
基于层次体系的情感单元表示方法*
2022-01-24 02:16张宝华李奀林张华平商建云
计算机工程与科学 2022年1期
张宝华 ,李奀林 ,张华平 ,商建云
(1.北京理工大学计算机学院,北京 100081;2.军委训练管理部,北京 100142)
1 引言
情感分析是自然语言处理的研究热点[1],近几年来,随着互联网用户的增加,情感分析技术已成为对网民进行观点挖掘的必不可少的技术手段[2]。然而,新词频出是互联网数据的一大特点,很多词汇不在已知的情感词典中,如“废青”“甴曱”等,由于这些词极性未知,在进行情感分析时会误认为其情感权重为零,从而导致分析结果不准确。因此,如何计算新情感词的权重是当前情感分析工作的难点。
现有的情感权重计算方法大多只根据语义信息计算,忽略了情感词所在语境,在面对语义未知的词时,很难得到正确的情感权重,因此,通过语义方法计算得到的情感词典的准确率较低。如在微博评论“香港法官是最大的甴曱,和那些乱港分子、暴力分子里应外合的太明显了”,其中由于“甴曱”的意思未知,现有的情感权重计算方法很难得到该词的情感权重。但是,根据语境信息,我们知道 “暴力”是个负面词,由“和暴力分子里应外合”可得“甴曱”是一个偏向负面的词。可以看出,基于语境的方法较适合此类语义未知的新词。
本文根据情感分析的要素,提出了从构字到篇章的情感分析层次体系,并针对每个层次提出了面向上层的表示方法和情感权重计算方法。在此基础上,本文提出了一种情感语义单元的自动构建方法,从情感语义单元的构字和语境的情感倾向出发推导其情感权重。本文在真实的评论数据上进行了实验,实验结果表明,本文提出的方法可以很好地提取出每个领域对应的情感单元并计算其情感权重,由此得到的情感词典较其他情感词典构建方法有更高的准确率。同时,本文提出的情感语义单元可以直接在基于规则的方法和深度学习的方法上使用。
本文第2节针对当前常用的情感词典构建方法进行了总结,第3节提出了情感分析层次体系,并详细介绍了每层向上层的表示方法和情感计算公式,第4节提出了情感语义单元自动构建的模型,第5节进行了真实评论数据的实验对比,结果表明,与当前公开的情感词典在基于规则的情感分析准确率上,本文方法构建的情感语义单元有约9%的提升,在深度学习方法的情感分析准确率上,本文方法构建的情感语义单元有3%的提升。
2 相关工作
基于情感词典的方法是最早用来进行情感分析的,早期的情感词典都是通过人工构建[3,4],所含情感词较少,只有一些常见的形容词如“高兴”“开心”“漂亮”等。洪巍等人[5]提出了基于情感词典的情感分析方法,其原理与斯坦福基于词典的情感分析方法基本相同,情感词典的质量决定了实验效果。基于机器学习的方法主要是通过提取文本的特征,然后根据某种算法进行分类。机器学习的分类器主要包括最近邻KNN(K-Nearest Neighbor)、最大熵和支持向量机SVM(Support Vector Machine)等。