
基于改进SSD算法对奶牛的个体识别
2022-01-25 18:55:02邢永鑫孙游东王天一
计算机工程与应用 2022年2期
邢永鑫,孙游东,王天一
贵州大学 大数据与信息工程学院,贵阳 550025
信息技术与智能技术的快速进步正推动现代畜牧业朝着绿色、高效、智能的方向发展[1-2]。奶牛养殖作为畜牧业的重要组成部分,智能化、自动化养殖也成为必然的趋势[3-5]。在养殖场中,为精准、快速地记录每头奶牛的产奶量、挤奶时间、挤奶次数、产奶品质等数据,需要对每头奶牛进行精准快速的识别。为完成这一任务,需要借助基于深度学习的目标检测算法。卷积神经网络[6]作为深度学习的一种学习算法,利用逐层深入的空间关系来减少需要学习的参数数目以提高一般神经网络算法的训练性能,具有很强的判别能力与学习能力[7]。将图像输入网络后,每层卷积层均通过不同权值学习输入数据的不同特征,得到的特征信息在不同的卷积层中依次进行传递。
近年来,以AlexNet[8]、VGGNet[9]等算法为代表的深度学习算法在图像识别等复杂任务上表现优异,迅速吸引了学术界和工业界的聚焦。在目标检测领域,基于深度学习的经典算法包括R-CNN[10]以及在其基础上改进的Faster R-CNN[11]等,这些算法虽然具有较高的检测精度,其双阶段检测的特性却导致检测的速度较慢。2016年,Redmon等在CVPR会议上提出统一实时目标检测算法[12](you only look once,YOLO),该算法利用回归得到边界框和类别概率,以检测精度为代价换来了检测速度的明显提升。同年,Liu等在ECCV会议上提出了多尺度单发射击检测算法[13](single shot multibox detector,SSD),在不同尺度感受野的特征图上提取特征,再利用回归得到目标物体的位置和分类结果,在保证实时性的同时,提高了检测精度。然而,SSD算法的缺点在于不能充分利用浅层的高分辨率特征图。此外,候选框的尺寸比例也需要人工根据经验设置。
本文以SSD算法为基础,针对前文提到的两个缺点,对SSD算法进行改进,提出了基于浅层特征模块的改进SSD(shallow feature module SSD,SFM-SSD)算法。
SFM-SSD在原始SSD算法的基础上,将主干卷积神经网络由VGG16换为MobileNetV2,利用MobileNetV2网络结构中的深度可分离卷积[14]来降低网络的运算量;再利用浅层特征模块(shallow feature module,SFM)[15-16],提高浅层特征图的特征提取能力,扩大浅层特征图的感受野[17];最后,利用K均值聚类算法对网络的区域候选框重新设置[18-19];降低真实框匹配的难度,提升算法在奶牛识别任务上的精度。实验结果表明,在FriesianCattle2017数据集上,SFM-SSD算法和SSD算法相比,性能有了明显改善。
1 基于卷积神经网络的目标检测原理
1.1 卷积神经网络
卷积神经网络是一种包含卷积计算的前馈神经网络,由不同的卷积层连接组成,卷积层的计算过程如图1所示。
如图1所示,为卷积层的计算过程。在图1中,(6×6×3)为输入的特征图。其中(6×6)为特征图的尺寸,3为特征图的通道数。(3×3×3)为权值矩阵(卷积核),其中(3×3)为权值的大小,3为输入特征图的通道数。权值矩阵在图像里就像一个特定信息的过滤器,一个权值矩阵用来提取边缘信息,另一个可能用来提取特定的颜色。如图1中,有两个权值矩阵,对应输出特征图通道数为2。权值与输入特征图进行卷积运算时,以滑动窗口的形式,从左至右,从上至下,3个通道和对应位置相乘求和。然后加上偏置(图1中b1、b2),经过Relu激活函数,得到输出特征图(4×4×2),其中(4×4)为输出特征图大小,2为输出特征图的通道数,输出特征图的通道数和权值矩阵的数量相同。

