等多种实体术语专业性较强,CWS容易产生大量的未登录词(Out-of-vocabulary,OOV),从而影响模型识别效果。
MENG等[8]在中文自然语言处理中通过大量的实验表明,“字”的表现总是优于“词”的表现。一些研究者[5,9-11]为了避免CWS错误,直接使用基于word2vec等词向量训练模型训练的字向量作为嵌入层。但以上词向量训练模型在单个字符上语义表征不充分导致模型识别性能欠佳。
BERT[12]等预训练语言模型采用双向的Transformer编码器对大规模语料进行训练,可以得到表征能力更强的字向量[13]。已有研究人员将预训练语言模型引入农林业领域命名实体识别任务中[14-17]。但实体识别任务与其它自然语言处理任务不同的是,大部分实体属于词,词中蕴含着丰富的实体信息,而字符向量却缺少该类信息。ZHANG等[18]提出的Lattice-LSTM模型,将每个字符匹配到的单词通过注意力机制进行加权求和作为字符表示,但由于每个字符对应的词数目不同,无法分批处理,导致识别速度较慢,且由于模型结构复杂,无法迁移到其它网络结构中。针对该问题,LIU等[19]提出了4种不同的策略将词进行固定数目的编码,使其可以分批处理从而适应各种网络结构。MA等[20]提出了一个更为简单高效的SoftLexicon模型,利用4个词集来表示每个字符在词中的位置,同时采用词的频率作为权重对词集进行压缩,简化了序列建模结构,提高了模型计算效率。但词集内的词语义信息往往是相似的,上述研究忽略了不同词对于当前字符的重要程度,词集中包含的词信息没有得到充分利用。
基于以上问题和研究,本文提出一种融合字词语义信息的猕猴桃种植实体识别方法。首先采用多头自注意力(Multiple self-attention mechanisms,MHA)[21]来调整SoftLexicon词集中每个词语的权重,缓解静态词频作为权重无法学习到更为重要的词特征问题;然后采用注意力机制自动获取每个词集的重要程度,增强重要词集信息的同时抑制不重要词集信息;最后融合词集表示和BERT的字符表示作为命名实体识别任务的嵌入层。同时使用双向门控循环网络(Bi-directional gated recurrent unit,BiGRU)进一步提取字符之间的关系特征,最终使用CRF得到全局最优标签序列。
1 融合字词语义信息的实体识别模型
模型主要由3部分构成,嵌入层、BiGRU编码层以及CRF层。嵌入层使用融合字词语义信息的表示,字符语义信息使用BERT预训练模型生成的字符表示,词语义信息使用注意力加权得到的词集向量表示。编码层采用BiGRU网络,最后通过CRF进行标签推理,获取全局最优标签序列。模型整体结构如图1所示。
1.1 融合字词语义信息的嵌入层
模型嵌入层融合了基于改进的SoftLexicon模型生成的词向量信息和采用BERT预训练语言模型生成的字符向量信息。

