
中国家庭债务风险测度及其预警研究
2022-02-03 04:35:46谭本艳吴艳甘子琪
金融发展研究 2022年12期
谭本艳 吴艳 甘子琪
(三峡大学经济与管理学院,湖北 宜昌 443002)
一、引言
防范化解金融风险,特别是防止发生系统性金融风险,是我国金融工作的根本性任务。目前,我国各级政府和金融监管部门主要关注的是高金融杠杆率、影子银行、互联网金融、大中型企业债务、房地产金融化泡沫化、地方政府隐性债务等宏观领域的金融风险,而微观领域的家庭债务风险却常常被忽视。根据上海财经大学高等研究院课题组(2018)[1]的研究,我国家庭债务问题十分严重,已经非常接近家庭能承受的极限,且对消费形成了显著的挤出效应,导致消费增速连续多年下滑。更为严重的是,家庭债务挤出消费的负面效应已经溢出到了实体经济和金融系统,加剧了系统性金融风险发生的可能性。因此,除了关注宏观领域的金融风险外,也要关注微观领域的家庭债务风险。
事实上,2011年以来,中国的家庭部门贷款问题不断显现。根据中国人民银行公布的数据,2011—2021年,中国的家庭部门贷款总余额从13.601万亿元增长至71.104万亿元,年均增长率达到17.99%,消费性贷款占贷款总余额的比例从65.23%增长至77.19%,中长期贷款占贷款总余额的比例由67.83%增长至75.64%。数据表明中国家庭债务呈不断扩张趋势,且消费性贷款占比不断提高,贷款期限呈拉长趋势。此外,我国很多家庭一定程度上通过民间借贷增加债务,如果考虑民间借款部分,中国家庭债务问题可能更加突出。由于金融风险具有较强的传染性,为防止该风险在部门之间传染,中国家庭债务风险问题需要警惕,因此,对其进行预警研究具有重要意义。
在对家庭债务风险进行预警之前,需要对其进行界定。根据我国家庭债务来源情况,微观数据更能反映我国家庭的真实债务风险水平,而目前从微观层面对家庭债务风险水平的界定并不统一。隋钰冰等(2020)[2]用风险债务比例衡量家庭债务的总体风险,比例越高,家庭债务的总体风险越高;黄晓东(2018)[3]认为债务总量指标不能很好地反映家庭债务的真实情况,因而引入家庭流动性约束概念,如果家庭流动性资产与家庭净收入的一半之比小于1,则认为该家庭面临流动性约束。然而,这些界定比较单一,本文尝试从微观层面的家庭债务因素、人口结构、流动性因素和收入支出状况四个方面综合测度家庭债务风险水平,将家庭债务风险界定为:在短时间内,家庭需要偿还债务时,由于负债过多导致家庭人均负债过重,以及由于家庭人口结构、流动性风险和收入风险等原因,使得家庭偿债能力急剧下降所引发的风险。
二、文献综述
与本文密切相关的研究主要有两个方面:一是关于家庭债务风险的测度研究;二是关于家庭债务风险的影响因素研究。
(一)关于家庭债务风险的测度研究
学术界常用宏观层面的居民部门杠杆率(家庭负债与GDP的比率)、居民部门债务收入比和居民部门资产负债率等指标来测度一个国家的居民债务风险水平(李若愚,2016)[4],从微观层面对家庭债务风险的测度并不统一,但采用的测度方法总体可以归纳为客观衡量法和主观衡量法两种,且多用过度负债指标表示债务风险水平。从客观衡量法来看,吴锟等(2020)[5]通过债务偿还比率、房贷偿还比率、家庭还债之后的人均可支配收入等指标来判断一个家庭是否过度负债。柴时军(2020)[6]用资产负债率高于50%、债务收入比高于100%等指标来判定一个家庭有债务风险。Oxera(2004)[7]将债务成本与收入之比超过50%的家庭定义为有巨大偿债负担的家庭。Keese(2009)[8]针对无负债、有负债的家庭分别依据“家庭收入减去还本付息后是否小于不可扣押收入”和“家庭收入减去债务偿还后是否小于社会救助水平”来判断其是否过度负债。从主观衡量法来看,陈莹和武志伟(2015)[9]采用一年内是否出现一个月以上拖欠行为、还款困难的程度和家庭是否因还贷款产生较大的心理负担等指标来定义其是否过度负债。Betti等(2007)[10]通过直接询问人们是否面临债务偿还困难,以此衡量欧盟国家家庭是否过度负债。但D'alessio和Iezzi(2013)[11]认为过度负债具有多维特性,并利用意大利家庭收入和财富调查微观数据,将家庭资产纳入并用主成分分析法构建家庭过度负债综合指标。