图1 卷积层的计算过程Fig.1 Calculation process of convolution layer
如图2所示,图片经过不同的权值矩阵,会产生不同通道的特征图,不同权值矩阵提取图片中不同方面的特征信息,有的权值矩阵提取奶牛背上花纹特征,有的权值矩阵则提取奶牛的轮廓特征,因此不同的权值形成了不同通道的特征图。将所有通道的特征融合后形成图片经过卷积的仿真图。

图2 图片经过卷积后的仿真结果Fig.2 Simulation results of convolution
1.2 SSD算法
SSD算法的网络结构如图3所示。SSD算法的主干网络为VGG16,并将VGG16网络的FC6、FC7层改为Conv6、Conv7层,然后在后面加了4个卷积层,构成SSD算法框架。网络以300×300图片作为输入,整个网络结构有6个特征图,分别预测不同尺寸的物体,浅层特征图分辨率高、感受野小用来预测小物体目标,深层特征图则用来预测较大的物体目标。最后经过非极大值抑制过滤掉多余边界框并产生最终检测结果。
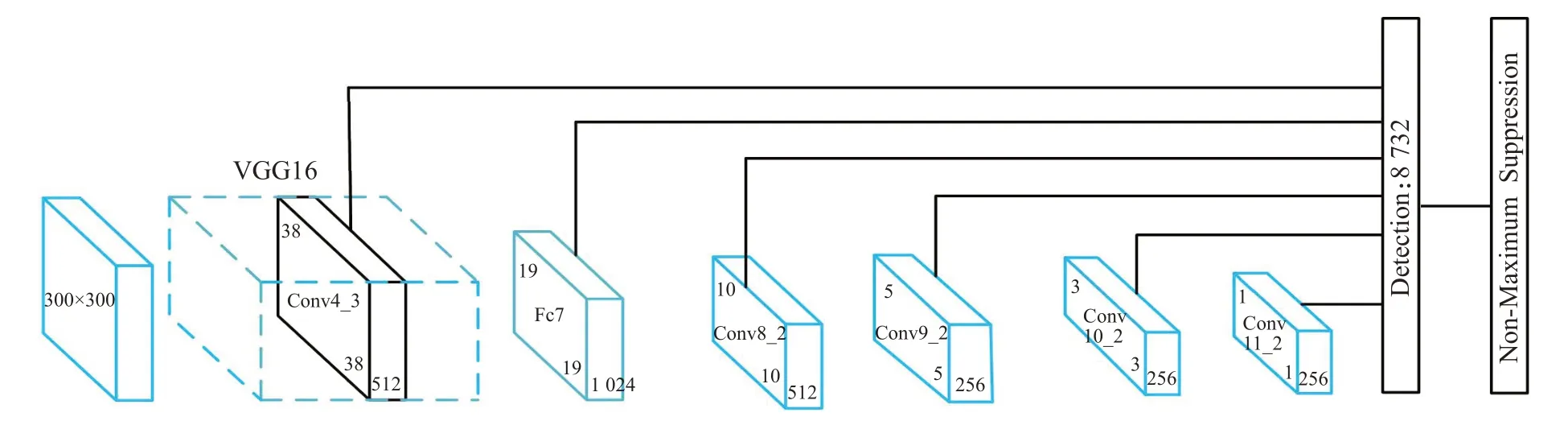
图3 SSD算法网络结构Fig.3 SSD algorithm network structure
2 SFM-SSD算法
SFM-SSD算法的网络结构如图4所示。算法的主干卷积神经网络由VGG16换为MobileNetV2,在不同尺度的特征图上提取特征,并在Conv4_3和Fc7层上增加了浅层特征模块(shallow feature module,SFM),然后对区域候选框重构,使区域候选框的数量由8 732增加到11 640。最后经过非极大值抑制预测目标物体。