图1 融合字词语义信息的猕猴桃种植实体识别模型Fig.1 Kiwifruit planting entity recognition model integrating character and word information fusion
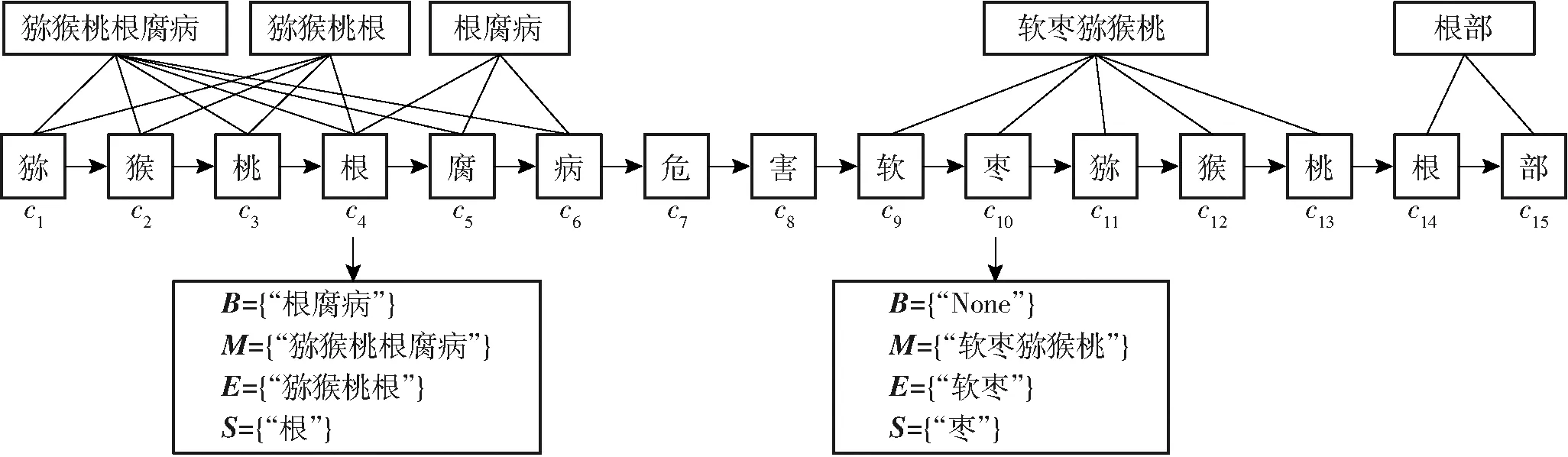
图2 词组匹配分类Fig.2 Word matching classification
词向量由4个词集组成,对于输入文本序列S=(c1,c2,…,cT),将序列中相邻的字符在词典中匹配词组,并按照每个字符ci在词组中的不同位置,分别用标签为B、M、E、S的4个集合来记录,集合B(ci)表示字符ci在开头且长度大于1的词集合,集合M(ci)表示字符ci在中间位置且长度大于1的词集合,集合E(ci)表示字符ci在结尾且长度大于1的词集合,集合S(ci)表示单个字符ci,如果集合为空,则用“None”来填补。如图2所示,输入句子“猕猴桃根腐病危害软枣猕猴桃根部”,以字符c4为例,因为该字符出现在“根腐病”的开头,“猕猴桃根腐病”的中间,“猕猴桃根”的结尾,所以B(c4)为{“根腐病”},M(c4)为{“猕猴桃根腐病”},E(c4)为{“猕猴桃根”},S(c4)则为{“根”}。
获得每个字符对应的B、M、E、S标签词集后,需要对每个词集进行压缩得到4个标签的词向量。原始的SoftLexicon模型只使用词频z(w),即每个词w在词典中出现的次数作为权重进行压缩,同时对于所有词集中不满足最大长度lmax的词集用0进行填充,并记录该词的z(w)为1。词集向量B的具体计算方式(M、E、S同理)为
(1)