(二)关于家庭债务的影响因素研究
关于影响家庭债务的微观因素方面,陈斌开和李涛(2011)[12]利用2009年“中国城镇居民经济状况与心态调查”数据研究发现,家庭负债随着户主的年龄及家庭收入水平的提高而下降。吴卫星等(2013)[13]研究发现负债与收入的关系存在群体差异,只有在较高负债规模的家庭中,家庭负债与家庭收入才呈正相关关系,而在其他群体中收入对家庭负债规模无显著影响。祝伟和夏瑜擎(2018)[14]指出以住房购买、汽车购买为代表的耐用品消费会显著增加家庭负债。吴卫星等(2018)[15]基于中国家庭微观调查数据实证发现,较高的金融素养能够使得家庭使用合理的信贷,从而提高家庭福祉。Disney和Gathergood(2011)[16]根据YouGov季度债务跟踪调查数据研究发现,财务文盲家庭的净资产较低,且更有可能使用成本较高的信贷,从而难以偿还债务,陷入过度负债。Brown和Taylor(2014)[17]基于BHPS调查数据实证研究发现,性格特征与不同类型的债务有不同的关联。关于影响家庭债务的宏观因素方面,王海燕等(2021)[18]认为数字金融发展会推动家庭杠杆率攀升。Mehmet(2021)[19]依据1996—2020年中国宏观数据并采用时间序列模型进行定量分析发现,人均GDP和利率对家庭债务有正向影响,但CPI对家庭债务影响不显著。Lerskullawat(2020)[20]根据泰国的宏观数据实证研究认为,家庭收入和消费支出、物价上涨等经济因素以及教育、婚姻、青年人口等社会因素对家庭总债务均具有显著的正向影响。
可以看出,上述研究主要存在以下不足:一是对家庭债务风险的测度主要采用的是单一指标;二是对家庭债务风险的研究还没有形成预警机制,即缺乏风险预警研究;三是对家庭债务影响因素的研究视角主要集中在回归模型的线性参数上,缺乏对家庭债务影响因素的非线性效应研究。
因此,本文主要从以下三个方面对现有文献进行拓展:第一,从债务因素、人口结构、流动性因素和收入支出状况四个层面构建中国家庭债务风险指标体系,并进一步采用因子分析法和聚类法构建中国家庭债务风险综合测度指标;第二,利用中国家庭金融调查(CHFS)数据库的微观调查数据,构建基于Light-GBM算法的家庭债务风险预警模型,从而有效识别家庭债务风险,起到预警作用;第三,采用机器学习的SHAP和PDP解释方法分析中国家庭债务影响因素的非线性效应。
三、研究设计
(一)中国家庭债务风险指标构建
1.数据来源、数据处理及样本筛选。(1)数据来源。本文数据来源于中国家庭金融调查数据库,该数据覆盖了除西藏、新疆、港澳台地区以外的全国29个省(自治区、直辖市),问卷内容涵盖了家庭的人口学特征、资产与负债、收入与支出等信息。目前该数据库包含了2011年、2013年、2015年、2017年和2019年共5年的数据,为保证样本量充足,本文将2013年、2015年、2017年和2019年数据进行合并,构成混合截面数据。(2)数据处理及样本筛选。①缺失值处理。将负债和收入等主要数据缺失的样本剔除后,其他有关变量的缺失率均在10%以下。对家庭成员年龄缺失用中位数填补;对户主婚姻状态按户主小于20岁用“未婚”填补,大于20岁用众数填补;对家庭成员是否有工作按年龄为16周岁以下或65周岁以上用“否”填补,否则用众数填充。②异常值处理。为避免异常值所造成的偏误,对收入小于0以及支出等于0的样本进行剔除,再对总资产、总负债、总收入、总支出进行上下1%截尾处理。③标准化处理。在进行因子分析时,采用Z-score方法进行标准化处理。④样本筛选。由于本文主要研究家庭债务的风险情况,因此,将总负债为0的样本剔除。⑤分样本实证。由于我国存在城乡二元结构差异,为更客观反映中国家庭债务风险,本文分别对城镇和农村家庭进行数据描述及实证分析。按照上述方法对数据处理后,最终得到城镇和农村家庭样本分别为22545和12778个。
2.预警指标的选取。根据本文对家庭债务风险的定义,接下来从家庭债务因素、人口结构、流动性因素以及收入支出状况4个层面进行指标选取,指标选取理由及定义说明如下。
