
时变特性的人脑超网络构建方法及其分类
2022-01-26 07:35:46刘永艳闻敏李瑶IbegbuNnamdiJulian郭浩
科学技术与工程 2022年1期
刘永艳,闻敏,李瑶,Ibegbu Nnamdi Julian,郭浩
(太原理工大学信息与计算机学院,晋中 030600)
抑郁症(major depression disorder,MDD)是一种严重的精神疾病,主要症状表现为情绪低落,悲观,思维迟缓,缺乏主动性,饮食、睡眠差,严重者可出现自杀念头和行为。影响着世界上超过6%的人口。同时,MDD在所有已报告的脑疾病中占比高达98%。尽管MDD在医学领域内多有研究,但对其临床诊断和发病机制的研究还没有取得较大的突破。
幸运的是,神经影像技术的出现帮助人们进一步了解了人类大脑,为脑功能网络研究提供了坚实的基础。功能磁共振成像(functional magnetic resonance imaging,fMRI)[1]是一种新型的神经影像技术,已成功应用在不同的脑疾病诊断中[2]。基于fMRI获得的数据,人们提出了功能性大脑连接模型的分析方法[3]。传统的脑网络构建方法,如Guo等[4]提出了图形化模型,Wang等[5]提出了基于相关的方法,Akin等[6]提出了基于偏相关的方法,Yu等[7]提出了稀疏表示方法,这些方法只能获取两两相关的数据,不能完全反映大脑中多个区域之间的相互作用[1]。最近的研究表明,在神经元同位素示踪、皮层活动和局部场电位中存在更高阶的相互作用[8]。神经科学研究表明,在同一时间内,神经元活动过程中,一个大脑区域与其他多个大脑区域之间存在直接相互作用。这意味着大脑区域之间的高阶关系被忽略了,而这些关系可能对大脑和相关疾病的研究是重要的。且脑网络在本质上是动态的,相互作用的神经元之间的动态变化可能正向影响相关功能连通性的拓扑结构和关联强度,而这些微妙的变化可能是脑疾病发作的诱因[9]。
为了解决上述问题,Jie等[10]利用稀疏表示从静态时间序列构建了超网络。超网络可以有效表现出人脑这一复杂系统中信息交互的空间层次中的多元高阶关系。在现有的超网络构建方法中,重点仅在于脑区之间的相互作用,从而存在一定的局限性,因为这种相互作用在本质上是静态的,而功能连接的时变特性可能包含非常多的信息,从而可能无法从图中获取有用信息[11]。刘磊等[12]提出的高阶功能连接网络可以解决脑网络的动态变化问题,其可体现出时间层次的动态变化。通过划分时间窗的方法来构造动态低阶功能连接网络,堆叠所有时间窗下的动态低阶功能连接网络,进而计算两两动态时间低阶功能连接网络间的皮尔逊相关系数,得到高阶功能连接网络。此外,一些研究者尝试将两种网络进行融合,Guo等[13]提出了一个基于感兴趣区域的高阶网络(空间层次),并将高阶有网络与低阶网络进行融合并分类。但是这些方法都没有同时体现脑网络的时间层次的动态性和空间层次的高阶关系。
因此,现提出一种具有时变特性的超网络构建方法,即融合高阶功能连接网络和超网络的特性。使所构建的网络不仅能有效反映空间中具有多重关系的多个脑区之间的相互作用,还能体现出时变特性对网络的动态影响。
首先,使用独立成分分析(independent component analysis,ICA)[14]模板构建低阶功能连接(functional connection,FC)网络[15]。独立成分分析模板是一种多元数据驱动的分析方法,不需要预设模板。为每个被试构建功能连接网络并将其堆叠在一起。每个被试的功能连接网络的堆叠揭示网络随时间的动态特性。然后,在每个被试的堆叠的低阶功能连接网络基础上,构建超网络。在这项研究中,使用稀疏线性回归模型来构建超网络,并由最小绝对值收敛和选择算子(least absolute shrinkage and selection operator,LASSO)方法进行求解。最后,根据超网络的聚类系数,提取特征,通过非参数置换检验方法选择具有显著差异的特征。使用支持向量机(support vector machine,SVM)[16]对差异性特征进行分类。
