
基于域名词间关系的字典型恶意域名检测方法
2022-01-28 02:16席一帆
信息安全研究 2022年2期
席一帆 汪 洋 张 钰
(武汉邮电科学研究院 武汉 430074) (南京烽火星空通信发展有限公司 南京 210019)
计算机网络面临着严重的安全威胁,其中很大一部分来自于僵尸网络.僵尸网络是一组被称为机器人(bot)的受攻击计算机[1],网络犯罪分子可以通过命令和控制(C&C)服务器[2]来对僵尸网络进行远程控制.通过命令和控制服务器操作这些机器人来执行恶意的网络活动,例如进行大规模网络钓鱼,将病毒软件传播到其他终端,继而窃取所需要的机密信息[3-4].
在早期的僵尸网络中,网络犯罪分子通常会把命令和控制服务器的域名或者IP地址硬编码到恶意程序中[5],因此安全人员能够通过逆向恶意程序得到命令和控制服务器的域名或者IP,从而预先建立黑名单来检测僵尸网络[4,6].但随着互联网技术的发展,许多僵尸网络都通过域名生成算法(domain generation algorithm, DGA)动态生成域名来躲避检测[7-9].
DGA是一种基于Fast-flux技术的机制,Fast-flux技术是指不断改变域名和IP地址映射关系的一种技术[8],这也意味着在短时间内查询使用Fast-flux技术部署的域名会得到不同的结果.僵尸网络利用DGA机制能够频繁更改命令和控制服务器的域名[10],使得黑名单的更新速度很难与恶意域名的产生速度同步,以此来隐藏从机器人到命令和控制服务器的回调通信.具体来说,机器人使用DGA动态生成域名,并尝试为每个域名进行域名解析,最终返回正确响应的域名将被视为命令和控制服务器.
部分早期相关研究关注的是检测DGA机器人与命令和控制服务器通信过程中,良性域名和恶意域名字符串的可识别差异[11-12].例如,Truong等人[13]提出了一种使用带有监督学习的双元模型学习和预测域名字符模式的方法.Anderson等人[14]则在此基础上进行了改进,引入带有长短期记忆(LSTM)网络的字符级建模.该方法基于一项来自观察经验的假设:良性域名的字符串通常由能够反映注册者意图的单词或字符组成[15],例如机构名、产品名或提供的服务内容等;相应地,为了避免与已注册域名产生冲突,恶意域名通常会选用大量无关字符进行随机组合[16].为了躲避检测,一些僵尸网络家族开始采用字典型恶意域名进行通信[17],字典型恶意域名即基于字典的DGA算法所生成的恶意域名.该类DGA算法从字典中选取单词来动态生成域名,这种方式产生的域名与人工注册的正常域名看起来非常相似,使得传统的基于字符级特征进行建模的检测方法逐渐失效.目前,学术界针对字典型恶意域名的检测方法仍集中于深度学习网络,例如Highnam等人[18]提出一种基于卷积神经网络(CNN)和长短期记忆(LSTM)网络并行使用的字典型DGA检测方法,该类方法不能充分发掘字典型恶意域名的词间关系.此外,Chowdhury等人[19]提出将图特征应用于基于行为的DGA检测的思想,图特征能有效表征良性域名与恶意域名在单词级别上的差异.
为了提高对字典型DGA生成的恶意域名的检测水平,本文引入有权无向图描述恶意域名的单词构成,通过度中心性指标量化单词级别特征,提出了一种基于词间关系的DGA恶意域名检测方法.
1 基于域名词间关系的字典型恶意域名检测方法
在当前防范僵尸网络的研究中,研究人员之所以将注意力更多地放在针对其DGA域名的检测上,是因为域名解析是一种未加密的交互,并且总是发生在DGA机器人的回调之前.表1示出部分基于字典的DGA生成的域名实例:

表1 部分基于字典的DGA家族
由于DGA合成的域名与人工创建的域名在单词组合频率上存在差异[20],我们提出了一种识别恶意域名的方法,通过分析每个域名中组成字符串单词之间的关系来识别恶意域名.该方法基于2点主要思想:1)利用图论中的通用概念来描述构成域名单词的词间关系;2)使用度中心性来量化域名中每个单词的特征,该指标表征了良性和恶意域名之间的区别.最后,我们将基于该指标构成的特征向量应用于机器学习算法,从而得到检测DGA恶意域名的模型.
图1展示了该检测方法的流程,大致分为3步:1)对输入的域名进行分词;2)利用得到的词组构建词图并处理为特征向量;3)训练并测试模型.其中,真实域名是指用来验证模型的域名集合,良性域名是指构成基础词图的域名集合,训练域名是指由恶意域名构成的域名集合.本文使用Wordninja库[21]作为域名分词工具,在下面的3个小节中,将对域名数据的表现形式、词图的构建方式与特征向量获取方法作详细介绍.
