
基于MEB和SVM方法的新类别分类研究
2022-01-28 09:24:46方扬鑫
广西师范大学学报(自然科学版) 2022年1期
杨 迪, 方扬鑫, 周 彦
(深圳大学数学与统计学院, 广东深圳518060)
2021年1月,国际癌症研究机构团队发表2020全球癌症统计报告,其中女性乳腺癌是全球新发病例数最高的癌症,约占男女新发病例总数的11.7%,在女性高发癌症类型排名第1,达到24.5%[1]。不同分子分型乳腺癌在疾病的表达、对治疗的反应、预后及生存结果上存在显著差异[2-3],乳腺癌分子分型一般是通过患者的免疫组织化学检查结果进行诊断,这种检查方式操作复杂且有创伤。因此,通过机器学习中的模式识别方法诊断患者乳腺癌的分子分型,在医疗上具有重要意义。癌症分析通常是分析肿瘤样本DNA甲基化数据[4-5]、基因表达水平[6-7]、突变数等数值[8]。
现在已经有多种癌症分析方法,比如通过卷积神经网络识别乳腺癌患者DCE-MRI图像,得到不错效果[9]。本文利用MEB分类方法对乳腺癌患者DNA甲基化水平数据进行分类。在其他疾病的应用,如黑素瘤分类[10],也有使用类似MEB方法的研究。如果只是传统的三分类数据,即在训练样本已经有3个类别样本,且测试样本也有且仅有该3类数据的样本,可以利用的机器学习方法有很多,诸如SVM、随机森林、决策树等。这些方法已经非常成熟且应用广泛,但是如果测试样本中有训练样本未出现的类别,如何进行分类则是普通机器学习无法解决的。本文研究的问题是若现在有一份数据集,拿出一份仅含有A类和B类的训练数据集,与一份还包含第3个类别的测试数据集,训练出一个分类器,使得可以将测试集数据较为准确分类。更多复杂情况诸如4个类别以上等情况并未进行研究和探讨,但是也同样具有很强的现实意义。
一般来说,对于大样本的分类,SVM方法[11-12]的准确率可以做到比较高的水平,但是对于样本较少或样本严重不均的情况,利用MEB方法可以获得更好的效果。例如,一个地区患某种疾病的人的数量远少于正常人的数量,用SVM方法输出的最终分类情况会十分糟糕,而使用MEB方法就不会有这个问题,因为MEB方法对异常值非常敏感,能够较为精确地将异常样本分离。MEB方法解决了SVM所具有的部分缺点,但是对参数的选择和核函数敏感,容易过拟合,在拥有多类别(大于两类别)的样本时,SVM进行调整后就可以输出多个分类结果,而MEB只能输出“TRUE”和“FALSE”2个结果。所以,如何利用MEB方法和SVM方法的优点是本文的研究点。
