
融合多头自注意力的远程监督关系抽取方法
2022-01-26 09:26:04李思琪朱庆陈钰枫徐金安张玉洁
情报工程 2021年6期
李思琪 朱庆 陈钰枫 徐金安 张玉洁
北京交通大学计算机与信息技术学院 北京 100044
引言
关系抽取作为自然语言处理领域中一项重要的基础任务,旨在判断出文本语句中实体对之间存在的语义关系。传统的基于有监督方法的关系抽取依赖于高质量的人工标注数据,需要花费大量的时间和人力。于是,能够在现有的知识库和语料库的基础上,自动标注训练数据的远程监督方法逐渐成为了关系抽取研究任务的热点。
远程监督的概念由Mintz等[1]于2009年提出,其核心思想是:若在现有的知识库中存在某一个实体关系三元组(实体1,关系R,实体2),则认为在语料库中,所有同时包含有实体1和实体2的文本语句,都表达了关系R。例如:在知识库中,有一个实体关系三元组(比尔盖茨,创始人,微软),则将所有“比尔盖茨”和“微软”同时出现的句子都标记为“创始人”的关系。通过远程监督思想可以在短时间内获得大量标注好的训练语料,但是由于其假设过于强硬,不可避免地导致了错误标注的噪声问题。例如在句子“在1992年,比尔盖茨拥有超过40%的微软股票,经过这么多年不断地抛售后,现在他只有1%了”中,同时出现了“比尔盖茨”和“微软”两个实体词,但是表达的关系却不是“创始人”的关系。因此,如何降低语料中的噪声数据影响,提升关系抽取的性能成为了当前研究的重点。
1 相关工作
由于远程监督构建数据集的特殊性,导致获得的数据集中存在大量的噪声标签,影响了关系抽取的性能。为了处理噪声问题,有学者提出将远程监督关系抽取看作一个多示例学习(Multi Instance Learning, MIL)任务,将包含有同一实体对的所有句子看作一个实体包,基于实体包来进行实体对的关系抽取[2],有效地缓解了错误标注的问题;之后也有学者们提出基于多示例学习的概率图模型[3-4]。Zeng等[5]提出了一种结合多示例学习思想的分段卷积神经 网 络(Piece-wise Convolutional Neural Network,PCNNs),基于At-least-once的思想,认为在实体包内至少存在一个句子,能够正确的表达实体对之间的关系,选择最优句子作为整个实体包的表示。之后,Lin等[6]认为应该将实体包内所有句子的信息都利用起来,组合作为实体包的表示,并提出使用句子级别的注意力机制来分配实体包内不同句子的权重。Ji等[7]提出使用基于TransE思想[8]的句子级别注意力机制,将两个实体的差值融合到注意力计算中,并且还加入了知识库中实体的描述信息。Jat等[9]使用了词级别和句子级别两层注意力,进一步降低了远程监督的噪声影响,取得了较好的效果。Yuan等[10]采用非独立非同分布关联嵌入法来捕获袋内句子的相关性,得到更好的包向量表示。Alt等[11]通过选择性注意机制将标准的Transformer结构扩展到多实例学习,并在远程监督关系抽取任务上进行微调,减少了显式特征提取以及误差累积的风险。Ye等[12]同时考虑了包内和包间的噪声,分别对句子级和包级噪声进行处理。