图4 SFM-SSD网络结构Fig.4 SFM-SSD network structure
2.1 MobileNetV2
在提高网络检测精度的同时为了提高网络的检测速度,将SSD网络的主干网络由VGG16换为Mobile-NetV2。MobileNetV2是对MobileNetV1的改进,同样是一种轻量级的神经网络,除了继承MobileNetV1的深度可分离卷积之外,另外借ResNet网络中采用了残差网络取得很好的效果,提出了反残差网络的概念。
深度可分离卷积将传统的卷积分解为一个深度卷积和一个1×1的点卷积。假定输出特征图的通道数为N,卷积核的大小为DK×DK,则深度可分离卷积的计算量仅为传统卷积的,因而能够明显提升运算速度,改善检测的实时性。如图5所示反残差网络是采用扩张通道-特征提取-压缩通道的信息处理方式,先通过一个1×1卷积对通道数进行扩展,对扩展之后的通道执行深度卷积以提取特征,最后通过一个1×1卷积使输出通道数和输入相同。为了兼顾算法的实时性,本文网络中部分高维通道扩展倍数设置为4。

图5 残差网络和反残差网络结构对比Fig.5 Structure comparison between residual network and anti residual network
2.2 浅层特征模块
浅层特征模块的结构如图6所示。为了充分利用SSD浅层特征图的细节表达能力,受到多分支卷积Inception和残差网络ResNet的启发,设计了SFM。SFM使用多通道的卷积核,在模块中1×1卷积主要是为了降低通道数,从而降低网络的计算量。使用3×1,1×3的卷积可以使网络学习到更多的非线性关系。空洞卷积不仅使网络学习到更多的特征信息,增大感受野,而且不同空洞率的卷积可以起到下采样的效果,增加特征多样性,能让浅层特征图进一步提取丰富的特征。然后通过通道拼接特征融合,最后与残差分支的1×1直连卷积连接,经过激活函数。将SFM模块添加到网络的Conv4_3层和Fc7层不仅可以提高检测精度,而且可以增强对小物体目标的检测能力,如图7。
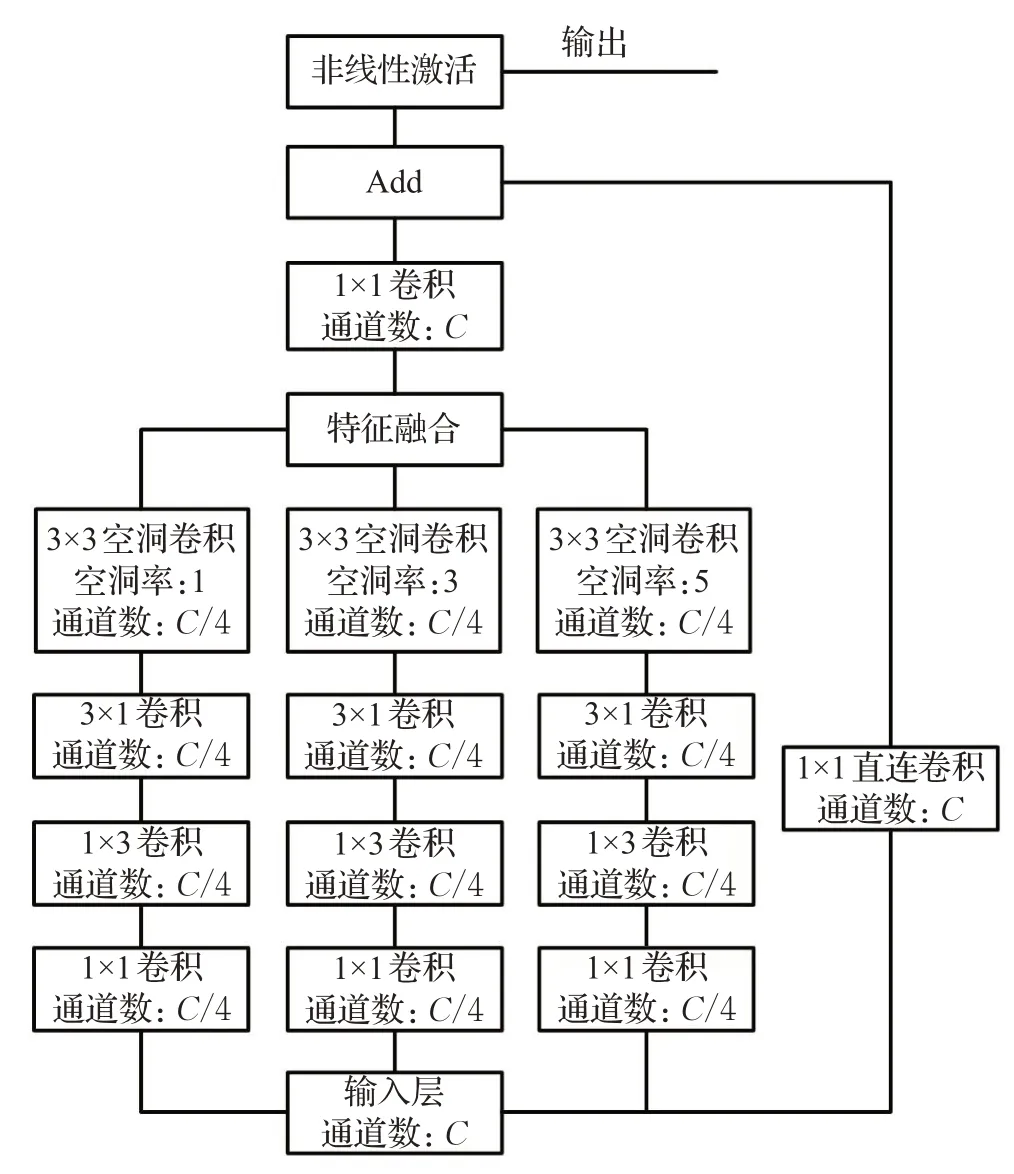
图6 SFM模块Fig.6 SFM module

