
基于归一化植被点云的林分平均高及蓄积量反演
2022-01-27 06:28王照利王浩伟杨佳乐段梦琦马胜利
林业资源管理 2021年6期
王照利,王浩伟,杨佳乐,段梦琦,马胜利
(1.国家林业和草原局西北调查规划设计院,西安 710048;2.中煤航测遥感集团有限公司,西安 710199)
传统森林资源调查受自然环境、交通、气候等影响,调查周期长、成本高、效率低,已不能满足新时期林业经营管理的需求。激光雷达具有极高的距离分辨率和较强的抗干扰能力,可精确获取树木和林冠下地形地貌,将其应用于提取林分相关因子,可以改善传统作业方式成本高效率低的弊端,提高森林调查精度,减少外业数据采集。Getzin等[1]利用无人机载相机获取的高分辨率影像提取了温带森林的林窗信息,Saarinen等[2]利用无人机载摄影测量点云及高光谱影像评估了样地尺度的森林生物多样性,均取得了较优的实验结果,为激光雷达在森林资源调查的应用提供了重要论证。
冠层高度模型(Canopy Height Model,CHM)表征植被冠层垂直分布情况,消除了地形起伏对树木高度及形状的干扰,反映了排除地形影响后的林区植被高度信息[3]。传统方法使用数字地表模型(Digi-tal Surface Model,DSM)和数字高程模型(Digital Elevation Model,DEM)差值得到CHM[4]。其本质是将点云数据划分成格网,用格网中的局部最大值与地面点进行栅格差值运算,保留了林木的冠层信息,适用于林层单一且郁闭度较低的人工林[5]。多数学者均使用DEM与DSM二者差值运算得到CHM[6-8],进而根据CHM提取的上四分位数处高度变量与样地实测树高的关系,从而估测单木树高、冠幅等参数。自然界中林区大多数地势复杂,林木茂密,存在遮挡现象,CHM在栅格差值中只保留了树顶和上层树冠的空间点数据,易丢失冠下结构信息,从而造成林相复杂时估测精度降低。