第一,与家庭债务因素直接相关的指标最能直观反映家庭债务情况。本文在中国家庭实际情况的基础上,选取了3个债务因素层面的指标,包括债务总规模(TD)、人均负债(PCD)和房屋负债占总负债比重(Pro_HD)。其中,房屋负债是中国家庭中最典型的债务类型之一,对家庭债务风险有较直接的影响,房屋负债占比一定程度上能够客观反映家庭的债务负担情况。
第二,家庭人口结构特征也会影响家庭债务行为(常思浩,2021)[21],本文从参与工作情况以及劳动年龄的角度选取了2个人口结构特征指标,即无工作人口占比(Pro_NWP)和人口抚养比(PDR)。一般而言,家庭中参与工作的人数越少,家庭收入来源越少,偿债能力可能越弱,因此,无工作人口占比越高,家庭债务风险也越高;人口抚养比是指非劳动年龄人口占劳动年龄人口的比重,其中非劳动年龄人口包括14岁及以下和65岁及以上的人口,劳动年龄人口则为15至64岁的人口,该指标能够反映一个家庭抚养的经济负担大小,其取值越大,表明家庭抚养的经济负担越重,借贷的可能性越大,债务风险越大。
第三,资产流动性因素也是家庭偿债能力的重要体现。本文参考已有文献并结合中国家庭的实际情况,选取了房屋资产占比(Pro_HA)、金融资产占比(Pro_FA)、财务边际(FM)和金融资产负债率(DFAR)四个指标。其中,房屋资产作为中国家庭的典型资产之一,具有流动性差、以居住功能为主等特点,房屋资产占总资产比重越高,资产的流动性越差,短时间内对家庭偿债能力提升有限。根据问卷,金融资产包含个人社保账户余额、存款、现金、股票、基金、理财、债券、衍生品、非人民币资产、黄金、其他金融资产、借出款这12项,与房屋资产相比,金融资产具有流动性较强的特点,一般而言,金融资产占比越高,短时间内能够有效提升家庭偿债能力,有利于降低家庭债务风险。财务边际是学术界常用于衡量家庭债务风险的指标之一(雷海波,2021)[22],本文在借鉴隋钰冰等 (2020)[2]的定义基础上,将财务边际定义为家庭总收入加上流动性较强的资产(主要包含现金、银行存款和货币市场基金),再减去消费支出和应偿还的债务之后的剩余。财务边际越大,表明资产的流动性越强,短期偿债能力越强,债务风险越小。金融资产负债率是指总负债占金融资产的比重,能够直接体现家庭用金融资产担负债务的能力,该值越大,表明用金融资产偿债的压力越大,风险也越大。
第四,收入支出状况能够反映家庭收支水平,同时也一定程度上能够反映家庭偿债能力。本文主要选取债务收入比(DIR)、结余比例(BR)、生存型消费占总收入比(Pro_SCTI)和人均消费(PCC)4个反映收入支出状况的指标。其中,债务收入比是学术界用于反映家庭债务情况最常用的指标之一,反映了家庭用收入清偿债务的能力,该指标值越高,表明用收入清偿债务的能力越差,甚至收不抵债,风险自然越高;结余比例为结余(收入减去支出后的剩余)占收入的比重,该指标值越高说明家庭收入用于消费的部分越少,而用于储蓄的部分越多,偿债能力也越强,风险越低;生存型消费是指为了维持生存所必需的物质和劳务消费(罗娟,2020)[23],借鉴肖立(2012)[24]的做法,生存型消费由食品、衣着、日用品和居住支出加总得到,该指标一定程度上能够反映家庭生活水平,生存型消费占总收入比重越高,说明家庭生活水平越低,偿还债务的保障能力越低,风险越高;人均消费支出也会影响家庭债务,家庭收入一定时,如果人均消费越高,则储蓄越少,同时由于“棘轮效应”的存在,家庭很难因收入急剧下降等冲击而短时间内降低消费水平,因而可能会通过信贷的途径以继续维持高消费水平,使得负债需求增加,风险增加。
综上,本文主要从家庭债务因素、人口结构、流动性因素以及收入支出状况4个层面选取了13个预警指标,基本能够综合反映家庭债务风险情况,各个指标名称及其说明如表1所示。
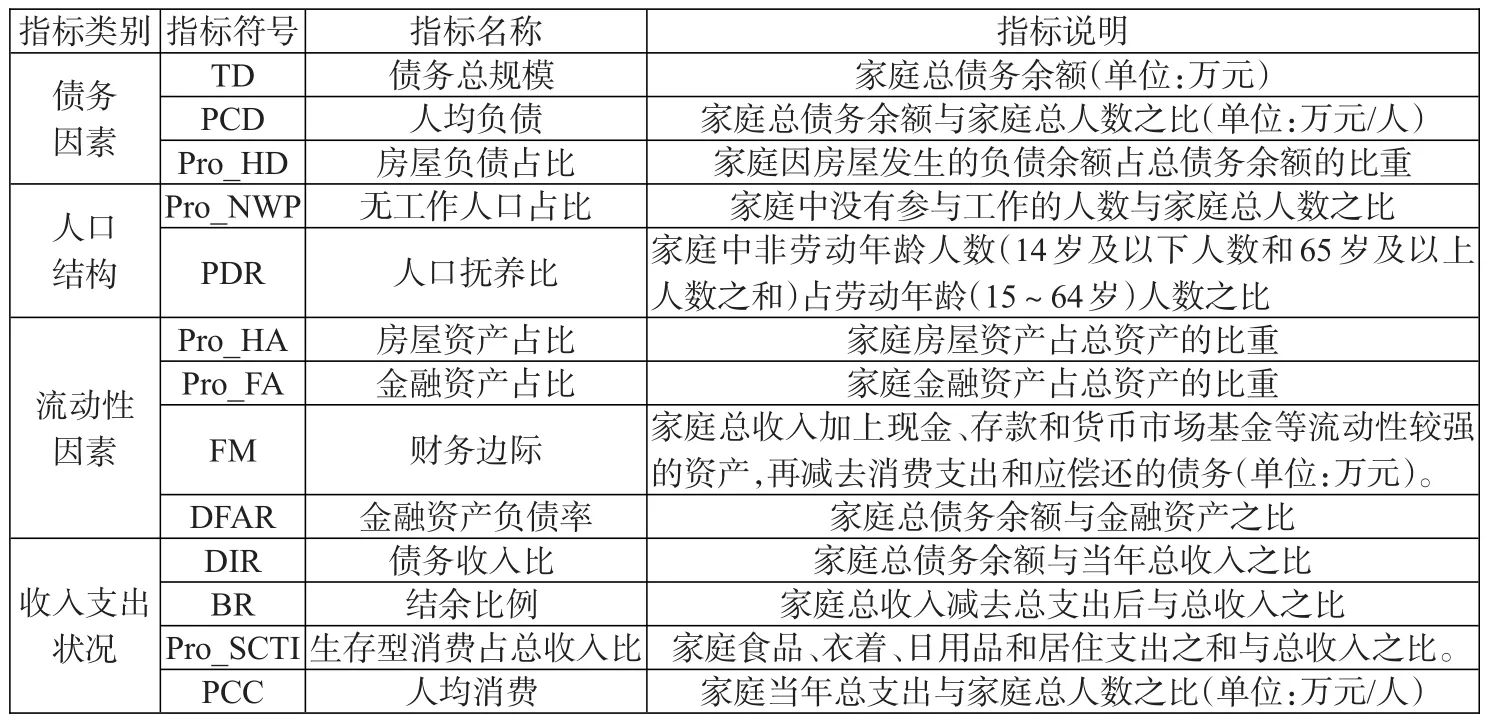
表1:预警指标名称及说明
3.债务风险测度方法。(1)因子分析法。确定好预警指标后,采用因子分析法分别构建城镇和农村家庭债务风险指标,并命名为F。根据本文分析的需要,进一步将F的取值划分为两种状态,即高风险状态和低风险状态。(2)层次聚类法。由于人为划分阈值具有主观性,故采用层次聚类法,对F进行聚类,从而得到每个家庭的债务风险状态。