图7 浅层特征图Fig.7 Shallow feature map
2.3 区域候选框重构
深度学习目标检测算法的性能很大程度上取决于特征学习的好坏,而特征学习是由训练数据驱动的,在SSD目标检测任务中训练数据就是区域候选框。当区域候选框与真实框的交并比(IOU)大于阈值时,被标为正样本,反之,被标为负样本。
区域候选框参数公式如下:
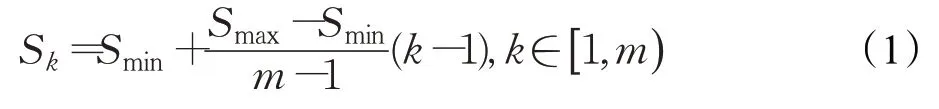
Sk是第k个特征图的min_size参数;max_size的值为Sk+1;Smin是设计好的最小归一化尺寸,取值为0.2;Smax为设计好的最大归一化尺寸,取值为0.9;m是特征图的数量(SSD算法中m=6)。
如图8所示,产生4个候选框,两个正方形(红色虚线),两个长方形(蓝色虚线)。300×min_size为小正方形的边长,为大正方形的边长,aspect_ration(纵横比)是一个设置的参数。aspect_ration={1,2},对应的两个长方形的长宽:
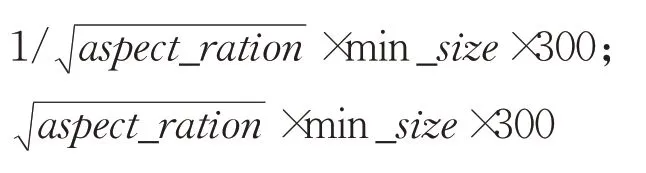

