
基于Inception-V3网络的多任务人脸属性识别研究
2022-02-03 02:42杜炳德赵雅琪
无线互联科技 2022年22期
谭 彬,杜炳德,赵雅琪
(山西农业大学 信息科学与工程学院,山西 太谷 030801)
0 引言
目前,深度学习的发展越来越快,人脸属性识别也成了深度学习的一个重要研究领域[1]。人脸包含很多属性特征,比如性别、微笑、眼镜等,人脸多属性识别检测到一张图像时,对图像处理并返回一些人脸信息。基于人脸多属性识别技术可应用在智慧公安系统[2]、教学管理系统等诸多领域[3]。
传统的人脸识别包括对图像进行特征提取以及进行分类器的训练[4]。随着人脸属性识别算法不断发展,对应的神经网络逐渐加深,识别效果也逐步提升。随着网络加深,参数也必定会增多。因此本文采用一种基于多任务网络的人脸识别技术。通过共享Inception-V3主干网络,大大地减少了模型参数,并且加快了训练速度。将一种属性对应一个分支网络,构建多分支网络,联合学习多个属性,增强属性之间的相关性。此方法模型参数较少,准确率较高,具有很大的研究意义。
1 网络基础
本文搭建了一个多任务网络来完成人脸识别任务,为了减少计算量和网络参数,通过使用共享的Inception-V3主干网络进行特征提取[5],然后将得到的特征输送给搭建好的4个分支网络,最终完成多任务网络的训练和测试。
1.1 Inception-V3主干网络
为了保持神经网络结构的稀疏性,又能充分利用密集矩阵的高计算性能。Google团队提出Inception结构,相较于传统的卷积神经网络来说,Inception的计算量比传统的卷积神经网络更少,控制了参数量和计算量的同时,获得了非常好的分类性能。Inception-V1有22层,比VGGNet的19层更深但参数更少,表达能力更强。采取多个尺度的卷积核进行特征提取,其中包括1×1、3×3、5×5,通过1×1卷积核降低通道数量,可以加速网络学习。该网络结构在增加了网络深度,提升了网络普遍性。原始的Inception模块如图1所示。

图1 原始的Inception模块
后续Inception模块在原始的Inception模块上进行了改进,Inception-V2是使用小卷积替换了大卷积,使用两个3×3卷积替换了一个5×5的卷积,分解前后的感受野相同,并且增强了representation能力,分解之后可以多加一个激活函数,增强了非线性表达能力。Inception-V2还提出了著名的Batch Normalization算法,该算法是将网络的输入数据进行归一化处理,让梯度增大,避免梯度消失现象,加快训练速度和收敛速度。Inception-V2模块如图2所示。

图2 Inception-V2模块
在此基础之上,Inception-V3引入了非对称卷积,将N×N结构分解为1×N和N×1的叠加,分解之后的感受野还是与原来的感受野相同,并且进一步减少了计算量、加快训练测试速度和减轻过拟合。此外,Inception-V3网络优化了Inception-module结构,优化后的Inception-module应用在网络后面部分,浅层还是使用了普通的卷积层,以确保网络可以有效提取更多的特征。
1.2 分支网络
多任务学习是一种归纳迁移机制[6],多任务学习方法基于同一个主干网络,在浅层的卷积层共享特征,在深层的卷积层则开始对每个任务分别学习。其中每个属性对应一个学习任务,将主干网络的输出作为每一个分支网络的输入,最终完成对分支任务的学习。该方法通过共享的主干网络,大大减少了整体的计算量,并且能够将多个任务之间关联起来进行学习,最终能够得到更优的学习效果。本文搭建了一个多任务网络模型,多任务网络模型如图3所示。