(2)
式中ew(w)——词w对应的词向量
vi——词集向量
对于要识别的猕猴桃种植领域文本中的实体,仅使用词频作为权重时,容易出现准确率较低但召回率较高的情况,例如针对“果实软腐病”的“果”字,“果实软腐病”和“果实”均属于B集合,“果实软腐病”中字符“果”的正确标签为“B-DIS”,但由于“果实”在词典中出现的频率较高且没有使用注意力等方式计算权重,“果实软腐病”中的字符“果”被标记为“B-PART”,导致精确率较低但召回率较高。针对以上问题,本文采用MHA机制动态地调整每个词语权重,学习到更为重要的特征后再进行压缩,词集B的具体计算公式(M、E、S同理)为
(3)
MHA(Q,K,V)=Concat(head1,head2,…,headn)Wo
(4)
headj=Attention(Qj,Kj,Vj)
(5)
(6)
式中 MHA(Q,K,V)——多头注意力输出
head——注意力头
Concat——合并操作
Wo——多头自注意力权重矩阵
Attention(Qj,Kj,Vj)——当前词在自注意力层的输出
Qj、Kj、Vj—— 查询向量、键向量、值向量
上述方式对每个词集中不同词进行了权重调整,但不同词集之间的重要程度没有被区分,使用4个词集的目的是区分字符在词组中的不同位置,但当部分词集压缩之后的结果非常相似时,容易导致后续步骤不能明显区分字符ci在所有词中所处的4种位置,使用4个词集的优势也相对被削弱。因此,为了进一步考虑各个词集的不同重要程度,本文采用注意力机制自动获取每个词集的重要程度,根据不同的重要程度增强重要的词集信息并抑制用处不大的词集信息,充分发挥4个词集的优势。注意力权重ai的计算公式为
(7)
其中
(8)
式中Vi——4个词集合并后的矩阵,维度为4×dw
W——权重矩阵,维度d×dw
U——权重矩阵,维度1×dw
dw——词向量维度
最终得到重要度矩阵ai的维度为1×4,4个值分别代表4个词集的重要程度,使用该向量对4个词集进行重要度加权后可以得到更有说服力的词集表示。
为了避免本文模型受太多分词影响,在最终的嵌入层表示中融入了特征向量xBERT,该向量是BERT预训练语言模型在大规模语料下通过学习上下文语义信息得到的,能够表征字的多义性,增强句子的语义表示,更好地挖掘结构复杂的猕猴桃种植领域命名实体特征信息。
将4个词集表示和字符向量连接后,得到字符的最终表示为
(9)
式中ai1、ai2、ai3、ai4——对应字符ci的4个词集B、M、E、S的重要程度
1.2 BiGRU编码层
编码层将融合字词语义信息的嵌入层最终表示序列作为输入,对序列中的字与字之间的关系进行特征提取。采用GRU作为特征提取层,该网络与长短期记忆网络(Long short-term memory,LSTM)类似,与LSTM的区别是不再采用单元状态记录或传输信息,将遗忘门和输入门合并为一个单一的更新门,用隐藏状态控制信息传输和记录,用更新门和重置门控制隐藏层状态的最终输出,用隐藏状态控制信息传输和记录。
但单向的GRU只能获取目标词的前文信息。例如,针对猕猴桃病害实体“猕猴桃叶斑病”,目标词为“斑”,GRU只能提取到“斑”的前一个字“叶”的特征,提取不到后面“病”的特征。而目标词的上下文信息均会影响到对目标词的预测,进而影响命名实体的识别性能。因此,为了精确识别猕猴桃种植领域命名实体,本文采用双向GRU(BiGRU)网络模型。
BiGRU的输出由正向GRU和反向GRU组成,对于输入文本序列X=(x1,x2,…,xt,…,xn),xt是t时刻的输入向量,正向GRU输出计算公式为
zt=σ(WZ[ht-1,xt])
(10)
rt=σ(Wr[ht-1,xt])
(11)
(12)
(13)
式中zt——更新门rt——重置门
σ——sigmoid函数

WZ、Wr——权重矩阵
ht、ht-1——t和t-1时刻的输出

1.3 CRF层
猕猴桃种植领域命名实体标签推理的任务是对序列文本中每个字符进行分类,类别包括B-VAR、M-DIS、O等。通过BiGRU编码层得到的特征向量是相互独立的,直接输入到全连接层中判定每个字符的标签时无法学习到文本标签间的约束关系,如B-VAR后面不可能是M-DIS。采用CRF全局优化来学习猕猴桃种植领域文本序列标签间的约束关系。
考虑到标签之间的约束关系,CRF引入一个转移矩阵A。对于输入句子X来说,输出标签序列y={y1,y2,…,yn}的得分定义为
(14)
式中Ni,yi——第i个字是标签yi的概率
Ayi,yi+1——标签转移概率
score(X,y)——输出序列得分
对所有输出序列y计算得分,采用Viterb动态规划算法得到猕猴桃种植领域文本序列标签的最优序列,进而对命名实体标签进行推理和预测。
2 实验设置
2.1 数据集
本文实验数据主要是通过爬虫框架,抓取百度百科和360百科网站有关猕猴桃种植的语料,少量数据摘取自与猕猴桃种植领域相关的知网文献和书籍。对获取的句子进行清洗和去重后做人工标注,得到12 477个猕猴桃种植领域相关的句子作为最终实验数据集。
猕猴桃种植领域实体共7类,类别定义如表1所示。

