
混合广义部分线性加性模型的参数估计
2022-01-28 09:26:50程文慧
广西师范大学学报(自然科学版) 2022年1期
任 帅, 程文慧, 周 洁
(首都师范大学数学科学学院, 北京100048)
作为一般线性模型的扩展,广义线性模型(GLM)允许误差非正态,且通过不同连接函数使转化后的因变量与自变量之间满足线性相关关系。建模条件的放宽使得广义线性模型相对比较灵活,且在实际中的应用非常广泛。但是广义线性模型依旧属于参数模型,且该模型依然是建立在线性假设下,因而在分析生物和医学研究中的复杂数据时不够准确。Hastie等[1]提出广义加性模型(GAM),该模型用预测变量的光滑未知函数的和来代替线性分量,是一种非参数模型。作为广义线性模型(GLM)的一种推广,GAM在探索数据的隐藏结构时十分有效,但由于非参数模型过于灵活,所以GAM 很难得到简单明了的结论。为了克服参数模型和非参数模型自身局限性,半参数模型应运而生,部分线性模型就是一种应用广泛的半参数模型。该模型比参数模型有更好适应性,相比于非参数模型有更强的解释性。基于此优点,部分线性模型估计方法得到广大学者的青睐。Heckman[2]针对部分线性模型提出光滑样条估计方法,证明了参数部分的估计相合并且是渐近正态;Speckman[3]使用核估计方法得到参数和非参数函数的估计,并且证明参数部分和非参数部分都能达到最优收敛速度;Robinson[4]将Nadaraya-Waston核估计方法用于估计部分线性模型,得到参数的最小二乘估计,并在一定条件下得出参数估计的渐近分布;Chen[5]使用分段多项式法研究部分线性模型;Chen等[6]使用两步样条法得到部分线性模型的估计;Li[7]应用多项式和样条方法估计部分线性可加模型;Fan等[8]针对部分线性可加模型提出一种基于核估计的方法;Ma等[9]提出将样条与核估计相结合的SBK 方法;为了应对更复杂情况,Wang等[10]提出广义部分线性加性模型(GAPLM),将响应变量的条件分布扩展到指数族。在应用方面,黄四民等[11]用部分线性模型分析居民消费结构;李启华等[12]用部分线性模型对笔记本电脑特征价格指数进行研究。
无论是广义线性模型、广义加性模型还是部分线性模型,都只适用于同质性总体,当研究异质性总体时,上述模型便不再适用。有限混合模型[13-14]是研究异质性总体的有效工具,它灵活且易于扩展,随着计算能力的不断提升,应用越来越广泛。随着计算机技术的发展,极大似然估计在有限混合模型中越来越受关注。Böhning[15]总结了有限混合模型中的极大似然估计算法,其中最常用的算法有2种:Newton-Raphson 算法和EM 算法;Bilmes[16]使用EM 算法对高斯混合模型进行参数估计;Figueiredo等[17]对高斯混合模型中的EM算法作了一些改进;Yin 等[18]通过频繁更新来加速EM 算法,并将此方法应用到高斯混合模型中。马晓敏等[19]用有限混合模型对肝硬化住院患者医疗费用进行研究。