图3 多任务网络框
2 人脸属性识别整体流程设计
本文设计了一种基于多任务学习网络的人脸属性识别方法,整体的网络结构如图4所示,其中包含了主干共享网络和属性识别分支网络。
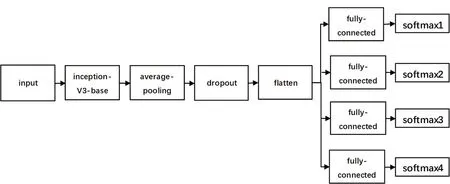
图4 整体网络结构
本文基于Inception-V3进行了改进,并且延展了分支网络,组成了一个多任务学习网络。本文中采用小卷积核来改进传统的卷积核,保证感受野不变的同时将参数量也减少了,并且还能增加更多的relu激活函数。输入大小为三通道的180×180的图片,进入主干网络进行一系列卷积操作,主干网络部分是多个 1×1 的小卷积和3×1与1×3的非对称卷积的组合,在卷积层之间加入relu激活函数,可以增加网络的非线性,使网格具有稀疏性,减少过拟合的风险。
在主干网络中加入BN层,目的是在网络的每一层输入的时候,插入一个BN层,也就是先进行归一化处理,然后再进入网络的下一层。归一化公式如下:
一层有d维输入:x=(x(1)…x(d))
注:所用药物统一为:拜阿司匹林为拜耳公司生产的阿司匹林肠溶片;阿托伐他汀钙为辉瑞制药有限公司生产的立普妥。
(1)
(2)
增加了BN层之后,能够改善流经网络的梯度、允许更大的学习率、大幅提高训练速度。
主干网络输出的值,首先通过一个average-pooling层,将当前的特征图进行平均操作,减少空间信息也就是减少参数。随之在average-pooling层后加一个dropout层,不仅解决过拟合问题还加快了训练速度。然后再加一个flatten层,该层用来将输入压平,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。最后即可得到分支网络的输入。
主干网络搭建完成之后,进行搭建分支网络,定义4个属性,分别是glasses,smile,young,male。分支网络使用二分类网络对4个属性进行处理,最终输出结果为0或1,其中1表示具有该属性,0表示不具有该属性。本文使用4个全连接层分别对各分支网络的输入数据进行处理,处理后输出一个二维的数据。在最后一层加入softmax函数,softmax适用于解决多分类问题,当分类情况只有两种的时候,softmax就转换成了回归问题,也就是二分类问题,对应的softmax的表达式如下:
(3)
该函数进行结果的预测,将最终结果约束到[0,1]之间,将得到的预测结果与真实结果进行比较,比较他们的拟合效果,通过损失函数的大小,不断修正模型参数。
3 实验
3.1 数据准备和数据打包
本文采用了香港中文大学发布的CelebA人脸属性数据集,该数据集提供了人脸对齐和自然场景下近20万张人脸图像,标注了40种人脸属性和5个人脸关键点的位置信息。本文只使用其中4个人脸属性进行具体的研究,以这4种属性来验证该网络模型的可行性。这4个属性分别是glasses,smile,young,male。
首先通过opencv库对图片进行读取,将读取到的图片通过dlib库中的人脸检测器识别出人脸的位置,并且裁剪人脸区域的图像,通过检测出来的人脸框数据,把数据中较小的人脸图片过滤掉。把最终得到的图像resize至128×128的大小,将图像的类型转换成bytes类型,方便后续打包。