图8 候选框示意图Fig.8 Schematic diagram of candidate box

当要产生6个候选框时,aspect_ration的值设置为{1,2,3},300为SSD算法中输入图片的尺寸。
在以往的检测中,大多都是按照经验来设定候选框的大小和比例,在训练过程中网络会调整候选框,如果能在训练前预先找到候选框合适的尺寸和比例,将能得到更好的预测结果。本文使用k-means聚类算法来预测候选框的大小和比例。
本文使用的距离度量公式为:
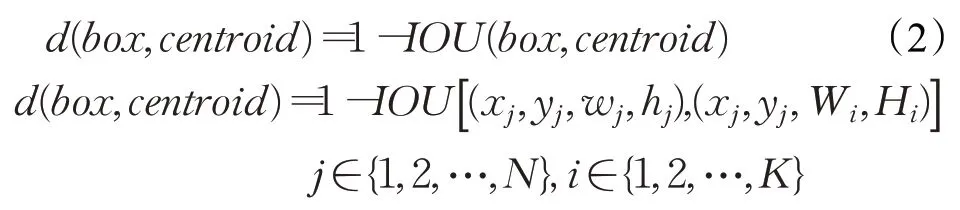
其中,centroid为聚类中心,box为标注框。在计算时,每个标注框的中心点与聚类中心的中心点重合才能计算IOU的值。(xj,yj)是标注框的中心点,(wj,hj)是标注框的宽高,(Wi,Hi)是聚类中心的宽高;N为标注框的个数,K为聚类个数,通过以上公式将标注框分配给距离最近的聚类中心。所有标注框分配完以后,对每个集合重新计算聚类中心点,公式:
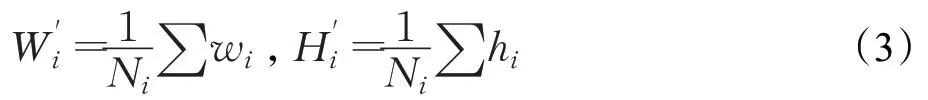
求集合中所有标注框平均宽和高,然后重复以上步骤,直到聚类中心改变很小。
实验中设置K={1,2,3,4,5,6,7,8,9,10}进行实验,分别对标注框进行聚类。由图9可知,当K<6时,平均交并比涨幅很大,当K>6时基本趋于平缓,再结合算法综合考虑,选择K=6。当K=6时得到候选框的纵横比为[0.59,0.89,1.18,1.84,1.9,2.84],通过以上实验数据结合图10实验结果对候选框重构。
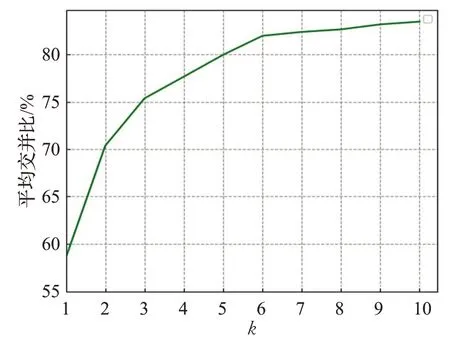
图9 标注框聚类Fig.9 Label box clustering

图10 K=6聚类效果Fig.10 K=6 clustering effect
SSD算法采用6个特征图生成不同尺寸大小的候选框,如果特征图的大小为M×N,即将对应的特征图划分成M×N个网格,然后以每个网格的中心点为中心,产生H个候选框,则每个特征图产生候选框的数量为M×N×H。在SFM-SSD算法中,6个特征图aspect_ration(纵横比;在表1和表2中简写为ar)设置为{1,2,3},H的个数由{4,6,6,6,4,4}改为{6,6,6,6,6,6}。