Pang等人[7]对比了最大熵、SVM和朴素贝叶斯3种机器学习算法,发现在影评数据集上SVM的分类效果更好。曹海涛[8]使用上述机器学习算法对愉悦激活优势PAD(Pleasure Arousal Dominance)情感语义特征进行了实验,发现SVM算法的实验效果较优。随着深度学习的兴起,许多研究者开始使用神经网络进行情感分类。由于长短时记忆LSTM(Long Short-Term Memory)神经网络可以保存时序信息,Li等人[9]提出了在情感分析上使用LSTM;Li等人[10]采用卷积神经网络提取文本的特征;Hassan等人[11]将这2种方法结合起来,使用LSTM代替池化层,减少了局部细节信息的丢失;李卫疆等人[12]在LSTM的基础上,将词性特征、位置值特征和依存句法特征,以多通道的方式输入到双向长短时记忆网络中,并取得了很好的效果;Wang等人[13]通过研究树型结构的区域卷积神经网络与长短时记忆神经网络结合模型CNN-BiLSTM(Convolutional Neural Network-Bi-directional Long Short-Term Memory),提出了更细粒度的情感分析方法;邱宁佳等人[14]提出的双通道中文情感模型结合了卷积神经网络和双向长短时记忆神经网络,同时还利用了文本特征和语法规则。可以看出,情感分析已经从早期以获取文本特征为主发展到同时结合文本特征和语义规则特征,如何将早期情感词典方法中的规则结合到深度学习模型中是当前的研究方向。但是目前的研究仍然没有形成完整的体系,文本方面的特征仍以句子特征为主,缺乏对其他维度特征的研究。
在情感词典构建方面,Liu等人[15]认为构建情感词典主要有基于手工标注的方法、基于已知词典的方法和基于语料库的方法。本文认为情感词典的构建方法分为以下3种:基于语义的方法、基于统计的方法和基于深度学习的方法。
基于语义的方法主要是通过选取一些种子情感词,然后利用同义词和反义词进行扩展。Hu等人[16]首先将句子中的形容词提取出来,然后人工给出20个正负面种子情感词,根据WordNet,如果形容词的近义词和反义词都在种子情感词中就可以确定其极性,然后不断迭代。Hatzivassiloglou等人[17]利用种子情感词和连接词进行判断,如and连接的形容词往往极性相同。Strapparava等人[18]分别在情感词典中加入了名词、动词、副词和中性词,扩展了情感词典。Kamps等人[19]提出了一种迭代公式计算方法EVA(EVAluate),通过该方法可分别计算出情感词迭代到正负面已知情感词的次数,利用迭代到负面情感词的次数减去迭代到正面情感词的次数,若差值大于0则为正面情感词,小于0则为负面情感词。该方法认为如果一个词的极性更倾向于正面,则迭代到正面情感词的次数越少,这种方法引入了少量的统计工作。