本文提出一种改进的冠层高度模型计算方法,通过计算所有植被点与地面点之间的高程差,得到去除地形影响的归一化植被点云(Normalizing Vegetation Point Cloud,NVPC),该方法保留了植被除冠层以外的整体形态信息,对林分描述更为全面,以此作为依据进行林分平均高及蓄积量等森林生态参数的反演能有效提高计算精度。
1 研究区概况
研究区位于贵州省南部荔波县小七孔镇,地理坐标北纬25°7′~25°9′,东经107°37′~108°18′。该区属亚热带季风性湿润气候,年平均温度18.3℃,无霜期283d,年降雨量1 320.5mm,优势树种为马尾松,伴生树种有杉木、枫香、桦木等。
2 研究方法
2.1 数据采集
2.1.1激光点云数据采集
采用无人机固定翼机载雷达+正射系统数据采集方式获取林区点云数据及影像数据。飞行采用的激光扫系统为AS-1300HL,搭载Riegl VUX-1LR激光传感器,激光发射最大频率820KHz,最小测距5m,测量精度15mm,飞行高度230~260m,飞行速度80km/h,设计飞行航线17条,获取点云平均密度为每平方米28个点。
2.1.2地面样地布设调查
2020年9—10月在荔波县国家储备林内,布设方形样地100个,大小均为25.82m×25.82m,优势树种为马尾松。对每块样地分别进行每木调查,测定并记录标准地内每株树木的树高、胸径、材积等,同时记录样地的蓄积、株树及郁闭度等森林参数。
2.2 点云分类
使用渐进加密三角网算法对研究区点云数据进行地物点与地面点的分类[9]。首先,通过种子点生成一个稀疏的地面三角网,然后,通过迭代算法逐层将满足阈值条件的点添加到当前三角网中来,直到所有满足条件的点均被添加,从而实现地面点和非地面点的滤波分类。在获取精确地面点云之后,利用点云垂直分布的特性,将非地面点云和地表进行垂直方向高差分析,对非地面点数据子集进一步利用高程阈值法,将非地面点分为植被点和其它类型的激光回波点。该过程的数据流图如图1所示。
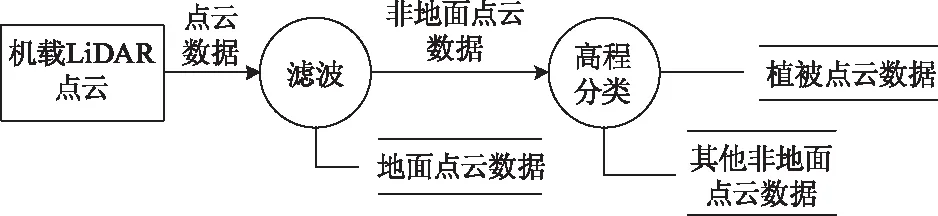
图1 林木资源自动识别过程数据流图Fig.1 Process of forest resource automatic identification
