
基于改进CNN—SVM的甲烷传感器数显识别方法
2022-01-25 02:52:20唐守锋史经灿周楠赵仁慈仝光明黄洁
工矿自动化 2022年1期
唐守锋, 史经灿, 周楠, 赵仁慈, 仝光明, 黄洁
(中国矿业大学 信息与控制工程学院, 江苏 徐州 221116)
0 引言
仪器仪表显示值的识别在机器人自动巡检、自动检定系统示值读取等应用领域必不可少。目前数显仪表的显示方式主要有数码管和液晶2种。常用的甲烷传感器多为非色散红外甲烷传感器,主要采用数码管显示。甲烷传感器自动检定系统采集传感器数值图像时,由于传感器本身材质存在光反射,且显示面板上有附着物,采集到的数值图像质量较差,对字符识别造成困难,降低了识别准确率。
基于机器学习的检测算法是一种常用的仪表字符识别方法,可以很好地解决传统图像处理方法对图像噪声敏感且鲁棒性差的问题。这类算法中,卷积神经网络(Convolutional Neural Network,CNN)和支持向量机(Support Vector Machine,SVM)表现突出并逐渐成为主流。文献[1]将图像预处理方法与模板匹配结合使用进行数值图像识别,实时性好,但识别率较低。文献[2-4]分别使用BP神经网络和CNN对数字仪表进行识别,不仅可以识别仪表字符图像和小数点,还可以识别仪表字轮图像,但识别率较低。文献[5-6]提出了一种基于CRNN的识别方法,结合CNN和深度循环神经网络(Recurrent Neural Networks,RNN)进行声纹个体识别,识别率高,但忽略了网络模型输出数据量大小,算法运行时间较长。文献[7]以SSD(Single Shot MultiBox Detector)为算法框架基础,有效解决了文字识别问题,但算法运行速度较慢。文献[8]采用FasterR-CNN网络对存在拥挤、遮挡等情况的图像进行识别,其优点是鲁棒性强。文献[9]提出的YOLOv3网络具有很好的实时性,但对相似目标的检测效果很差。针对上述问题,本文提出了一种基于改进CNN-SVM的甲烷传感器数显识别方法。首先对传感器数值图像进行增强与分割处理,然后采用传统CNN进行特征提取,结合主成分分析法(Principal Component Analysis,PCA)对提取的图像特征进行降维,最后通过SVM实现数字分类识别。
1 传感器数值图像增强与分割处理
