
基于自适应特征融合的小目标检测算法
2022-02-04 04:42:56王彦雅李卫东张伟娜李晓娟
河北省科学院学报 2022年6期
王彦雅,李卫东,张伟娜,李晓娟
(河北经贸大学信息技术学院,河北 石家庄 050061)
0 引言
目前的目标检测算法大多使用卷积神经网络进行特征提取,卷积神经网络的提取能力毋庸置疑,但一味地通过增加网络深度来提升检测精度是不可行的。越来越深的网络层数不仅伴随着庞大的计算量,计算成本十分昂贵,而且深层的网络会使得图像中小目标的位置信息丢失严重,导致算法对图像中小目标的识别准确率变低。这就面临着一个难题,如何在识别精度提升的前提下,更好地识别图像中的小目标,这是目标检测领域一直以来研究的热点问题[1]。
ResNet(Residual Network)[2]是何凯明团队在2015年提出来的网络模型,通过许多短连接的残差结构,使得特征提取过程中浅层特征信息与深层特征信息相结合,有效减少了深层特征中小目标信息丢失的问题,取得了十分瞩目的提取效果。Faster RCNN(Region Convolutional Neural Network)[3]在两阶段目标检测中较为成功,其提出的区域建议网络效果良好,首次使目标检测实现端到端的检测,检测精度高,但弊端也很明显,检测速度较慢。YOLO(You Only Look Once)系列是主流的单阶段目标检测算法,至今已经迭代了YOLOv1[4]、YOLOv2[5]、YOLOv3[6]、YOLOv4[7]和YOLOv5五个版本。YOLO系列算法有着检测精度高且速度快的优势,但在小目标检测方面仍有很大的进步空间。赵一鸣等人[8]提出了一种基于反馈的特征融合网络ReFPN(Retroaction Feature Pyramid Networks)用于YOLOv4,加强小目标特征信息,在COCO数据集上平均精度提升了1.9%,小目标平均精度提升了3.3%。王卜等人[9]提出一种改进的YOLOv3模型检测交通标志,通过引入特征金字塔,加入FI模块进行特征融合等操作对TT100K交通标志数据集进行检测,较原模型mAP提升了11.1%,且检测每张图片耗时仅增加6.6ms。
针对以上问题,本文采用YOLOv5为基本框架,首先针对小目标特征容易丢失的问题,提出一种CS-AM(Channel Spatial Attention Module)混合注意力机制,对空间维度和通道维度中重要性较高的特征层赋予更高的权重,以加强特征提取过程中对有效特征层的关注,并提升在浅层网络中小目标特征信息的提取能力。其次,针对YOLOv5中输出的三种大小特征图相互独立的问题进行改进,基于原有的PANet(Path Aggregation Network)特征融合结构,添加ASFF(Adaptively Spatial Feature Fusion)[10]自适应特征融合,对三种尺度的特征输出进行自适应特征融合,自动提取三种尺寸的特征图中特征信息最有效的特征层进行融合,有效提升特征提取效果。
1 YOLOv5算法介绍
YOLOv5发布之初共四个版本v5s、v5m、v5l和v5x。各版本只是在模型的深度与宽度有所不同,见表1。本文使用YOLOv5s框架进行实验。模型框架可分为四部分:输入端、Backbone、Neck和预测头,如图1所示。

表1 YOLOv5模型参数
输入图像尺寸为640×640,尺寸不同的图片会被压缩和填充为同一大小。Backbone使用CSPDarkNet-53特征提取模型,由Focus、CBS(Convolution Batch Normalization SiLU)、Resunit、CSP结构和SPP(Spatial Pyramid Pooling)组成,如图2所示。Focus是将输入图像进行切片操作,将640×640×3的图片切割成四份,宽度与高度缩减一半,并将切割好的图像进行拼接,生成320×320×12的图片,增加通道维度的同时减小空间维度,可减少计算量。CBS是由卷积、批量归一化和SiLU激活函数组成。Resunit借鉴残差结构思想,可以使网络构建的更深。CSP在Backbone和Neck部分分为CSP1和CSP2两种结构,CSP1主要由残差块和CSB组成,CSP2将残差块换成了CBS结构。SPP通过三次最大池化操作将任意大小的特征图输出固定维度。