针对远程监督数据存在的错误标注问题,Huang等[13]基于上下文相关的矫正策略将可能错误的噪声标签修正到正确方向。Shang等[14]利用无监督深度聚类为含噪句子生成可靠标签。Wang等[15]提出了一种无标签方法,即利用类型信息和翻译规律对学习过程进行软监督,不需要额外的降噪模型。另外,有学者还提出应该在关系抽取模型之前就过滤数据集中的噪声,Qin等[16]通过生成对抗训练来去除噪声,处理错误标注的句子。Feng等[17]引入强化学习,将过滤噪声句子建模为一个强化学习决策问题,根据删除一个句子后的关系抽取器性能表现作为强化学习的奖励或者处罚。
当前远程监督关系抽取经过不同研究者的不断努力创新,已经取得了较好的性能表现,但是仍存在三个问题影响了关系抽取的性能提升。(1)远程监督构建的句子中存在大量和关系表示无关的噪声词,根据Liu等[18]的研究:在NYT-Freebase这一远程监督关系抽取经典数据集中,约有99.4%的句子都存在无关的噪声词,平均每条句子中都有着12个无关词。无关的噪声词影响了关系抽取模型提取到的句子特征的质量,而现有的方法直接以关系标签为依据,计算不同词与关系标签的相关度,进而分配不同词的注意力权重,没有考虑到关系标签会存在大量的噪声,向错误关系标签学习,导致了“越学越错”的问题,影响了关系抽取的性能。(2)现有的方法在生成实体包特征时,直接采用含有噪声的关系标签作为计算注意力权重的依据,忽略了关系标签噪声的负面影响,难以获得合理的实体包特征表示。(3)Ye等[19]的研究表明,句子中的命名实体词往往对于句子的语义表示有较高的影响,而现有的基于词向量和位置向量的句子输入表示忽略了文本句子中的命名实体对于句子表示的重要性,另外头、尾的实体词作为句子中最核心的词,也应受到更多的关注度。
针对以上问题,我们提出了一种新的融合多头自注意力和实体特征的分段卷积神经网络模型(Entity-wised Multi-head Self Attention based PCNNs,简称为EMSA_PCNN),与JAT等人在词级和句子级注意力都依据关系标签分配注意力不同的是,我们在PCNNs提取句子特征的基础上,使用多头自注意力来更加合理地分配不同词的贡献度,不需要额外的监督信息,缓解了远程监督的无关噪声词影响句子表示的问题。除此之外,我们在生成实体包时,基于TransE算法的思想:e1-e2≈r,认为实体之间的关系可以由头、尾实体进行一定的计算变换得到,采用头、尾实体经过双线性变换后的向量表示作为句子权重的计算依据,通过缩放点积注意力处理,完全不依赖关系标签,进一步缓解了远程监督关系抽取的噪声在生成实体包特征时的负面影响。另外,在输入部分,额外加入了命名实体和核心的头、尾实体词特征,进一步丰富了句子的输入特征表示,有利于关系抽取模型学习到更多有效的语义特征。我们在NYT-Freebase数据集上的实验结果表明:相较于基线系统,我们提出的方法性能有了显著提升,验证了提出的方法的有效性。
2 模型架构