表1 猕猴桃种植领域实体类别Tab.1 Kiwifruit planting field entity category
2.2 数据标注
采用BMESO标注策略:B(Begin)表示实体开始,M(Median)表示中间部分,E(End)表示结尾部分,S(Single)表示单个字符的实体,O(Other)表示其它非命名实体字符,并在最后加上实体类别。如“桑/B-PEST白/M-PEST蚧/E-PEST的/O主/O要/O危/O害/O部/O位/O是/O叶/B-PART片/E-PART”。在训练时,添加了保证训练长度一致的PAD占位符,同时用[CLS]和[SEP]标记句子的首部和尾部。
2.3 实验数据
将自建的实验数据按7∶1∶2划分为训练集、验证集和测试集,训练集8 734条,验证集1 248条,测试集2 495条,数据规模如表2所示。

表2 实验数据规模Tab.2 Experimental data scale
数据集中包含实体24 740个,其中品种5 364个、病害887个、虫害1 784个、部位7 985个、药剂1 314个、区域7 201个、气候205个。不同类型实体在训练集、验证集和测试集中的统计如表3所示。

表3 不同类别实体数据规模Tab.3 Data size of different types of entities
2.4 实验环境及模型参数
实验环境:操作系统Ubuntu 16.04,CUDA 9.2,cudnn 7.6.5;4个E5-2620 v4 @2.10 GHz的CPU,一个GTX TITAN X GPU;内存94 GB,显存12 GB;编译环境为Python 3.6.3和PyTorch 1.8.1。
本文实验使用Glove无监督模型在大规模猕猴桃种植语料下训练得到的词典。模型使用Adam优化算法进行参数调整,最大迭代次数为50,选取其中最优结果作为最终实验结果。为了与其它方法对比,本文模型同样采用单层BiGRU网络。具体参数设置如表4所示。