本文使用的SVDD(support vector data description)算法是Schölkopf[13]、Tax等[14]在SVM算法上拓展而提出来的一种新的SVM算法。经过一段时间发展,它已经可以完成更多工作,如入侵数据分类[15]、图像检索[16]、文本分类[17]、数据异常值检测[18]等。该算法的中心步骤是找到一个合适的球心和半径,使大部分样本点被这个球包围住,将高密度区域中的样本点类别记为“+1”,而那些处于高密度以外的点,也就是异常样本点被记作“-1”。对于新输入的观测点,输出为“+1”的样本即判断为“TRUE”,和训练样本属于同一类,输出为“-1”的样本即判断为“FALSE”,不属于训练样本那一类。
1 MEB方法原理
需要注意的是,本文方法所使用的数据均为非零数据,且均来自同一类别。由于研究的是DNA甲基化数据,所以使用的样本集也定义为一个DNA甲基化数据。给定一个DNA甲基化数据Z=x1,y1,x2,y2),…,xl,yl)},式中:xi∈RN;yi∈+1,-1;l是训练样本总数,i=1,2,…,l。首先将样本点通过核函数映射到高维空间,变换为φxi,本文设函数kx,z是核函数,且有
kx,z=φ(x)φz。

如图1所示,MEB方法的目标是寻找一个最小的超球B(c,R),满足
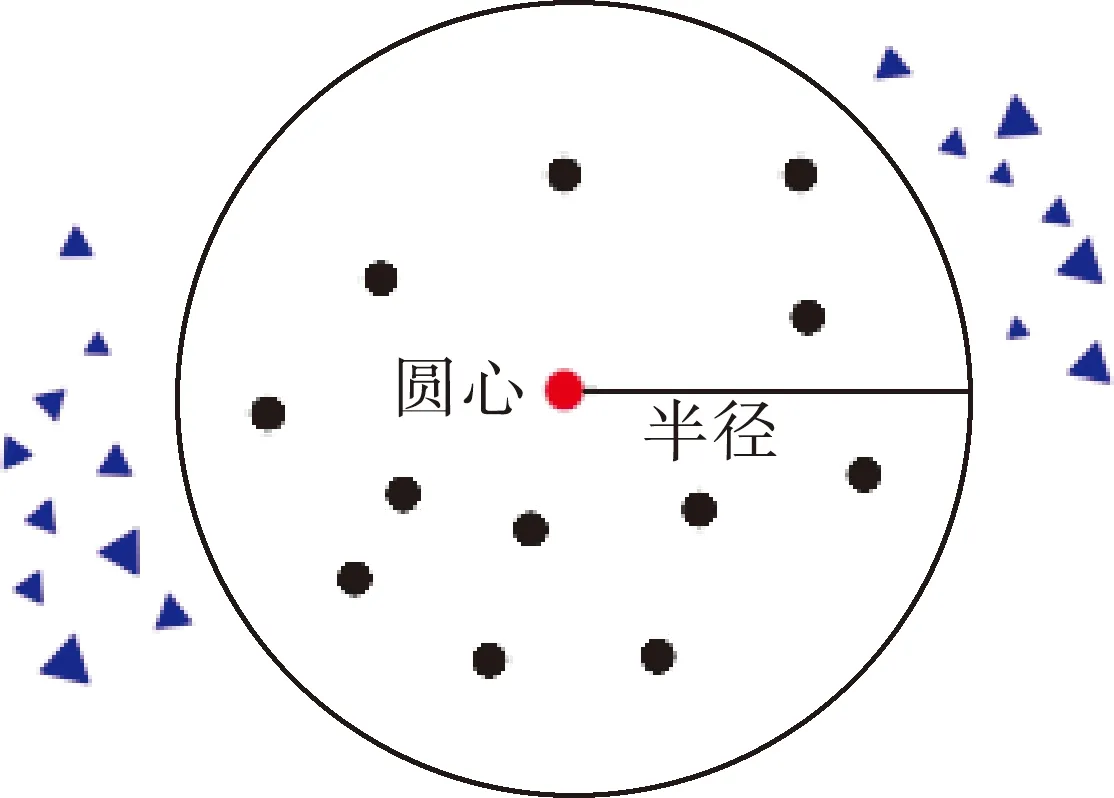
图1 MEB方法
① 样本中的点尽量多地被球包在其中;
② 所找到的超球是所有满足条件①的超球中半径最小的。
很自然得到下列最优化函数
式中:c是超球的球心;R是超球的半径;l是样本个数。
数据中经常会存在离群点,为了使模型具有更好的泛化效果,引入松弛参数ξi≥0,惩罚参数C>0,类似于SVM,控制超球大小,同时使更多样本点被包含在内,此时的约束问题就变为
采用拉格朗日数乘法,αi>0,βi>0均为拉格朗日算子,
对R、ξi、c求导,并令等式为0,化简得
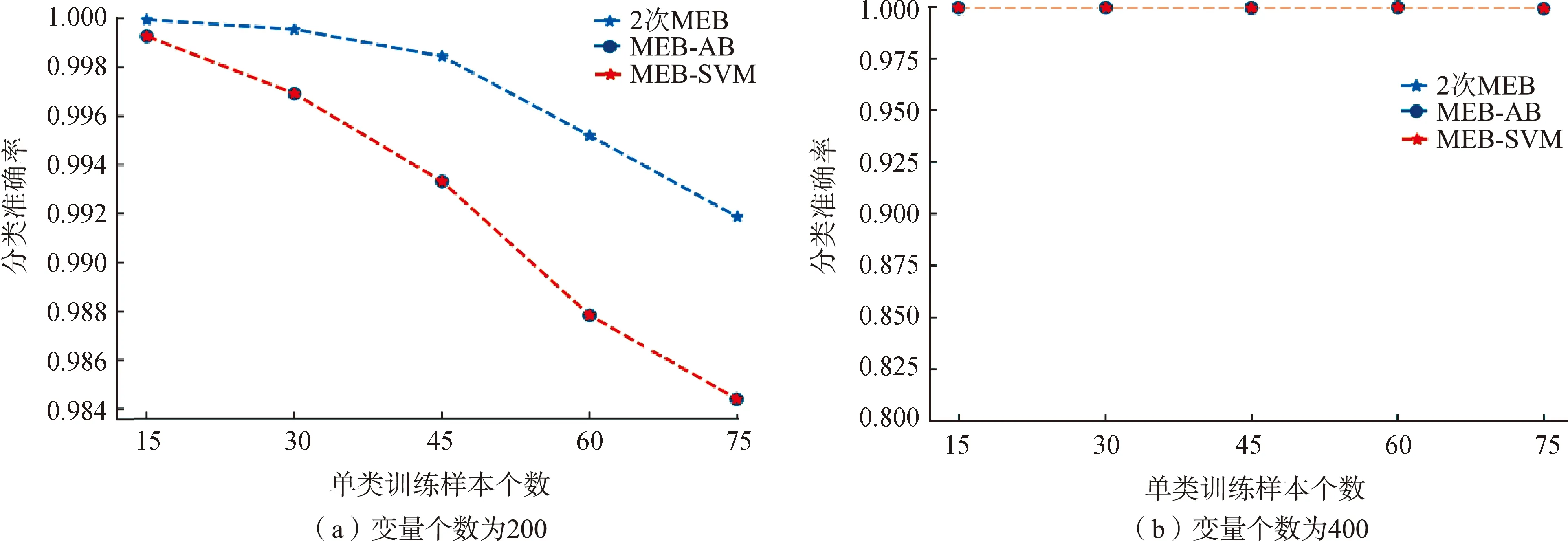
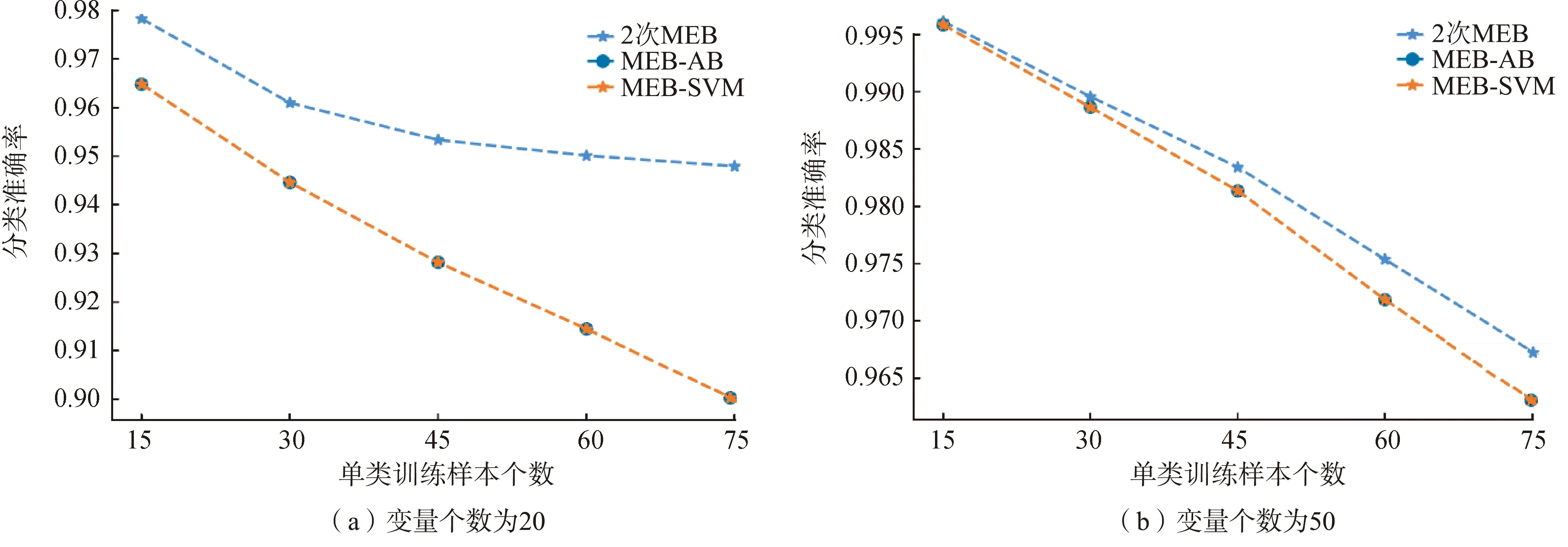
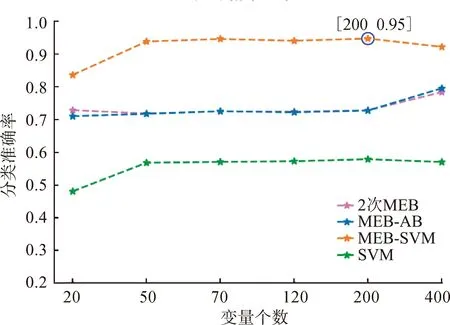
式中:xk为任意满足0<αk 下面SVDD算法是对整个计算过程的总结与提炼。 SVDD算法 输入:Z=x1,y1,x2,y2),…,xl,yl)},式中xi∈RN,yi∈+1,-1,l是训练样本总数,i=1,2,…,l。 输出:分类决策函数f(x)。 