如EMSA_PCNN模型架构图如图1所示,对于实体包B中的所有句子,EMSA_PCNN模型首先将文本句子转换为向量表示(2.1节融合实体特征的输入层),然后采用卷积层提取文本特征(2.2节卷积层),再通过多头自注意力机制来合理分配不同词的权重(2.3节多头自注意力层),然后对文本表示进行分段的最大池化处理获得最终句子表示(2.4节分段最大池化层),再通过基于头、尾实体双线性变换的注意力计算合理分配不同句子的权重,综合所有句子特征以获得最终实体包B的表示(2.5节融合实体特征的句子特征选择层),最后通过经过Softmax激活的全连接层处理,获得实体包B对于所有关系类别的得分。
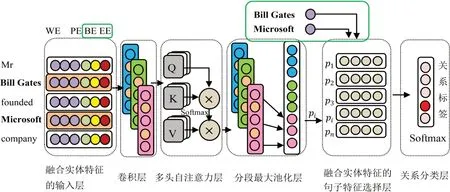
图1 EMSA_PCNN模型架构图
相较于现有的基于PCNNs的模型,我们提出的方法在卷积层之后使用多头自注意力机制来分配句子中不同词的权重,并且在生成实体包时,完全不使用含有噪声关系标签的特征信息,使得模型能进一步避免远程监督噪声的影响。
2.1 融合实体特征的输入层
2.1.1 词向量
词向量是对词的分布式表示,目的是将文本中的每一个词都转换成低维的数字向量。具体来说,对于包含n个词的输入句子s,可表示为s={w1,w2,w3, …,wn},首先将其中每个词wi{i=1, 2, 3,…,n}都通过词典映射为数字索引号,其次通过映射矩阵WE∈ℝ|V|×dw将每个索引号都转换成向量形式vi(i=1, 2, 3,…,n),词向量的维度为dw,|V|是词典大小。
2.1.2 位置向量
句子中离实体词越近的词对于句子表示的贡献越大,通过每个词与两个实体词的相对距离大小可以获得位置向量,弥补了CNN对于位置信息编码能力较弱的缺点。具体来说,句子中第i个词与两个实体的相对位置大小分别用P1i(i=1, 2, 3,…,n)和P2i(i=1, 2, 3,…,n)表 示,再通过两个向量矩阵PE1和PE2,将数值映射为低维向量p1i(i=1, 2, 3,…,n)和p2i(i=1, 2, 3,…,n),位置向量的映射维度为dp。相对位置如图2所示:“technology”这个词到头实体词“Bill Gates”和尾实体词“Microsoft”的相对距离分别是“4”和“-6”。

图2 相对距离示例
2.1.3 命名实体向量
文本中存在不同类型命名实体词,将命名实体的开头词标记为“命名实体类型-B”,命名实体的后续词标记为“命名实体类型-I”,不是命名实体的词的标记为“O”。如图3所示的一个句子:“On July 28, Bill Gates sold 2 million Microsoft shares”,其中的“July”和“28”分别被标记为DATE-B和DATE-I类型,“Bill”和“Gates”分别被标记为PER-B和PER-I类型,“Microsoft”被标记为ORG-B类型。给定输入句子s={w1,w2,w3, …,wn},将其命名实体标签(BIO类型)NE={ne1,ne2,ne3, …,nen}转换成向量表示BE={bio1,bio2,bio3, …,bion},命名实体向量的维度为dbio。

图3 命名实体类型示例
2.1.4 头、尾实体向量
头、尾实体词是文本中最核心的两个词,在输入阶段强化两者的影响,将头、尾实体词向量的差值作为其特殊特征,即ee=ve1-ve2。