1 材料与方法
1.1 方法步骤
基于时变特性的MDD患者的超网络构建及分类方法包括以下5个步骤。
步骤1数据采集及预处理。采集MDD被试和正常被试的功能磁共振成像数据进行预处理。
步骤2组独立成分分析(group independent analysis,GICA)。主要包括数据降维、独立成分估计、数据重构以及去除噪声。
步骤3低阶功能连接网络的构建。根据模板划分成分,提取每个成分的平均时间序列。选择固定的滑动窗口分割每个成分的平均时间序列,计算两两时间序列间的皮尔逊相关系数,构建低阶功能连接网络。将所有的低阶功能连接网络进行堆叠,即对每个时间窗口下低阶功能矩阵中的相应元素的值进行提取,形成时变的低阶功能连接网络。
步骤4超网络的构建。采用LASSO方法求解稀疏线性回归模型,根据上述产生的时变的低阶功能连接网络,使用该模型构建每个被试所对应的超网络。
步骤5特征提取、选择和分类。构建超网络后,引入3种不同定义的聚类系数作为超网络的局部特征。以统计差异分析为基础,选取最具判别性的特征作为分类的关键特征。即采用Kolmogorov &Smimov(KS)[17]非参数置换检验,并从提取的特征中选择显著性特征。使用支持向量机进行分类。在分类过程中,采用径向基函数(radical basis function,RBF)和留一交叉验证方法[18]进行有效性评估。
1.2 数据采集和预处理
严格按照山西医学伦理委员会的要求(会议号:2012013),在该项研究实施之前,与每位参与者均达成了书面协议。根据《赫尔辛基宣言》,书面知情同意书由实验中的每一个被试签署。总共招募了66名被试,其中包括38名首发,无用药重度MDD患者(15名男性)和28名健康右利手志愿者(13名男性)。静息状态下,应用3T磁共振扫描仪(Siemens Trio 3-Tesla scanner,Siemens,Erlangen,Germany)对他们进行功能磁共振成像(fMRI)扫描。被试的具体情况如表1所示。

表1 被试的具体信息Table 1 Specific information of participants
山西医科大学第一医院完成数据采集任务,并且由精通磁共振技术的放射科医师完成扫描任务。被试在进行扫描时也有相应的要求,即被试需要在放松的状态下闭上眼睛,但不能入睡,需要保持清醒,也不进行特定的思考。每个扫描的结果是248个连续的EPI功能图像,其中的扫描参数有如下设置:轴向切片33,回波时间TE=30 ms,重复时间TR=2 000 ms,厚度/跳过=4/0 mm,偏转角=90°,矩阵=64 mm×64 mm,视野FOV=192 mm×192 mm。前10个功能图像的时间序列由于被试对环境的自适应性以及初始磁共振信号的不稳定性而被丢弃。
用SPM8(http://www.fil.ion.ucl.ac.uk/spm)来完成数据的预处理过程。首先,头动校正和时间片校正必不可少,而在校正过程中,抑郁组和对照组中分别出现2例转动大于3°或者头动大于3 min的被试,因此弃除这些被试的扫描数据。需要注意的是,最后的66例样本数据中不包含那些被丢弃的数据。接着,图像经过优化仿射变换会被标准化到蒙特利尔神经研究所(Montreal neurological institute,MNI)的标准空间中。最后,为降低生物高频噪音和低频漂移的影响,对数据进行带通滤波(0.01~0.10 Hz)和线性降维。
