
基于双通道语义差网络的方面级别情感分类
2022-02-03 13:12:50曾碧卿徐马一杨健豪裴枫华甘子邦丁美荣程良伦
中文信息学报 2022年12期
曾碧卿,徐马一,杨健豪,裴枫华,甘子邦,丁美荣,程良伦
(1. 华南师范大学 软件学院,广东 佛山 528225;2. 广东省信息物理融合系统重点实验室,广东 广州 510006)
0 引言
对文本数据进行情感信息提取的技术称为情感分析,其定义为: 情感分析是对文本中关于某个实体的观点、情感、情绪以及态度的计算研究[1],情感分析任务主要可分为3类[2]: 文档级、句子级和方面级[3-4]。方面级别情感分类(Aspect-level Sentiment Classifition,ASC)目的是分析句子中不同方面词的情感极性[5],例如,句子“The price of the computer is too expensive, but I'm quite satisfied with its performance and appearance”,这个句子中有三个方面词“price”“performance”,“appearance”,其对应的情感极性分别是消极、积极和积极。方面级别情感分类属于细粒度的情感分类,针对不同的方面词挖掘更加细腻的情感信息,近年来已成为自然语言处理(Natural Language Processing,NLP)领域的重点研究问题之一。
近年来,深度学习技术在学术界持续升温,在不同的领域取得了巨大的成功[6],以卷积神经网络(Convolutional Neural Networks,CNN)[7]、门控循环单元(Gated Recurrent Unit,GRU)[8]以及长短时记忆网络(Long Short-Term Memory Network,LSTM)[9]为代表的深度神经网络模型以及注意力机制[10]在自然语言处理领域得到广泛应用。在方面级别情感分类任务中,结合深度神经网络与注意力机制的模型长久以来占据了主流地位,大量学者对其展开了研究。Ma等人[11]利用两个LSTM分别对上下文文本和方面词进行建模,并采用交互式注意力学习上下文文本和方面词的特征。Fan等人[12]采用LSTM捕获上下文信息,并设计了细粒度注意力以及粗粒度注意力来捕获上下文和方面词的特征信息。Huang等人[13]设计了AOA(Attention-over-Attention)网络,通过双向LSTM分别获取上下文和方面词的隐状态信息,进而计算两者的交互矩阵,通过交互矩阵计算方面词到上下文的注意力、上下文到方面词的注意力以及方面词层面的注意力和上下文层面的注意力,使模型能够有效关注文本中的重点信息,并取得了超过当时所有以LSTM为基础的模型的效果。Yang等人[14]提出了一种联合注意力机制,通过同时对方面词级别和上下文级别注意力进行建模来提取有效情感特征。Song等人[15]构建了一种注意力编码网络,设计了内部注意力以及外部注意力,有效捕捉了上下文内部以及上下文与方面词之间的特征,并取得了当时的最佳效果。杜成正等人[16]设计了一种螺旋注意力,通过方面词与上下文之间的螺旋式交互与加权,有效提取了情感信息,并取得了优异的性能。
上述结合深度神经网络与注意力机制的方法均取得了优秀的效果,但仍存在部分缺陷及不足之处:
(1) 在文本表示上,上述方法在建模过程中均采用分别对整体上下文和方面词进行词嵌入,再进行交互的架构,这种交互架构能够捕捉方面词与上下文的特征信息及方面词与上下文之间的交互信息,但却难以获取依赖于特定方面词的上下文表示,如对文本“Great food but the price was unacceptable”,在对两个不同的方面词“food”和“price”进行情感极性分析时,上述方法只能获取完全相同的上下文词向量。在TOWE(Target-orient Opinion Words Extraction)任务中,Fan等人[17]认为在提取意见词时,在同一文本中,针对不同的意见目标,应当构建依赖于特定意见目标的上下文文本表示。受此启发,本文认为在ASC任务中,由于同一文本往往存在多个不同的方面词,所以在对同一文本中不同方面词进行情感极性分析时,为捕获不同的上下文特征,同样应当构建依赖于特定方面词的上下文文本表示。