对于输入句子s={w1,w2,w3, …,wn},通过上述的词向量、位置向量、命名实体向量和头、尾实体向量,将s转换为一个二维矩阵向量X={x1,x2,x3, …,xn},X∈ℝn×dx,其中xi={vi;p1i;p2i;bioi;ee},n是输入文本句子长度,dx是模型的输入向量维度,表示为dx=2×dw+2×dp+dbio。X将作为后续卷积层的输入。
2.2 卷积层
卷积神经网络(Convolutional Neural Network,CNN)是NLP领域提取文本特征的常用模型之一,能够获取文本中不同的n-gram特征,并且计算时可以并行处理。
给定输入句子矩阵X={x1,x2,x3, …,xn},其中xi∈ℝdx,xi:j表示xi到xj的拼接矩阵,权重矩阵W∈ℝw×dx卷积操作的卷积核,首先通过大小c为w滑动窗口与X进行卷积运算,超出句子最大长度的部分用0填充。通过卷积处理后,可以得到文本特征c={c1,c2,c3, …,cn-w+1},cj的计算如公式(1)所示:
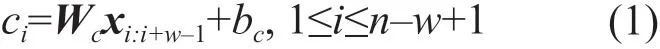
采用Swish函数作为激活函数,其计算如公式(2)、公式(3)所示,其中β为可学习的超参数。
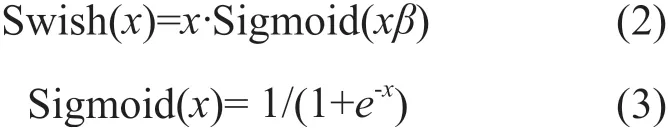
使用多个卷积核进行卷积运算以获得文本的多粒度特征信息,卷积核集合为Wc={wc1,wc2,…,wnk},进行k次卷积处理。获得文本特征表
2.3 多头自注意力层
远程监督构建的训练句子中往往存在大量和关系表示无关的噪声词,现有的方法在处理这些噪声词时,往往直接采用远程监督的关系标签作为计算注意力的依据,重新分配词的注意力权重,没有考虑到远程监督关系标签的噪声问题对于词权重分配的影响。于是,我们选择使用多头自注意力机制来处理这一问题,不需要关系标签作为注意力分配依据,通过计算词与词之间的相关性,动态地分配不同词的权重,过滤无关词的负面影响。
多头自注意力(Multi-head Self Attention,MSA)机制来源于Google所提出的Transformer模型[20],在机器翻译任务中被广泛使用,性能表现十分突出。MSA是一种特殊的内部注意力计算方法,对一个序列本身计算并且重新分配各个位置合适的注意力权重,以获得更合理的特征表示。MSA的计算过程主要包括自注意力计算和多头拼接两个部分组成。
2.3.1 自注意力计算
自注意力是指将句子中每个词都与其他词计算注意力权重,单次自注意力计算过程为:将卷积层获得的特征C通过三个不同的线性变换处理,分别得到Q、K和V三个矩阵,再通过缩放点积注意力计算,得到单次自注意力后的句子表示,缩放点积注意力计算过程表示为公式(4),其中dk表示矩阵K的维度。
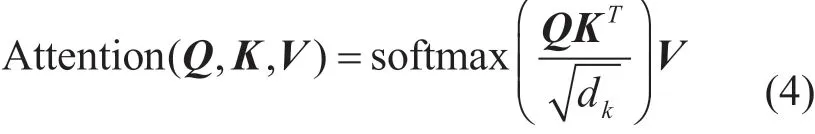
2.3.2 多头拼接
多头拼接部分指进行多次自注意力计算,将多次计算结果进行拼接,得到最终的句子表示,以综合在多个向量子空间内的权重表示。
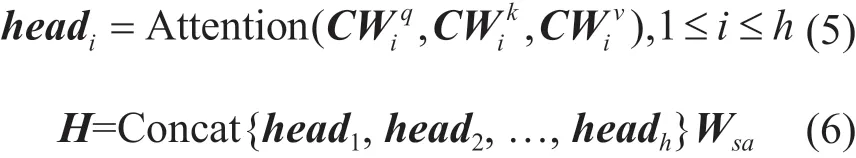
2.4 分段最大池化层