为了更好地提取甲烷传感器数码示值区域数字,首先利用带色彩恢复的多尺度视网膜增强(Multi-Scale Retinex with Color Restoration,MSRCR)算法进行图像增强处理,使得甲烷传感器数码管显示区域明显区别于其他区域;其次,将RGB图像转换至HSV空间,提取出图像中包含红色像素的区域;然后,为了提高特征提取和识别的可靠性,利用区域分割方法将数值区域从整体图像中分割出来;最后,使用高斯滤波算法对图像进行去噪处理,并对处理后的图像进行二值化。图像增强与数值提取过程如图1所示。


图1 图像增强与数值提取过程Fig.1 Image enhancement and numerical extraction process
利用OpenCV中的Rect数据结构将数值图像中的数字分割成单个数字图像,作为自建数据集。正常情况下小数点位于数字右下角,判断对应区域像素值是否为0即可得到小数点位置。数字分割效果如图2所示。



图2 数字分割效果Fig.2 Digital split effect
2 CNN-SVM模型及其改进
2.1 CNN-SVM模型
CNN通过卷积层从原始图像中提取基本数字特征,为减少后续计算量,防止过拟合情况的发生,通过池化层对数值图像的局部代表性特征进行提取,全连接层将前面提取的特征整合到一起后通过Softmax分类器进行分类识别。与Softmax相比,SVM采用最大类间分类平面对样本数据进行分类,具有更高的识别准确率。因此,CNN-SVM模型[10-12]用SVM分类器替代原有的Softmax分类器,其结构如图3所示。

图3 CNN-SVM模型结构Fig.3 CNN-SVM model structure
用SVM分类器替代Softmax分类器的具体操作步骤如下:
(1) 训练原始CNN,使CNN模型具有较高的识别率。
(2) 将模型中的损失函数Cross-entropy Loss更换为Hinge Loss。
(3) 将全连接层之前的学习率系数lr_mult全都设置为0,直到固定特征提取完毕。
(4) 重新训练模型(只需要训练最后的SVM分类器),经过一段时间后,完成CNN-SVM模型训练。
2.2 CNN-SVM模型改进
CNN-SVM模型运行时间依然较长,为了缩短运行时间,提高识别准确率,本文使用PCA算法对全连接层提取的图像特征进行降维处理,用最主要数据特征代替原始数据作为SVM分类器的样本进行分类识别。改进CNN-SVM模型由3个卷积层、3个池化层、1个全连接层、PCA及SVM分类器组成,其流程如图4所示。
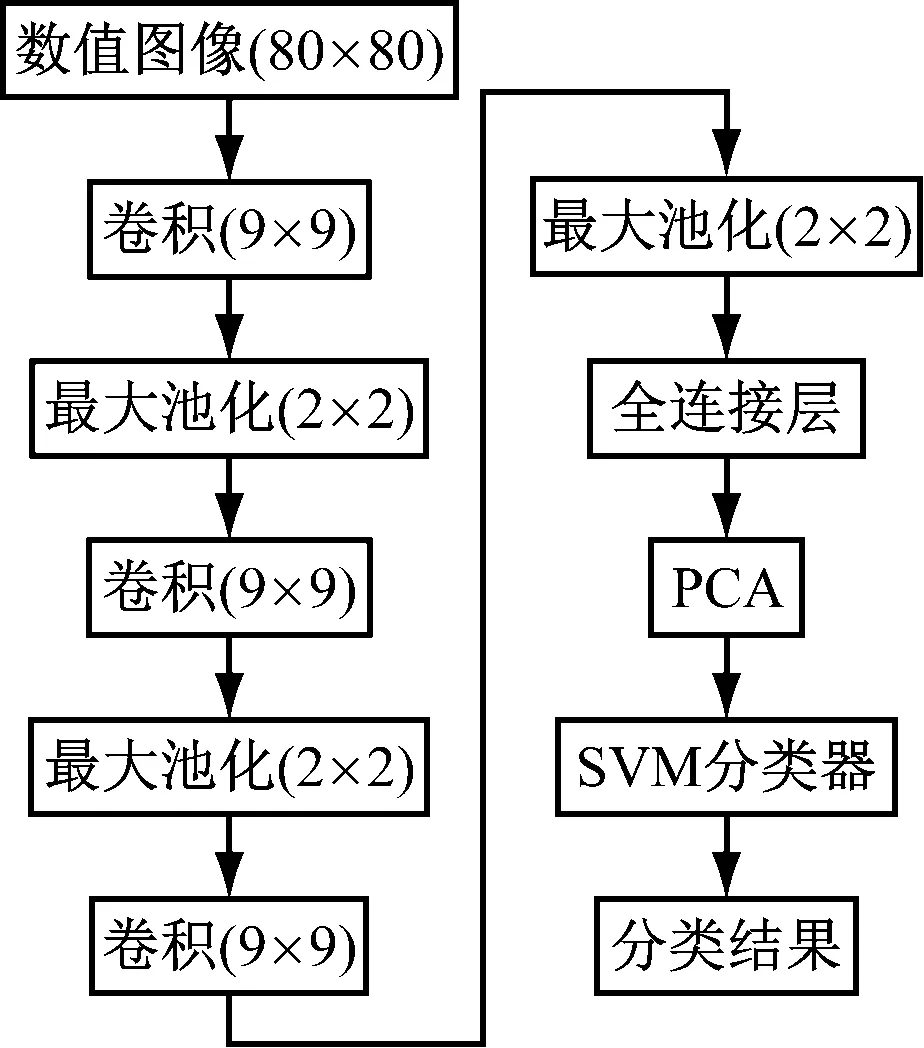