1.3 组独立成分分析
独立成分分析(ICA)已成为处理和分析fMRI数据的重要方法之一。ICA是一种多元数据驱动的分析方法,主要优点之一是它不需要预设模板。从fMRI数据分析中找到不同被试之间的一致模式很重要,但是被试之间的个体差异会导致从不同的被试中获得的成分彼此不一致,并且难以组合这些成分进行分析。通过将所有被试的fMRI数据链接到ICA估计中,提出组独立成分分析(GICA)方法,找出在被试之间表现出较高一致性的通用成分。这样就可以将所得的独立成分用于计算统计显著性。
研究采用GIFT(http://mialab.mrn.org/software/gift)。具体来说,使用最小描述长度(minimum description length,MDL)[19]来估计两组中最优的分解次数。MDL最终被设置为54。为保证独立成分的稳定性和可靠性,对每个fMRI实例和54个空间独立成分使用信息最大化(information maximization,Infomax)算法,在ICASSO上随机化初始分解矩阵,重复20遍Infomax算法,得到相同的收敛阈值。最后,使用GICA3算法反转数据,并对其进行重构,获得被试独立成分的空间分布和时间序列。
经过GICA处理后,提取到很多成分,但其中一些是不需要的,而某些成分还包含了较大的噪音。为了选择重要的成分,采用了匹配法和人工检查法来确定所筛选出来的成分[20]。排除成分的标准包括较大的激活区域,其中的多元回归系数与先前模板匹配;主要激活区域在灰质中的分布,以及这些区域与已知成分(例如血管和低频空间中的头部运动)的重叠。低频功率在激活区域中对时间序列功率谱的控制[21]。
经过筛选,共获得22个成分。发现这些成分是听觉网络、感觉运动网络、视觉网络、默认模式网络、注意力网络或额叶网络的一部分。如图1所示,显示了属于上述各个网络的成分。

图1 成分及其各自网络的空间地图Fig.1 Spatial maps of components and their respective networks
1.4 网络构建
1.4.1 动态低阶功能连接网络的构建
使用ICA模板,大脑被分为22个(左右半脑各11个)成分。计算每个成分中体素的血氧水平依赖(blood oxygen level-dependent,BOLD)信号的平均值,这代表每个节点的信号值。通过提取所有体素在不同点的BOLD信号值并求平均值,得到22个成分的平均时间序列。选取一个固定的窗口大小,对提取的平均时间序列进行分割[22]。
采用滑动窗口法将时间序列划分为重叠子序列的片段,每个片段代表较短时间内的序列。假设rs-fMRI的平均时间序列是针对第l个被试的第m个感兴趣成分,K个重叠段的表达式为
K=[(M-N)/s+1]
(1)
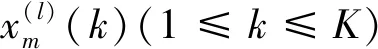
对于第l个被试的R个成分,第k段的矩阵形式表示为

(2)
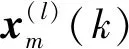
(3)
(4)

1.4.2 具有时变特性的超网络的构建
超网络的构建是将上述矩阵Y(l)中的每一个时间序列分别作为新的节点集,并利用稀疏线性回归模型[23]来构建超网络。使用该模型,可以获得Y(l)中所有时间序列两两之间的交互。
稀疏线性回归模型采用的公式为
Xi=Aiαi+τi
(5)
