
基于k-means 算法的学生在线学习行为研究
2022-02-02 03:38蹇旭陈婷
高师理科学刊 2022年12期
蹇旭,陈婷
(阿坝师范学院 计算机科学与技术学院,四川 汶川 623002)
在大数据时代下,我国社会的各个行业都在产生海量的数据,并随着现代信息技术的发展逐渐形成“互联网+”的行业模式[1-2].在教育行业中,“互联网+教育”这种新型的学习模式,依托在线学习平台,促使学生的学习模式从传统的课堂教学向传统与在线平台相结合的模式转型.然而,随着在线学习平台用户数量的增加和技术的发展成熟,这种模式也面临着挑战[3-4].由于互联网学习的自由性,在线学习课程完成率成为了当前教育人员重点关注的问题[5].在此背景下,大量业界学者及相关人员对学生的在线学习行为进行分析探讨,以提高在线学习的成绩.有学者认为,对学生在线学习行为进行研究,挖掘其数据并归纳分类,总结在线学习行为模式,从而帮助在线学习平台优化自身的服务结构,推动“互联网+教育”新型学习模式的发展[6].学习者的行为数据是研究学生在线学习行为的前提和基础,但由于目前平台数据呈现海量分散的特点,导致采集数据缺乏全面性,数据分类效率和准确性较低,影响在线学习行为研究结果的可靠性.
本文结合k-means 聚类分析的算法,针对学生在线学习行为进行研究,以期获得更为精准的在线学习行为研究结果.
1 采集学生在线学习行为数据
与传统教学模式相比,在线学习作为打破时空限制的新型学习模式,同样涵盖多种学习者的学习行为,如根据教学者提前布置的任务进行预习,观看课堂视频资源,课后完成作业及学习者之间相互的沟通交流等,这些在线操作都会留下痕迹并且产生海量的数据[7-8].如何全面有效地采集学生在线学习数据成为研究在线学习行为的基础,也是学生在线学习行为分类的基础.由于学生学习行为数据类型多样,海量且复杂,为全面覆盖并采集,可以借助xAPI 技术模型,减少数据采集过程中的遗漏,其流程见图1.