为了应对更为复杂的实际情况,研究者开始考虑将回归模型与混合模型相结合,Jansen[20]最早将GLM 推广到有限混合框架之下,但他只考虑了计算问题;后来Wedel等[21]又对混合广义线性模型(MGLM)进行更为全面和深入地研究。MGLM提出的初期便有很丰富的研究成果,相继出现了二项MGLM、 泊松MGLM、 伽马和逆高斯MGLM、probitMGLM、多项MGLM。 近年来,Young 等[22]、Huang等[23]提出一种混合比例依赖于协变量的混合线性回归模型;Wu等[24]将他们的结果推广到一般MGLM中;Cao等[25]提出一种二项回归的半参数混合模型,其中混合比例和成功概率都非参数地依赖协变量;Huang等[26]系统研究一类非参数混合线性回归模型;Wang 等[27]对2类非参数和半参数混合广义线性模型的可识别性进行讨论;Xiang等[28]提出2种不同的单指标半参数混合线性回归模型。 尽管混合广义部分线性加性模型的一些特殊形式在前人的文章中出现过,但是关于该模型的一般形式并没有相关研究。本文对这种模型的一般形式进行深入探讨,提出一种统一的模型估计方法。该模型同时具有参数部分和非参数部分,并且假设响应变量的条件分布为指数族,因而是一种应用广泛的模型,适用于多种不同情况。此外,该模型还是一种混合模型,因而可以用于异质性总体的研究。
本文后续内容安排如下: 第1章将广义部分线性加性模型推广到有限混合框架之下,在一定条件下证明模型可识别性;第2章构造各参数的最大似然估计,给出其EM算法;第3章证明所提供参数估计的大样本性质,并提供一种模型检验方法;第4章利用数值模拟,验证所得到估计量在有限样本下的表现;第5章通过一组实例数据,将模型应用到实际问题中,结合实际情况对建模结果进行分析;第6章对本文主要工作进行相应总结。附录是定理的证明。
1 模型建立
1.1 混合广义部分线性加性模型
将广义部分线性加性模型(GAPLM)推广到有限混合框架下,得到本文要研究的混合广义部分线性加性模型。令{Xi,Zi,Yi}i=1,…,n,为来自总体{X,Z,Y}的随机样本,Yi为一维响应变量,Xi和Zi分别为d1维和d2维协变量,在给定(XT,ZT)T=(xT,zT)T的条件下,定义Y的密度函数为
(1)
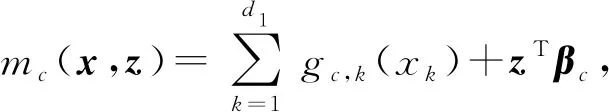
式中:a(·)、b(·)和c(·)是已知函数;φc是尺度参数。在给定(XT,ZT)T=(xT,zT)T的条件下,Y的期望为
gc,k(·)为线性函数时模型(1)为经典的混合广义线性模型。当总体个数C=1 时,模型(1)为广义部分线性加性模型。因此,本文所提出的模型(1)是混合广义线性模型和广义部分线性加性模型的自然推广。
1.2 模型的可识别性
可识别性是建立有限混合模型时首先要考虑一个重要问题, 因为在混合模型中, 各子模型的可识别性无法保证相应混合模型的可识别性[29-31]。Wang等[27]对2类非参数和半参数混合广义线性模型的可识别性进行讨论, 本文在此基础上建立模型(1) 的可识别性条件。下面给出模型(1)的可识别性定义。