图1 YOLOv5整体框架图

图2 YOLOv5各组件结构图
2 改进的YOLOv5算法
2.1 CS-AM混合注意力机制的引入
小目标的特征在卷积过程中容易丢失,因此可以使用注意机制对小目标的特征信息进行加强处理。通道注意力可以对不同的通道分别施加不同的权重,以此加强特征提取过程中对重要通道的关注度。空间注意力机制是分析特征图中空间维度上的特征信息,对不同特征层施加不同的权重,以此加强重要空间信息的关注度。混合注意力对通道域和空间域中的重要特征信息分别施加关注度,可以更好地增强模型特征提取能力。SENet(Squeeze Excitation Net)是Jie Hu等人[11]提出的通道注意力机制,通过Squeeze、Excitation和Scale三部分组成,并使用残差结构的方式插入分类模型中,取得了较好的效果。CBAM(Convolutional Block Attention Module)注意力[12]包括通道域模块和空间域模块,并将两部分串联输出,同样取得了较好的效果。基于以上思想,本文提出一种混合注意力机制CS-AM。
CAM(Channel Attention Module)将特征图F在空间上进行最大池化和平均池化,将得到的两个C×1×1的特征图进行相加操作,得到一个C×1×1的特征图,再经过Sigmoid函数激活输出,得到通道维度不变且空间维度是1×1的权重矩阵,每个通道的重要程度都会被赋予一个权重系数,CAM结构如图3所示。

图3 通道注意力CAM结构图
SAM(Spatial attention module)将特征图在通道上进行最大池化和平均池化,得到两个1×H×W的特征图,两个特征图高和宽不变,通道数变为1。将二者进行拼接操作得到一个2×H×W的特征图,再使用1×1的卷积核进行卷积,使用Sigmoid激活,就得到了通道维度是1,空间维度不变的权重矩阵,每个权重系数代表了空间位置的重要性,SAM结构如图4所示。

图4 空间注意力SAM结构图
CS-AM混合注意力机制如图5所示,首先将特征图输入子模块CAM,将输出的权重与原特征图相乘,得到加强的特征图Fc。其次,将Fc作为SAM模块的输入,输出结果与Fc进行相乘,最终得到经过通道域与空间域加强的特征图Fs。由于CAM与SAM将特征图进行全局平均池化与全局最大池化的方法会导致部分特征信息丢失,故决定采用残差结构的思想,将Fs与原特征图进行相加操作,再经过Sigmoid激活,最终得到输出F′。
⑥郑石桥、刘庆尧:《〈审计法〉涉及的若干基础性问题的再思考——基于十九大报告的视角》,《南京审计大学学报》2018年第1期。

图5 混合注意力模块CS-AM结构图
公式(1) (2) (3)分别为CAM、SAM和CS-AM的计算公式,其中σ为Sigmoid激活函数,GAP为全局平均池化,GMP为全局最大池化,⊕为张量相加。
Fc=σ(GAP(F)⊕GMP(F))
(1)
Fs=σ(Cov(Concat(GAP(F)⊕GMP(F))))
(2)
F′=σ(F⊕Fs)
(3)
将CS-AM混合注意力模块添加在Backbone中的CSP结构之后,可以在特征提取之后直接对特征图中的小目标的特征信息进行加强,增强模型对小目标的特征提取能力。
2.2 基于ASFF的自适应特征融合结构
在特征提取过程中,卷积层加深,提取到的特征更为抽象,小目标的位置信息容易消失。FPN[13]是一种自上而下的特征融合方法,从而可以解决深层网络对小目标检测不友好的问题。PANet[14]在FPN的思想之上又加入了一条自底向上的特征融合路径,使特征融合的更好。YOLOv5中使用的PANet结构分别输出20×20、40×40和80×80三种固定大小的特征图对大、中、小目标进行预测,达到了不错的效果,而使用固定大小的特征图进行预测仍具有一定局限性。
ASFF是一种自适应特征融合结构,它可以自适应的学习三个尺度特征图在融合的过程中的权重占比,并且能够直接过滤掉低权重的特征层,保留高权重的特征层进行组合。如图6所示,Level 1、Level 2、Level 3和ASFF-1、ASFF-2、ASFF-3之间是全连接,融合时需要将特征图进行上采样或下采样。