表1 SSD算法区域候选框设置Table 1 SSD algorithm area candidate box setting
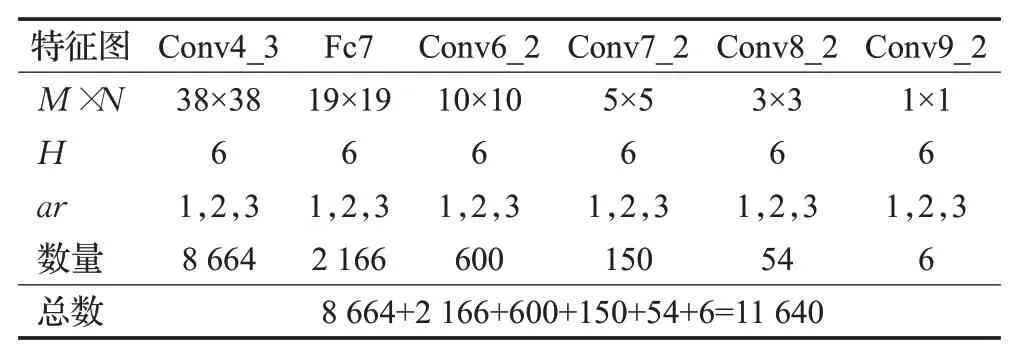
表2 SFM-SSD算法区域候选框设置Table 2 SFM-SSD algorithm area candidate box setting
SSD算法进行目标检测时,最终的检测结果与区域候选框的预测有关,而区域候选的预测框进行回归与其周围一定范围内的样本有很大关系,因此重构区域候选框的同时,也应该选择合适的阈值。为了选择合适的阈值,在不同阈值下进行实验,由实验结果可知,选择最佳阈值为0.45。
2.4 损失函数设计
SFM-SSD算法的损失函数由SSD算法的损失函数结合聚焦分类损失函数[20]优化而来,损失函数由分类损失和位置损失加权求和获得,公式如下:
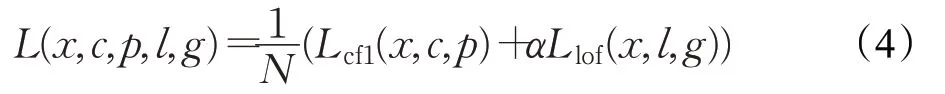
分类损失公式如下:
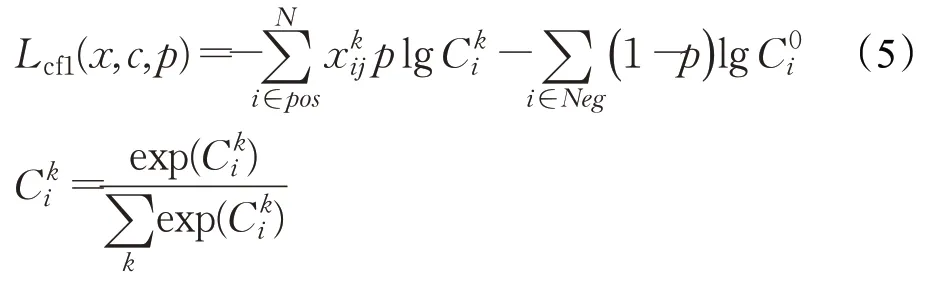
位置损失的公式如下:
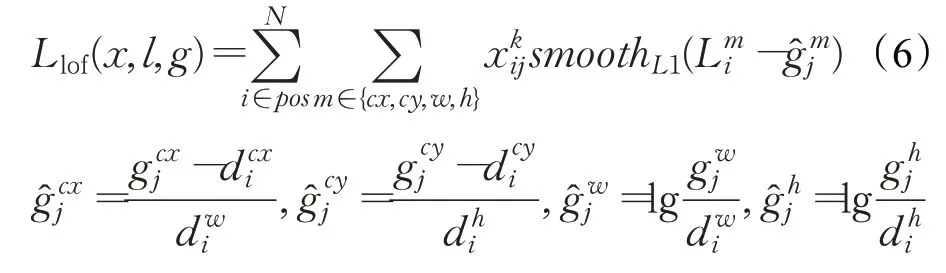
在公式中{cx,cy,w,h}分别是中心点和宽高,pos表示正样本集;分别表示第j个真实框的中心点坐标和宽高。
3 实验结果与分析
3.1 实验数据与环境
实验使用FriesianCattle2017数据集,在训练时对图像进行数据增强,包括随机亮度变化、随机平移、随机旋转、水平翻转和垂直翻转、尺寸变化、随机裁剪等。对不同的模型进行训练,按照6∶2∶2的比例将数据集分为训练集、验证集、测试集。
实验环境:python3.7,tensorflow2.0。用labelimg标注数据集;用keras构建网络结构;图11为数据集图片标注结果;用RTX 2080Ti加速训练。CPU:i7-9700 3.6k@3.60 GHz×8。