式(5)中:Xi为指定Y(l)的第i行;Ai=[X1,…,Xi-1,0,Xi+1,…,Xu]为包含Y(l)中除第i行以外的其他所有行的数据矩阵;αi为权重向量,表示其他行时间序列对第i行的影响程度;τi为噪声项。
采用LASSO方法对稀疏线性回归模型进行处理和计算,优化函数如下。
min‖Xi-Aiαi‖2+λ‖αi‖1
(6)
式(6)中:‖·‖1为L1范式;‖·‖2为L2范式;λ为调节模型稀疏度的参数,该稀疏度代表不同稀疏解。λ的取值是一个范围,取值越大表示αi中有更多的零值。模型具有的零值数目越高,模型将越稀疏。λ值的范围为0.1~0.9。此外,为了解决优化问题,使用SLEP软件包[24]。
每个被试可以构建得到一个超网络,其中一个时间序列被认为是一个节点,超网络中的一条超边ei不仅考虑到中心时间序列(第i个时间序列),还考虑了用式(6)计算得到权重αi中其他非零权重对应的时间序列。由于时间序列之间可能存在多层次交互作用,可以通过在0.1~0.9范围内给出不同的λ,为每个时间序列生成一组超边。具体来说,对于每个被试,总共有u个时间序列,其中u=[R(R-1)]/2,R表示每个被试中成分的个数。假如设置num个不同的λ,则可以生成得到的表示超网络连接关系的矩阵A,其中A∈Ru×u×num,num设置为9。这个最终的矩阵就是用LASSO方法构造的超网络[25]。
1.5 特征提取
构建功能连接超网络之后,选择超网络中每个顶点的属性值作为特征。对已构建的超网络进行指标计算,定义了3种聚类系数,分别具有不同的定义[26],分别记作HCC1、HCC2以及HCC3。这3种聚类系数从不同的角度反映了超网络的局部聚类属性。
(7)
(8)
(9)
式中:u、t、v为节点;N(v)为集合,指超边中除了节点v以外,还包括其他节点的集合;|e|为超边中包含的节点数目;S(v)为超边集合,这些超边中都含有节点v,且S(v)={ei∈E,v∈ei}。
式(7)计算与节点v不存在连接的相邻节点的数目。如果E表示边集,ei表示某一条超边,则I(u,t,-v)=1当且仅当∃ei∈E,u,t∈ei,但v∉ei;否则I(u,t,-v)=0。HCC1查找不包含u的邻居之间的连接,HCC1的优点是,在这个集合中发现的任何交互都可能表示邻居之间的真实连接。它的缺点在于可能过分关注于那些次要的共享连接,这些连接与u的交互没有什么关系。
式(8)计算与节点v存在连接关系的相邻节点的数目。如果∃ei∈E,u,t∈ei,则I′(u,t,-v)=1。HCC2查找那些包含u的邻居的连接,这种方式找到的边真实地反映了u和邻居之间的聚集。但是需要注意这种连接可能只是与u共享连接的人工数据。
式(9)计算超边之间的重叠量,具体指节点v的相邻超边。|e|表示超边中包含的节点数目;S(v)指超边集合,这些超边中都含有节点v,且S(v)={ei∈E,v∈ei}。其分子表示与u相关联的超边的顶点个数。分母表示这种重叠可能的数目。HCC3则通过邻域超边的重叠量来衡量邻域的密度。与以上两种定义都不同,它从节点的角度来定义重叠量。
对于HCC1、HCC2以及HCC3,从超网络中提取一组聚类系数作为特征,因此每个被试对应3组特征。
1.6 特征选择和分类
从超网络中提取了多个特征,但是其中一些提取的特征是多余的。以统计差异分析为基础,选择最具判别性的特征作为分类的关键特征。计算每个被试所对应的平均聚类系数(HCC1、HCC2以及HCC3,分别对231个脑区进行平均),使用KS非参数置换检验来分析两组特征是否具有差异。用KS检验比较正常对照组和抑郁组的所有693个特征及其性质,选取局部属性(P<0.05)(聚类系数)。将所选择的属性作为分类特征,用于建立分类模型。