(2) 在语义特征上,上述方法中的注意力机制及其变体从不同层面和角度捕捉了上下文内部、方面词内部、上下文与方面词之间的特征信息,但忽略了上下文中方面词双侧文本在整体语义上与方面词情感极性具备不同程度的关联度这一特征。如文本“Great food but the service was terrible”,针对方面词“food”,其左侧文本“Great”和右侧文本“but the service was terrible”与其情感极性具备不同程度的关联,其左侧的文本在整体语义上对其情感极性分析的重要性远高于右侧的文本,同样,针对方面词“service”,其左侧文本“Great food but the”和右侧文本“was terrible”与其情感极性也具备不同程度的关联,其右侧的文本在整体语义上对其情感极性分析的重要性远高于左侧的文本。因此,本文提出语义差这一概念,语义差是指在一个句子中,针对某一方面词,其双侧文本在整体语义上对该方面词的情感极性分析具有不同程度的重要性,通常某一侧文本所包含的促进分析的语义信息远高于另一侧。
针对上述问题,本文构建了双通道语义差网络(Double Channel Semantic Difference Network, DCSDN)。针对问题(1),本文设计了一种双通道架构,利用预训练语言模型从方面词双侧对文本展开建模,以此构建依赖于特定方面词的上下文表示,同时以Sentence-pair的形式构建上下文与方面词之间的交互;针对问题(2),本文设计了语义提取网络与语义差注意力机制,首先通过语义提取网络对双通道中的文本进行语义提取,进而利用语义差注意力机制来增强模型对促进方面词情感极性分析成分的关注。
本文主要贡献总结如下:
(1) 设计了双通道架构,对相同文本中不同的方面词建模时,能够获取依赖于特定方面词的上下文表示。
(2) 提出了语义差这一概念,并据此设计了语义差注意力机制,增强了模型对促进方面词情感极性分析成分的关注。
(3) 构建了双通道语义差网络,在SemEval2014的Laptop和Restaurant数据集以及ACL的Twitter数据集上进行了实验,实验结果表明,该模型的整体性能超过所对比的基线模型。
1 相关工作
在过去的工作中,方面级情感分类方法主要分为基于情感词典、基于传统机器学习以及基于深度学习三种类别。
1.1 基于情感词典的方法
基于情感词典的方法通常会引入一个外部常用的情感词典,如General Inqurer Lexicon、Subjective Lexicon、BosonNLP情感词典、Hownet 情感词典等[18],情感词典里面保存着大量的词、短语及对应的情感极性,该方法通常根据文本中出现的词和短语在情感词典中对应的情感极性来判断方面词的情感极性。基于情感词典的方法十分依赖情感词典的构建,情感词典的质量对方面词的情感极性分析起决定性作用。同时,如何在文本中确定描述方面词情感信息的成分也缺少完善的规则,所以基于情感词典的方法会因为语义表达的多样性(如倒装句等)出现较大误差,现在已经很少单独使用。
1.2 基于传统机器学习的方法
与基于情感词典的方法相比,基于传统机器学习的方法通常有着更好的效果,传统机器学习方法包括支持向量机(Support Vector Machines,SVM)、朴素贝叶斯(Naive Bayes,NB)和最大熵(Maximum Entropy,ME)等[19]。传统机器学习方法需要选择带有语义信息的特征进行训练,有效改善了基于情感词典的方法在匹配过程中由于语义表达多样性所产生的误差。但传统机器学习方法同样存在局限之处,其需要人工特征工程(Feature Engineering),在文本处理中常用的特征有N-Gram,TF-IDF等,人工特征不仅需要耗费大量人力,且泛化能力较差。