在NLP领域,往往使用最大池化来提取句子表示中最显著的特征,并且降低参数量,但是在关系抽取领域,最大池化选择粒度过大,难以获取到实体对周围的重要信息。由Zeng等[5]提出了分段最大池化,根据句子中两个实体的位置将句子分为三个部分,对三个部分分别进行最大池化,对于多头自注意力层得到的特征表示H={h1,h2,h3, …,hk},每个hi会被分为{hi1,hi2,hi3},则分段最大池化定义为:
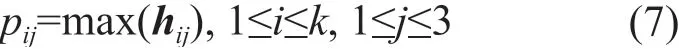
将所有的pi={pi1,pi2,pi3}进行拼接,再采用Swish函数激活,可得到句子的最终表示P∈ℝ3k。
2.5 融合实体特征的句子特征选择层
现有的研究在选择句子特征进而生成实体包特征时,采用的句子级别注意力机制是以关系标签为分配权重依据的,这种方法已取得了良好的效果,但是关系标签中所存在的噪声问题仍然对实体包级别的特征有负面影响。于是,我们基于TransE算法的思想,认为关系能够通过头、尾实体之间的计算得到,采用头、尾实体的词向量(ve1,ve2)经过双线性变换所学习得到的向量表示r作为注意力计算的依据。
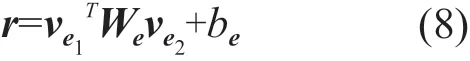
对于实体包B中第j个句子特征Pj的权重aj计算如下所示:
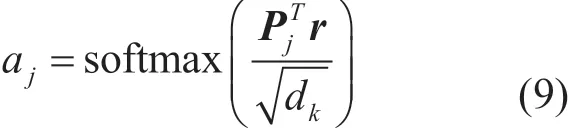
实体包B最终的特征表示为E=ΣiaiPi。
再将实体包B的表示E通过softmax分类器,预测最终的关系标签,使用交叉熵函数计算损失:
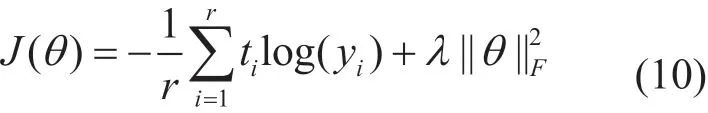
3 实验结果
3.1 实验数据及评测标准
我们采用NYT-Freebase作为实验数据集,该数据集由Riedel等[2]于2010年构建并且开源,是采用远程监督方法将Freebase知识库和纽约时报(New York Times,NYT)语料库对齐得到的,包含NA在内的共53种关系类别,NA即表示实体对间没有关系。将NYT语料中的2005—2006年的文本作为训练集,2007年的文本作为测试集。其中,测试集的实体关系标签是人工标注的,可靠性较高,共172 448条句子,96 678个实体对以及1950个关系事实;训练集则完全由实体关系三元组匹配得到,存在噪声,共522 611条句子,281 270个实体对以及18 252个关系事实。
同现有的研究一样,我们采用held-out evaluation方法来评估我们提出的关系抽取模型。通过模型的PR曲线(Precision Recall Curve)、P@N(Precision@Top N)以及AUC值(Area Under Curve)的表现来评估模型的性能。
3.2 实验设置
我们提出模型使用的词向量是通过Word-2Vec在NYT语料上预训练得到的,而位置向量和命名实体向量则是随机初始化生成的。我们采用网格搜索法来确定模型最优的超参数设置。其中卷积核数目取值k∈{100, 200, 230,256, 300},滑动窗口大小取值w∈{3, 4, 5},批处理大小取值batch∈{64, 128, 160},神经元随机失活率取值dropout∈{0.3, 0.5, 0.7},学习率取值lr∈{0.001, 0.01,0.05, 0.1},多头自注意力的头数取值h∈{1, 3, 5, 7}。最终的超参数设置为:卷积核数目为230,滑动窗口大小为3,批处理为160,神经元随机失活率为0.5,学习率为0.01,多头自注意力头数为5,采用的优化算法为Adadelta。