(二)中国家庭债务风险预警
1.预警模型的介绍。基于轻量级梯度提升树(Light Gradient Boosting Mechine,LightGBM) 算法的机器学习模型是集成模型的一种,相比于传统的单一模型,集成模型具有准确率更高、更稳定以及稳健性更好等优点。LightGBM主要通过直方图做差加速的方法实现速度提升并减少分割增益的计算,同时使用Leaf-wise(Best-first)的决策树生长策略,使得误差降低,精度提高。因此,相比于其他集成模型,LightGBM具有训练速度快、内存消耗少等优点,比较适合本文的预警分析。
2.数据说明。本文分别依据城镇和农村数据集建立预警模型,建模使用的软件为Python,数据沿用债务风险指标构建的数据,即22545个城镇家庭和12778个农村家庭数据,均包含13个特征变量(13个预警指标)和1个标签变量(债务风险状态)。
3.预警模型的建立。预警模型输入特征变量为影响每个家庭债务风险的13个预警指标,输出标签变量为家庭债务风险状态(高风险或低风险)。构建单个家庭的数据集向量为:

其中,xj,i(i=1,2,…,13)表示第j个家庭债务风险的影响因素,yj(j=1,2,3,…)表示第j个家庭的债务风险状态,yj取值为0或1,其中0表示低风险,1表示高风险。
输入特征变量为:


输出标签变量为:对模型进行训练时,则训练模型的输入变量为:
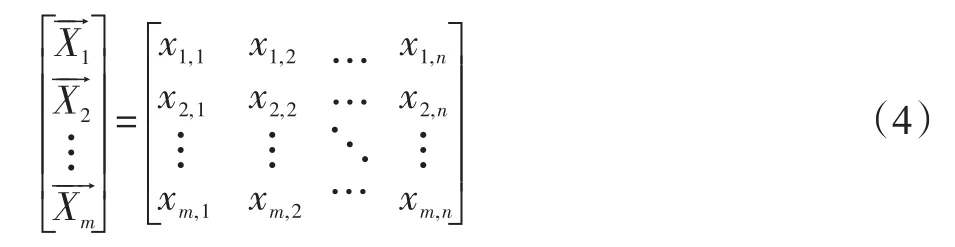
式(4)中,m为训练样本个数,n为影响因素个数。
进一步得到预警模型的对应关系式:

其中,f(φ1,φ2,…,φL)为输入特征变量到输出标签变量的映射关系,此处为LightGBM映射关系;φk(k=1,2,3,…,K)为LightGBM内部的参数,K为参数总数。训练模型的过程就是对参数进行标定的过程。将LightGBM与影响因素的映射关系表示为FLGBM,则构建预警模型表达式如下:

用已知风险状态的家庭对模型进行标定,再根据式(6)可以对测试集样本进行预测,进而实现预警的目的。
四、实证分析
(一)中国家庭债务风险分析
1.预警指标的描述性统计。城镇和农村家庭预警指标的描述性统计如表2所示。根据表2,各个预警指标在我国城镇和农村之间存在较明显的差异。具体而言,从债务因素指标来看,在负债家庭中,平均每个城镇家庭负债总规模为17.63万元,农村为7.39万元,前者为后者的2倍多;平均每个城镇家庭的人均负债为5.45万元,农村为1.76万元,前者为后者的3倍多;平均每个城镇家庭的房屋负债占比为44.6%,远超过农村的32.7%。从流动性因素指标来看,平均每个城镇家庭的房屋资产占比和金融资产占比均高于农村家庭,但是财务边际和金融资产负债率低于农村家庭,且不论是城镇还是农村,平均每个家庭的房屋资产占其总资产的比重均超过一半。

表2:预警指标描述性统计
2.预警指标构建及风险类别划分。因子分析前的KMO值和Bartlett's球状检验均表明数据适合进行因子分析。限于篇幅,此处不汇报因子分析过程。最终,聚类结果显示,在22545个城镇负债家庭中,高风险和低风险的家庭分别为5650个和16895个;在12778个农村负债家庭中,高风险和低风险的家庭分别为1571个和11207个。
3.中国家庭债务风险情况分析。为进一步分析家庭债务风险情况,本文将高(低)风险率定义为高(低)风险家庭数占总家庭数的比率,由此,计算得到我国城镇和农村家庭债务高风险率分别为25.06%和12.29%。
此外,基于上述数据和测度方法,本文还根据数据库来源的年份,分别得到了2013年、2015年、2017年和2019年城镇和农村家庭的债务风险状况,如表3所示。由表3可知,不论是城镇还是农村家庭,高风险率均在40%以下,表明风险整体可控,但从时间维度来看总体都呈现增长的趋势,且城镇家庭高风险率一直高于农村家庭,可能的原因是,城镇家庭由于生活成本高等原因导致其信贷需求更高,从而更容易陷入高风险状态。

表3:各年份中国城镇和农村家庭的债务风险状况