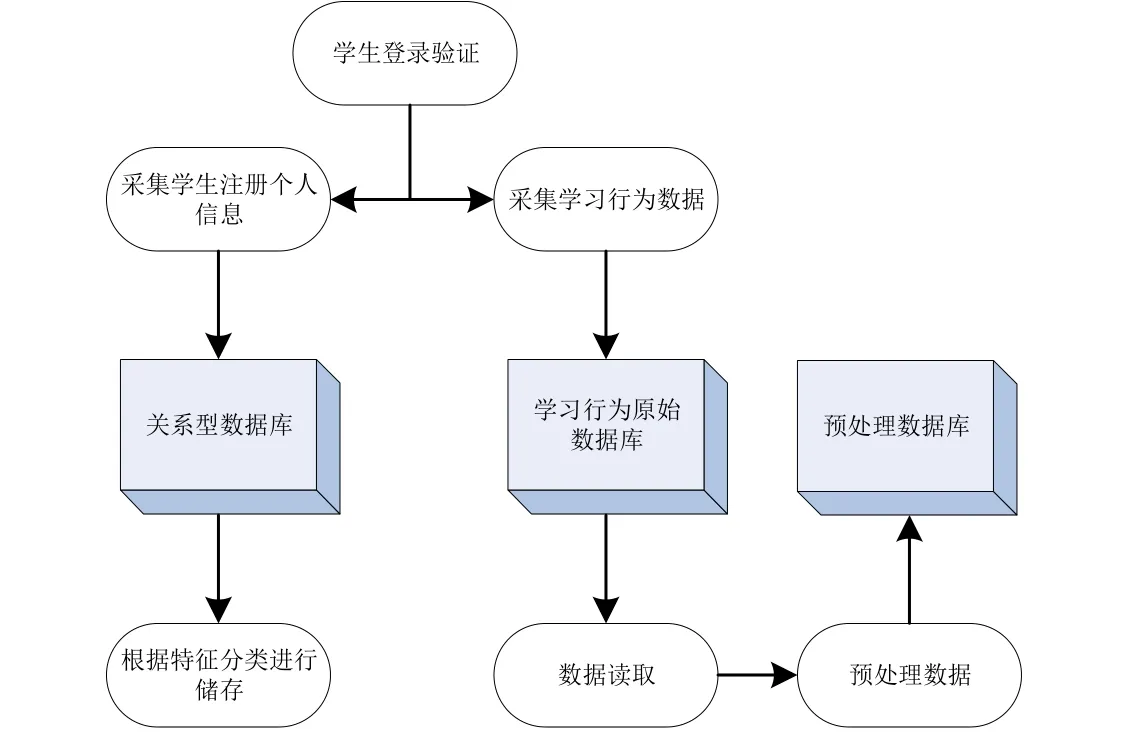
图1 在线平台学生数据采集流程
根据图1采集流程可知,学生在线学习过程中产生的数据大致分为2类,即个人信息和学习行为数据.学生个人信息的采集流程较为简单,在学生首次注册在线学习平台账号时进行,之后输入到关系型数据库并根据特征分类储存.学生学习行为数据的采集则更为重要,首先根据学生在线学习时的操作记录,形成一个原始未经处理的学习行为数据库,其次利用模型对海量数据进行读取和识别的预处理,并大致分为4类:学生轨迹数据,具体表现为在线学习过程中的浏览痕迹等;在线学习的核心学习行为,具体内容为学习者观看了何种视频资源或课件;社交交互行为,即学生在学习过程中的交流频率如何;学习评价行为,代表某一阶段的学习结束后,学生利用在线学习平台获得的评价.根据不同类别学习行为中设定的评价指标对学生在线学习行为进行属性评价[9-10].
利用xPAI 技术模型采集数据可以将学习行为数据单独进行提取,尽量提高覆盖率,避免遗漏.同时,在储存前对采集数据进行预处理,降低学习行为原始数据的重复率,为研究学生在线学习行为提供数据处理上的保障.
2 利用k-means 算法分类在线学习行为
k-means 算法是以种类划分为基础的聚类算法,其种类划分的标准是度量每个数据的距离相似性,该算法能够高效迅速地对数据进行处理,因此常用于对大规模海量数据进行聚类处理.首先,k-means 算法要求给定一个包含大量数据样本的数据集以及聚类数目的具体数值;其次,随机抽取样本作为算法初始的中心点,再计算其余样本与初始中心点间的距离,以此来度量某一样本与哪一个中心点更为相似,就将其归入中心点所在的簇类中,并继续计算.根据结果不断变化簇类的中心点,直到将误差降低到最小时停止.利用k-means 算法对数据进行聚类计算的流程可以用公式表达,给定样本集合K