表4 模型参数设置Tab.4 Parameter setting of model
2.5 评价指标
命名实体识别的评价标准有精确率(Precision,P)、召回率(Recall,R)和F1值(F-measure)。
3 实验结果与分析
3.1 不同模型实体识别结果对比
为了验证本文模型在猕猴桃种植领域的命名实体识别效果,在同一实验环境下,使用不同模型进行对比实验,对比模型包括:BiLSTM-CRF模型[22]、Lattice-LSTM模型[18]、WC-LSTM模型[19]、SoftLexicon模型[20]和BERT-BiLSTM-CRF模型[23],6组实验结果如表5所示。
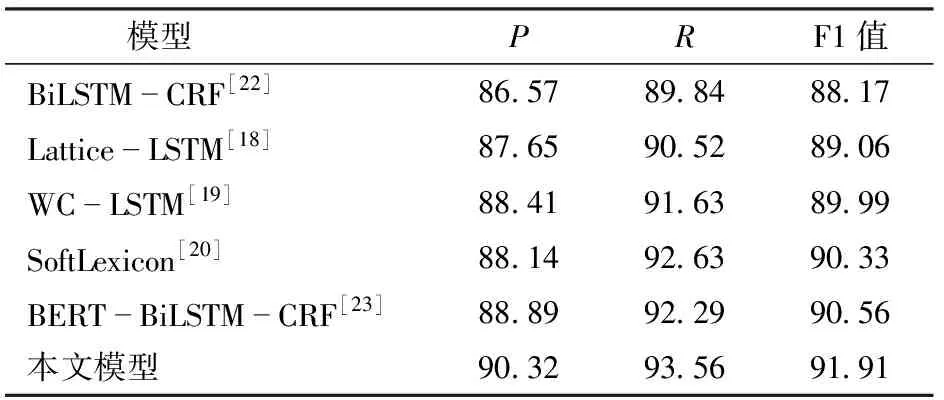
表5 不同模型实体识别结果Tab.5 Entity recognition results of different models %
本文BiLSTM-CRF模型使用Glove无监督模型训练得到的字向量作为嵌入层,然后将其输入到BiLSTM-CRF中进行序列标注,虽然Glove模型得到的字向量能够在一定程度上捕捉到字的一些语义特性,但识别的F1值只有88.17%,识别效果不佳。Lattice-LSTM模型使用注意力机制对当前字符匹配到的词进行加权求和,显著提高了识别效果,F1值提高0.89个百分点,说明引入外部词汇可以有效提高猕猴桃种植领域命名实体识别性能。WC-LSTM模型对当前字符所有匹配到的词采用自注意力编码生成权重向量后,与字向量直接拼接得到最终的字符表示,序列编码依旧使用BiLSTM-CRF结构,F1值高达89.99%。SoftLexicon模型为了简化模型结构,在嵌入层使用词频代替注意力加权的方式,同时加入了表示当前字符在词不同位置的4个词集标签,将压缩得到的4个词集向量和字符向量进行拼接得到最终字符表示,与使用注意力加权的WC-LSTM模型相比,F1值提高0.34个百分点,说明引入4种词集信息可以有效提高文本命名实体的识别性能。BERT-BiLSTM-CRF模型只使用BERT预训练增强的字符向量作为嵌入层,F1值高达90.56%,与使用Glove模型字向量作为嵌入层相比,F1值提高2.39个百分点,说明BERT预训练模型可以学习到更全面的字符特征。
本文模型采用MHA和Attention对词和词集加权,将得到的词集向量与BERT预训练语言模型得到字符向量融合后作为字符的最终表示,并使用BiGRU进行序列编码,CRF模型进行标签推理,实验结果表明,本文模型的F1值达91.91%,相较于其它模型,本文模型在猕猴桃种植领域命名实体识别任务中表现更加出色。
3.2 MHA和Attention影响对比实验
为了验证添加MHA调整词权重和Attention获取词集重要程度对模型的影响,本文对添加MHA和Attention进行对比实验,实验结果如表6所示。