1.3 基于深度学习的方法
深度学习这一机制最早由文献[20]提出,与基于情感词典和传统机器学习的方法相比,深度神经网络结构更加复杂,特征拟合能力更强,并且无须人工特征工程,训练深度神经网络虽然计算量巨大,同时也需要大量样本数据,但是近年来硬件算力飞速发展,并且互联网的普及也为搜集大量数据奠定了基础,所以深度学习一跃成为自然语言处理领域最常用的技术,在机器翻译(Machine Translation)、对话系统(Dialogue System)、文本摘要(Text Summarization)等任务中均被广泛应用。
在方面级别情感分类任务中,深度学习同样是最常用的技术。近年来大量学者运用深度学习技术对方面级别情感分类问题展开了研究。Dong等人[21]提出了自适应递归神经网络,利用上下文和语法结构一起作用于方面词,学习语境词对方面词的情感极性影响。Ruder等人[22]提出了一种分层模型H-LSTM来处理方面级别情感分类任务,通过Sentence-level双向LSTM以及Review-level双向LSTM来同时提取句子内部以及句子之间的联系。Tang等人[23]采用深度记忆网络来解决方面级别情感分类问题,通过多个外部记忆网络上的神经注意力模型进行计算,进而捕捉每个上下文单词的重要程度。Ma等人[24]使用方面词级的注意力和句子级别的注意力组成的分层注意力机制来扩充LSTM网络,同时在网络端到端的训练中融入与情感相关的常识。Li等人[25]提出一种CNN变体来取代注意力机制,用于提取上下文中的重要信息,并设计了一种上下文特征保存机制使模型更好地捕获上下文特征。Chen等人[26]提出一种迁移胶囊网络,通过胶囊网络将文档级知识迁移到方面级情感分类任务中,用于解决方面级分类任务数据不足的问题。Du等人[27]利用胶囊网络构建基于向量的特征表示,并提出一种EM路径算法提取特征,同时利用交互注意力来对方面词和上下文的语义关系进行建模。Jiang等人[28]构建了一个大型多方面多情感的数据集用于ASC任务,并设计了一种胶囊网络对该数据集进行情感极性分析。Wang等人[29]设计了一种强化双向注意力网络来解决面向问答领域的方面级别情感分类中的情感匹配以及数据噪声问题。针对文本中的相关句法限制以及远程单词依赖关系,Chen等人[30]在依存句法树的基础上构建了一个图卷积神经网络来挖掘句法信息以及单词之间的依赖。He等人[31]设计了交互多任务学习网络同时作用于方面级情感分类以及方面词抽取任务,与传统多任务学习方法通常为不同任务学习通用特征的做法不同,交互多任务学习网络利用一种消息传递架构使信息通过一组共享的潜在变量迭代地传递到不同子任务。Liu等人[32]提出了门控交替神经网络,利用门控截断RNN来学习依赖于方面词的情感线索表示。Gan等人[33]提出一种基于稀疏注意力的稀疏膨胀卷积神经网络来解决方面级别情感分类中LSTM难以并行化训练以及传统的CNN难以捕获全局特征的问题。Jiang等人[34]提出了一种交互增强转换网络,通过方面词增强模块和双层结构来增强方面词对上下文语义特征的学习,并迭代地增强方面词和上下文的表示。
2 双通道语义差网络
双通道语义差网络(DCSDN)模型如图1所示,共包含5部分:

图1 DCSDN模型
(1)嵌入层(Embedding Layer): 嵌入层将语言文本转换为包含语义的词向量矩阵。
(2)语义提取网络(Semantic Extraction Network): 语义提取网络用于对不同通道中的文本信息进行整体语义提取,进而生成语义值。