步骤1先设定惩罚参数C>0,构造并求解方程组 核函数为高斯核函数,分类决策函数还可进一步简化为 数据来源于网站The NCI's Genomic Data Commons(GDC)的数据库(https:∥portal.gdc.cancer.gov/)中乳腺癌(breast invasive carcinoma,BRCA)类型的 DNA 甲基化 450 K 芯片(Illumina Infinium Human Methylation 450 K Bead Chip) 数据。本次分析使用的数据集有2个文件:一个是BRCA_matrix,记录乳腺癌分子分型的DNA甲基化水平,数值范围为[0,1],0表示未甲基化,1表示完全甲基化,BRCA_matrix部分数据见表1;另一个是BRCA_type,由Perou等[19]根据ER、PR、HER2状态[20]将乳腺癌患者分为不同的分子亚型。经过数据处理和清洗(删除全为NA的变量数据),得到407×314 798 数据框,其中407为细胞个数,314 798为CpG位点(特征变量)个数,共有6种类型,包括5种乳腺癌分子分型和正常人类型。本次选取其中3种类型,分别是“Normal”(无病正常人,样本数量为98)、“Luminal A”( 管腔上皮A型,样本数量为108)、“Basal-like” (基底细胞样型,样本数量为40)。 表1 BRCA_matrix部分数据 本次用于分析的类别“Luminal A” (共108个样本,设为“1”类) 和类别“Normal” (共98个样本,设为“2”类),以及仅包含在测试数据集中的“Basal-like” (共40个样本,设为“3”类)。分析过程中用于训练样本的2个类别“Normal”和“Luminal A”数量保持一致。 3个新的分类方法步骤如下: 2次MEB ① 训练“1”类MEB,将测试集用此模型分类(T分为“1”类); ② 训练“2”类MEB,将①中分为F的用此模型分类(T分为“2”类); ③ 两次为F,则为“3”类。 MEB-AB ① “1”和“2”类作为1类训练MEB,将测试集用此模型分类(F分为“3”类); ② 训练“1”类MEB,将①中分为T的用此模型分类(T分为“1”类,F分为“2”类)。 MEB-SVM ① “1”和“2”类作为1类训练MEB,将测试集用此模型分类(F分为“3”类); ② 训练SVM二分类器,将①中分为T的用此模型分类(+1分为“1”类,-1分为“2”类)。 为了探究只有SVM方法的情况下对异常值识别的局限性,加入SVM和上述3个分类方法作对比。只把“1”、“2”类数据放入SVM训练,测试集包含“3”类。 