2.3 NVPC计算
传统的CHM模型是利用DEM数据与DSM数据作差得到,其流程如图2所示。该方法对于地势复杂的陡坡等地区,会出现因地势起伏过大无法完整扫描到地形的情况,从而造成地面点丢失,进而导致后续计算结果出现较大误差。
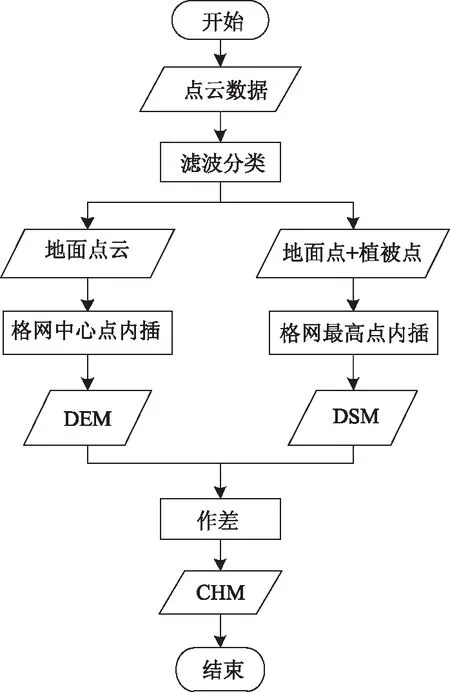
图2 传统CHM计算方法Fig.2 Computing method of traditional CHM
本文提出一种改进的CHM计算方法,引入NVPC的概念,直接利用植被点与地面点云数据,计算植被点相对地表的垂直高度,从而生成优化的归一化植被高度点云,减少栅格差值过程中的误差。其流程如图3所示。
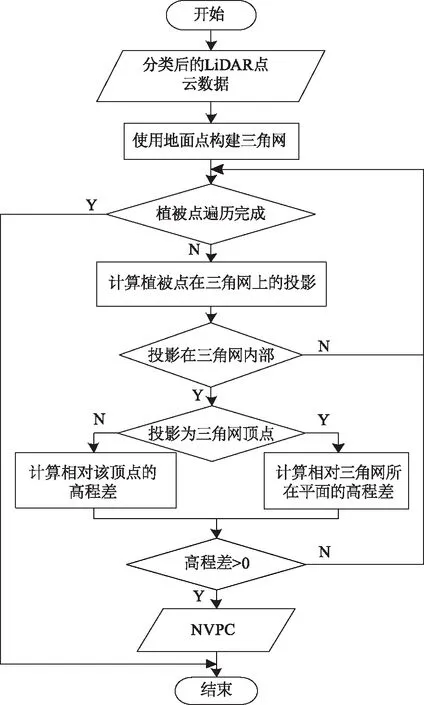
图3 NVPC计算方法Fig.3 Computing method of NVPC
具体步骤为:
1) 对点云数据进行滤波处理,得到分类后的地面点云和植被点云;
2) 使用地面点云为待测区域构造三角网;
3) 循环遍历每一个植被点,将其沿z轴方向垂直投影;
4) 使用四叉树索引查找三角网,判断植被点投影相对于三角网的位置;
5) 若投影在三角网内部,则计算其相对于所在三角网的绝对高度,并记录该高程差值Δz,由Δz代替该植被点的z坐标值;
6) 直到所有植被点均完成搜索,去除高程差为0的点,并以此生成NVPC。
当待测区域林相较复杂时,使用植被点云直接生成NVPC,可有效保留冠下植被信息,这一技术可实现对林木的整体描述,更为全面细化,能够有效解决使用数字表面模型时造成的下层植被信息丢失等问题。
2.4 基于NVPC的森林特征变量提取
以计算的NVPC为基础,提取森林参数特征变量,包括高度特征(最大高程、最小高程、平均高程、高程四分位间距、方差、标准差、分位数高度)及密度特征(分位数高度以上点在植被点中所占比),并采用随机森林算法(Random Forest,RF)构建基于NVPC森林特征变量参数与林分平均高及蓄积量的估测模型。本文提取的特征变量如表1和表2所示。