式中:n为样本容量;C为选取样本的属性集合;x与j分别代表集合K中第x个数据共有j个属性.在选取样本集后,可用确定簇类中心

式中:B为数据集中所有簇类中心的集合;Iv为中心点的属性集;v和d依旧为中心点Iv有d个不同的属性,共有m个簇类需要计算.当数据集合和簇类中心都确定后,即可对两者的相似性距离进行计算和度量

式中:Cx与Iv分别为数据集合中的某数据与已经完成设定的簇类中心点;T为数据与簇类中心点相似性距离的度量值,共需计算d个属性;其中x,v分别有自己固定的取值范围.基于k-means 算法,可以快速高效地对海量学生在线学习行为数据进行划分,依据度量相似性计算判断某一特定的学习行为数据属于何种类别,并尽可能地减少分类过程中产生的误差,为系统研究学生在线学习行为提供数据处理前提和技术基础.
3 设定在线学习行为评价指标
利用模型对学生在线学习行为数据进行采集后,为进一步准确分析采集数据与实际发生的学习行为之间的关联性,需要针对学习者在线学习的不同行为设定相应具体的评价指标,为此应首先明确学习者在进行在线学习的具体流程(见图2).
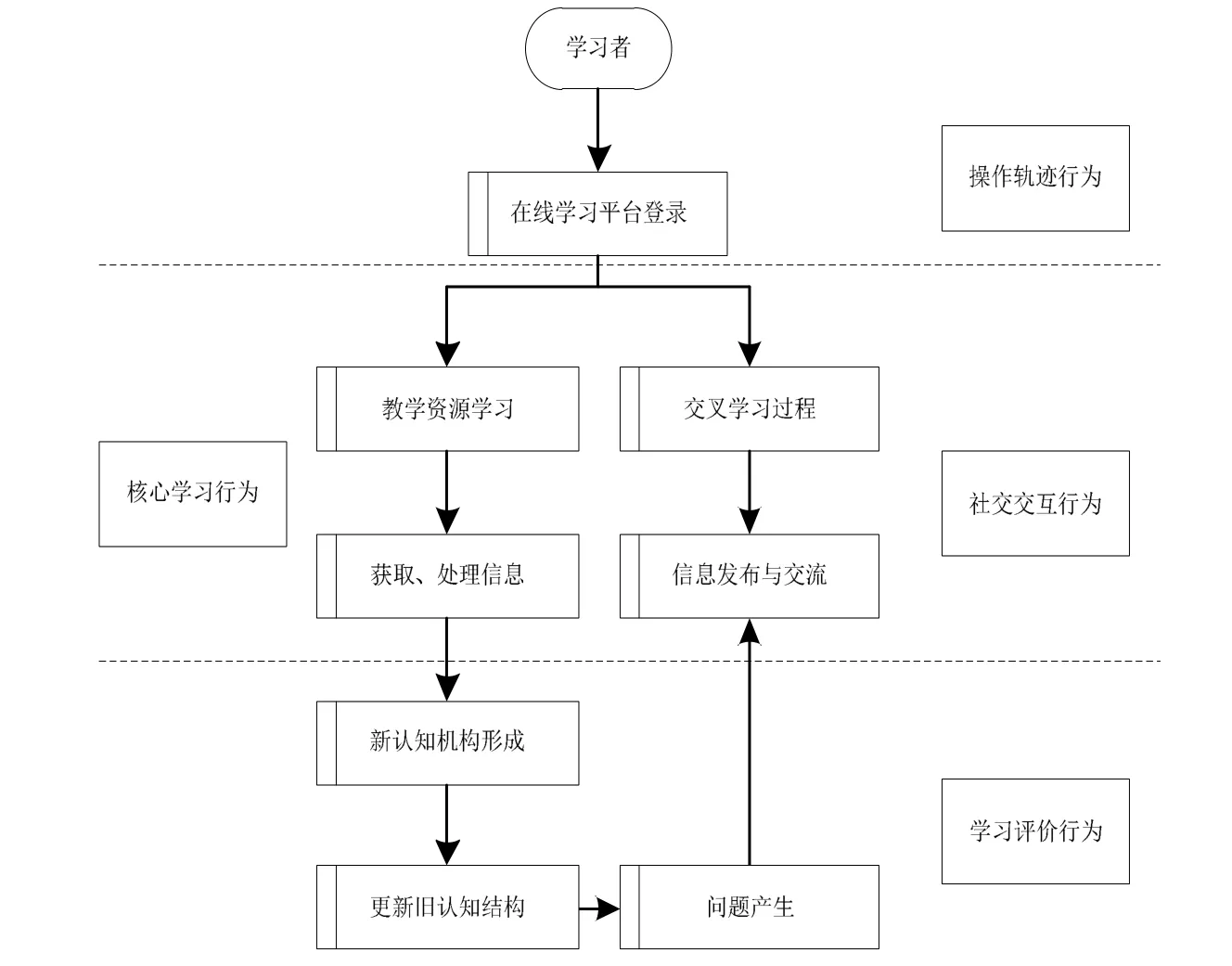
图2 学生在线学习行为进行过程
根据在线学习行为数据采集过程中区分的类别,可将图2 中阐述的在线学习行为过程与其对应,总结为登录轨迹、核心学习、社交交互和学习评价4大阶段,并基于此流程,分别设定4 个阶段中的评价指标(见表1).

表1 在线学习行为阶段性指标
由表1 可知,在对海量学生在线学习行为数据进行采集和挖掘后,通过设定指标解析在线学习行为过程,可以将学生在线学习行为4 个阶段的评价标准具体化,用具体的次数、时间和频率等数值反映诸多学习行为因素对学生在线学习效果的影响.基于对在线行为数据的指标具体化,利用评估模型对数据指标与实际学习行为间的关联性进行分析,抽选出对学生在线学习效果影响最深刻的学习行为属性,可以在未来的研究中重点优化这一属性,充分发挥学生在线学习行为研究的重要作用,增强研究的现实意义.
4 构建在线学习行为评估模型
基于k-means 分类算法,采集学生在线学习行为数据并设定具体对应的指标后,构建在线学习行为评估模型,直接呈现学生在线学习结果.在线学习行为评估模型的建立,要明确评价的目标、方法及结果的呈现方式等要素,并要注重跟随学习者在进行在线学习行为过程中的变化和发展,将动态变量融入评估模型中,实时地反映学生在线学习行为的评价结果.除了阐述的外部指标外,构建评估模型还应尽可能纳入内部衡量标准,例如:学生是否具备独立进行在线学习的能力,在线学习行为发生时的学习态度和学习动机以及在完成在线学习后学生对自己日后学习行为的预期是否提高等,具体占比权重为