(3)语义差注意力(Semantic Difference Attention)机制: 用于对不同通道中的信息施加不同的关注,包括动态语义差注意力(Dynamic Semantic Difference Attention, DSDA)和静态语义差注意力(Static Semantic Difference Attention,SSDA)两种模式。在本文中,采用DSDA的DCSDN模型本文称为双通道动态语义差网络(Double Channel Dynamic Semantic Difference Network, DCDSDN),采用SSDA的DCSDN本文称为双通道静态语义差网络(Double Channel Static Semantic Difference Network,DCSSDN)。
(4)双通道信息融合层(Double Channel Information Fusion Layer): 将双通道中的信息进行融合。
(5)情感分类层(Sentiment Classification Layer): 用于生成方面词情感极性分类结果。
2.1 嵌入层
为构建依赖于特定方面词的文本表示,在嵌入层中,受 Tang等人[35]提出的TD-LSTM启发,本文设计了双通道架构,从方面词双侧对上下文文本展开建模。与TD-LSTM不同的是,本文在嵌入层采用了预训练语言模型BERT(Bidirectional Encoder Representations from Transformers)[36](1)本文中所用的BERT为bert-base-uncased版本。,BERT采用了多层双向Transformer[37]的编码器结构,这种结构能够对输入文本进行整体感知,在处理不同文本中的相同单词时,能够生成不同的词向量。由于每个方面词在文本中的位置不同,即具备不同的上文和下文,本文将这一特征与BERT结合,构建了双通道架构,在左通道和右通道中运用BERT对方面词的上文与下文分别进行词嵌入,通过这一方法,在对同一文本中不同方面词进行情感分类时,由于不同通道每次会因为方面词所处位置的不同而接收到不同的上文文本和下文文本,又由于BERT在生成词向量时会计算全局输入信息,因此DCSDN模型能够根据方面词在文本中所处位置的不同来获取到依赖于特定方面词的文本表示。
同时,为了捕捉方面词与上下文的交互特征,本文采用Sentence-pair的形式对上下文文本与方面词建模。在处理句子对任务时,传统的方法通常先对句子对进行独立编码,再进行双向交互,在BERT中,Devlin等人[36]利用自注意力机制将这两步进行了整合,通过自注意力对拼接的句子对同时进行编码与交互。如图2所示, BERT中采用了两种方式来标示句子对中的不同句子,第一种是在两个句子间添加特殊标记“[SEP]”,第二种是添加段嵌入。

图2 句子对标示

2.2 语义提取网络
语义提取网络由多头自注意力(Multi-Head Self-Attention,MHSA)机制、Pool层和Compress层组成。
2.2.1 多头自注意力机制
与传统注意力机制相比,多头自注意力机制能够学习句子内部的词依赖关系,捕获句子不同层面的内部结构信息,多头自注意力计算过程如式(5)~式(7)(2)本文公式中的不同的W和b均代表线性变换中的映射矩阵以及偏置。所示。
其中,O∈dh×m是不同通道中的词向量矩阵,m为输入到通道的文本长度,其中dq×m,WMH∈hdv×dh,bMH∈dh×m,dq=dk=dv=dh/h,dh是嵌入层生成的词向量的隐藏维度,本文中设置为768,hi代表多头自注意力的第i个head,本文设置了12个head,“;”代表将每一个head进行拼接。经过多头自注意力机制处理得到输出S={s1,s2,…,sm}。
2.2.2 Pool层
Pool层的作用是对文本整体信息进行提取,根据多头自注意力机制的特征,经过多头自注意力计算得到的向量矩阵的每一维度的向量均包含整体文本的语义信息,本文选取S∈dh×m中的s1∈dh×1,即输入文本中“[CLS]”所对应的特征向量进行全连接和激活操作,以此来进行整体信息提取.计算过程如式(8)、式(9)所示。