表2 密度特征变量及其描述表Tab.2 Description of density characteristics variables
随机森林算法从原始样本集中有放回的重复随机抽取N个新样本集,并由此构建N棵决策树,且决策树在生长过程中不进行剪枝操作,然后组合多个决策树进行结果的回归反演[10]。本文将提取的k组森林特征变量D1,D2,…,Dk划分为训练数据D-Dt,测试数据Dt,t=1,2,…,k,每组训练集对应一组测试集,分别将每组训练集作为RF的训练数据,通过算法内部不断迭代计算,得到对应的模型,分别使用每组模型对应的测试数据测试回归模型,从而得到各模型的精度,选取精度最高的模型并以此代表该样方数据集D下的最终模型结果。
使用实测值与反演结果的拟合精度对模型进行评价,根据公式(1)计算:
(1)
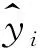
3 结果与分析
3.1 CHM对比
针对同一片点云数据,通过DSM与DEM差值运算得到的CHM同本文中直接使用植被点云与地面点云差值得到的NVPC对比情况如图4所示。其中a,b,c分别为原始点云数据、DSM与DEM差值得到的CHM,以及改进的植被点云与地面点云差值得到的NVPC。
从图4对比可以看出,当低矮植被与高大植被比较靠近时,DSM与DEM差值法得到的CHM丢失了低矮植被的细节信息,造成其形态轮廓不完整,容易与邻近高大植被混为一体,从而影响森林株数、蓄积量等森林生态参数的计算。而NVPC方法在将地面置平的基础上,能够清晰的保留全部植被结构信息,为后续植被特征参数正确提取提供保障。
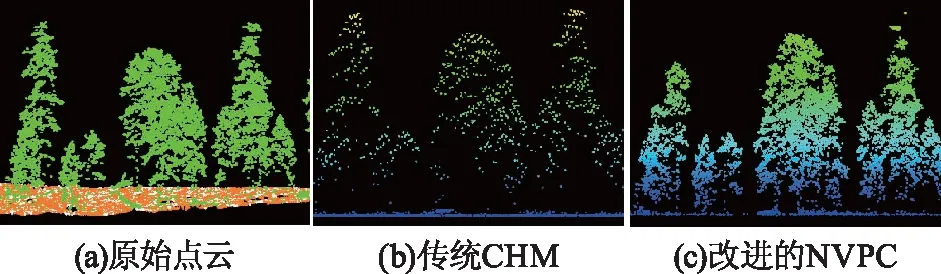
图4 不同算法下的植被点云结果示意图Fig.4 Vegetation point cloud of different algorithm
当林相结构较为复杂时,即点云的垂直结构上存在不同林龄的树木,对比结果如图5所示。其中a,b,c分别为多林龄原始点云数据、DSM与DEM差值得到的CHM,以及改进的植被点云与地面点差值得到的NVPC。