图4 改进CNN-SVM模型流程Fig.4 Improved CNN-SVM model process
(1) 对传感器数值图像进行增强与分割处理,得到统一大小的80×80灰度数字图像。
(2) 卷积层使用9×9的卷积核,取步长为1,对输入图像做卷积计算,得出对应大小的特征图。激活层使用ReLU激活函数对特征图进行处理。
(3) 设置池化层窗口大小为2×2,步长为2,对激活层得到的特征图进行降维处理。
(4) 全连接层对第3次池化得到的特征图进行全连接操作,得到640个1×1的特征图,即640维特征。
(5) 利用PCA算法对全连接层提取的640维特征进行进一步降维处理,最终得到150维特征。
(6) 将150维特征作为SVM的样本数据,通过SVM分类器进行分类识别。
3 模型训练及验证
为了验证改进CNN-SVM模型的性能,采用多种模型对自建数据集和经典MNIST数据集中的单个数字图片进行识别和对比分析。仿真实验平台配置:Intel Core i7处理器,NVIDIA1080Ti显卡,32 GB运行内存,操作系统为Linux Ubuntu 16.04的微服务器,在Pycharm 2020.3平台使用Python 3.7进行软件设计。
3.1 自建数据集验证
自建数据集包含数字0~9和小数点共11类字符。训练集包括5 500个样本,每种字符选择500个样本。测试集包括6 600个样本,每种字符选择600个样本。对自建数据集图像进行预处理,全部归一化为80×80的图像。
为了对比改进前后模型的性能,采用传统CNN模型、CNN-SVM模型及改进CNN-SVM模型进行仿真,结果如图5所示。3种模型的识别准确率及所需时间见表1。
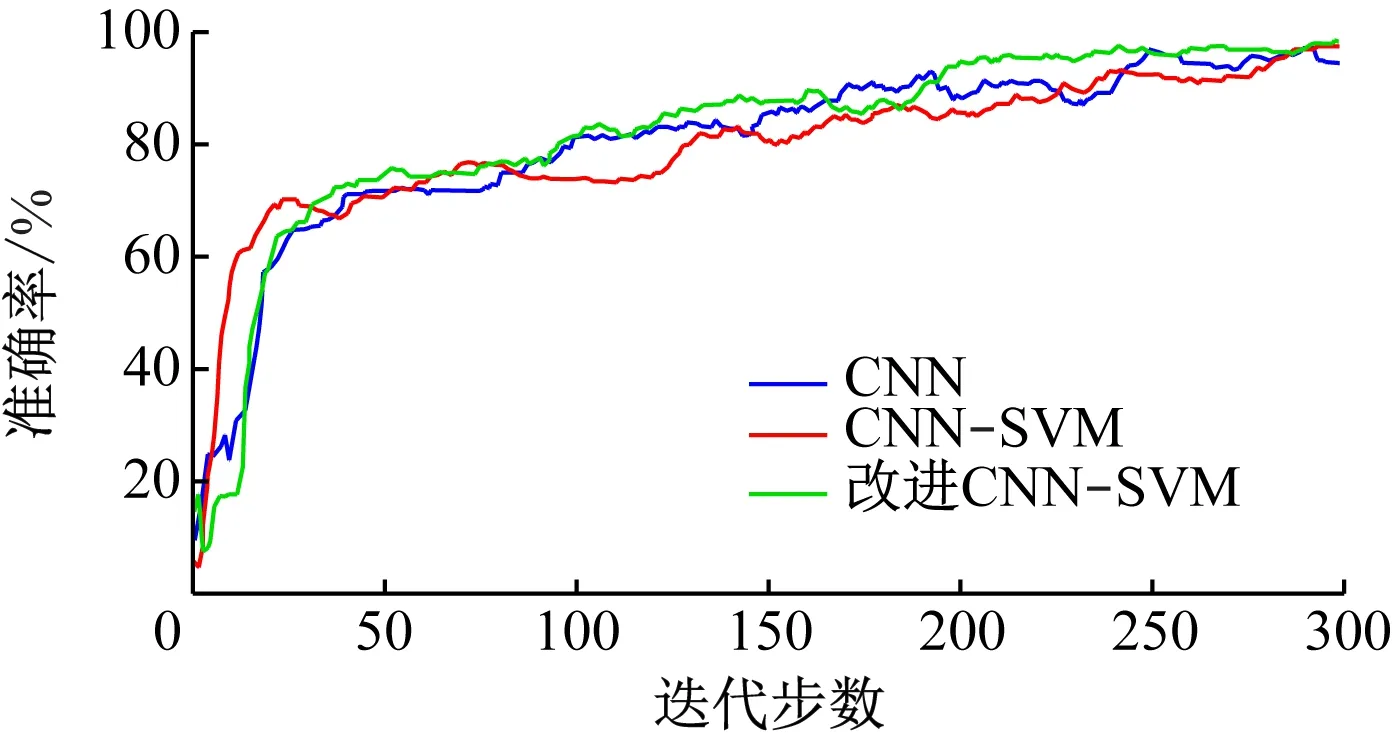
图5 3种模型识别准确率对比Fig.5 Comparison of the recognition accuracy of three models
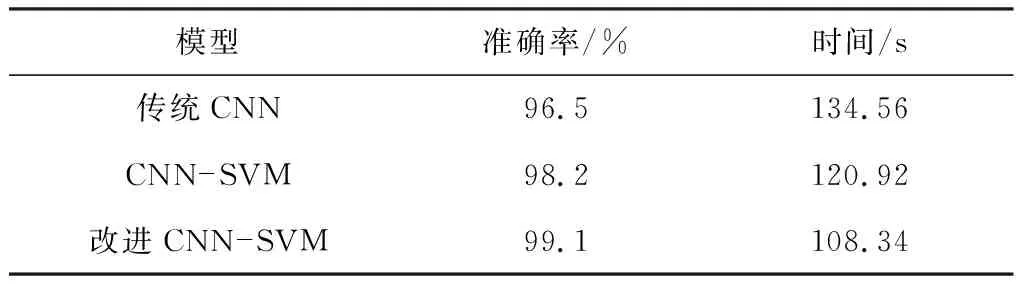
模型准确率/%时间/s传统CNN96.5134.56CNN-SVM98.2120.92改进CNN-SVM99.1108.34