图6 ASFF结构和添加位置
2.2.1 上采样与下采样
YOLOv5具有三种不同大小和通道数的特征图,三种尺度融合需要进行上采样或下采样保持特征图的大小和通道数一致。上采样ASFF使用1×1卷积增加通道数,并使用差值法提升分辨率。下采样使用3×3卷积和最大池化降低图片通道数和分辨率。
自适应特征融合可表示为公式(4):
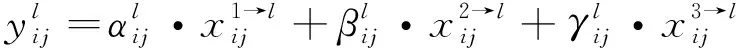
(4)

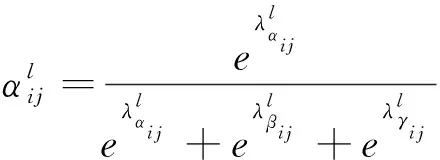
(5)
输出的y1、y2、y3就是ASFF-1、ASFF-2、ASFF-3结构,作为预测头的输入。
将ASFF结构添加在原PANet与预测头之间,可以将原模型的三种尺度的输出进行自适应特征融合,有效特征层被赋予更高的权重,并组合成新的特征图。小目标在新的特征图中特征信息更加明显,提升预测头的预测效果。
3 实验结果与分析
3.1 数据集
实验数据集使用MS COCO2017,其中小目标占比较高,有41%,共80个类别,如表2所示。由于数据集数量庞大,选取训练集中50 000张进行训练。

表2 MS COCO2017数据集
3.2 实验环境与实验参数
实验在Ubuntu18.04.5操作系统中进行。硬件配置为12核CPU Intel(R) Xeon© Platinum 8255C,主频2.50GHz。GPU 为Nvidia RTX 2080 Ti 11G显卡。软件版本为Pytorch1.9.0,CUDA 11.1,Python3.8.10。训练参数学习率0.01,余弦退火0.1,预热Epochs3,权重衰减系数0.000 5,学习动量率0.973,Batchsize32,Epoch 300。
3.3 评价指标
实验使用四种评价指标。P为查准率,R为查全率,如公式(6)(7)所示。TP为真实正类别,FN为错误负类别,FP为错误正类别,TN为真实负类别。mAP为所有类别的平均精度均值。mAP @0.5为IoU为0.5时的平均精度均值,mAP @0.5∶0.95为IoU在[0.5∶0.95]之间步长为0.05的平均精度均值。

(6)