4.为考察中国家庭债务风险的异质性,本文还进一步对城镇和农村样本从户主性别、户主婚姻状态以及家庭所处地区三个层面分别进行了分组分析,结果如表4所示。根据表4,城镇和农村家庭的债务风险情况存在以下特征:(1)不同户主性别。不论是城镇还是农村家庭,户主为男性的高风险率都低于户主为女性的高风险率,即户主为女性的负债家庭其为高风险的可能性更大。这可以借鉴周利和冯大威(2020)[25]的研究结论进行解释,即相比于男性,女性更容易呈现“大五人格”中的神经质人格特征,而神经质程度高的个体更有可能过度负债,因此,女性户主家庭为高风险家庭的可能性越大。(2)不同户主婚姻状态。对于城镇家庭而言,户主已婚家庭的高风险率略高于户主未婚家庭的高风险率。可能的原因是,相比于户主未婚的城镇家庭,户主已婚的城镇家庭要承担的经济压力更大,信贷需求更大,从而导致其为高债务风险的可能性越大。而对于农村家庭而言,户主已婚家庭的高风险率低于户主未婚家庭的高风险率。这可能是因为户主已婚的农村家庭在进行信贷决策时相对更加保守,从而其为高债务风险的概率也更低。(3)不同地区。无论是城镇还是农村家庭,东部地区的高风险率均最高,东北部地区高风险率最低,而中部和西部比较接近。这可能是因为东部地区基础设施相对而言更健全,人口更密集,发展程度也更高,使得家庭消费水平更高,信贷需求更大,高风险的可能性也更大,而其他地区生活成本相对较低,信贷需求较小,高债务风险的可能性也较小。
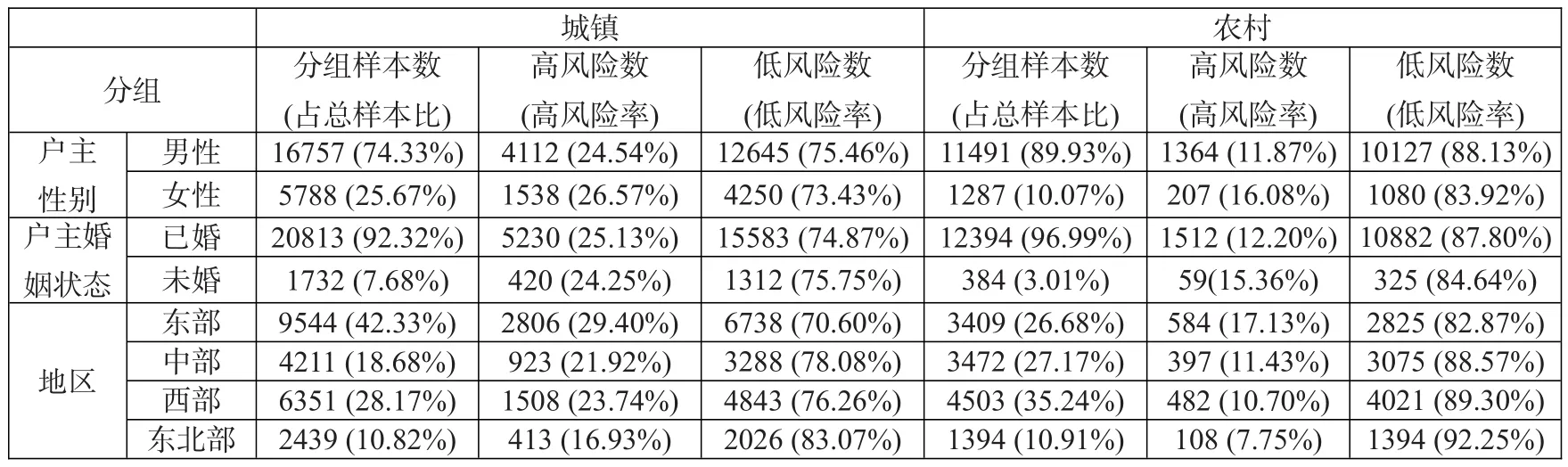
表4:城镇和农村家庭债务风险分组分析
(二)中国家庭债务风险预警分析
1.预警模型的求解。(1)测试集和训练集划分。参照一般经验,本文按照3∶1的比例划分训练集和测试集,经过划分后,城镇数据集的训练集中包含16908个样本,其中高风险样本有4254个,高风险率为25.16%,测试集中包含5637个样本,其中高风险样本有1396个,高风险率为24.76%;农村数据集的训练集中包含9583个样本,其中高风险样本有1181个,高风险率为12.32%,测试集中包含3195个样本,其中高风险样本有390个,高风险率为12.21%。(2)预警模型参数调整。当所有参数都选为默认值时,即不进行参数调整,模型在城镇和农村的测试集上的AUC值分别为0.9695和0.9287。为了使模型预警效果更好,本文采用网格搜索和5折交叉验证进行参数调整,并设置learning rate为0.1,网格搜索的参数列表及得到最优参数结果如表5所示。经过参数调整后,模型在城镇和农村的测试集上的AUC值分别达到0.9725和0.9599,相比参数调整前均有所提高。

表5:LightGBM模型参数列表及最优参数
2.预警模型的评估。为了评估预警模型的效果,选取了常用的分类模型评估指标,包括混淆矩阵、AUC、准确率、精确率、召回率以及F1得分对预警结果进行评价。其中,混淆矩阵可以直观展示模型的预警结果;AUC取值范围为[0,1],若AUC>0.5表明模型效果较好;准确率、精确率、召回率、F1得分值越高表明模型效果越好。根据预警模型在测试集上的表现,绘制混淆矩阵如图1所示。
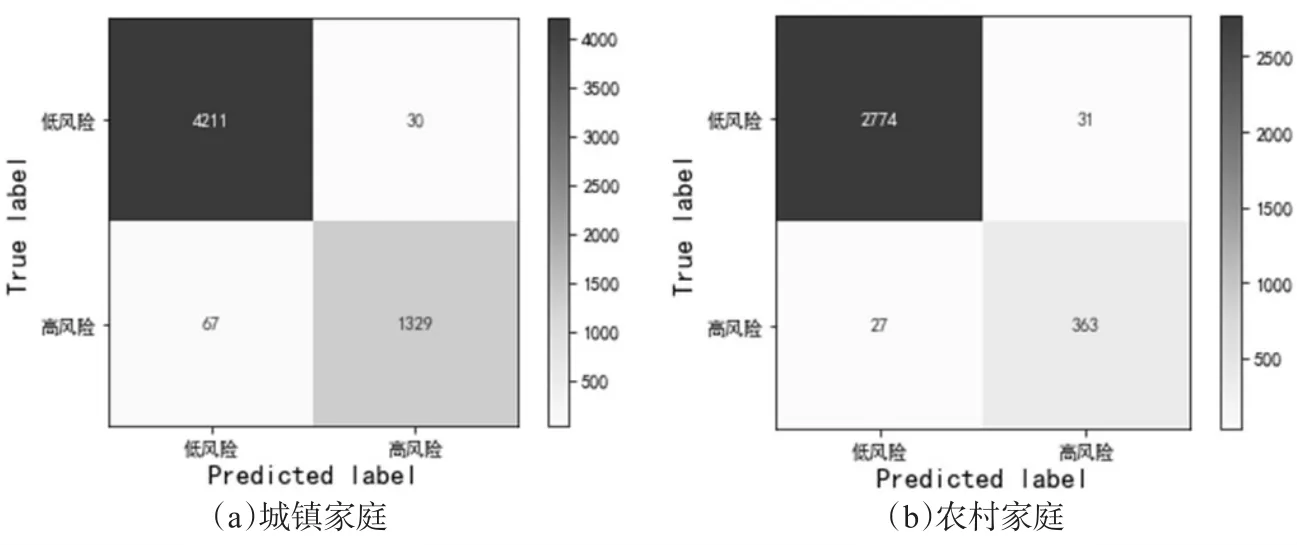
图1:LightGBM模型的混淆矩阵
从图1(a)可以看出:对于城镇家庭样本而言,在测试集的5637个样本中,预警模型把4241个低风险家庭正确判定为低风险家庭的有4211个,把1396个高风险家庭正确判定为高风险家庭的有1329个,同时把低风险家庭误判为高风险家庭的有30个,把高风险家庭误判为低风险家庭的有67个,准确判断率为98.30%。同理,根据图1(b)可以解读农村家庭样本的混淆矩阵,此处不再一一分析。进一步,预警模型在城镇测试集上的AUC值、准确率、精确率、召回率、F1得分分别为0.9725、0.9830、0.9779、0.9520、0.9648,在农村测试集上的上述5个评估指标值分别为 0.9599、0.9818、0.9213、0.9308、0.9260。可见,不论是城镇还是农村家庭,本文基于LightGBM算法的机器学习模型都取得了较好的预警效果。