表6 MHA和Attention影响实验结果Tab.6 MHA and Attention affected experiment results %
从表6可以看出,在SoftLexicon模型中添加MHA对词集中的词进行权重调整时,F1值提高0.52个百分点;当在SoftLexicon模型中添加Attention调整词集取值时,F1值提高0.25个百分点,同时添加两者时,精确率、召回率和F1值均有显著提高,与未添加任何机制的SoftLexicon模型相比,F1值总体提高0.82个百分点,比单独添加MHA或Attention机制效果都好。因此,使用MHA对词向量进行加权和使用Attention对词集向量进行调整可以提升模型性能,两者同时使用可以进一步提升猕猴桃种植领域命名实体识别性能。
3.3 字词融合对比实验
为了验证使用BERT预训练语言模型增强字符表示和引入词集向量作为外部词汇对于模型的提升效果,分别使用Glove字符表示和词集向量融合表示、基于BERT的字符增强表示以及BERT字符增强和词集向量融合的表示作为嵌入,其中SoftLexicon表示以Glove字符表示和词集向量融合表示作为嵌入层的模型,结果如表7所示。
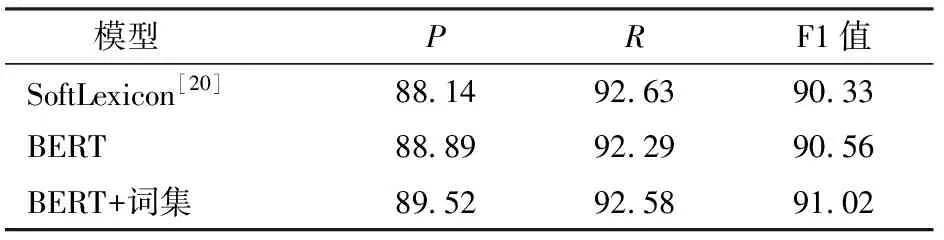
表7 字词融合实验结果
本文词集向量均没有添加MHA和Attention机制,仅使用词频作为权重计算词集信息,编码层均为单层的BiLSTM。SoftLexicon模型融合Glove字符向量和词集向量作为嵌入,由于Glove模型特征提取能力有限,无法获取更全面的语义信息,得到的字词向量包含上下文信息较少,而且猕猴桃种植领域实体专业性较强,结构复杂,从而导致模型的识别性能不佳。使用BERT预训练语言模型得到字符向量作为嵌入层时,与使用Glove字词向量相比,其F1值提高0.23个百分点,原因是BERT预训练语言模型可以提取出序列中与领域相关的更丰富的上下文信息,增强字符表示。融合BERT增强的字符向量和词集信息作为嵌入层时,识别性能有了显著提高,其F1值高达91.02%,与使用Glove字词向量和单纯使用BERT字符向量相比,F1值分别提高0.69个百分点和0.46个百分点,表明使用BERT预训练语言模型增强的字符表示和引入外部词汇信息融合的方式确实可以提高本文猕猴桃种植领域命名实体识别效果。
3.4 编码层对比实验
为了验证BiGRU编码层对模型的影响,分别使用BiLSTM、CNN、Transformer和BiGRU作为编码层进行实验对比,结果如表8所示。
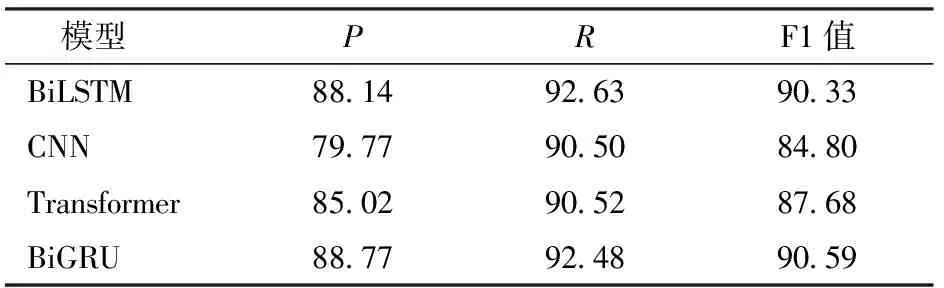
表8 编码层实验结果Tab.8 Experimental results of coding layer %
从表8可以看出,BiGRU作为编码层时,与BiLSTM、CNN或Transformer作为编码层相比,模型的识别效果最好,F1值达到90.59%,说明使用BiGRU作为编码层更适合猕猴桃种植领域命名实体识别任务,可以进一步提高命名实体识别水平。
3.5 嵌入层通用性实验
本文提出的添加MHA和Attention机制以及使用BERT预训练语言模型的方法仅改变了嵌入层,可以与不同的序列建模层联合使用,具有较好的通用性。为了验证不同序列建模层在本文模型中的通用性,将序列建模层的单层BiGRU更换为CNN,卷积层个数为2,卷积核大小为1和3,通用性实验结果如表9所示。

表9 通用性实验结果Tab.9 Performance of commonality test %
由表9可知,本文模型的识别效果最优,与基于字的CNN和SoftLexicon模型相比,精确率分别提高5.77、4.25个百分点。说明本文模型能够更好地利用外部词汇信息,具有更好的通用性。并且与 表7 进行对比时,可以看出编码层使用BiGRU时,模型识别效果更优。
3.6 消融实验
为了验证本文模型嵌入层各个部分对整体模型的影响,对添加MHA机制、Attention机制和BERT预训练模型增强的字符进行消融实验,实验结果如表10所示。