将N个特征中的每个特征都分别作为测试集,其他的N-1个特征作为训练集。训练集使用K折交叉验证(K-fold cross validation,K-CV)[27]对惩罚因子c和核参数g进行寻优。在测试集验证中,c和g的最优值取分类准确率最高的那组值,并由此建立N个不同的模型。在标准化分类特征的平均值和标准偏差后,最后的分类结果取不同模型的分类准确率的平均值。
2 结果与分析
2.1 异常成分
经过特征选择和特征提取,选出了27个显著的功能连接。选择这些连接的原因在于,和这些连接有关的成分记录了与其他成分的最大连接数。在22个成分中,IC25、IC33和IC43的出现次数最高,各7次,IC39出现6次。这些成分共有27个功能连接,如表2所示。
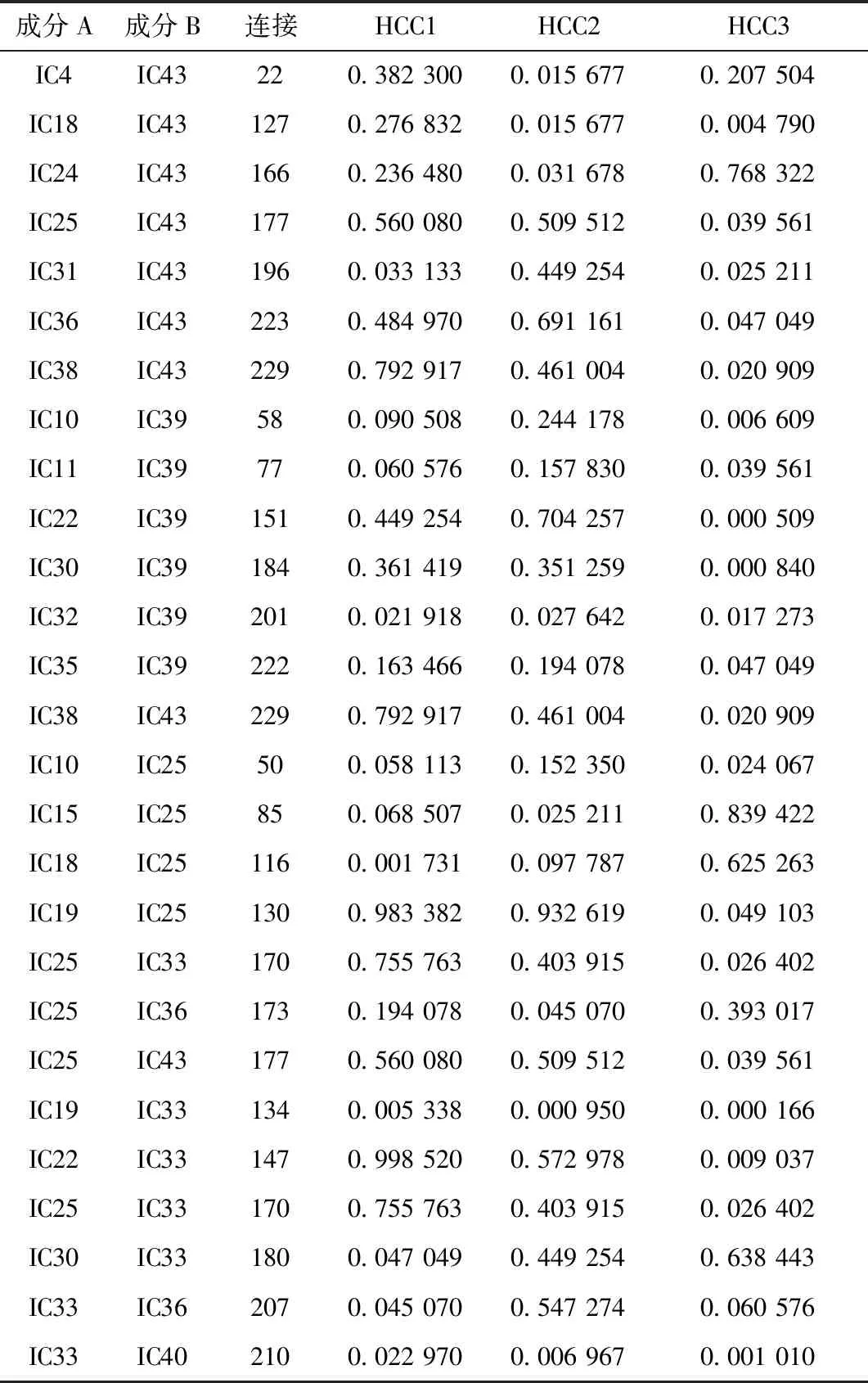
表2 27个功能连接对应的数据信息Table 2 Data information corresponding to 27 functional connections
2.2 分类结果
研究的主要目的是创建一个与多个成分交互的超网络,并反映神经交互作用随时间的动态变化。
对于MDD的分类结果,对比了不同的方法,包括稀疏时间动态网络(sparse temporally dynamic networks,DNwee)方法,动态高阶网络(dynamic high-order network,DNH)方法、分层高阶功能连接网络(Hierarchical high-order FC networks,HHON-SFS)方法和基于时变的超网络构建方法。如表3所示,可以看出,所提方法具有明显更高的准确率,可以更好地对MDD进行分类。
此外,不同研究采用的数据集与方法都存在差异,因此,为了评估本文方法的有效性,还在同一数据集下构建了超网络(hyper-network,HN)、低阶功能连接网络(low-order function connection networks,LON)以及高阶功能连接网络(high-order function connection networks,HON),并进行了对比。如表4所示,显示了具有时变特性的超网络与上述网络在分类精度上的显著优势。

表4 同一数据集下不同构建方法的分类结果Table 4 Classification results of different network construction methods with the same data set
此外,经过特征提取和选择过程后,分类准确率为86.36%,特异度为92.10%,灵敏度为78.57%。
3 方法论
具有时变特性的超网络构建和所选分类方法的性能在很大程度上依赖于一组特定参数的选择,如滑动窗口长度(大小)、步长、超网络构建模型参数(λ)和SVM分类模型参数(c和g)。这些参数值的变化会显著影响我们得到的结果。为了得到最佳的分类结果,必须为每个参数选择最优值。另外,为了获得尽可能高的分类精度,选择了不同的参数值组合。
3.1 滑动窗口长度
滑动窗口长度的变化会改变时间窗口的数量,这也将影响为每个被试构建的低阶功能连接网络的数量。在其他参数保持不变,步长固定为2 s的情况下,选取窗口长度分别为40、50、60、70、80、90 s,研究各自的结果。当窗口长度设为60 s时,得到了最优结果。值得注意的是,当滑动窗口长度过大或过小时,该方法的精度显著降低。与使用不同窗口长度的高阶网络相比,本文方法的分类结果如图2所示。
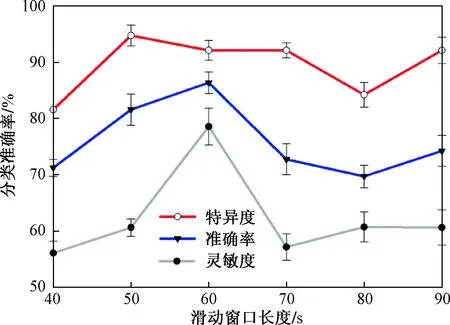