3.预警模型的解释。相比传统的统计计量模型,机器学习模型有预测效果好、能够处理复杂的非线性关系、对大数据友好等优势,但也存在可解释性表现较差的不足,这使得机器学习模型几乎成为“黑箱”模型。为了对预警模型进行合理解释,本文利用Lundberg和Lee(2017)[26]引入的机器学习SHAP可解释工具,从预警模型的特征重要性和预警模型的全局解释两方面进行解释。SHAP可以通过量化并汇总每一个特征对目标变量的贡献,从而解释特征对预警结果的影响力,并通过SHAP值的正负来反映影响力的正负。
(1)预警模型的特征重要性 (Feature importance)。我们使用SHAP摘要图来考察影响家庭债务的主要特征,SHAP摘要图按输入特征映射的输出标签不同,可分为低、高二类不同风险状态的SHAP摘要图,通常只考查更有实际意义的高风险状态SHAP摘要图。以本文的高风险状态SHAP摘要图为例,输入特征为反映家庭债务的13个特征,输出标签为高低风险二分类状态,若第j个样本的第i个特征的取值 (Feature value) 对应的SHAP值 (SHAP value)为正,表明第i个特征对j样本预警为高风险状态的边际贡献为正,即样本j的i特征取该值时,样本j更有可能为高风险状态,反之亦然。高风险状态家庭的SHAP摘要图见图2。

图2:高风险状态家庭的SHAP摘要图
SHAP摘要图的作用是从全局的角度对预警模型的特征贡献度进行排序。图2中,左侧为各个输入特征的名称,位置较高的特征表示对预警模型的特征贡献度较大,右侧从浅变深,表示输入特征的取值由低到高,横轴表示SHAP值,即每个样本的各个特征对应的SHAP值的取值范围和大小。图中每一行代表1个特征(本文为13个特征),每个点代表一个样本,每一行上的样本点是相同的,宽区域的样本点比窄区域多。以城镇家庭的第1行为例,房屋负债占比在城镇家庭中排在第1位,说明其对预警模型的贡献度最高。进一步,当房屋负债占比取值较小时,对应的SHAP值为负,说明房屋负债占比取值较小的样本点被预测为高风险的概率较小,而随着取值的增大,SHAP值逐渐变为正值,说明房屋负债占比取值较大时的样本点被预测为高风险的概率也逐渐提高。
此外,从图2可以看出,对城镇和农村家庭债务预警贡献度最大的前8个特征中,相同的特征为房屋负债占比、财务边际、无工作人口占比、人口抚养比、人均消费、房屋资产占比、人均负债。可见,无论是对城镇还是农村家庭,这7个特征都是影响家庭债务风险的重要因素;不同的特征中,城镇家庭为债务总规模,农村家庭为结余比例,这说明城镇家庭借贷总额过大从而增加债务风险可能性更大,而农村家庭因收入支出状况导致债务风险增加的概率更大。
(2)预警模型的全局解释。为了更直观地分析家庭特征对债务风险状态的影响,本文使用SHAP值映射图来展示家庭特征与债务风险状态之间的非线性关系,SHAP值映射图的横坐标为特征的取值,纵坐标为SHAP值,从SHAP值等于0处作一条水平线,穿过图形上的两点分别为安全点和预警点。为了进行对比分析,并结合前文的SHAP摘要图,本文选取7个影响城镇和农村家庭债务风险的共同重要特征再加上债务总规模共8个特征,即房屋负债占比、财务边际、人口抚养比、无工作人口占比、人均消费、房屋资产占比、债务总规模、人均负债,进行SHAP值映射分析,对应的SHAP值映射图分别如图3和图4所示。
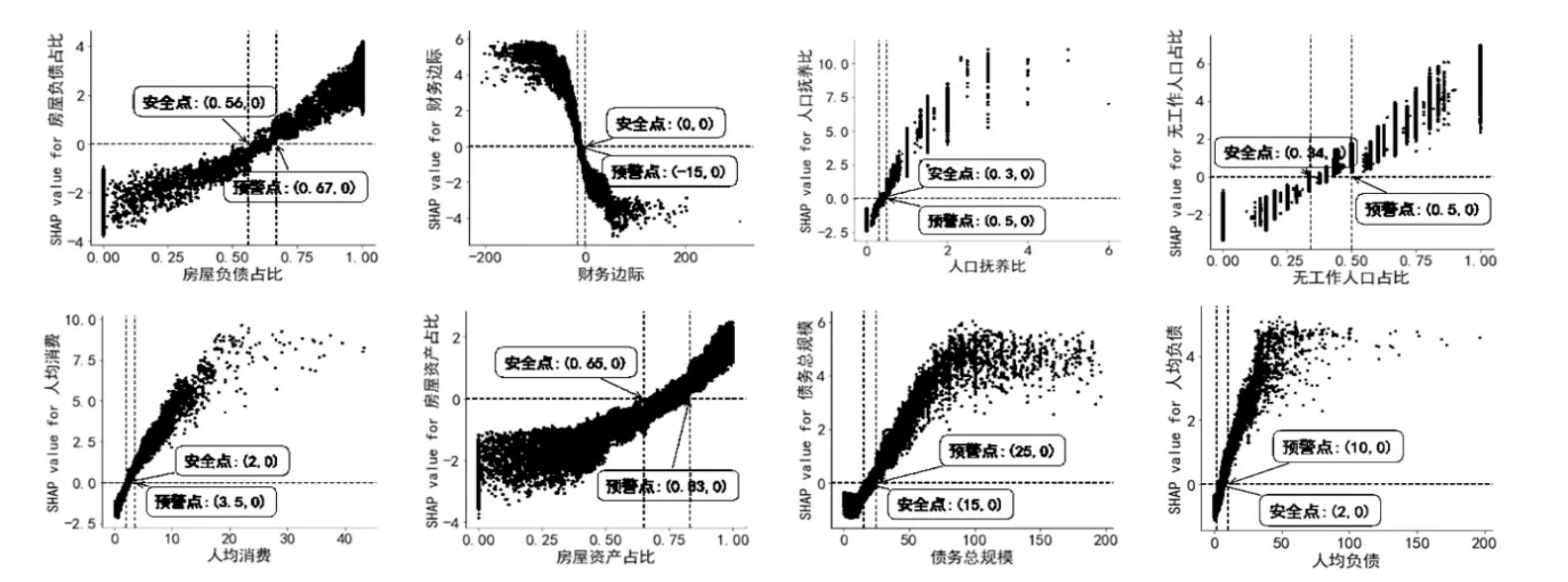
图3:城镇家庭8个特征的SHAP值映射图
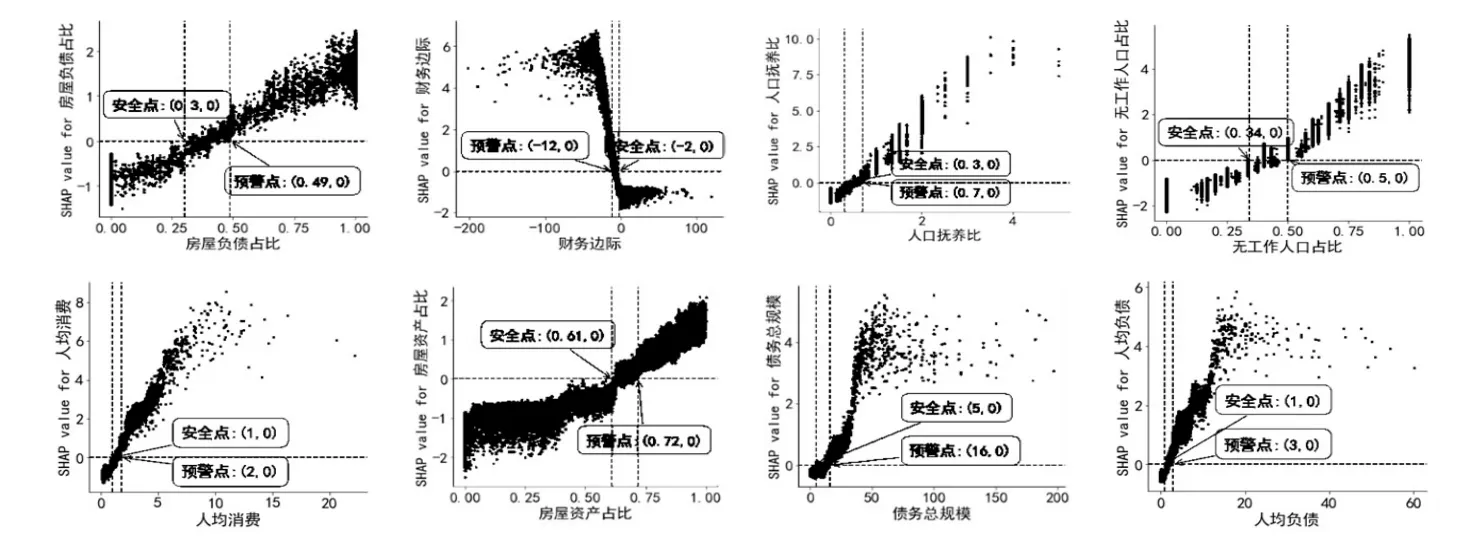
图4:农村家庭8个特征的SHAP值映射图
SHAP值越大,意味着模型将样本预警为高风险状态的概率增加,从图3和图4可以看出,无论是城镇还是农村家庭,我们选取的8个特征和高风险状态之间均呈现出以下特征:①从债务因素层面,随着房屋负债占比、债务总规模和人均负债的增加,SHAP值增加,家庭为高风险的可能性越大。②从人口结构层面,随着人口抚养比和无工作人口占比的增加,对应的SHAP值增加,家庭为高风险的概率增加。③从流动性因素层面,随着房屋资产占比的增加,SHAP值增加,家庭为高风险的可能性越大,而随着财务边际的增加,SHAP值反而减少,家庭为高风险的可能性越小。④从收入支出状况层面,随着人均消费的增加,SHAP值增加,家庭为高风险的可能性增加。