本文使用分类总准确率 (简写trate)作为主要评价指标, trate=正确分类样本数/总样本数, 即最终得到的分类结果中,分类正确的样本总数和总样本数之比,能很好反映分类器的性能。 “3”类样本分类准确率 (简写为Trate), Trate=“3”类样本分类正确数/“3”类样本总数。 由于是异常样本检验,所以“3”类样本分类准确率也是检验所设置分类器性能的一个重要指标。根据所研究问题,在结果分析中通过这2个指标来判断分类器的实际表现。 本文训练集中选取的“1”类和“2”类样本数量相同,单个类别训练样本数分别取15、30、45、60、75,并通过BW最大选取不同特征变量个数20、50、70、120、200、400进行分类分析。分类器的训练误差上限设置为0.01。 3.1.1 不同训练集样本个数对准确率的影响 固定特征变量个数,如特征变量个数取20,随机抽取单个类别训练样本个数(如取15,则训练样本总个数为15+15),按照2.2节中研究方法训练分类器,计算分类总准确率和“3”类样本分类准确率,将上述步骤循环1 000次计算评价指标的平均值,减小误差,然后单个类别训练样本个数分别取30、45、60、75,重复上述步骤,研究不同训练样本数对分类方法准确率的影响。本文采用组间差异和组内差异的比值来筛选最有影响的特征变量,公式如下 3.1.2 不同特征变量个数对准确率的影响 固定训练样本个数,如训练样本个数取30(15+15),随机抽取单个类别训练样本个数15,通过BW最大筛选特征变量,如选取20个,按照2.2节中研究方法训练分类器,计算分类总准确率和“3”类样本分类准确率,将上述步骤循环1 000次计算评价指标的平均值,然后通过BW最大筛选最有影响的特征变量个数50、70、120、200、400,研究不同特征变量个数对准确率的影响。 由图2可以看出,提出的结合MEB的3种新方法,随着训练样本个数不断增加,分类准确率也不断增加。以变量个数20为例,MEB-SVM方法从最开始的65%左右随着训练样本个数增加逐渐上升,当训练样本个数为75(即总训练样本个数为150)时,总体准确率达到84%。同时注意到SVM方法分类准确率随着训练样本个数增加逐渐下降,这是因为SVM对已知类的分类效果很好,当训练样本量很少时,测试集样本量包含的已知类的样本比例大,因此分类准确率较高;随着训练样本数量增加,测试集中包含已知类样本比例减少,未知类比例增加,SVM对于未知类的分类率为0,所以总体准确率下降。 图2 不同训练样本个数对分类总准确率的影响 MEB-SVM方法对于训练集为已知类,测试集包含未知类的数据分类效果最好,在训练样本量为75时,结合MEB的新方法的分类效果均好于SVM,且分类准确率最高。