3.3 实验结果及对比分析
我们将提出的EMSA_PCNN模型与现有的多个模型进行对比:
(1)Mintz[1]:由Mintz首次提出远程监督的概念,通过多分类logistic回归分类器处理关系抽取。
(2)MultiR[3]:由Hoffman提出的采用多示例学习的概率图模型。
(3)MIML[4]:由Surdeanu提出的处理多示例多标签问题的概率图模型。
(4)PCNNs+MIL[5]:由Zeng提出的结合多示例学习和PCNN模型,选择实体包内最优句子来代表整个实体包。
(5)PCNNs+ATT[6]:基于PCNN模型,由Lin提出的采用句子级别注意力机制的方法,根据关系标签分配实体包内不同句子的权重。
(6)APCNNS[7]:基于PCNN模型,由Ji提出的使用两实体之差辅助的信息计算句子级别注意力机制的方法。
(7)BGWA[9]:由Jat提出,采用BiGRU提取特征,基于关系标签分别使用词级别和句子级别两种注意力的方法。
根据图4和表1可以看出:

表1 不同模型的P@N、AUC值对比(%)
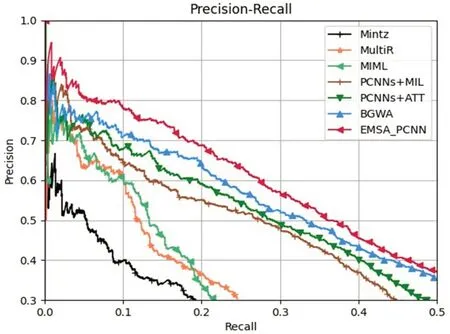
图4 EMSA_PCNN与基准模型的PR曲线图
(1)相较于基于机器学习的传统方法Mintz、MIML、MultiR,其他的基于深度学习的方法效果明显更好,在PR曲线、P@N和AUC值等表现都更好,这说明传统的人工设计的特征在性能上难以与深度学习自动提取到的特征相比较。
(2)EMSA_PCNN在PR曲线和各项指标上都优于PCNNs+MIL、PCNNs+ATT以及APCNNS模型,AUC值比APCNNS模型提升了2.5个百分点,P@Mean值提升了6.2个百分点。这是由于EMSA_PCNN不光在句子级别进行了降噪处理,还降低了词级别的无关噪声,进一步缓解了远程监督的错误标注的问题。
(3)EMSA_PCNN与BGWA相比,PR曲线与各项指标都更优,在AUC值上提升了2.2个百分点,在P@Mean值上提升了5.9个百分点。这是因为EMSA_PCNN在词级别降噪时,使用了多头自注意力来分配权重,避免了噪声关系标签的负面影响,另外在句子级别降噪时,EMSA_PCNN使用了头、尾两实体经过双线性变换的向量表示作为计算注意力的依据,进一步降低了远程监督错误标注的影响。
此外,本文还与2019年最先进的两种关系抽取模型进行了性能对比,这两种方法使用的是Liu等[18]提供的数据集,本文称为NYT-SoftRE,与先前介绍的NYT-Freebase不同的是NYT-SoftRE是在NYT-Freebase基础上增加了约5万条训练句子,而测试句子保持不变。选取的关系抽取模型有:(1)PCNN+BAG-ATT:Ye等[12]在句子级别注意力的基础上,进一步增加实体包级别的注意力机制,降低了实体包级别的噪声;(2)PCNN+WN:Yuan等[10]提出在向量表示阶段加入注意力计算,在句子选择部分认为实体包内的句子不是独立同分布的,将最优句和其他句子计算相似度得到注意力权重的方法。为了更加直观的看出不同方法在NYT-SoftRE上的性能对比,除了这两种方法之外还加入了PCNNs+ATT作为对比模型,本文方法和上述几种方法的AUC值对比如表2所示:
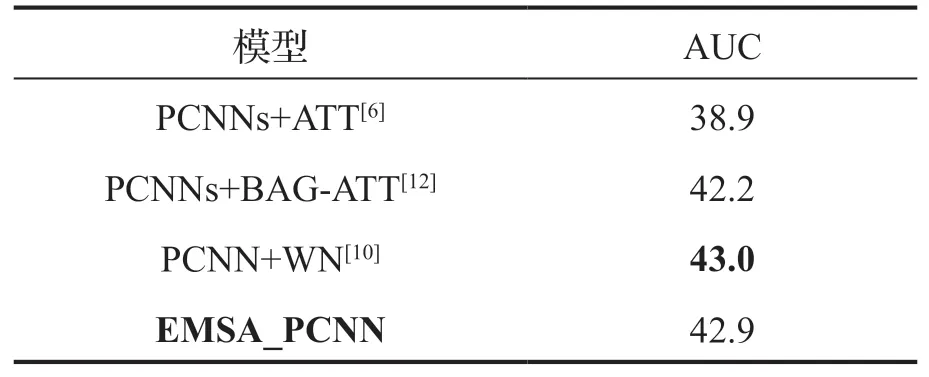
表2 基于NYT-SoftRE数据集的模型的AUC值对比(%)
根据表2可知,在NYT-SoftRE数据集上,相较于PCNNs+ATT模型,本文提出的 EMSA_PCNN模型在AUC值表现上提升了4个百分点,验证了本文方法的有效性。相较于加入实体包级别注意力的PCNN+BAG-ATT模型,EMSA_PCNN 在性能上有0.7个百分点的提升。而相较于PCNN+WN模型,本文提出的EMSA_PCNN模型的AUC值表现仅低0.1个百分点,说明我们提出的方法也具有较好的竞争力。在以后的研究工作中,我们可以进一步探索实体包中不同句子之间的联系,而不是将所有的句子看作独立的个体,从而提升关系抽取的性能。
4 消融实验
4.1 融合多头自注意力的性能评测
为了验证多头自注意力机制对于远程监督降噪的有效性,我们设计了采用PCNN为句子编码器,使用一般的句子级别注意力,多种方式计算词的注意力,进行对比实验。(1)PCNNs+ATT:未采用任何词级别降噪的方法。(2)WA+PCNN+ATT:直接采用关系标签作为监督信息计算词级别注意力的方法。(3)MSA_PCNN:不采用任何监督信息,使用多头自注意力计算词级别注意力的方法。
从图5和表3可以看出,加入普通词级别注意力的WA+PCNN+ATT模型在性能上有一部分提升,说明无关噪声词的确影响了关系抽取的性能。另外,MSA_PCNN模型的表现更好,在PR曲线、P@N以及AUC值上都较于WA+PCNN+ATT有显著提升,这是因为MSA_PCNN采用的多头自注意力避免了噪声关系标签的影响,另外“多头”机制能够综合多个向量子空间的权重信息,进一步降低了词级别的噪声,验证了多头自注意力的有效性。
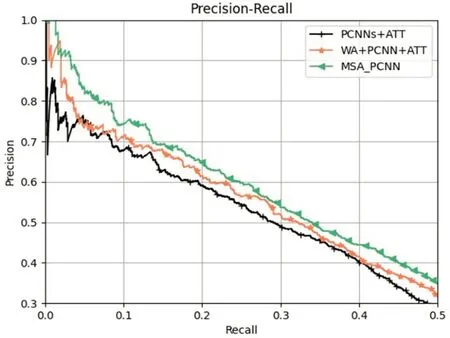
图5 不同词级别注意力机制的性能对比

表3 不同词级别注意力机制的P@N,AUC值对比(%)
4.2 融合实体特征的性能评测
为了验证融合实体特征的有效性,我们设计了同样采用PCNN为句子编码器,不同方法计算句子级别注意力的方法。(1)PCNNs+ATT:以关系标签为依据,计算句子级别注意力的方法;(2)APCNNS:以两实体之差作为辅助关系标签的信息,计算句子级别注意力的方法;(3)PCNNs+EATT:我们提出的使用头、尾实体经过双线性变换的向量表示作为依据,采用缩放点积注意力分配句子权重的方法。
根据图6和表4可知,采用头、尾实体经过双线性变换的PCNNs+EATT模型相较于PCNNs+ATT和APCNNS模型来说,在PR曲线、P@N和AUC值上表现都有较好提升,验证了融合实体特征在句子级别注意力计算的有效性。
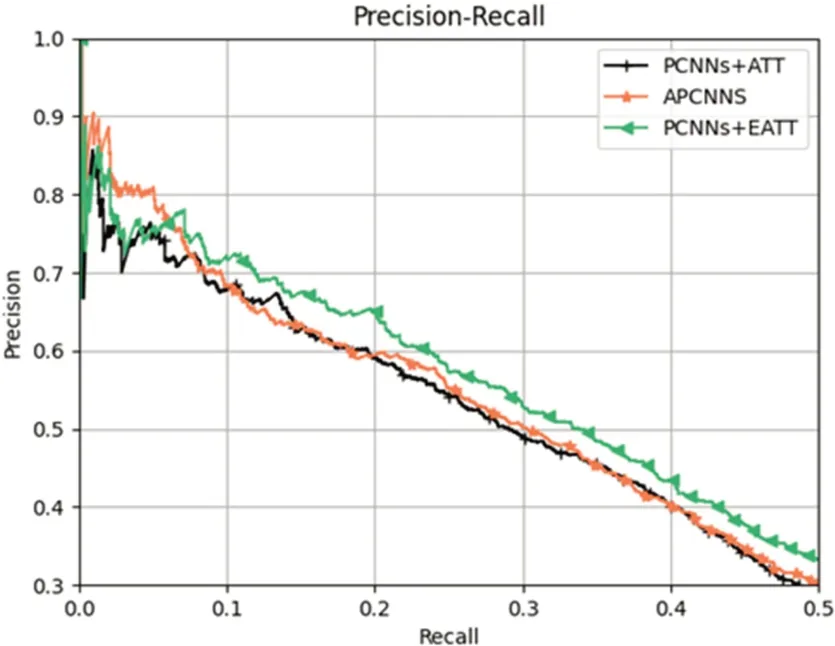
图6 不同句子级别注意力机制的性能对比