从图5可看出,改进CNN-SVM模型的识别准确率随迭代步数的增加而稳定上升;传统CNN模型的准确率在迭代步数达到200左右时波动起伏严重;CNN-SVM模型的准确率也随迭代次数的增加而稳定上升,但低于改进CNN-SVM模型的准确率。3种模型的准确率在迭代步数达到300时趋于稳定,改进CNN-SVM模型、CNN-SVM模型、传统CNN模型的准确率分别为99.1%,98.2%,96.5%。从表1可得出改进CNN-SVM模型的运行时间最短。仿真结果表明,与另外2种模型相比,改进CNN-SVM模型的准确率更高,运行时间更短。
3.2 MNIST数据集验证
在MNIST数据集下,使用主流深度学习模型与改进CNN-SVM模型进行对比分析。各模型训练参数见表2。
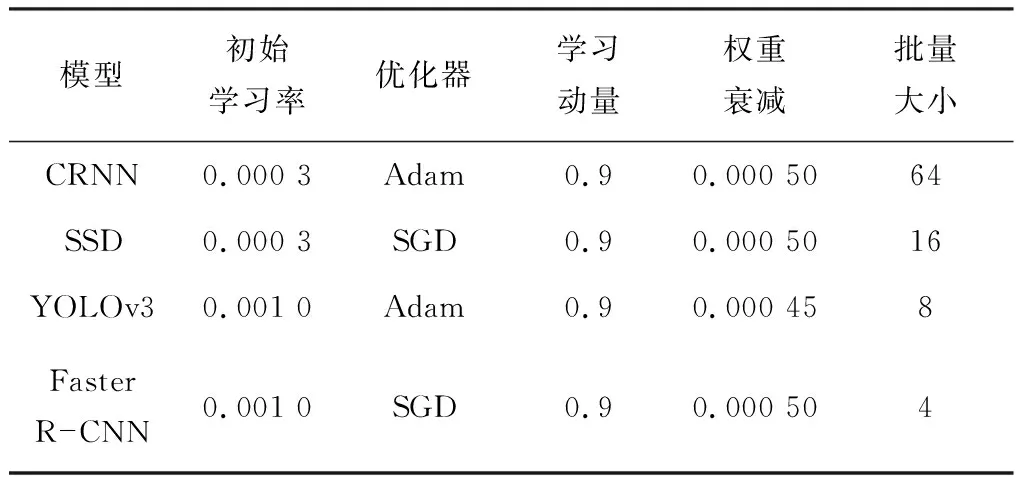
表2 主流深度学习模型训练参数Table 2 Training parameters of mainstream deep learning models
选取MINST数据集中10 000张数字图像作为测试集,采用表2中的各模型进行测试,结果见表3。由表3可知,YOLOv3的实时性较好,每秒可识别85张图片,但其准确率只有95.7%,精度较低;Faster R-CNN识别准确率高,但实时性较差。综合考虑精度和实时性要求,改进CNN-SVM模型的综合性能优于其他模型。
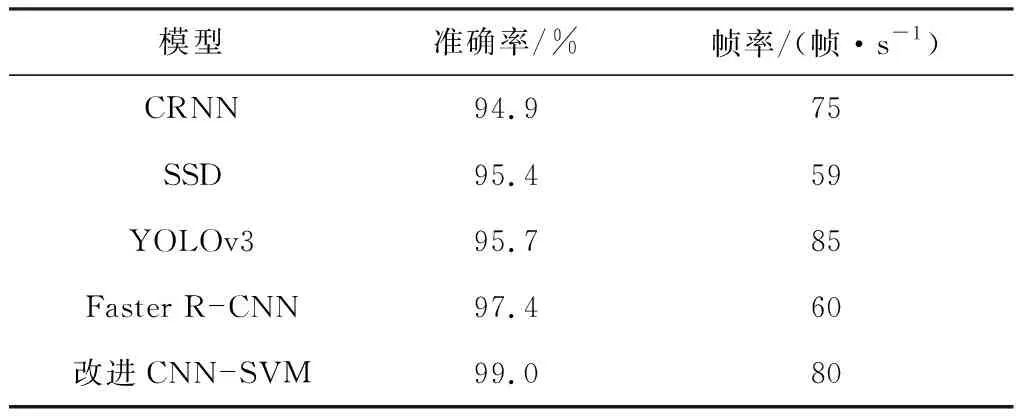
表3 实验结果对比Table 3 Comparison of experimental results
4 基于改进CNN-SVM的甲烷传感器数显识别
由于甲烷传感器数显识别对准确率、实时性有较高要求,单独使用1台计算机完成图像识别不利于系统迁移。综合考虑,选择插拔方便且体积小的树莓派作为图像识别处理器。通过树莓派与微距摄像头配合完成图像采集与识别工作,保证图像采集的实时性和识别的准确率。基于改进CNN-SVM的甲烷传感器数显识别方法如图6所示[13]。采用STM32F407ZGT6作为控制器,实现数据接收、处理及传输;采用树莓派运行改进CNN-SVM模型,实现图像处理和识别;选用微型高清USB摄像头采集甲烷传感器数值图像,该摄像头使用CMOS型感光芯片,具有体积小、功耗低、价格低等优点。

图6 基于改进CNN-SVM的甲烷传感器数显识别方法Fig.6 Digital recognition method of methane sensor based on improved CNN-SVM