在所选取的变量数值中,变量为50、70、120、200、400时总的分类准确率均达到90%以上。 如图3所示,本文提出的结合MEB的3种新方法,“3”类样本分类准确率高达100%,其中MEB-AB与MEB-SVM这2种方法的“3”类样本分类准确率趋于一致,主要是因为2种方法第1步都是将“1”和“2”类看成一类训练MEB,判断为F就分为“3”类,对于参数和训练集一致情况下,“3”类样本准确率也一致,这2种方法主要区别在于第2步中“1”和“2”类的分类。由图2可知,对于已知类别的分类效果SVM要优于MEB,所以MEB-SVM方法在总体分类准确率上效果好于MEB-AB。当变量个数为200时,随着训练样本量不断增大,“3”类样本分类准确率缓慢下降,可能是因为训练集增大,所训练的球变大,导致少量的“3”类样本分入了“1”或“2”类。其他变量取值的“3”类样本分类准确率见图4。 图3 不同训练样本个数对“3”类样本分类准确率的影响 图4 不同训练样本个数对“3”类样本分类准确率的影响 由图5可以看出,MEB-SVM的总准确率明显高于其他3类分类方法,当训练样本量为30、60、90、120时(这里指的总训练样本量,区别于上文中单类),随着变量不断增长,当训练样本量到达70时,分类效果最好;之后随着变量增长,分类准确率缓慢下降,可能是因为无关变量太多,信息赘余,导致总体分类准确率下降。如图6,当训练样本量为150,变量个数取200时,MEB-SVM分类效果最好,分类准确率可达95%。变量超过200,准确率就会缓慢下降,这说明变量的选取也对分类效果产生一点影响,实际数据分析中要去除相关性不大的变量数据。 图5 不同变量个数对分类总准确率的影响 图6 训练样本个数为150时,不同变量个数对分类总准确率的影响 由图7可以看出,MEB-SVM分类方法随着变量不断增加,“3”类样本分类准确率也不断增加,分类准确率可达100%,非常优秀,兼顾了总体准确率的同时还保持着对“3”类样本分类准确率。其他2个分类方法中2次MEB和MEB-AB分类方法在“3”类样本分类效果上表现也非常不错,说明本文提出的3种分类方法可以很好克服SVM的缺点,在未知类分类效果上表现非常好。其他训练样本量取值的“3”类样本分类效果见图8。 图7 训练样本个数为150时,不同变量个数对“3”类样本分类准确率的影响 图8 不同变量个数对“3”类样本分类准确率的影响 可以观察到2次MEB、MEB-AB和SVM这3种分类方法总准确率60%~70%,明显低于MEB-SVM。比较MEB-SVM和SVM这2种方法,对于测试数据集包含未知新类的数据采用MEB方法,不仅对于新类的分类准确率要优于SVM,总分类准确率也优于SVM。