从图5对比可以看出,对于在点云垂直结构上存在多种林龄的情况,传统方法计算DSM时仅使用格网中最大值,由于植被间存在遮挡,生成的CHM只有上层林木的表层信息,被遮挡的植被信息全部丢失。而改进后的算法能够完整保留不同高度的植被点,有效杜绝精度丢失。
3.2 林分平均高及蓄积量反演精度对比
针对研究区内布设的100个样方进行试验,大小均为25.82m×25.82m,随机选取其中70个样方数据用于计算回归模型,剩余30个样方数据用于模型精度检验,分别计算样方的冠层高度模型及归一化植被点云,以此为基础提取相应的特征参数,并使用随机森林算法进行森林生态参数的反演回归,最后根据模型的拟合优度及均方误差对模型进行评价。本次试验对林分平均高及蓄积量进行森林生态参数反演。部分样方统计结果如表3、表4所示。
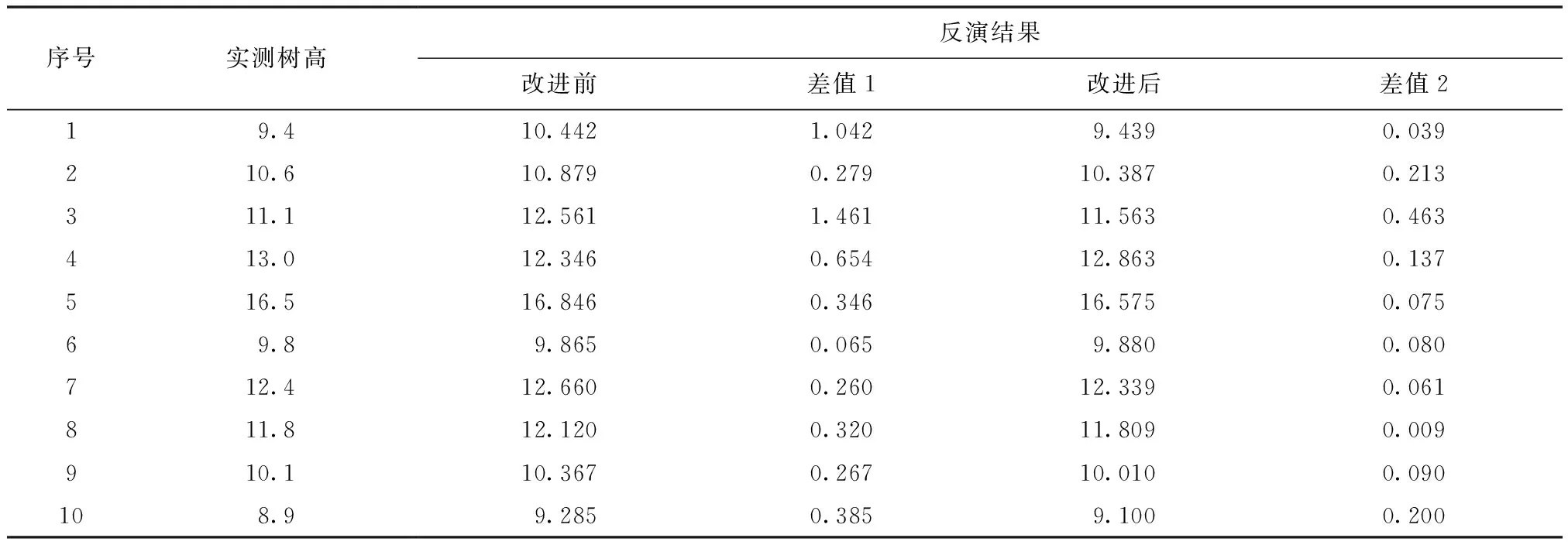
表3 林分平均高模型评价结果对比Tab.3 Comparison of average stand height model m
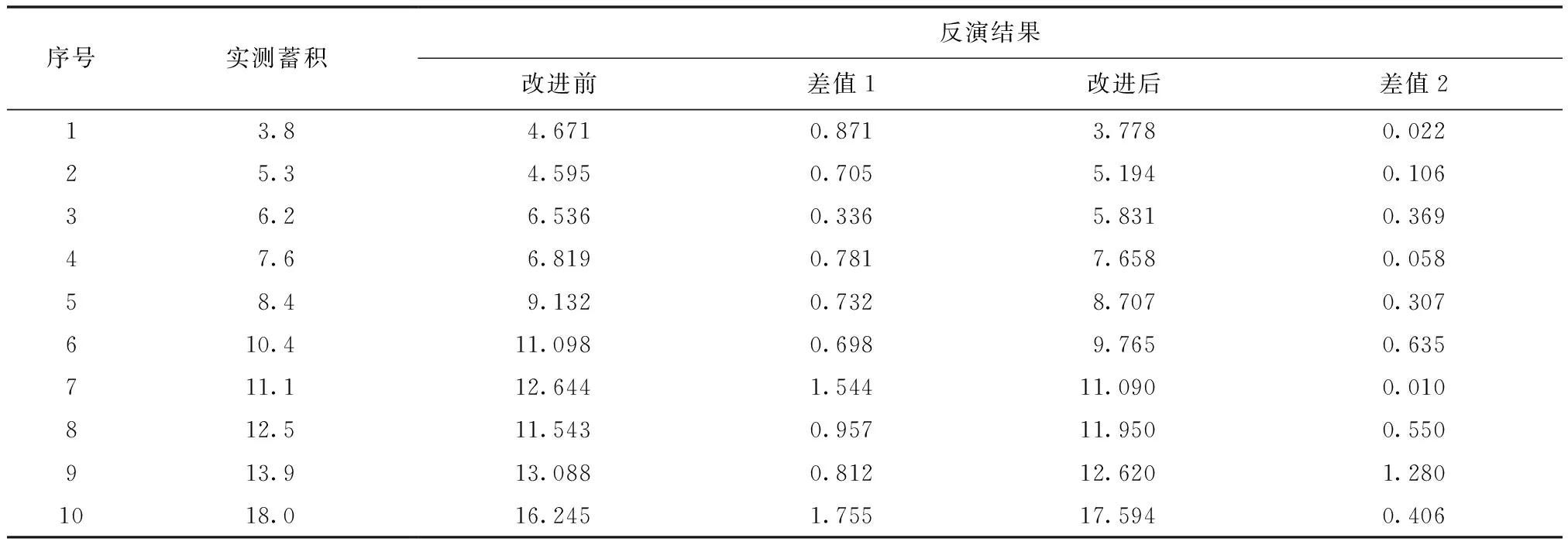
表4 蓄积量模型评价结果对比Fig.4 Comparison of stock volume model m3
对布设的100个样地的林分平均高和蓄积量的拟合结果分别图6、图7所示。
通过模型评价结果对比分析得知,分别使用传统方法提取CHM和提取归一化植被点云对100个样地的林分平均高拟合度R2分别为0.91和0.94,改进前后对蓄积量的拟合度R2分别为0.90和0.93,基于NVPC计算的森林生态参数具有较优的精度。
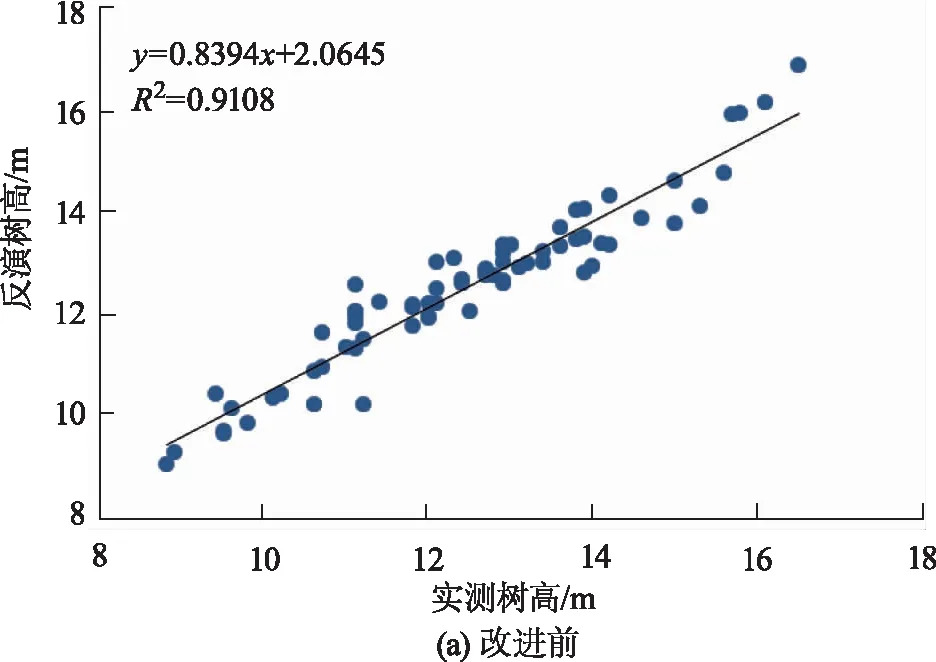
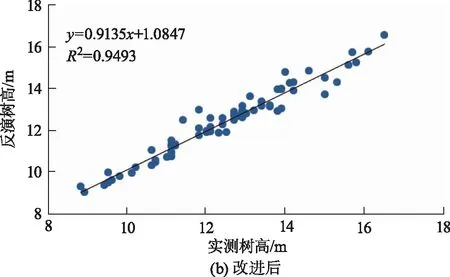
图6 改进前后林分平均高拟合结果示意图Fig.6 Fitting result of average stand height before and after improvement