数显识别流程如图7所示。将训练好的改进CNN-SVM模型移植到树莓派中,上电后,通过上位机发送开始指令给控制器,控制不同浓度甲烷标准气体及N2的通断和流量;微型高清USB摄像头采集传感器数值图像并传输至树莓派进行识别处理;树莓派将识别后的数据传输至控制器,控制器与上位机进行通信,上位机显示甲烷传感器数值。
为了验证基于改进CNN-SVM的甲烷传感器数显识别方法的识别率,在实验平台通入体积分数为0.5%,3.5%,9%,35%的甲烷标准气体,对摄像头捕获的100张甲烷传感器数值图像进行识别,准确识别出99张图片,识别成功率为99%,与仿真分析结果一致。
5 结论
(1) 改进CNN-SVM模型在采用传统CNN模型进行特征提取的基础上,结合PCA完成对数字图像特征的降维提取,通过SVM对不同数字进行分类识别。

图7 数显识别流程Fig.7 Digital recognition process
(2) 在自建数据集上的验证结果表明,改进CNN-SVM模型、CNN-SVM模型、传统CNN模型的准确率分别为99.1%,98.2%,96.5%,运行时间分别为108.34,120.92,134.56 s,改进CNN-SVM模型的准确率最高,运行时间最短。
(3) 在经典MNIST数据集上的验证结果表明,改进CNN-SVM模型的识别准确率为99.0%,帧率为80帧/s,综合考虑精度和实时性要求,改进CNN-SVM模型的综合性能优于CRNN,SSD,YOLOv3,Faster R-CNN等模型。
(4) 采用微型高清USB摄像头采集传感器数值图像,将训练好的改进CNN-SVM模型移植到树莓派中进行图像处理和识别,结果表明,基于改进CNN-SVM的甲烷传感器数显识别方法的识别成功率为99%,与仿真分析结果一致。
猜你喜欢
高技术通讯(2021年3期)2021-06-09 06:57:24
军民两用技术与产品(2021年10期)2021-03-16 06:05:08
水上消防(2020年1期)2020-07-24 09:26:02
电子制作(2019年11期)2019-07-04 00:34:32
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
电测与仪表(2017年24期)2017-12-19 05:15:16
电子制作(2017年17期)2017-12-18 06:40:43
北京航空航天大学学报(2017年12期)2017-04-23 08:31:39
中国酿造(2016年12期)2016-03-01 03:08:19
铁路通信信号工程技术(2014年5期)2014-02-28 16:57:09