进一步,本文将SHAP值小于0的区间定义为安全区间,将SHAP值大于0的区间定义为预警区间,对应的特征临界点分别为安全点和预警点,城镇和农村家庭8个影响债务风险的重要特征的安全和预警参考值如表6所示。
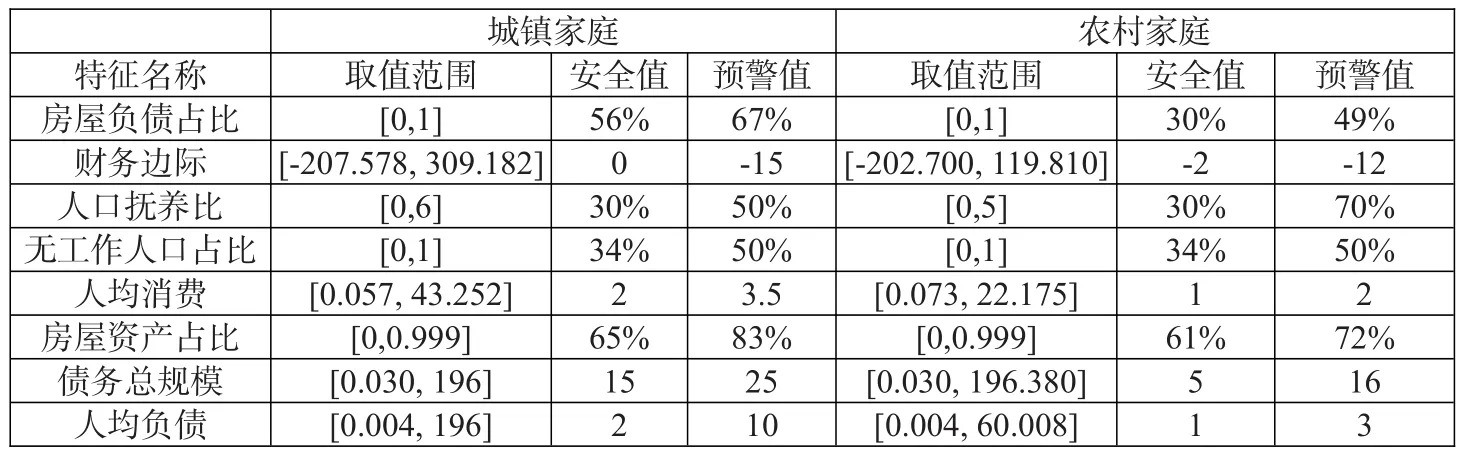
表6:8个特征的安全和预警参考值
由表6知,对于同一个特征而言,城镇和农村家庭的安全值和预警值存在差异。根据预警参考值,本文选取的8个特征对城镇(农村)家庭债务存在明显的非线性效应,具体而言,当某个特征超过以下预警值后,城镇(农村)负债家庭被预警为高风险的可能性会明显增加:①房屋负债占总负债的比重超过67%(49%)(括号内为农村家庭的预警值,下同);②财务边际小于-15(-12)万元;③人口抚养比高于50%(70%);④未参与工作的人口超过总人口的50%(50%);⑤人均消费超过3.5(2)万元/年;⑥房屋资产占比高于83%(72%);⑦债务总规模超过25(16)万元;⑧人均负债超过10(3)万元。
(三)稳健性检验
1.更换参数列表重新调整参数。为克服基本模型的参数列表选择可能存在的局限性,接下来对部分参数列表进行更换。按照给定的新范围采用5折交叉验证和网格搜索重新调整参数,并将learning_rate提高至0.15,最终,城镇和农村的预警模型AUC值分别由最初0.9695和0.9287提升至0.9716和0.9519,效果的提升程度均与基本模型接近,说明基本模型的调参效果已经达到相对最优。
2.更换机器学习方法。为了验证LightGBM模型预警效果的可靠性,引入逻辑回归(Logistic Regression,LR)、决策树(Decision Tree,DT)以及随机森林(Random Forest,RF)作为对比模型,为了防止过拟合,同样采用网格搜索和5折交叉验证分别对其主要参数进行调整。在分别对城镇和农村样本建立上述模型并调参后,所有对比模型的各个评估指标值均低于LightGBM模型,可见无论是城镇还是农村,LightGBM模型效果均最好。
3.更换预警模型解释方法。(1)特征重要性排序。LightGBM模型的plot_importance方法也可以输出特征重要性排序图。根据此方法得出的影响城镇和农村家庭债务风险的共同重要特征与前文SHAP摘要图得出的结论一致。(2)部分依赖图(Partial Dependence Plot,PDP)。PDP图的纵轴为对应特征对模型预测结果相较于基线值的变化,反映了该特征对预测结果的边际贡献。城镇和农村家庭8个重要特征的PDP图分别见图5和图6。根据图5和图6,无论是城镇还是农村家庭,房屋负债占比、人口抚养比、无工作人口占比、人均消费、房屋资产占比、债务总规模以及人均负债的折线均在基线上方(对预测值有正影响),且随着这些特征值增大,正影响越大,即风险越大;而财务边际的折线在基线下方(对预测值有负影响),且随着财务边际的增加,负影响越大,风险越小,这均与SHAP映射图得出的结果一致。类似地,基于PDP图的含义,将对预测值影响显著增加的临界值点作为预警点,各个特征的预警点如对应图中的标注所示,可以发现基于PDP图得到的预警值与前文基于SHAP映射图得到的预警参考值较为接近,这进一步说明了前文的研究结果具有稳健性。
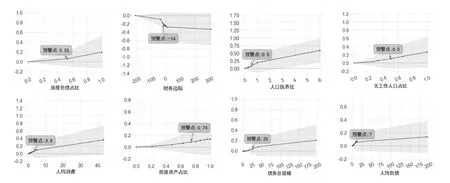
图5:城镇家庭8个特征的PDP图
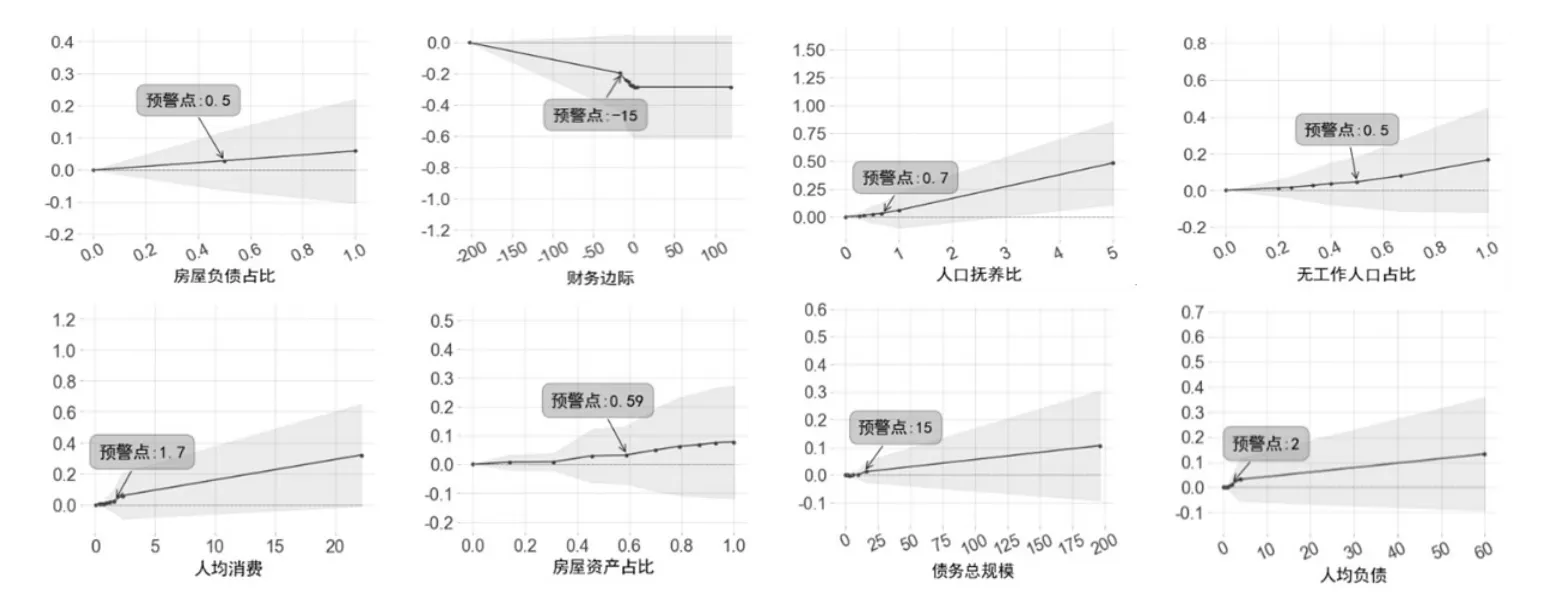
图6:农村家庭8个特征的PDP图
五、研究结论与政策启示
(一)研究结论
本文基于2013年、2015年、2017年和2019年CHFS数据,对中国家庭债务风险进行了测度,并通过构建机器学习模型进行了预警分析,得出以下主要结论:
第一,根据因子分析和层次聚类结果得到中国城镇和农村的高风险率分别约为25.06%和12.29%,且从时间维度来看,不论是城镇家庭还是农村家庭,每年的高风险率均在40%以下,但高风险率均呈上升趋势。进一步的分组分析发现,高风险率在户主不同性别、户主不同婚姻状态以及家庭所处不同地区之间存在差异性,具体表现为户主为女性的家庭、东部地区家庭、户主已婚的城镇家庭和户主未婚的农村家庭为高风险家庭的概率更大。