(2)
成立,则C=D,并且式(2)中的求和项经过重新排序后有πc=λc,βc=γc,φc=ψc,gc,k(xk)=hc,k(xk),k=1,…,d1,c=1,…,C,那么称模型(1)是可识别的。
下面的定理1给出了模型(1)的可识别条件, 定理1证明详见附录。
定理1模型(1)是可识别的, 如果它满足条件:
① (xT,zT)T的定义域是Rd1+d2上的开集;
②gc,k(xk)有连续一阶导数,且E(gc,k(xk))=0, 其中c=1,…,C,k=1,…,d1;
③ 对任意1≤i≠j≤C, 如果φi=φj, 则
式中上角标(l)表示第l阶导数;
定理1的条件②是广义部分线性加性模型的可识别条件, 条件③要求任意2个总体的自然参数函数mi(x,z)和mj(x,z) 不能在同一点(xT,zT)T处相切。基于定理1, 可以看到在一些温和条件下,模型(1)是可识别的。
2 估计方法
2.1 SBK估计方法
使用将样条与核方法相结合的spline-backfitted-kernel(SBK)[9]两阶段估计方法估计模型(1) 中的参数。SBK 方法的主要思想是在第一阶段用样条方法估计,在第二阶段用核方法估计单个变量的非参数函数,并将其余的参数和非参数函数用第一阶段的估计结果代替,最后把所有非参数函数的估计结果代入模型,并用参数极大似然估计法更新参数部分的估计。
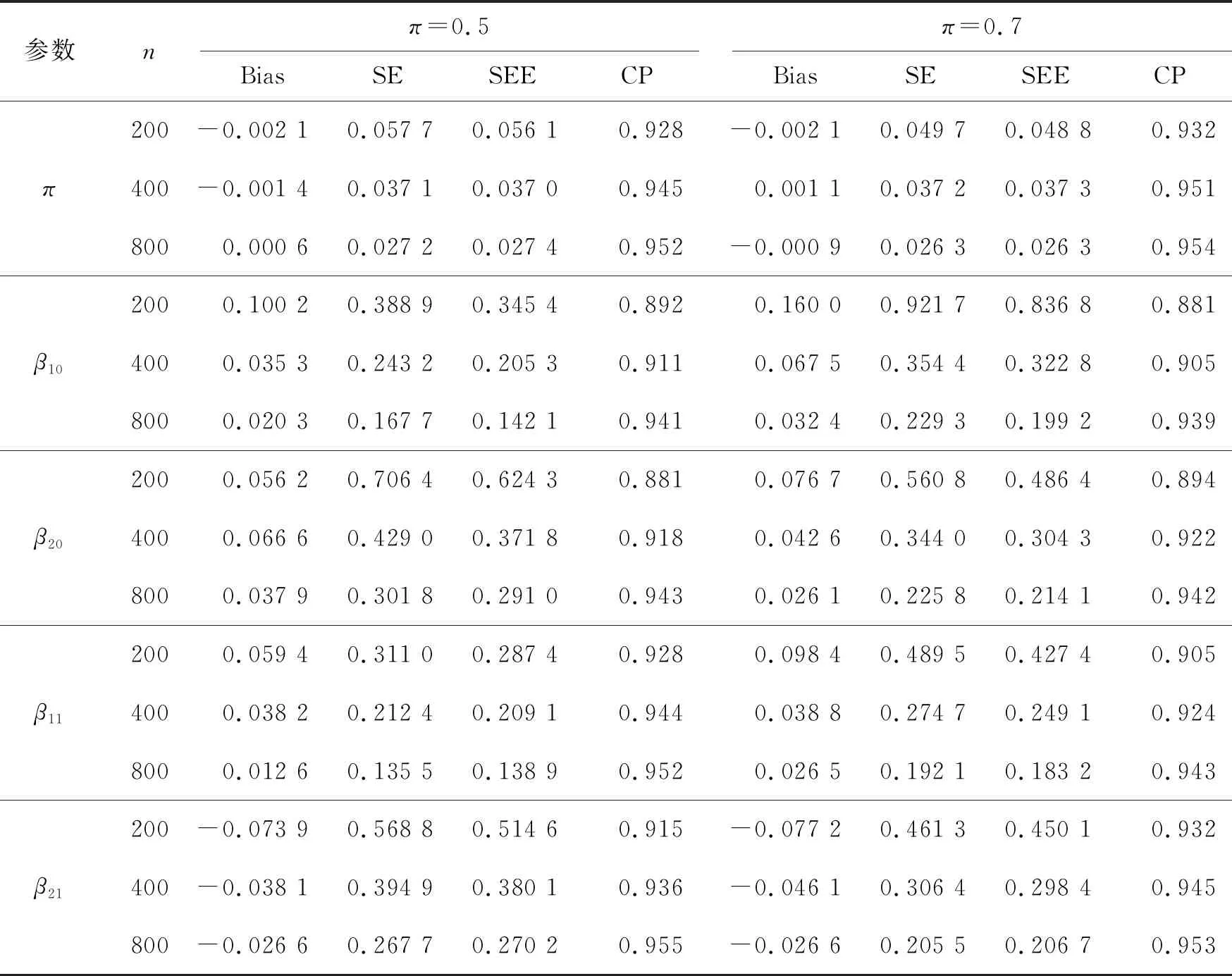
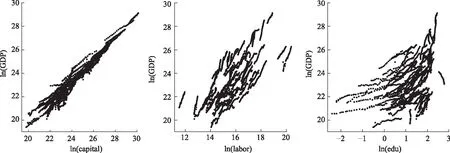
首先给出B样条的定义:选择正整数Nn~n1/3ln(n),即存在0 有了B样条的定义,下面给出SBK估计方法。在第一阶段,定义基于标准化B样条的对数似然函数为 (3) 在第二阶段,用核方法近似单个变量的未知函数,而将其他函数和参数替换为第一阶段的估计结果。令E={ui:0=u1<… (4) (5) EM算法是混合模型中常用的算法,本文使用EM算法来实现估计方法。式(3)、(4)和(5)是3个不同的对数似然函数,所以分别叙述他们对应的具体EM 算法。 在EM 算法框架下,观测数据(xi,zi,yi) 被认为是不完全数据,需要引入隐变量Δi=(Δi1,…,Δic)T,其中 则{(xi,zi,yi,Δi),i=1,…,n} 称为完全数据。下面分别叙述式(3)、(4)和(5)对应的EM算法。 2.2.1 式(3)的EM算法 式(3)是使用标准化B样条近似非参数函数时的不完全数据的对数似然函数,它对应的完全数据对数似然函数为 使用常规EM算法将其最大。 E步:在E步中,首先确定Q函数,即在给定观测数据和当前参数下完全数据对数似然函数关于隐变量的条件期望,经计算 这里需要计算E(Δic),将它记为ric,在第l+1次迭代中, 2.2.2 式(4)的EM算法 E步:Q函数为 式中g,k=(g1,k,…,gC,k)T。这里需要计算E(Δic),将它记为ric,在第l+1 次迭代中, M步:在格子点u∈{ut,t=1,…,N′} 上更新: 2.2.3 式(5)的EM算法 E步:Q函数为: 这里需要计算E(Δic),将它记为ric,在第l+1次迭代中, 选择最大化CVh的窗宽。在实际中,J通常被设为5,即使用5折交叉验证。 