图11 标注图片Fig.11 Label picture
3.2 评价指标
实验通过在测试集中分析模型改进前后的平均准确率(average precision,AP)和平均检测时间,对比模型的性能。用AP作为精度检测的指标,平均准确率为精确度关于召回率的函数曲线与坐标轴0到1范围围成的面积。AP值越高,检测性能越好;精确度(Precision)和召回率(Recall)公式定义如下:

其中,TP为正样本中的正例,FP为负样本中的正例,FN为负样本中的负例。
AP的积分公式:

其中,P(r)为精确度关于召回率的函数,r为召回率。
3.3 实验结果
由表3可知,当阈值为0.45时模型的平均准确率最高,因此在SFM-SSD算法中选择阈值为0.45。

表3 不同阈值模型的平均准确率Table 3 Average accuracy of different threshold models
如图12所示,为不同算法的loss曲线。实验中使用Adam优化器,bath_size设置为16,初始化学习率为0.000 4,为了防止过拟合,实验中使用了early_stoping(早停),当连续6个epoch的vall_loss(验证集损失)的值不下降时自动停止训练。
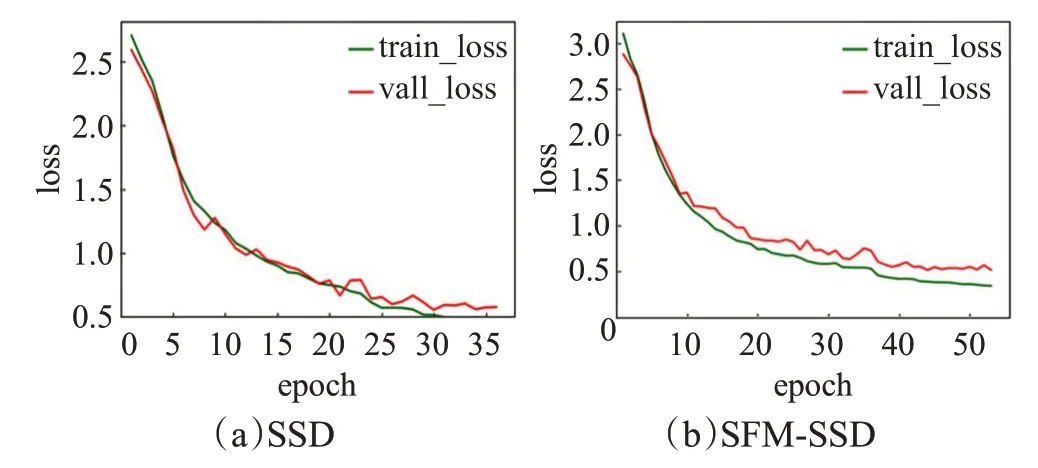
图12 不同模型的loss曲线Fig.12 Loss curves of different models
由表4可知,本文的SFM-SSD算法的AP值为94.91%,和传统的SSD算法相比不仅精确度提高了3.13个百分点,而且检测速度也减少了5.07 ms,和第3个网络模型相比虽然准确度稍微下降,但检测速度有了很大的提升。可见本文提出的SFM-SSD算法对奶牛的识别效果较好,且检测速度有了一定的提升。