然后从标注文件中提取4个属性对应的属性值。遍历标注文件(txt文件)中的属性名所对应的一行,通过split函数对属性名进行分隔,得到4个属性所对的下标值。对每一行的标注信息也通过split函数进行分隔,结合得到的下标值和分隔后的标注信息就能够得到图片中4个属性对应的属性值,其中1表示是该图片具有该属性,-1表示否。实验中将处理后的图像数据与对应的4个属性值的数据结合起来完成数据打包,把最终打包的文件保存为tfrecord类型文件。
3.2 模型训练
指定训练的参数之后,传入tfrecord文件进行训练,训练时将shuffle参数置为True,通过shuffle实现数据增强。在标注信息中,需要将原来的标注信息的值为-1和1转换为0和1,其中1表示具有该属性,0表示不具有该属性,使得后续预测的时候输出的是0和1。将最终训练好的模型保存为ckpt文件。然后将保存的网络模型进行网络固化,将ckpt文件转为pb文件,使用pb文件实现前向推理。
3.3 损失函数和评价方法
损失函数的作用是描述模型的预测值和真实值之间的差距大小,使得模型通过不断地训练来变得收敛。对于多任务网络结构,本文采用交叉熵损失函数对模型进行训练[7]。对输入的logits先通过softmax函数计算,再计算交叉熵损失函数,交叉熵损失函数的公式如下:
(4)

随着训练次数的增加,不断更新网络参数,来减少损失函数的大小,实现模型的高精确性。本文中每一个属性对应一个损失函数,然后将4个损失函数相加得到一个总的损失函数,总的损失函数的变化如图5所示。
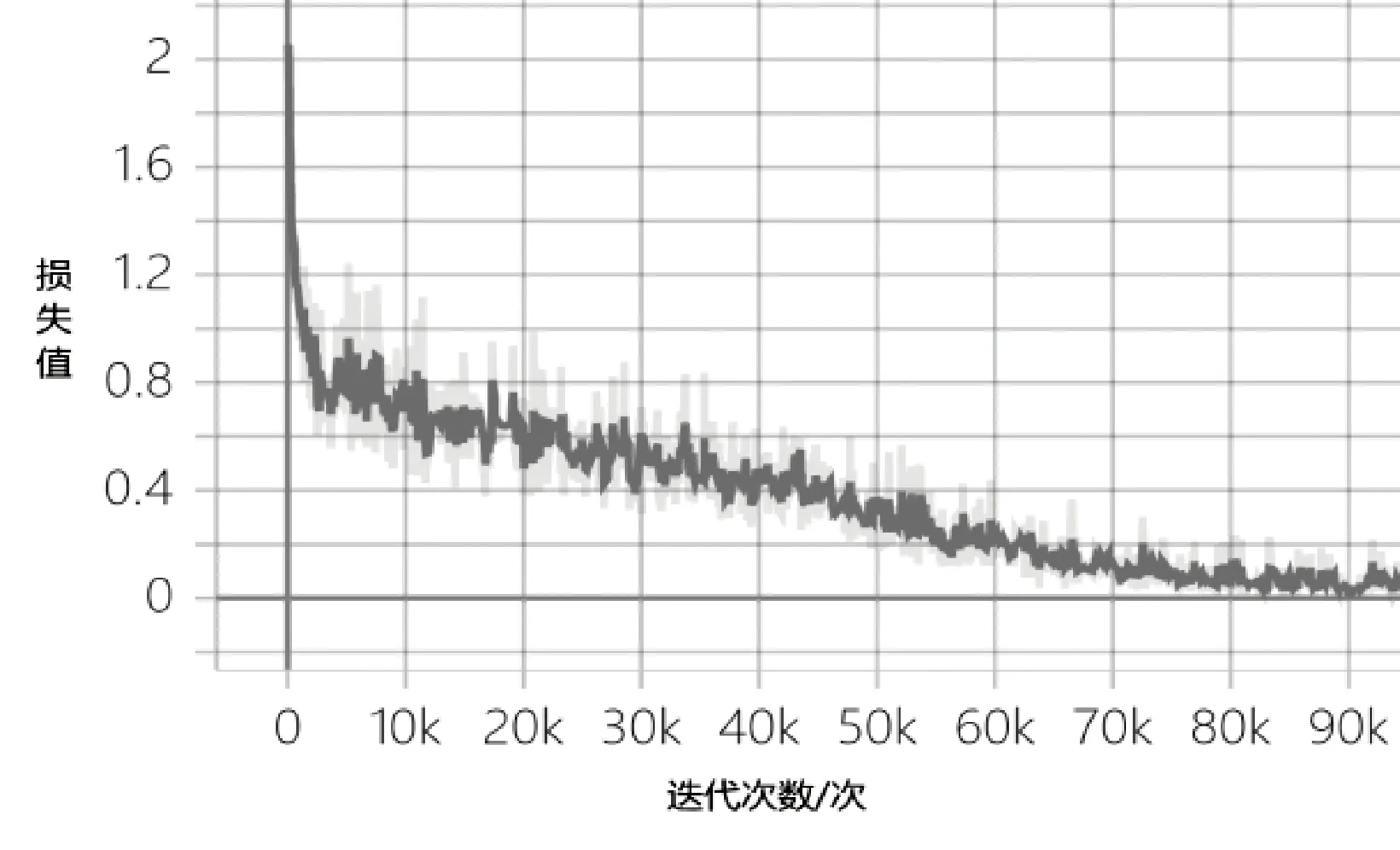
图5 损失函数的变化情况
本文采用准确率(ACC)作为模型的评价标准,准确率(ACC)是指分类正确样本个数与总样本数的比值,公式如下:
(5)
公式(5)中TP表示被模型预测为正的正样本,TN表示被模型预测为负的负样本,FP表示被模型预测为正的负样本,FN表示被模型预测为负的正样本。
3.4 实验结果与分析
选取300张人脸图片进行测试,多任务网络模型逐一读取图片,并且完成多属性识别任务,得到如表1所示的准确率。实验表明,基于Inception-V3改进的多任务网络人脸属性识别模型的平均分类准确率可达89.09%,准确率较高,进一步证明了该模型对于人脸属性识别的可行性,能够较好地应用在信息安全等领域,具有较高的研究价值。
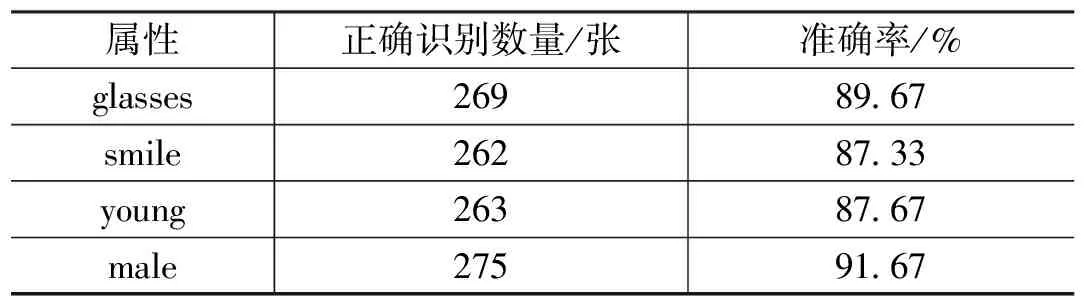
表1 各属性的识别准确率
4 结语
本文结合深度学习进行人脸属性的识别,基于Inception-V3网络为主干网络,并对其进行扩展和优化,搭建了多任务网络结构,使用此网络结构的人脸属性识别有效地降低参数量,准确率最高可达91.67%,证明了该网络的可行性。人脸属性识别的应用领域越来越广泛,为教育、公安等部门提供了很好的技术方案,其应用前景非常广阔。
猜你喜欢
军事文摘(2024年2期)2024-01-10
广东教育·高中(2022年1期)2022-03-16
少儿美术·书法版(2021年9期)2021-10-20
中国生物医学工程学报(2019年6期)2019-07-16
动漫星空(2018年9期)2018-10-26
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
新课程研究(2016年21期)2016-02-28
中国交通信息化(2015年2期)2015-06-05
发明与创新(2015年33期)2015-02-27