本节讨论估计量的相合性和渐近正态性。首先介绍一些记号: η=(πT,φT)T,ζ=(βT,ηT)T, λk(u|w)=Eq1(g,k(w)+g,-k(X),ζ,Z,Y)|Xk=u, Ik(xk)=-Eq1,1(g(X),ζ,Z,Y)|Xk=xk。 附录中给出了相应的正则性条件(C1)~(C9),这些条件都是温和的,适用于混合模型、局部似然估计和SBK 估计等众多统计模型和方法。下面的定理2和定理3给出了估计量在该正则条件下的渐近性质,证明详见附录。 式中: 定理3假设模型(1)是可识别的,在条件(C1)~(C9)下,当n→∞,有 定理2给出了非参数函数估计量的渐近性质,定理3表明参数部分的估计量是相合的且具有渐近正态性,其渐进方差可通过bootstrap方法估计。 本文提出的模型是一种半参数模型,部分协变量与响应变量间的关系用非参数函数刻画,而混合广义线性模型是一种参数混合模型,为了确定所提模型是否比混合广义线性模型在实际中更好,也就是说非参数部分是否有效,本文使用类似Li等[32]以及Zhang等[33]的方法来构造一个检验统计量,并对2种模型进行检验。 用H0表示原假设即混合广义线性模型是正确的模型,并用H1表示备择假设即混合广义部分线性加性模型是正确的模型,定义检验统计量 ① 分别在原假设和备择假设下估计模型,并用估计值计算检验统计量Tn的值; 本章通过数值模拟测试估计量在有限样本下的表现。考虑响应变量的条件分布为正态分布和二项分布2种情形,在每种情形下取2种不同混合比例。参数函数的估计效果使用均方误差的平方根(square root of the average squared errors, RASE), 式中:{ut,t=1,…,N′}是协变量u范围内的格子点;RASEgc,k表示第c个总体的第k个非参数函数gc,k(·)的RASE。在模拟中使用Epanechnikov 核函数,格子点个数N′=100,并且在B-Spline函数中选用5个节点。 模拟一正态分布。 首先考虑由2个总体构成的MGAPLM,且响应变量的条件分布为正态分布,即 式中μ1(x1,x2,z)=g11(x1)+g12(x2)+β10+β11z,μ2(x1,x2,z)=g21(x1)+g22(x2)+β20+β21z。具体参数设置为: 协变量X1、X2和Z均独立产生于均匀分布U(0,1),样本量n取值为200、400、800,模拟次数为1 000 次。 用Bias、SE、SEE和CP考查参数估计的有效程度,其中:Bias 是参数估计的偏差;SE 是参数估计的样本标准差;SEE是通过500次bootstrap 抽样得到的参数标准差估计的样本均值;CP 是重复1 000次实验中,95% 置信区间的经验覆盖率。参数部分的模拟结果如表1所示,从模拟结果可以看出,所有估计量都是无偏的,估计量的标准差(SE)和标准差的估计(SEE)很吻合,95%经验覆盖率(CP) 取值也都在0.95 左右。同时,随着样本量的增大,估计结果变得越来越好。非参数函数的估计效果如表2 所示,可以看到RASE 都很小,且随着样本量的增加变得越来越小,说明本文的估计方法是有效的。 表1 模拟一中参数部分估计结果 表2 模拟一中非参数函数的RASE 模拟二二项分布。 