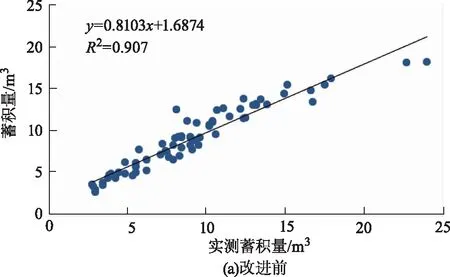
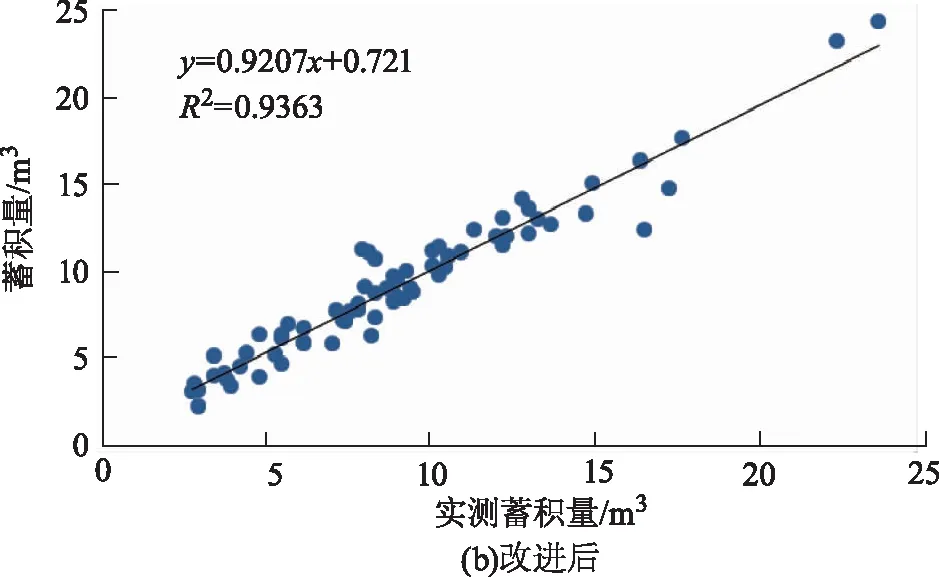
图7 改进前后蓄积量拟合结果示意图Fig.7 Fitting result of stock volume before and after improvement
4 讨论与结论
冠层高度模型反映了去除地形影响的植被垂直分布情况,直接影响着森林特征变量的提取,进而影响森林生态参数的反演精度。本研究引入NVPC的概念,即利用测区的激光雷达点云数据,计算植被点与地表的垂直高度差,并根据NVPC中提取的植被特征变量反演森林生态参数。以贵州省荔波县小七孔镇马尾松人工林为研究对象,借助机载激光雷达点云,构建实验区的冠层高度模型,提出一种归一化植被点云计算方法,并与改进前的方法进行比较,同时讨论并分析了改进前后对林分平均高及蓄积量拟合结果的影响。
1) 本文提出的NVPC计算方法在郁闭度较高、存在植被间错落遮挡的的复杂林分中有较强优势,能够有效保留所有植被点的高程值,更加全面的描述林区植被的垂直分布结构。
2) 使用NVPC对森林生态参数的拟合精度更高,其中林分平均高的拟合精度R2提升至0.949,蓄积量的拟合精度R2提升至0.936。
3) 本研究主要针对人工林采集的点云数据,存在一定的局限性,后续研究可以针对天然林开展实验。另外,对于NVPC对其他森林生态参数(如郁闭度、胸径、冠幅面积等)的影响没有进行讨论,有待以后做更深入和准确的分析研究。
猜你喜欢
昆明医科大学学报(2021年5期)2021-07-22
防护林科技(2020年6期)2020-08-12
绿色科技(2019年6期)2019-04-12
绿色科技(2019年6期)2019-04-12
高中时代(2017年7期)2018-02-24
南方农业·下旬(2017年8期)2017-10-23
绿色科技(2017年16期)2017-09-22
现代农业科技(2017年12期)2017-07-29
安徽农学通报(2014年9期)2014-06-23