式中:W为评价指标占比权重值;Ymax为最大特征根;k为评价指标标准值的总和.在占比权重值的基础上进行学习行为的研究分析,具体方式为

式中:R为学习行为的学习结果;m为所要研究指标的具体数据;mmax和mmin分别为其最大值和最小值,得出对学生在线学习行为研究分析的最终结果.由此可见,在线学习行为评估模型大致的运行机制,即同时对内部因素和外部标准中的线性指标进行评价,计算占比权重之后形成在线学习者主观意向和学习效果在数据上的反映,作为评估结果反馈给教学者,使在线学习行为评估模型成为一个循环式研究方法.
5 实验测试与分析
5.1 准备工作
为测试本文提出的基于k-means 算法的学生在线学习行为分析方法在实际应用中的准确性和可靠性,将本校计算机专业大三A 班的46 名学生作为测试对象,对该班级学生的在线学习行为进行分析,采用本文方法构建的学生在线学习行为评估模型,根据评估结果对学生期末成绩进行预测.经过1周时间的调查,对该班级46 名学生的在线学习情况进行统计,结果见表2.

表2 A 班学生在线学习情况
在此引入指标隶属度的概念,即在线学习行为数据与指标平均值之间的距离.在对学生在线学习结果进行评估时,指标隶属度将学习行为结果划分为不同的等级,用具体数值作为学生在线学习结果的直观呈现.利用本文研究方法,在A 班的46 名学生中,随机抽取1 名学生S 作为测试对象,对其在线学习行为进行评价研究,验证此方法的可行性.
5.2 实验结果
利用本次研究方法对学生的在线学习行为进行指标隶属度的记录,并根据公式(4)(5)计算出具体指标的占比权重隶属度.具体数据见表3.

表3 S 学生在线学习行为指标隶属度
由表3 数据可知,S 学生在出勤、观看资源视频及避免不良记录方面表现良好,作业完成和讨论参与指标效果并不理想.为保证此次实验结果的可靠程度,选取S 学生参与的6门科目作为评价学生成绩的6个指标,即U={u1,u2,… ,u6},评级为V={v1,v2,…,v5},分别对应“优秀、良好、中等、及格、不及格”,95~100 分为优秀,85~94 分为良好,75~84 分为中等,60~74 分为及格,60 分以下为不及格.根据S 学生行为指标的隶属度对其考试成绩进行预测.将本文提出的基于k-means 算法的学生在线学习行为分析方法作为实验组,将文献[6]提出的MOOC 学习者在线学习行为和学习绩效评估模型作为对照组,共同对S 学生的期中考试成绩进行预测计算,并与S 学生的实际成绩进行对比,预测成绩与实际成绩越相近,说明学习行为分析方法的预测成绩准确性越高.具体结果见表4.

表4 不同方法预测成绩与实际成绩对比
由表4 记录的数据可知,实验组的预测分数与实际成绩分数之间的误差分值可控制在2 分以内,而对照组的预测分数与实际成绩分数之间的误差分值为3~6 分.由于对照组的误差分值较大,可以看出对照组对于S 学生的成绩评级与实际成绩评级有一定出入,u1科目应该是良好却评定为中等,u3科目应该是优秀却评定为良好,u5科目应该是良好却评定为优秀;而实验组的评定结果与实际成绩的评定结果完全一致,能够证明本文设计的基于k-means 算法的学生在线学习行为分析方法能够对学生的学习行为进行准确的分析,分析结果较为准确,结果具有一定的可靠性.
6 结语
本文的学生在线学习行为研究方法在借鉴传统方法的不足和经验后,引入k-means 聚类算法,为学生在线学习行为研究提供更加准确高效的选择.但由于在线学习平台的不断更新和发展,学生的在线学习行为也会增加,相应的评价指标如果没有变化,就会造成研究结果的偏差加大,这种实时动态变化的机制是研究在线学习行为所面临的挑战.今后可以逐步强化评价指标的全面性,尽力缩小研究结果的误差范围.
猜你喜欢
学生天地(2020年15期)2020-08-25
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
意林·少年版(2020年2期)2020-02-18
电脑报(2019年4期)2019-09-10
阅读与作文(英语初中版)(2019年8期)2019-08-27
湘潮(上半月)(2019年3期)2019-05-22
小学生学习指导(低年级)(2018年11期)2018-12-03
现代防御技术(2016年1期)2016-06-01
成人教育(2015年7期)2015-12-21