其中,P∈dh×1是经过Pool层提出得到的包含该通道整体语义信息的特征向量,WP∈dh×dh,bP∈dh×1。
2.2.3 Compress层
Compress层的作用是对Pool层提取出来的包含整体语义信息的特征向量P进行压缩,将其维度转换到1×1,得到整体文本语义值G,计算过程如式(10)、式(11)所示。本文认为整体文本包含有比单个单词更加复杂的特征信息,所以为使特征信息在向量空间得到更加充分的表达,在对特征向量P进行压缩前,本文通过线性变换将P映射到更高维度空间得到H∈2dh×1。同时为了控制语义值的范围以及在双通道中产生有效特征差异的语义值,本文以sigmoid函数为基础,构建了一个语义值函数semantic(x),如式(12)所示。α为语义域值,用于控制语义值的范围。
其中,WH∈dh×2dh,bH、WG∈2dh×1,bG∈1×1,“||”代表取行列式值。
2.3 语义差注意力机制
语义差注意力根据双通道中的语义提取网络提取到的语义值G来对不同通道中的信息施加不同的关注,包括动态语义差注意力(DSDA)和静态语义差注意力(SSDA)两种模式。同时,为缓解特定条件下的语义冗余问题,本节提出语义掩盖机制(Semantic Mask Mechanism,SMM)。
2.3.1 语义掩盖机制
语义掩盖机制是指当某一通道中仅包含方面词时,对这一通道中的词向量矩阵O进行掩盖。当某一通道中仅包含方面词,不包含其余上下文文本时,由于另一通道中已包含方面词语义信息,本文认为这一通道中的信息会造成语义冗余问题,对其进行掩盖,能有效减少其对后续分类任务的干扰。
本文以方面词左侧文本是否为空来判断左通道中是否含有除方面词以外的语义信息,以方面词右侧是否仅含有结束符来判断右通道中是否含有除方面词以外的语义信息,本文取最常用的三种结束符“.”“!” “?”作为句末结束判断条件。ML为左通道语义掩盖值,MR为右通道语义掩盖值,textleft代表方面词左侧文本,textright代表方面词右侧文本。计算过程如式(13)~式(15)所示。
2.3.2 动态语义差注意力
DSDA动态地为双通道信息进行加权,根据语义提取网络提取的左通道语义值GL和右通道语义值GR以及由语义掩盖机制生成的左通道语义掩盖值ML、右通道语义掩盖值MR来计算最终的左通道动态注意力值DL和右通道动态注意力值DR,最后对左通道中的词嵌入OLeftchannel∈dh×m以及右通道中的词嵌入ORihgtchannel∈dh×m进行加权,得到左通道输出OL∈dh×m和右通道输出OR∈dh×m。计算过程如式(16)~式(19)所示。
2.3.3 静态语义差注意力
在SSDA中,本文首先设置一个静态高权值Whigh和静态低权值Wlow,本文中设置的默认Whigh为0.8,默认Wlow为0.6,然后根据GL、GR、ML、MR来计算最终的左通道静态注意力值SL和右通道静态注意力值SR。具体计算方法如下: 当ML、MR均为1,即双通道中均包含除方面词以外的语义信息时,语义值高的通道被赋予Whigh,语义值低的通道被赋予Wlow;当ML⊕MR=1,即双通道中有且仅有一个通道包含除方面词外的语义信息时,赋予包含其他语义的通道的注意力值为Whigh,不包含的为Wlow;当双通道中均不包含除方面词外的语义信息或双通道中均包含除方面词外的语义信息但双通道中的语义值相同时,双通道中的注意力值均被赋予1。最后,同样对双通道中的信息进行加权并得到双通道的输出,计算过程如式(20)~式(23)所示。
2.4 双通道信息融合层
双通道信息融合层首先对经过语义差注意力机制加权的双通道输出OL、OR进行拼接,然后对拼接后的向量进行降维,计算如式(24)、式(25)所示。
其中,OLR∈2dh×m代表将双通道输出拼接后的结果,WF∈2dh×dh,bF∈dh×m,其中,Funsion∈dh×m代表降维后的双通道信息融合层的输出的融合特征向量。