(7)
3.4 与主流算法的比较
为了证明算法的有效性,将本文的算法在MS COCO2017数据集上与目前主流的目标检测算法进行比较,如表3所示。改进的YOLOv5算法较Faster-RCNN mAP @0.5/%提升了2.7%,较YOLOv3 mAP @0.5/%提升了6.7%,较YOLOv4 mAP @0.5/%提升了4.6%,较原YOLOv5提升了1.8%。结果表明在MS COCO2017数据集中本算法的有效性。
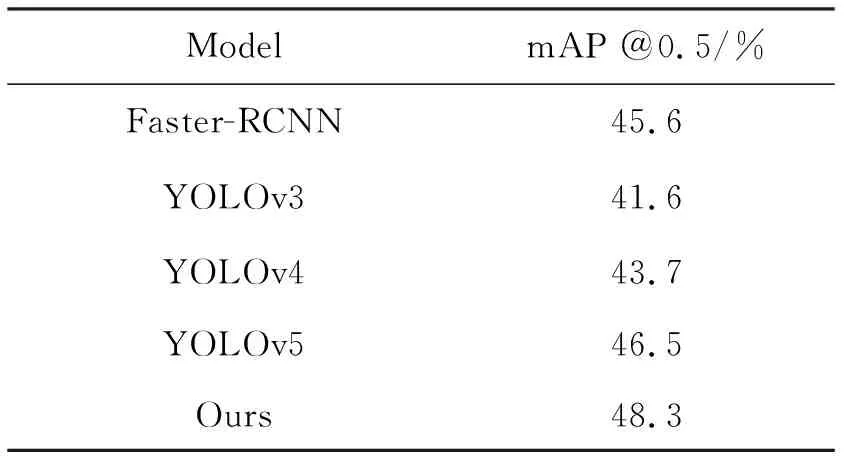
表3 与主流算法对比表
文献[8]中算法较原YOLOv4平均精度提升1.9%,而本文算法提升了4.6%,提升幅度更加明显。文献[9]中改进的YOLOv3算法精度虽提升了11.1%,但每张图片的检测耗时增加了6.6ms,而本文算法在精度提升6.7%的同时检测耗时减少了0.4ms,更好地兼顾了检测精度与检测速度。
3.5 消融实验结果及分析
如表4所示,使用CS-AM混合注意力机制的模型较原模型精度提升了0.6%,召回率提升了1.2%,mAP @0.5提升了0.5%,mAP @0.5∶0.95提升了1%。
使用ASFF改进的特征融合结构较原模型精度提升了1.6%,召回率提升了1.4%,mAP @0.5提升了1.2%,mAP @0.5∶0.95提升了1.8%。
综合改进后的模型较原模型精度提升了2.8%,召回率提升了2%,mAP @0.5提升了1.8%,mAP @0.5∶0.95提升了2.4%。
结果表明,本文提出的CS-AM混合注意力机制可以较好地提升对小目标的特征信息关注度,ASFF自适应特征融合可以更好地对三种尺度的特征输出进行融合,综合模型对小目标的检测效果增加明显。

表4 实验结果对比表
3.6 实验结果可视化比较
为了更好的证明算法效果,在MS COCO数据集中挑选出两张含有小目标的图片。图7左侧是使用YOLOv5模型检测的效果,图7右侧是使用改进后模型的检测效果。不难发现,使用原YOLOv5模型对图7左上进行检测,只检测出图片中距离较近的6个人,而改进后的模型在此基础上检测出了距离较远的一个人和左侧只露出了半个身子的人,并且检测出了两个体积非常小的冲浪板。证明算法不仅对小目标的检测效果有所提升,而且对图片中被遮挡的物体以及部分露出的物体检测效果均有提升。
图7左下检测出了面积占比较大的两个人和两个冲浪板,而图片右上角的海面上存在一个肉眼难以发现的人,改进后的模型精准的检测出了面积占比极小的人。证明提出的算法对小目标的检测效果明显提升。

4 结论
针对目标检测常用算法对小目标的检测效果较差的问题,基于YOLOv5检测模型,提出了CS-AM注意力机制加强对小目标特征信息的关注度。使用ASFF改进原PANet特征融合结构,将三个输出维度的特征图中权重较大的特征层进行自适应融合,提升了预测头对小目标的预测能力。
小目标的预测一直是目标检测领域的重难点,由于像素占比较少,在特征提取过程中特征信息极易丢失。现有模型对小目标的检测效果较为一般,经常出现漏检的现象,所以对小目标的检测仍有较大的提升空间。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
软件导刊(2022年3期)2022-03-25 04:45:04
计算机技术与发展(2019年1期)2019-01-21 00:56:38
电子制作(2018年19期)2018-11-14 02:37:08
传媒评论(2017年3期)2017-06-13 09:18:10
自动化学报(2017年11期)2017-04-04 02:52:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
噪声与振动控制(2015年4期)2015-01-01 07:08:21