下面考虑由2个总体构成的MGAPLM,且响应变量的条件分布为二项分布,即 f(y|x,z)=(1-π)B(20,p1(x,z))+πB(20,p2(x,z)), 参数部分的模拟结果如表3所示,从模拟结果可以看出,所有估计量都是无偏的,估计量的标准差(SE) 和标准差的估计(SEE) 很吻合,95% 经验覆盖率(CP)取值也都在0.95左右。同时,随着样本量的增大,估计结果变得越来越好。非参数函数的估计效果如表4所示,可以看到RASE都很小,且随着样本量的增加变得越来越小,说明本文的估计方法是有效的。 表3 模拟二中参数部分估计结果 表4 模拟二中非参数函数的RASE 本章将提出的方法应用于一组从世界银行的STARS数据库中获得的经济数据集,此数据集包括1960年至1987 年期间82 个国家的实际国内生产总值(GDP)、人力资本(labor)、 全部实际资本(capital) 和平均受教育年限(edu)。本文研究人力资本、全部实际资本 和平均受教育年限如何影响实际国内生产总值。首先对所有数据取对数,得到X1=ln(capital),X2=ln(labor),X3=ln(edu)以及Y=ln(GDP)。通过图1可以看出,ln(capital) 和ln(labor) 都与ln(GDP) 之间呈现线性关系,而ln(edu) 与ln(GDP)之间呈现非线性关系。 图1 ln(capital),ln(labor),ln(edu)的散点图 构建2个总体MGAPLM,并假设Y的条件分布为正态分布,即 (7) 经过计算,最佳窗宽为h=0.3,如图2(a)所示,在最佳窗宽下的参数估计及其标准差的估计如表5所示。这些结果与Li等[32]的结果一致。 表5 实例分析中参数部分估计结果 图2 CV图和非参数函数的估计结果 为了检验用非参数函数刻画教育(edu)是否比用线性函数更有效,计算3.2 节所提出的检验统计量Tn=0.009 1,且显著性水平为0.05时,在500个bootstrap样本下临界值为0.000 2,所以拒绝原假设。这表明本文提出的混合广义部分线性模型比混合广义线性模型对此数据有更好地拟合效果。 本文将广义部分线性加性模型推广到有限混合框架之下,在一定条件下证明模型的可识别性,并且使用样条和核估计相结合的SBK方法给出参数的最大似然估计,同时证明估计量的渐近性质,还给出模型检验的方法。此外,通过数值模拟验证参数估计方法在有限样本下的表现,从结果可以看出本文方法是有效的。最后,将本文方法应用到一个经济数据集中,结果表明本文模型对于异质性数据的分析十分有用。 附录 正则性条件(C1)~(C9) (C1){(xi,zi,yi),i=1,…,n}是从联合密度f(x,z,y)抽取的独立同分布样本,f(x,z,y)在[0,1]d1×Rd2上具有有限6阶矩,且密度函数fX(x) 满足 xk的边缘密度fk(xk)在[0,1]上二次连续可微,且具有相同的上界Cf和下界cf。 (C3)存在一个邻域N(gk(xk)),使得对某些λ∈(2,∞), 有 (C5)参数空间是紧的,内部节点数满足Nn~n1/3ln(n),即存在0 (C6)存在函数M(y)且E2[M(Y)]<∞,使得对所有y和在邻域ζ(x,z) 内的ζ, (C7)对所有i和j,有 (C8)核密度函数K定义在[0,1]上且是对称的,存在CK>0使得K∈Lip([0,1],CK)。 (C9)存在常数c,使得当n→∞ 时窗宽h满足nh→∞,h-1=O(n1/5lncn)以及h≥(lnn/n)1-2/λ,λ如条件(C3)所示。 下面证明定理1。 定理1的证明假设模型(1)有另一种表示形式 swx,z(c)(x,z)=mc(x,z),λωx,z(c)=πc,ψωx,z(c)=φc,c=1,…,C。 考虑任意一个排列ω={ω(1),…,ω(C)}和某个(x,z),使得 sw(c)(x,z)=mc(x,z),λω(c)=πc,ψω(c)=φc,c=1,…,C, S={(x,z)∈Rd1+d2∶sω(c)(x,z)=mc(x,z)} (6) 是Rd1+d2上的d1+d2-1维超平面,且测度为零。由于{1,…,C}所有排列的数量有限,如果式(6)在一个空集或者Rd1+d2上测度为零,这与定理的条件①相矛盾。因此存在一个排列ω*={ω*(1),…,ω*(C)},使得 条件③表明ω*是使式(6)在定义域上一个的非零测度子集上成立的唯一排列。定理1证毕。 为了证明定理2和定理3,先给出5个引理。 引理1如果条件(C1)、(C2)、(C3)、(C8)、(C9)成立,当n→∞ 时, 此引理来自文献[34]的定理2.1。 引理2如果条件(C1)、(C6)、(C7)、(C8)、(C9)成立,对任意xk∈[h,1-h],当n→∞时, 式中: 经泰勒展开以及一些计算,得 式中: 由二次近似引理(quadratic approximation lemma)[35],得 可以证明 式中 式中H=(Nn+1)-1。 引理4在条件(C1)、(C6)、(C7)下,第一阶段估计满足 式中H=(Nn+1)-1。 式中 (7) 式中H=(Nn+1)-1。 下面证明定理2。 定理2的证明假设{gc,k(xk),c=1,…,C,k=2,…,d1},{βc,c=1,…,C},{πc,c=1,…,C-1},{φc,c=1,…,C}通过“Oracle”已知,唯一的未知量g,1(x1)=(g1,1(x1),…,gc,1(x1))T,可通过最大化 来估计,则g,1(u)的Oracle估计为 同理可以得到ζ=(βT,πT,φT)T的Oracle估计。由引理1、引理2和引理5可推出定理2。证毕。 最后证明定理3。 (8) 将等式(8)泰勒展开得到 (9) 式中: 由大数定律以及一些简单计算,可得 Bn=-E[Iζ(X)]+op(1)=-B+op(1)。 则式(9)变为 将An泰勒展开为 再由文献[23]引理3可得 这表明 所以,对任意i=1,…,n,有 令 通过计算二阶矩[37]可以证明 所以 根据等式(7)和二次近似引理(quadratic approximation lemma)[35],可得 经过一些计算便可证明E[∂(g(Xi),ζ,Zi,Yi))/∂ζ]=0 ,E[ω(Xj,Yj,Zj)]=0,所以E(An)=0,再定义σ=var(An),由中心极限定理,定理3得证。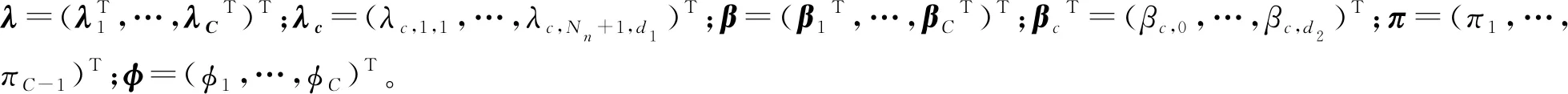
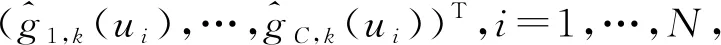
2.2 EM算法实现