2.5 情感分类层
情感分类层的作用是对整体信息进行提取并分类得到最终结果,计算过程如式(26)~式(28)所示。
其中,K∈dh×1是由pool层提取得到的双通道信息融合后的整体语义特征向量,此处pool层的原理同2.2.2节。Out∈3×1是将提取出来的整体信息进行降维得到的结果,其中每一个元素代表对应的情感极性的值。WK∈dh×3,bK∈3×1。最后本文通过argmax函数选取Out中最大值所对应的情感极性sentiment为方面词的情感极性。
3 实验
3.1 实验数据集
为了验证模型的性能,本文采用SemEval2014的Laptop和Restaurant数据集(3)http://alt.qcri.org/semeval2014/task4/以及ACL的Twitter数据集(4)http://goo.gl/5Enpu7进行实验,数据集中的数据统计如表1所示。
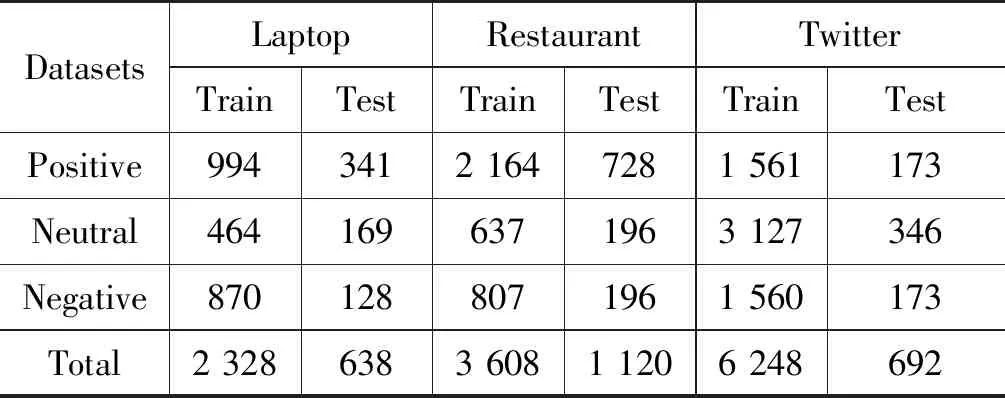
表1 数据集统计
3.2 模型训练
本文采用交叉熵函数作为目标函数,如式(29)所示。
(29)

本文采用Adam[38]算法来对目标函数进行优化,并同时采用了dropout和L2正则化来防止模型过拟合,本文实验所采用的超参数如表2所示。

表2 超参数设置
3.3 评价指标
本文的实验采用准确率(Accuracy)和宏平均F1值(Macro averageF1, MF1)作为评价指标,计算方法如式(30)~式(34)所示。
(30)
(31)
(32)
(33)
(34)
对某一个情感极性类别i,TPi是正确预测的样本数量,FPi是其他类别的样本被预测为当前类别样本的数量,FNi是当前类别的样本被错误地预测为其他类别的样本的数量。Pi是指情感极性类别i上的精确率(Precision),Ri是指情感极性类别i上的召回率(Recall),MF1是所有类别F1的平均值。
3.4 对比模型
(1)AE-LSTM[39]: 利用LSTM对上下文进行建模,并利用注意力机制计算不同单词的权重值。
(2)ATAE-LSTM[39]: 在AT-LSTM的基础上进一步利用方面词信息,将方面词嵌入和上下文嵌入拼接。
(3)IAN[11]: 利用两个LSTM分别对上下文文本和方面词进行建模,并采用交互式注意力学习上下文文本和方面词的特征。
(4)RAM[40]: 提出了一种基于多重注意力的框架,利用多重注意力对双向LSTM和其位置加权结果进行建模。
(5)BMAM[41]: 设计了陈述性记忆注意力机制和程序性记忆注意力机制用于捕获与方面词相关的词级别和短语级别信息,并设计了一个分段解码器来提取相关情感语义信息。
(6)MGAN[12]: 采用LSTM捕获上下文信息,并设计了细粒度注意力以及粗粒度注意力来学习上下文和方面词的特征。
(7)AOA[13]: 通过计算方面词内部、上下文内部和方面词与上下文之间的注意力来捕捉不同层面的特征信息。
(8)BERT_PT[42]: 提出了一种后训练的方法对BERT进行调整,让其包含更多的领域知识和任务知识,以更好地适应当前任务。
(9)AEN_BERT[15]: 提出了一种注意力编码网络,设计了内部注意力和外部注意力来捕捉上下文内部及方面词与上下文之间的语义特征。
(10)BHAH[16]: 提出一种螺旋式注意力来对方面词与上下文进行螺旋式加权,以此来提升方面词与上下文表示。
3.5 对比实验及分析
对比实验结果如表3所示,其中,BHAH模型效果“81.35(5)”中的“(5)”代表采用5层螺旋注意力层,DCDSDN模型效果“81.35(1.0)”中的“(1.0)”代表语义域值α为1.0,“-”代表在原文中未报道的结果。根据表中结果,本文分析如下所述。

表3 不同模型的实验结果 (单位: %)