第二,通过参数调整后,LightGBM取得了较大的性能提升,最终预警结果显示,模型在城镇和农村测试集上AUC值分别达到了0.9725和0.9599,且准确率、精确率、召回率、F1得分也均达到0.9以上,能够实现较好预警效果。
第三,基于LightGBM模型的SHAP特征分析发现,房屋负债占比、财务边际、人口抚养比、无工作人口占比、人均消费、房屋资产占比、人均负债是影响城镇和农村家庭债务风险的主要共同指标。
第四,基于SHAP值的映射关系分析发现,对于一个城镇负债家庭而言,如果其房屋负债占比超过总负债的67%,或财务边际低于-15万元,或人口抚养比超过50%,或超过一半的家庭成员没有工作,则该家庭被预警为高风险的可能性将增加;对于一个农村负债家庭而言,如果其房屋负债占总负债比重接近甚至超过一半,或财务边际小于-12万元,或人口抚养比超过70%,或超过50%的人口没有参加工作,则该家庭被预警为高风险的可能性将增加。
第五,经过更换机器学习参数、机器学习算法以及预警模型的可解释方法,显示本文研究结论具有稳健性。
(二)政策启示
根据研究结论,提出如下政策建议:
第一,我国城镇和农村家庭的整体债务风险虽总体可控,但仍不能忽视家庭债务风险对经济的负面影响。对此,政府可以通过开展免费的家庭金融知识培训等方式提高居民的债务风险意识,引导居民正确评估信贷风险,从而避免过度负债。
第二,基于LightGBM算法的机器学习能够较准确地识别出高债务风险家庭,有较好的预警作用,政府及相关金融部门应当充分利用大数据及机器学习算法的优势,不断完善预警方法,并逐步建立一套统一的家庭债务风险预警机制,对可能存在的高债务风险做到“早识别、早预警、早发现、早处置”,进而降低系统性金融风险发生的概率。
第三,基于家庭债务因素、人口结构、流动性因素以及收入支出状况会显著影响家庭债务的高风险概率,规避家庭高债务风险可以从这几个方面出发。一方面,金融信贷机构在进行放贷决策时,应当重点关注客户的这些指标,合理评估其偿债能力,从而降低被违约的可能性;另一方面,相关机构应当继续构建、完善微观家庭数据库,为进一步建立家庭债务风险预警机制提供更全面可靠的大数据支撑,从而辅助金融机构建立科学合理的债务风险评估体系。
第四,基于城镇和农村家庭的房屋负债占比、财务边际、人口抚养比、无工作人口占比等影响家庭债务风险的重要指标存在不同的高风险预警值,政府和居民家庭应当共同努力,将各个指标值控制在预警值以下。具体而言,一是重视家庭因房屋负债比重过高带来的风险问题,应继续建立完善长效住房保障制度,并继续落实“房住不炒”政策,缓解家庭因贷款购房导致的过度负债问题;二是持续优化金融环境,提高居民金融资产可得性,提高家庭金融资产占总资产的比例,以保证合理的家庭资产流动性,从而提高家庭偿债能力;三是由于无工作人口占比增加会显著降低家庭抵御债务风险的能力,政府应继续完善就业优先政策体系,鼓励创业,多渠道为居民提供更多参与工作的机会,鼓励居民积极就业,降低家庭中无工作人口占总人口的比例;四是由于人口抚养比过高会增加家庭被预警为高风险的可能性,政府应当继续完善养老保险等制度,提高社会保障水平,减轻家庭因生育、教育、医疗以及养老等方面的经济负担。
猜你喜欢
核安全(2022年2期)2022-05-05 06:55:32
中国民间疗法(2021年18期)2021-11-02 08:20:26
煤气与热力(2021年3期)2021-06-09 06:16:28
中华民居(2020年6期)2020-06-09 05:47:48
海峡姐妹(2018年3期)2018-05-09 08:21:06
中国卫生(2016年4期)2016-11-12 13:24:16
外语教学理论与实践(2016年1期)2016-06-11 05:51:40
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:48
中国卫生(2015年3期)2015-11-19 02:53:34
中国卫生(2014年4期)2014-12-06 05:57:16