对比于2次MEB和MEB-AB,MEB-SVM嵌入了SVM方法,对于“1”和“2”类2个已知类的分类效果上要好于MEB。MEB-SVM分类方法很好地结合了2个分类模型的优点。 本文经过数据分析和分类预测,可以了解不同分类器的性能。结合SVM方法和MEB方法提出3个新的分类方法。从各个分类器数据来看,MEB-SVM分类方法展现出不错的性能,测试结果都强于其他分类方法,总体准确率达到90%以上。联合之前所得结果,综合分析后发现,随着训练样本数量增多,总体准确率也会增加。接着研究不同变量数目对于分类效果的影响,从分析结果来看,变量数量超过一定值时,分类准确率会下降,说明数据中包含很多无关变量,影响分类效果。当训练样本量为150、变量数为200时,MEB-SVM分类方法总体准确率为95%左右、对“3”类样本准确率更是达到99%以上,符合预期目标。综合上述分析可以看出训练样本数量和变量的选取都会对分类器的分类效果产生一定影响。 作为中国女性最常见的恶性肿瘤之一,乳腺癌发病率呈逐年上升趋势[21]。本文基于MEB和SVM新方法诊断患者乳腺癌的分子分型,在医疗上具有实际意义。近10年国内外对此类问题的研究不多,本文研究对含有新类别的测试样本进行分类。将MEB 和SVM方法相结合,给出3种全新方法,是全新的尝试,并对3种不同方法进行系列分析,包括不同训练样本数量和变量数目的差异对分类器结果的影响。 分析发现,当训练样本数量越多与变量选取适量时,分类器分类性能越好,同时,在分析中利用MEB-SVM的分类方法得到总体准确率95%左右,“3”类样本准确率高达99%的分类器。MEB结合SVM对于包含未知类别的测试集分类效果非常好。 未来工作将继续优化上述分类器性能,以达到更好的效果,或者从其他机器学习方法寻找突破口,并加以改进。也可以对更难的问题,如对异常样本进行再分类、测试集中有2个甚至2个以上的新类别分类问题,这些新问题难度更大,也更加具有挑战性。


2 实际数据分析
2.1 数据描述

2.2 研究方法
2.3 评价指标
3 结果与分析
3.1 分析设置
3.2 训练集数量影响

3.3 变量个数影响



3.4 实验结果总结
4 结语
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
科技创新与应用(2020年6期)2020-02-29 10:39:27
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