表4 不同模型在测试集上的测试结果Table 4 Test results of different models on test set
3.4 不同模型检测结果对比
如图13所示,为SSD算法与SFM-SSD算法的检测结果,由检测结果可知,无论是置信度还是预测位置SFM-SSD算法都优于SSD算法。
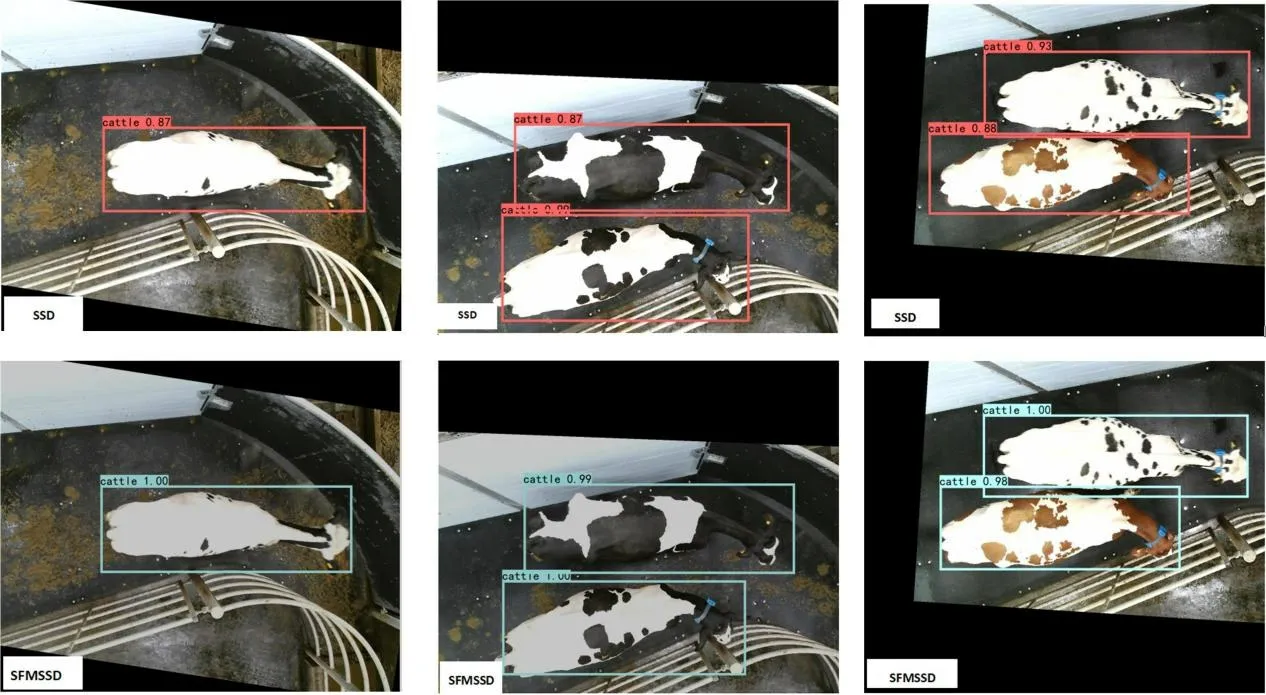
图13 不同模型检测结果对比Fig.13 Comparison of test results of different models
3.5 SFM-SSD算法与YOLO系列算法对比
由表5所示,为SFM-SSD算法与YOLO系列算法的实验结果,由实验结果可知,SFM-SSD算法比YOLOV2,YOLOV3算法的检测精度更高。

表5 SFM-SSD算法与YOLO系列算法在测试集上实验结果Table 5 Experimental results of SEM-SSD algorithm and YOLO series algorithm on test set
3.6 SFM-SSD算法与YOLOV3算法检测效果
如图14所示,为YOLOV3算法与SFM-SSD算法的检测结果,由检测结果可知,对奶牛个体的检测识别,SFM-SSD算法的检测结果优于YOLOV3算法。

图14 SFM-SSD算法与YOLOV3算法检测效果Fig.14 Detection effect of SFM-SSD algorithm and YOLOV3 algorithm
4 结语
本文通过对传统的SSD改进算法,首先,使用了MobileNetV2作为主干网络,提高网络的检测速度。然后,对网络中的候选框从新设置,提高网络的检测精度,设计浅层特征模块,提高网络中浅层特征图的特征提取能力,扩大浅层特征图的感受野,增强对小目标物体的检测能力。实验结果表明,SFM-SSD模型在精度上和速度上都超过了传统SSD模型。为了在不同的环境中对奶牛都可以很好地识别,接下来利用迁移学习方面的知识展开研究。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
计算机工程与应用(2022年1期)2022-01-22 07:46:48
计算机工程与科学(2021年4期)2021-05-11 01:59:36
建材发展导向(2021年24期)2021-02-12 02:00:24
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
环境影响评价(2020年5期)2020-12-02 01:18:56
火力与指挥控制(2018年3期)2018-04-19 11:43:39
自动化学报(2017年7期)2017-04-18 13:41:02
水利规划与设计(2016年10期)2017-01-15 14:01:14