图2 不同滑动窗口长度的分类结果Fig.2 Classification results of different sliding window lengths
3.2 正则化参数的影响
λ是超网络建设中最重要的参数之一,因为它控制着网络的稀疏性。网络拓扑和模块性高度依赖于稀疏性。λ太大会导致网络稀疏,而太小会导致网络过于粗糙甚至可能包含噪声[30]。这些都将导致网络的缺陷。因此,重要的是找到λ的最佳值以给出最佳结果。结果表明,当λ设置为0.1时,网络是最可靠的。λ设置为0.1意味着网络中每个节点都至少在一条超边上[31]。先前的研究[10]表明,多级λ设置是最好的方法,因为它可以组合多个λ以提供有关网络的更多信息。使用一系列值升序排列组合表示λ,即为{0.1},{0.1,0.2},…,{0.1,0.2,…,0.9}。较小和较大的λ被舍弃,这证明了节点是在超网络中连接的,使得特征提取更加具体。
3.3 SVM分类参数的影响
SVM分类器在各领域中的应用都比较广泛,而分类时经常涉及到核函数的选取问题。由于RBF核函数应用广泛,无论是小样本还是大样本均试用。因此,在分类中选取RBF核函数。SVM模型中有两个参数对分类影响较大,即惩罚因子c和核参数g:c表示调节优化方向中两个指标(间隔大小,分类准确度)偏好的权重,即对误差的宽容度,c过大或过小,其泛化能力都会变差;g隐含地决定了数据映射到新的特征空间后的分布,g越大,支持向量的个数越少,反之则越多,而支持向量的个数影响训练与预测的速度。最优的c和g能使SVM的分类性能达到最佳。对于如何找出最佳的c和g,首先选取某一组给定的c和g的值,把训练集作为原始数据集,利用K-CV方法得到在该组c和g下的训练集验证的分类准确率,然后不断更换c、g的值,最终取使测试集验证分类准确率最高的那组c和g作为最佳参数。参数c、g可在[2-8,28]内变化,并将1设置为步长大小。图3表示参数c和g的寻优结果,结果显示,测试集验证分类准确率最高时的c、g参数的值分别为2和0.062 5,最高准确率是91.923 1%。

图3 c和g的参数寻优结果Fig.3 Parameter optimization results ofc and g
4 结论
超网络已被证明是脑诊断中重要的脑网络构建方法之一。然而,现有的超网络构建方法忽略神经相互作用在一段时间内的动态变化。为了解决这一问题,提出了一种具有时变特性的超网络的MDD分类方法。提出的网络不仅显示了两个以上成分(大脑网络)在同一时间内的内在相互作用,而且考虑了相互作用之间的时变特性,为分类和诊断提供了大量信息。此外,本文方法具有较高的分类准确率。由此证明,具有时变特性的超网络是一种更强大的网络构建方法,可以为MDD和其他脑疾病的分类提供更丰富的信息。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
矿产勘查(2020年11期)2020-12-25 02:55:34
数学物理学报(2019年3期)2019-07-23 01:15:30
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
数学物理学报(2018年3期)2018-07-17 06:15:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
智富时代(2017年4期)2017-04-27 17:08:47
广东石油化工学院学报(2016年6期)2016-05-17 05:17:43
中国煤层气(2015年3期)2015-08-22 03:08:23