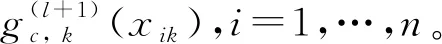
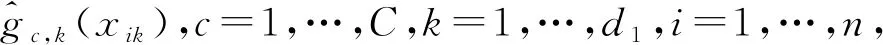

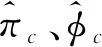
2.3 窗宽选择
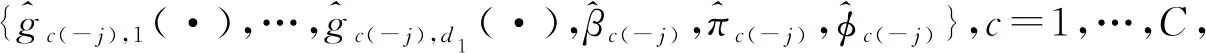
3 模型性质
3.1 渐近性质


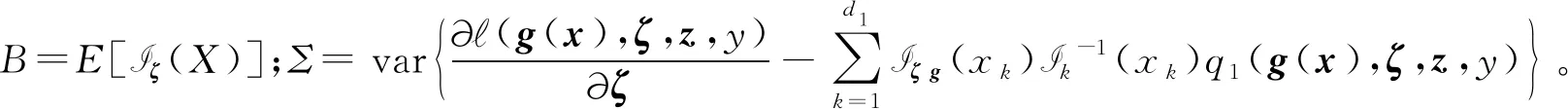
3.2 模型检验


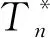
4 数值模拟
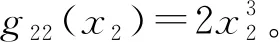


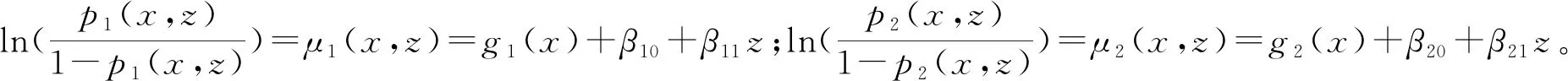
5 实例分析


6 结论

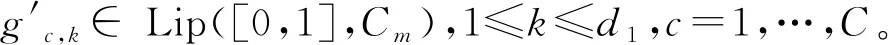

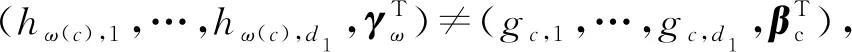


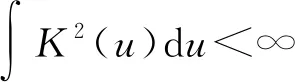


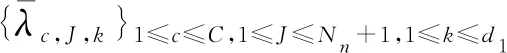


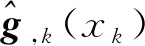





 猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00数学物理学报(2022年3期)2022-05-25 13:33:00阜阳师范大学学报(自然科学版)(2022年1期)2022-04-02 12:35:16中学生数理化·高一版(2021年2期)2021-03-19 08:32:06中国中医急症(2019年10期)2019-05-21 07:20:28中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34系统管理学报(2018年3期)2018-08-13 01:05:28系统管理学报(2018年2期)2018-08-13 01:04:38数学年刊A辑(中文版)(2016年2期)2016-10-30 01:46:38哈尔滨师范大学自然科学学报(2015年1期)2015-04-19 06:55:36
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00数学物理学报(2022年3期)2022-05-25 13:33:00阜阳师范大学学报(自然科学版)(2022年1期)2022-04-02 12:35:16中学生数理化·高一版(2021年2期)2021-03-19 08:32:06中国中医急症(2019年10期)2019-05-21 07:20:28中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34系统管理学报(2018年3期)2018-08-13 01:05:28系统管理学报(2018年2期)2018-08-13 01:04:38数学年刊A辑(中文版)(2016年2期)2016-10-30 01:46:38哈尔滨师范大学自然科学学报(2015年1期)2015-04-19 06:55:36