表4 不同句子级别注意力机制的P@N,AUC值对比(%)
另外,为了验证在输入部分融合实体特征信息的有效性,我们同样也以PCNN为编码器,在句子选择时采用多示例学习(MIL)和普通句子级别注意力(ATT),根据输入部分是否加入实体特征(E),分别记为:(1)E+PCNNs+MIL和PCNNs+MIL,(2)E+PCNNs+ATT和PCNNs+ATT。
根据图7可以看出,加入命名实体特征和实体词特征的模型在PR曲线表现中都优于未加入的模型,验证了在输入层加入额外特殊词特征的有效性。
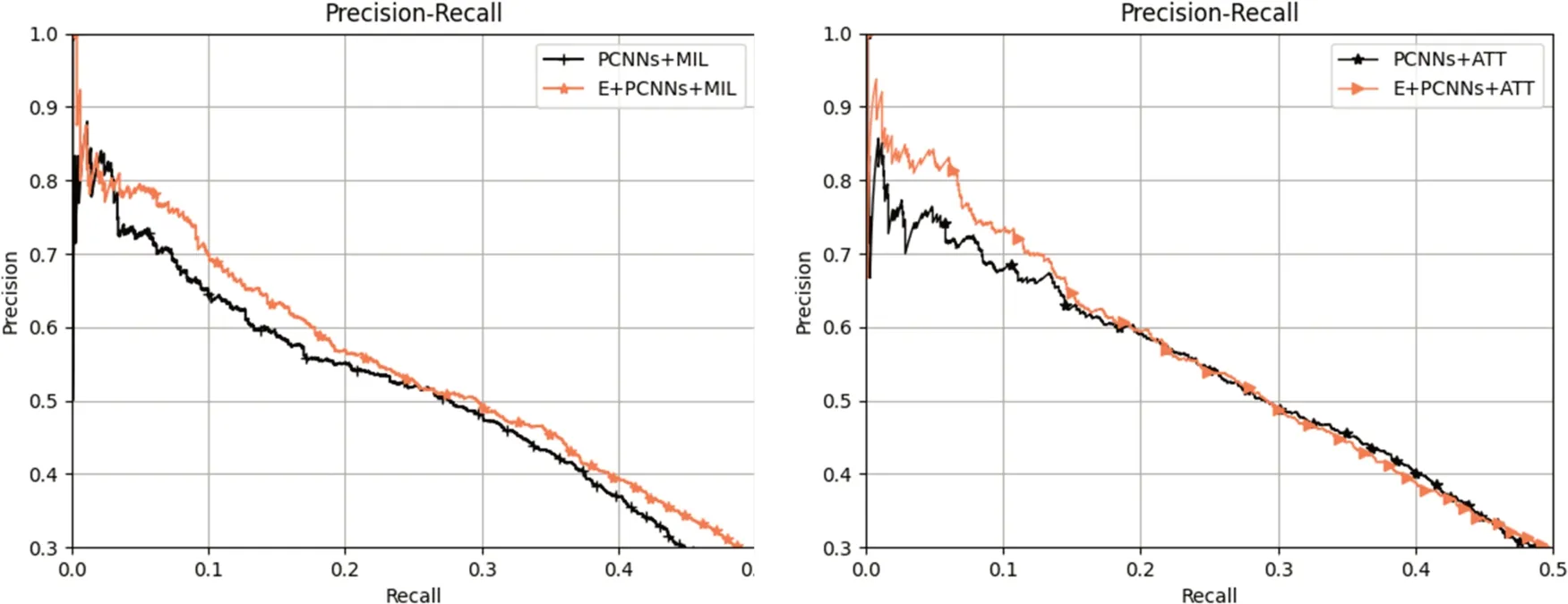
图7 输入层融合特殊词特征的性能对比
5 实例分析
为了更直观地解释多头自注意力机制能够缓解词级别噪声的原因,我们从测试集中选取了一个实例,分别对5个头的注意力权重进行了可视化的展示,如图8所示。由于关系抽取任务旨在抽取两个实体间的语义关系,因此我们仅关注实体对(Boston,Back Bay)与句内其他词之间相关性,其中颜色越深表示所分配的权重越大,即相关性越高。
通过权重分布可以看出,多头自注意力机制可以从5个不同的表示子空间学习相关信息,为“more”“inviting”“first”等无关词分配低权重,同时也为“in”“church”等相关单词分配了高权重,为预测“Boston”与“Back Bay”之间的/contains/关系提供了有效信息。由此可见,多头自注意力机制可以降低无关词的噪声信息的影响,从词级别缓解噪声传播,从而提升关系抽取性能。
6 结语
针对当前词级别、句子级别降噪的注意力计算时都依据含有噪声的关系标签的问题,本文提出了一种融合多头自注意力和实体特征的分段卷积神经网络方法,并将其应用到远程监督关系抽取任务中。在词级别降噪时,采用多头自注意力来更加合理地分配每个词的贡献度,降低句子中无关的噪声词对于句子表示的负面影响;在句子级别降噪时,采用头、尾实体经过双线性变换的隐层向量作为注意力计算的依据,两者注意力计算时都没有以关系标签作为依据,降低了关系标签中噪声对于注意力权重分配的不利影响,进一步缓解了远程监督的错误标注的问题。实验结果表明:我们提出的模型优于所有的基线模型,达到了最好的效果。在以后的研究中,我们将进一步融合知识库的其他有用信息,以及预训练语言模型的知识来探索进一步提升关系抽取性能的方法。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
基层中医药(2021年8期)2021-11-02 06:25:02
中国外汇(2019年18期)2019-11-25 01:41:54
家庭影院技术(2018年5期)2018-06-29 07:42:10
家庭影院技术(2018年3期)2018-05-09 07:06:12
哲学评论(2017年1期)2017-07-31 18:04:00
中学生(2017年13期)2017-06-15 12:57:48
传媒评论(2017年3期)2017-06-13 09:18:10
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