(1) 在整体上,DCDSDN模型的准确率要优于其他模型,MF1值也要优于其他已报道MF1值的模型,这说明了本文所设计的DCDSDN模型的有效性。与其他模型相比,DCSSDN模型能够利用双通道架构获取依赖于特定方面词的上下文表示,针对相同文本中的不同方面词,能够捕获特定的上下文特征。同时,语义提取网络以及动态语义差注意力能够使模型关注重点通道中的语义信息。
(2) DCSSDN模型的准确率优于BHAH以外的模型,MF1值同样优于已报道MF1值的模型,这同样说明了DCSSDN模型的有效性,同时,其整体效果差于DCDSDN模型,本文分析主要原因是动态语义差注意力能够根据双通道中的语义差异动态地调整注意力值以更好地拟合语义特征。但本文认为当处理语义差现象不明显的文本时,静态语义差注意力更有优势。
3.6 消融实验
为了探究模型中不同部分对模型准确率的影响,本文设计了如下几种模型进行消融实验:
(1)DCDSDN_V1: 在DCDSDN的基础上去掉语义差掩盖机制。
(2)DCDSDN_V2: 在DCDSDN的基础上去掉以句子对的形式输入上下文和方面词,直接将它们作为单个句子拼接输入。
(3)DCSSDN_V1: 在DCSSDN的基础上去掉语义差掩盖机制。
(4)DCSSDN_V2: 在DCSSDN的基础上去掉以句子对的形式输入上下文和方面词,直接将它们作为单个句子拼接输入。
(5)DCSDN_V1: 在DCSDN的基础上去掉语义差注意力机制。
(6)DCSDN_V2: 在DCSDN_V1的基础上去掉以句子对的形式输入上下文和方面词,直接将它们作为单个句子拼接输入。
(7)DCSDN_V3: 在DCSDN_V1的基础上去掉双通道架构
其中,DCDSDN模型及其变体模型的语义域值本文统一设定为1.0,DCSSDN模型及其变体模型的静态高权值本文统一设定为0.8, 静态低权值本文统一设定为0.6。实验结果如表4所示,本文分析如下:
(1) 仅在去掉语义差注意力后,DCDSDN和DCSSDN在三个数据集上的准确率分别下降了2.20%、0.9%、2.03%和1.1%、0.9%、1.31%。这充分说明了语义差注意力机制的有效性,同时印证了语义差这一概念的合理性,去除语义差注意力之后的模型由于无法捕捉双通道信息的差异,进而导致模型准确率下降。
(2) 仅在去掉语义掩盖机制后,DCDSDN和DCSSDN在三个数据集上的整体准确率也有一定下降。在去除语义掩盖机制之后,当方面词在句首或句尾时,双通道架构在捕捉信息时可能产生语义信息冗余问题,进而干扰模型分类效果。
(3) 所有去掉以句子对的形式对上下文和方面词建模的模型与其基础模型相比效果均有所下降。在去掉句子对的建模方式后,导致模型在通道内部难以捕捉方面词与上下文的交互信息,进而造成模型准确率下降。
(4) DCSDN_V2在去掉其双通道架构后,模型准确率分别下降了0.47%、1.25%、0.29%。在去掉双通道架构后,针对同一文本中的不同方面词,模型只能获取相同的上下文表示,无法捕捉不同方面词的特定上下文特征。同时,本文发现在Twitter上准确率下降较低,本文分析其原因是 Twitter数据集中仅收录单方面词文本,在对单方面词文本进行分析处理时,双通道架构的优势难以得到充分发挥。
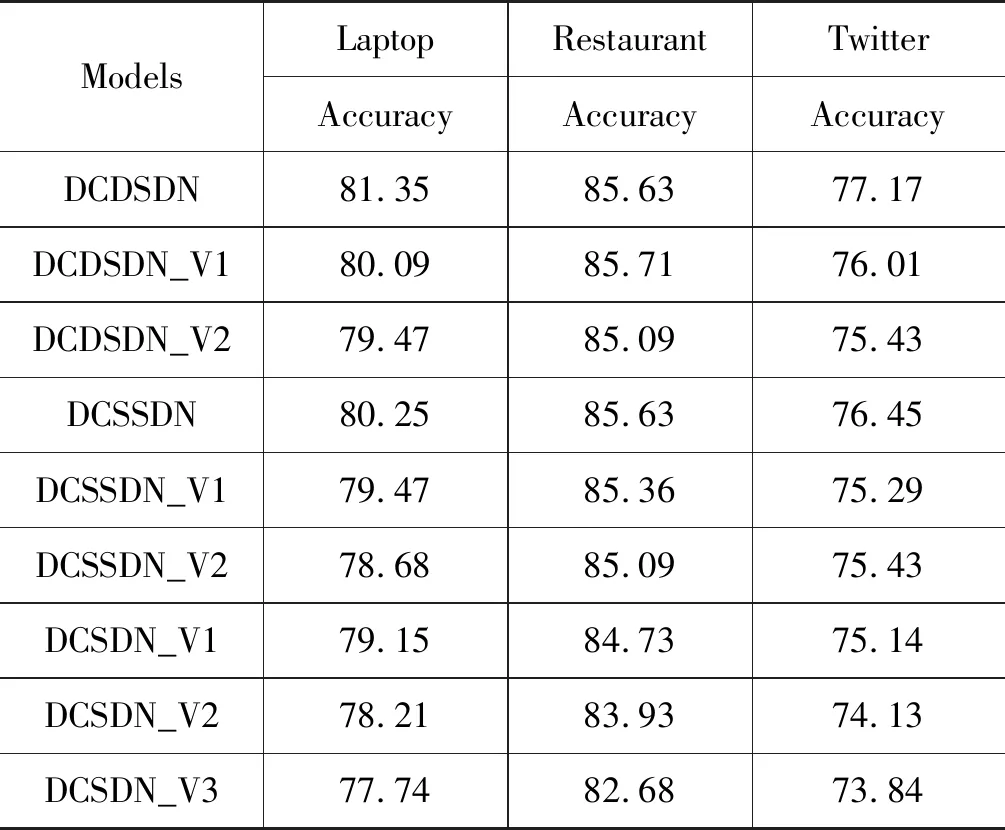
表4 消融实验结果 (单位: %)
3.7 语义域值实验及分析
为探究不同语义域值α对模型准确率的影响,本文在DCDSDN模型上选取[0.1,2.0]之间的20组不同的语义域值进行实验,实验结果如图3所示。根据实验结果,本文分析如下:

图3 不同语义域值下的模型准确率
(1) 语义域值较低时,模型准确率通常较低,本文分析其主要原因是过低语义域值会导致后续动态语义差注意力数值过低,从而使词向量被过度压缩,难以充分表达语义。
(2) 在Twitter数据集上,不同语义域值下的模型准确率波动较大,本文分析其主要原因是Twitter数据集中的数据包含大量语法不规则文本以及特殊符号。