1.1 域名数据
我们用x∈Xi(i∈0,1,…,n)表示由相同类型的域名组成的数据集,其中数据集X0包含的都是良性域名,其余n个数据集X1,…,Xn包含所属于n个不同DGA家族的恶意域名.并且,数据集中的域名将被去除域名前缀与顶级域名后缀,仅保留域名中有意义的部分.例如,域名www.sicris.cn将被转化为sicris,再对其进行分词处理.
1.2 构建词图
该步骤使用单词图表示训练数据集Xi中与域字符串对应的词组Wi之间的关系.词图Gi是一个带有顶点集和边集的有权无向图.每个顶点分别对应集合Wi中的每个单词;每条边的权值表示集合Wi中单词两两之间共现的频率,共现是指单词属于同一个词组.注意,具有相似字符串的单词共享同一个顶点,相似在这里是指忽略大小写与单复数.我们使用度中心性来量化每一个单词在词图中的关系.
图2示出一个使用由3个词组组成的集合所构成的词图示例,该集合为[{our,approach,amazing}{our,experiments,well}{this,experiment,well}].由于experiment与experiments这2个单词是相似的,因此它们共享同一个顶点.此外,我们以Gi:j来表示词图Gi结合词图Gj所构建的一个新词图,其中Gi与Gj是由词组Wi与词组Wj所对应创建的词图.
动态生成的恶意域名与人为生成的良性域名在单词共同出现的频率上表现出明显的差异.能最有效地阐明这些区别的是那些在词图中扮演中心角色的单词.为此,本文使用下列公式来描述任意一词组ω的词间关系,ω包括单词ω1,…,ωj,…,ωn:
其中,|ωj|表示单词ωj的长度;M0:i(ωj)和M0(ωj)是推导单词ωj在词图G0和词图G0:i的度中心性函数.因此,该值表示词组ω在由良性数据集X0所构建的词图G0中时与在由恶意数据集Xi结合良性数据集X0所构建的词图G0:i中时词组度中心性的变化.
1.3 构建特征向量
该步骤首先从训练数据集中的域中计算特征向量.根据1.2节定义的词图中的重要值,由词组ω组成的域名特征向量由下式给出:
ω=(V1(ω),…,Vi(ω),…Vn(ω)).
然后,我们将这些特征向量应用于机器学习算法以构建训练模型.由于支持向量机(SVM)优异的识别性能,我们采用支持向量机作为机器学习算法.这一步的输出是模型对未知输入域名进行分割,计算特征向量,并应用训练模型得到关于未知输入域名良性与恶意性质的整体识别结果.
2 实验验证
本节给出了用于评估所提方法有效性的实验.评估的重心主要聚焦于2个方面:1)模型对良性域名和字典型DGA恶意域名二分类的Accuracy值、Recall值与F1值;2)模型针对4个选定的基于字典的DGA家族各自的F1值.实验设计与实验结果在2.1节和2.2节中详细介绍.
2.1 数据集
表2示出实验中使用的良性域名和恶意域名的数据集.7个恶意域名数据集来自FKIE主导的DGArchive项目[22],从中挑选了4个基于字典的DGA家族以及3个非基于字典的DGA家族.另外基于大访问量网站不可能是DGA恶意域名的先验假设,良性域名数据集选用了在Alexa上排名前30万的站点域名.实验中,我们将选择Alexa作为良性域名样本,Gozi,Nymaim2,Pizd,Suppobox这4个基于字典的DGA家族作为恶意域名样本,后3个恶意域名数据集为非基于字典型DGA家族,目的是增加词图的大小与多样性,以及提高特征向量维度.在选中的5个数据集中,我们随机抽取20%的数据作为测试数据集,其余数据作为训练数据集,并对良性域名和恶意域名进行5倍交叉验证.
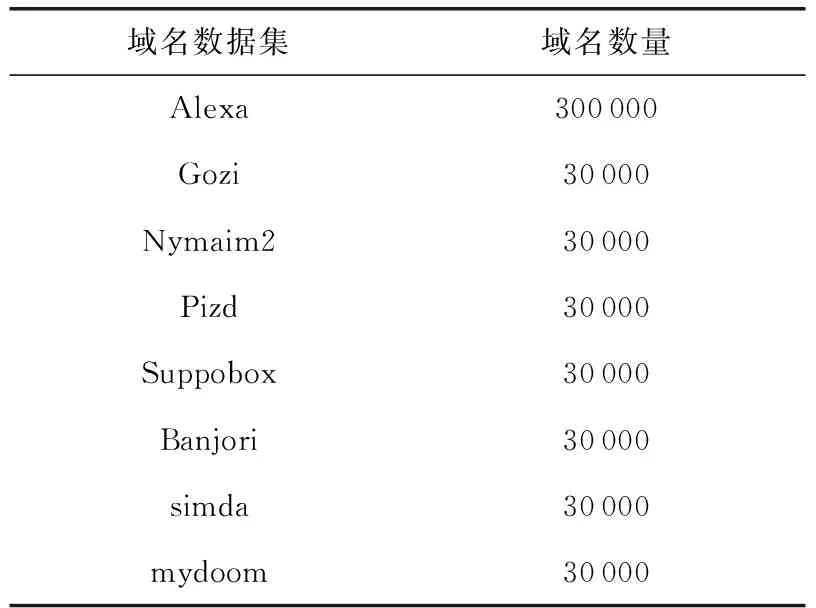
表2 数据集中良性域名与恶意域名数量
为了证明本文方法的有效性,通过字符统计特征的检测方法与基于2-gram模型的检测方法进行对照.在对照实验中,我们使用了与本文方法相同的数据集以控制实验环境.