表10 消融实验结果Tab.10 Ablation experimental results %
从表10可以看出,使用BERT预训练语言模型增强的字符表示对模型性能提升最明显,F1值提高0.62个百分点,相比之下,添加MHA机制的提升效果最小,但总体来看,本文提出的每个改进点,均对模型性能有一定程度的提升。
3.7 模型各类实体识别效果分析
表11对比了BiLSTM-CRF模型[22]、Lattice-LSTM模型[18]、WC-LSTM模型[19]、SoftLexicon模型[20]、BERT-BiLSTM-CRF模型[23]和本文模型在7类实体上的识别效果。
从表11可以看出,本文提出的模型识别效果优于其它模型。使用BERT预训练的字向量作为嵌入层时,与SoftLexicon模型相比,除病害类别外,其它6种类别实体的识别效果均有所提升,说明使用BERT预训练的字向量可以有效提升本文命名实体识别效果。本文模型部位类别识别的F1值高达96.87%,病害类别识别的F1值为96.17%,对于实体结构复杂的虫害识别F1值高达95.70%,与SoftLexicon模型相比,在7种类别实体上识别效果均有所提升,说明融合BERT预训练语言模型增强的字符表示和添加不同层次注意力机制等方法可以有效提升本文模型在猕猴桃种植领域实体识别效果。本文模型与BERT-BiLSTM-CRF模型相比,在6种实体类别上也有不同幅度的提升,进一步验证了本文方法在猕猴桃种植领域实体识别任务上的优势。与SoftLexicon模型相比,本文模型对虫害类别的F1值提升最高,提升3.13个百分点,原因是该类别存在虫害嵌套、歧义等干扰信息,在没有其它充足的上下文语义信息时容易预测错误,例如在识别“棉红蜘蛛”和“红蜘蛛”、“盲椿象”和“椿象”、“二点叶螨”和“叶螨”等实体时,SoftLexicon模型只识别出“红蜘蛛”、“椿象”和“叶螨”等,从而造成实体识别效果差,而本文模型则可以识别出正确的实体。
3.8 模型泛化性分析
为了验证本文模型泛化性和稳定性,本文在ResumeNER公开数据集上开展了实验。实验结果如表12所示。结果表明,本文模型表现良好,F1值达到96.17%,显著高于BiLSTM-CRF模型[22],与Lattice-LSTM[18]、WC-LSTM[19]、SoftLexicon[20]、BERT-BiLSTM-CRF[23]模型相比也均有提升。

表11 不同类别实体识别结果Tab.11 Entity recognition results of different types %

表12 各模型在公开数据集上识别效果对比Tab.12 Comparison of recognition effect of each model on public data set %
4 结束语
本文面向猕猴桃种植领域,提出一种融合字词语义信息的命名实体识别模型,有效解决了猕猴桃种植领域命名实体结构复杂、识别精确率较低的问题。该模型使用MHA调整词向量权重,并使用注意力机制进一步获取每个词集的重要程度,使模型更好地利用外部词汇信息,融入BERT预训练语言模型提取的字符增强表示,使嵌入层输出包含更丰富的上下文信息,编码层使用BiGRU模型进一步提高识别效果。通过实验证明,本文模型对7种猕猴桃种植领域实体的识别F1值高达91.91%,在公开数据集ResumeNER上也有较好的效果。
猜你喜欢
快乐语文(2021年36期)2022-01-18
今日农业(2021年11期)2021-11-27
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
动漫星空(兴趣百科)(2020年12期)2020-12-12
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
作文小学中年级(2019年9期)2019-10-14
数字通信世界(2019年3期)2019-04-19
东方女性(2018年3期)2018-04-16