3.8 静态语义差注意力分析
为分析不同静态权值组合对模型准确率的影响,本文在DCSSDN模型上选取了[0.0,1.0]区间中不同静态权值组合进行了实验,实验结果如图4~图6所示,同时,本文计算了在三个数据集上不同差值静态权值组合的平均准确率(Average Accuracy),如图7所示。根据实验结果,分析如下:

图4 Laptop数据集上不同静态权值组合的准确率

图5 Restaurant数据集上不同静态权值组合的准确率

图6 Twitter数据集上不同静态权值组合的准确率

图7 不同差值的静态权值组合的平均准确率
(1) 当静态高权值相同时,静态低权值为0.0时模型效果最差,这说明语义值低的一侧不仅包含干扰信息,同时也包含一定的有效语义信息,若完全丢弃掉语义值低的一侧所包含的信息,则会在整体上给模型准确率带来负面影响。
(2) 当静态高权值远高于静态低权值时,模型的平均准确率整体上较低,当静态高权值与静态低权值的差值在[0.1,0.4]区间中时,模型平均准确率通常较高,这说明较大差值会导致大量语义信息流失。
3.9 实例分析
为了进一步分析DCSDN模型的效果,本文抽取了几组测试数据集中的语义差注意力权值,可视化结果如图8所示,其中图8(a)、图8(b)是根据动态语义差注意力抽取得到的,图8(c)、图8(d)是根据静态语义差注意力抽取得到的。如在图8(a)中,针对文本“It is the perfect size and speed for me.”中的方面词“size”,在分析其情感极性时,其左侧文本的重要程度明显远高于右侧,在动态语义差注意力的作用下,模型能够对这一部分施加更多关注。在图8(c)中,针对文本“It’s so quick and responsive that it makes working / surfing on a Computer so much pleasurable !”中的方面词“working”, 其右侧文本的重要程度明显远高于左侧,在静态语义差注意力的作用下,模型能够对这一部分施加更多关注。这表明语义差注意力能够对文本中包含更重要信息一侧的文本施加更多的关注,从而增强模型分类效果。
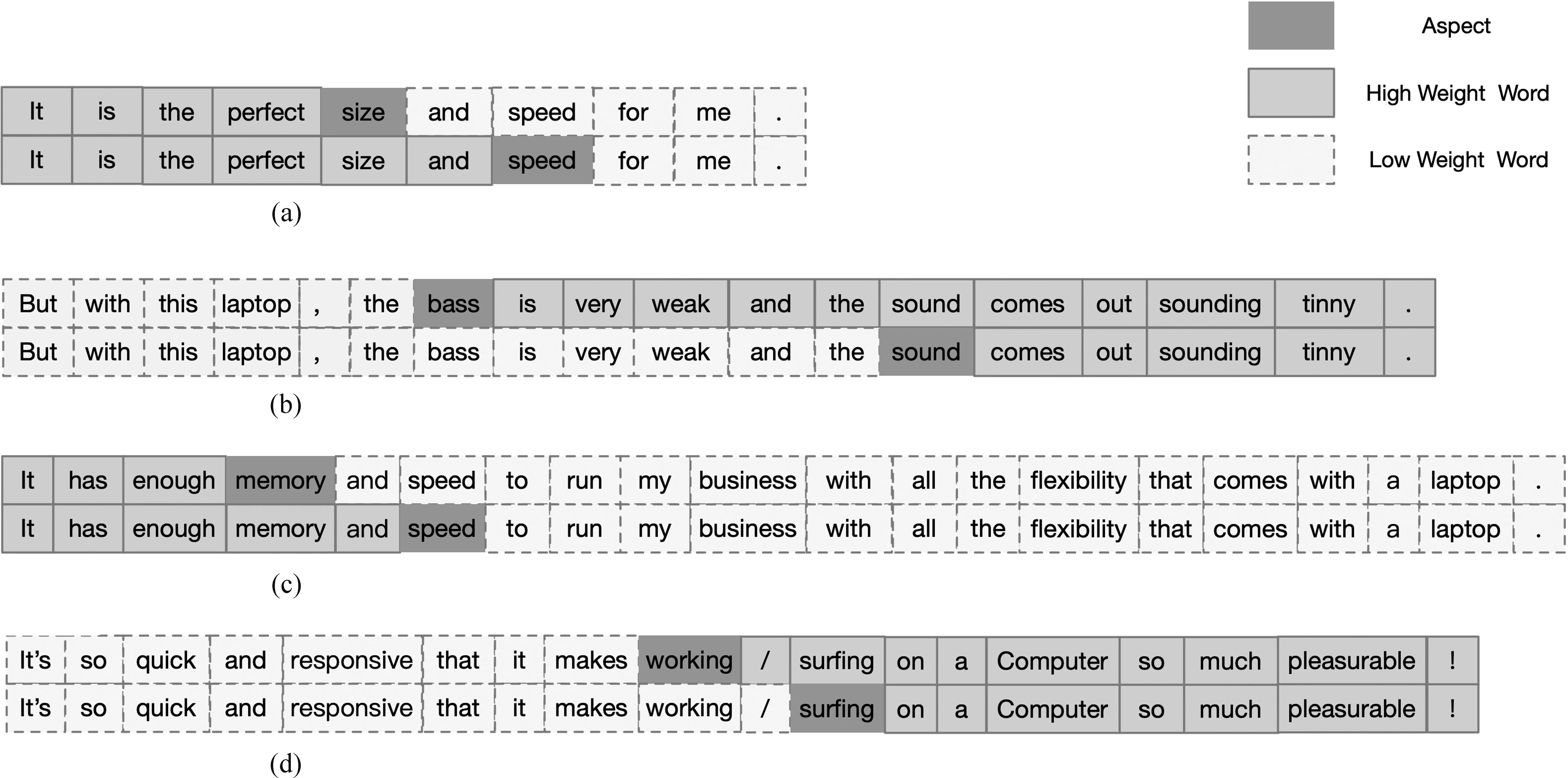
图8 数据可视化
4 总结
为了构建依赖于特定方面词的上下文表示,本文设计了一种双通道架构,针对同一文本中的不同方面词,利用预训练语言模型的全局感知特性以及方面词的位置特性在双通道中捕获不同的上下文信息。为了拟合语义差特征,本文构建了语义提取网络及语义差注意力机制,通过对不同通道进行语义特征信息提取,并根据双通道文本在整体语义上的差异,利用语义差注意力对重要通道中的信息施加更多关注。实验结果表明,本文提出的双通道语义差网络模型取得了优异的性能,有效证明了本文所提出的理论的合理性以及设计的模型的有效性。
未来工作中: ①将针对双通道架构中的跨通道信息交互问题进行进一步研究; ②将结合依存句法分析对语义差进行进一步拓展性研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
昆明医科大学学报(2021年4期)2021-07-23 01:21:56
时代英语·高一(2019年5期)2019-09-03 02:09:34
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电测与仪表(2016年11期)2016-04-11 12:20:42
电源技术(2015年5期)2015-08-22 11:18:28
电子设计工程(2015年16期)2015-02-27 12:07:56
教育与职业(2014年31期)2014-01-19 01:48:18
城市道桥与防洪(2013年8期)2013-03-11 15:18:23