2.2 实验结果与分析
我们使用3个常用的指标来描述模型对良性域名和恶意域名的识别能力,分别是Accuracy,Recall与F1值. Accuracy是正确预测的样本数量与需要预测的样本总数的比值,Recall是正确预测的恶意域名数量与实际恶意域总数的比值,F1值是Precision与Recall的调和平均值,Precision指模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例.
1) 针对4个DGA家族二分类检测能力
实验首先使用4个恶意域名数据集将本文方法与另外2组对照方法进行二分类实验,实验结果如表3所示:

表3 模型二分类检测4个DGA家族实验结果
实验结果表明:基于词间关系的检测模型在各个指标上都优于对照组模型.在F1值值上,词间关系模型比字符统计特征模型高出3.45%,比2-gram模型高出2.84%.
2) 针对每个家族的F1值
实验使用1)中训练得到的模型,分别对4个DGA家族进行检测,统计检测结果的F1值如表4所示:
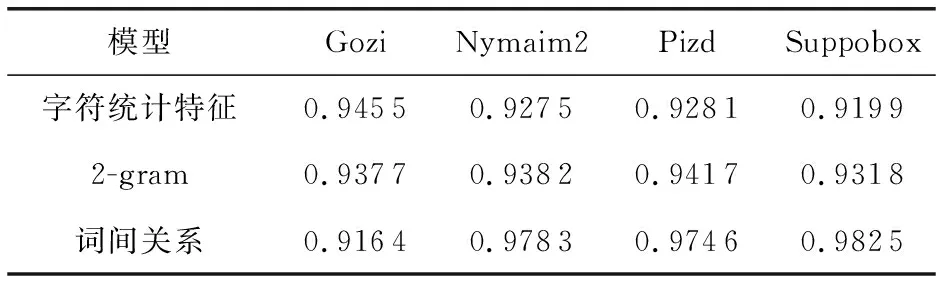
表4 每个家族实验结果的F1值
实验结果表明:词间关系模型在大部分数据集上都表现出优于对照组模型的性能指标,在针对Suppobox家族的检测上,词间关系模型的F1值达到98.25%,相较于字符统计特征模型提高了8.06%,相较于2-gram模型提高了5.07%.但在针对Gozi家族的检测上,基于词间关系的检测方法F1值却仅为91.64%,低于字符统计特征模型2.91%,低于2-gram模型1.73%.经过分析,原因是Gozi家族的域名生成字典来源于从指定网页实时摘取的单词,该方法会出现从网页摘取的单词并非完整的情况,进而使得生成的DGA域名不具有自然语言的意义,再通过词间关系模型对其进行检测将得到较差的性能指标.
2.3 实验总结
上述实验表明:在检测性能上基于词间关系的检测方法在各项指标都明显优于对照组方法.在进行4个DGA家族的二分类实验时,基于词间关系的检测方法F1值为96.48%,相较于基于字符统计特征的方法提升了3.45%,相较于基于2-gram的检测方法提升了2.84%.可以看出,本文方法在面对典型的字典型DGA域名时优于传统检测方法,但对于字符熵较高的DGA域名的检测性能相对传统检测方法较差.
3 结 语
本文提出一种基于恶意域名词间关系的字典型DGA检测方法,该方法首先利用分词工具将域名分割成为表征域名组成的单词词组,进而利用有权无向图构建该词组所对应的词图,并通过词组中所包含单词在词图中度中心性的变化来描述良性域名与恶意域名的差异.实验结果表明,基于恶意域名词间关系的检测方法在针对字典型DGA域名时检测效果优于其他模型,但在针对字符串熵值较高的DGA域名的检测中还有一定的优化空间.在接下来的研究中,将探索一种更为准确的表征单词在词图中关系的量化方式,并尝试引入深度学习技术,以进一步提高模型的检测性能.
猜你喜欢
中老年保健(2022年6期)2022-08-19
昆明医科大学学报(2021年1期)2021-02-07
天津医科大学学报(2021年1期)2021-01-26
江苏教育研究(2020年2期)2020-04-10
江苏教育研究(2020年1期)2020-04-10
高中生学习·高三版(2014年3期)2014-04-29