基于统计的方法是根据语料库计算某一领域的情感词典,最常见的是利用点互信息PMI(Pointwise Mutual Information)[20],其认为如果2个词同时出现的次数越多,则2个词相似度越高。因此,结合情感词典中的正负面情感词就可以计算得出其他词的情感极性和权重。Tureny[21]提出利用SO-PMI(Semantic Orientation Pointwise Mutual Information)公式来计算未知情感词的权重,计算情感词的正面点互信息和负面点互信息的差值。Tai等人[22]针对PMI做了改进,提出了二阶点互信息SEC-PMI(SECond-order Point Mutual Information)的算法,可以计算2个由中间词连接的词的PMI。张华平等人[23]提出了一种基于贝叶斯公式的算法,其主要思想是一个词的构字也是具有情感倾向的,根据已知情感词典和语料库计算每个字的情感倾向概率,然后利用贝叶斯公式计算未知情感词的权重。
基于深度学习的方法是基于词嵌入(word2vec)技术的,杨阳等人[24]在训练词向量的基础上分别使用了权重递增法、SVM分类法和中心向量法3种方法进行候选情感词的倾向判断,实验表明权重递增法和SVM分类法的效果不佳,而中心向量法又依赖人工选取中心点。胡家珩等人[25]提出了在word2vec的基础上使用全连接层训练情感词的分类器,然后对候选情感词进行分类。Tang等人[26]在word2vec的基础上,修改了词袋模型,提出了3种神经网络模型,将语义信息和情感信息加入到了训练的词向量中。李永帅等人[27]提出了三层神经网络结构的方法,通过CBOW(Continuous Bag Of Words)提取情感信息,然后利用2层双向LSTM和二叉语义依存结构得到高质量的情感词典。
3 情感分析的层次体系构建
本文构建了一个情感分析的层次体系,包括字、元情感词、复合情感词、单句、复句和篇章。其中元情感词是本文新提出的,表示不包含否定词和程度词的情感词。情感单元是指每层中最基础的部分,每一层都可看做是其上层的情感分析单元,在进行情感分析时,根据每层的情感单元计算对应的权重。
本文认为组成情感词的字同样具有情感极性,情感词的极性在本质上受其构字的影响,因此字在情感分析中应该处于最底层。而否定词和程度副词会对情感词的极性和权重产生影响,因此根据情感词中是否含有否定词和程度副词,将情感词划分为元情感词和复合情感词。元情感词处于第2层,复合情感词在其上层。句子是由多个词构成的,根据句法规则和句型规则[24],句子可分为单句和复句,因此,句子在词的上层。其中单句表示不能再拆分的句子,复句表示由关联词或者标点符号连接的2个以上的单句组成的句子。篇章是由多个复句组成的。因此,篇章为情感分析的最高层,本文构建的情感分析层次体系具体如图1所示。

Figure 1 Hierarchical of sentiment analysis图1 情感分析层次体系
对于元情感词,字是其情感单元,元情感词是复合情感词的情感单元,令L表示字,W=L1,…,LNL表示词,其中NL为W中包含的字L的个数,则复合情感词Cs表示如式(1)所示:
Cs=(WD|WN)*WS|WS(WD|WN)*
(1)
其中,WN表示否定词,如“不是”“从未”“绝不”等;WD表示程度词,如“非常”“有点儿”等;WS表示简单情感词也叫元情感词,即不含否定词和程度词的情感词,如“公平”“仁慈”,*表示存在0个或者多个。
令weigth表示权重,则元情感词的权重记为:weigth(WS),程度词的权重记为weigth(WD)。令score表示情感得分,根据其所包含的否定词和程度副词以及组成顺序,复合情感词的情感值计算方式如式(2)所示:
score(Cs)=weight(WS)*D
(2)
其中D为情感词的影响因子,其计算方式如式(3)所示:
(3)
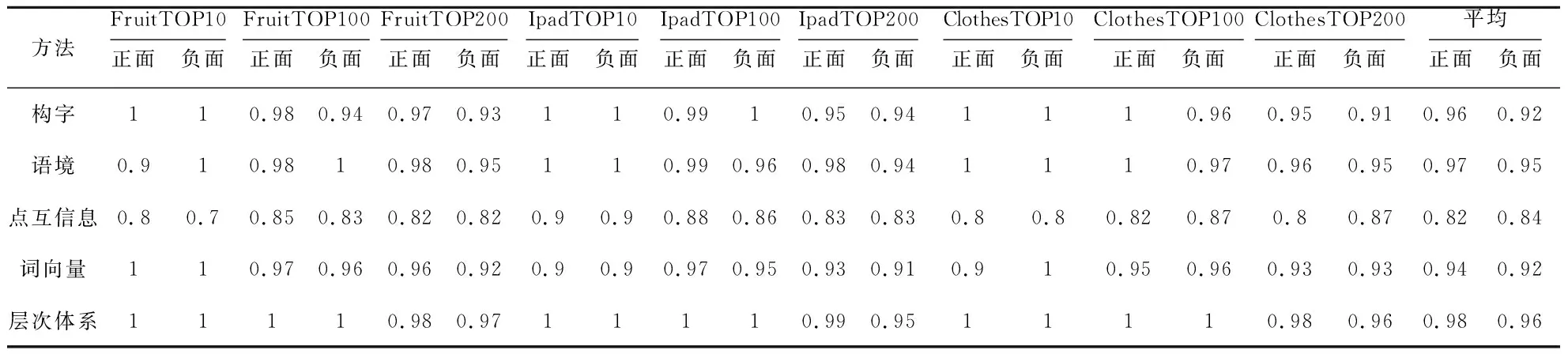
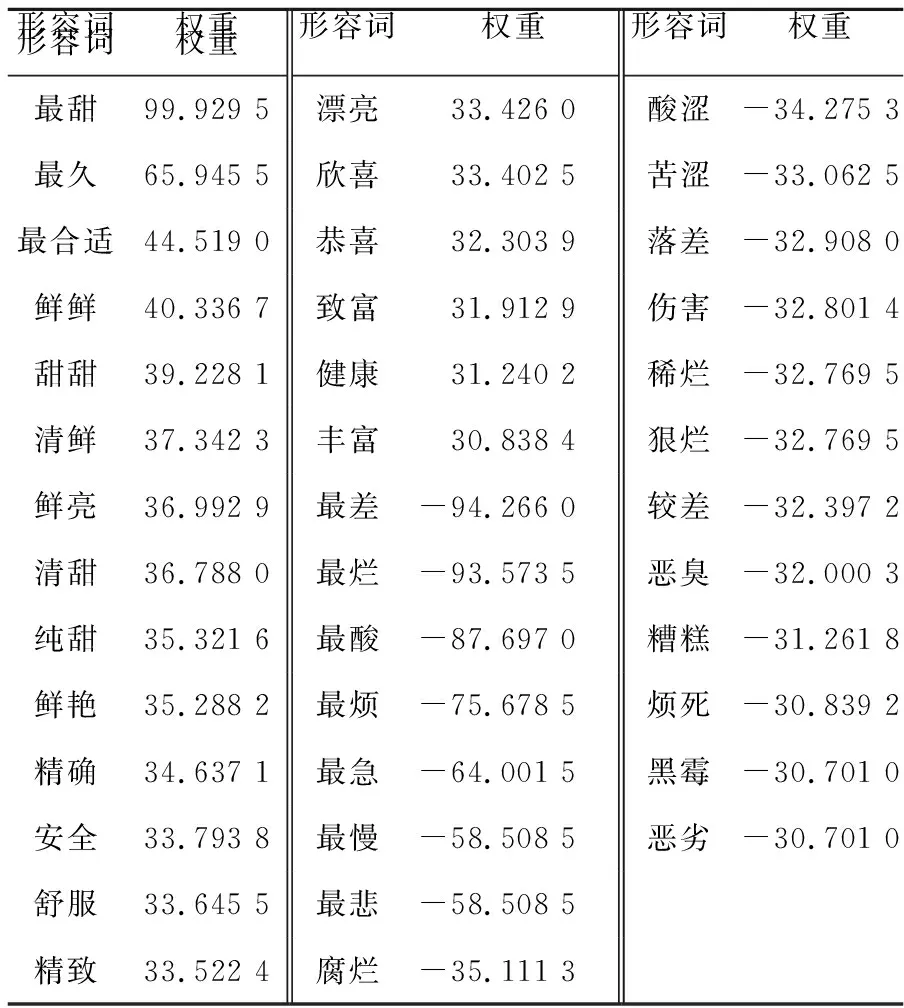
其中,M为比例因子,第4种情况表示较弱的否定词+情感词,所以0 记单句为SS,复合情感词是单句的情感单元,则SS可以表示如式(4)所示: SS=Cs(W|Cs)* (4) (5) 其中,NC为单句SS中包含的复合情感词Cs的个数,Csi表示第i个复合情感词。 记复句为MS,关联词为WR,单句是复句的情感单元,则MS可以表示如式(6)所示: MS=(WR1)*Ss1(WRi|Ssi)*(SsNS)* (6) 其中,WR1,WRt分别表示复句中的第1个关联词和第i个关联词,如“虽然”“但是”。Ss1,Ssi分别表示复句中第1个单句和第i个单句,NS为复句MS中单句SS的个数。 综上所述,复句MS的情感值score(MS)计算公式如式(7)所示: (7) 其中,weight(WR)是关联词的权重,具体计算方法由关联词的类型决定,计算公式如表1[28]所示,其中SSi和SSj分别表示第i个和第j个单句。 Table 1 Weight of different types of related words on different positions 计算依据为句型规则,句型规则一般有转折关系、递进关系、因果关系和假设关系[29,30]。但是,在实验中发现,由于因果关系和假设关系存在多种情况,如因果关系“因为你喜欢我,所以我也喜欢你”和“因为你喜欢他,所以我不喜欢你”中,2句的前半句的情感词相同,但是后半句的情感词完全相反,所以这里只考虑转折关系和递进关系。 令Q表示篇章,则: Q=MS(MS)* (8) 由于篇章是由复句组成的,所以其情感值应该等于复合的情感值累加,如式(9)所示: (9) 其中,Msi表示第i个复句,NM为篇章Q中复句MS的个数。 在本文提出的情感分析层次体系中,词处于最重要的位置,无论是单句、复句还是篇章的情感值,都可以通过情感单元变换,最终由词的权重计算得到,在基于规则的方法中,词典本身就是一个重要的因素,在深度学习方法中,复合情感词也是重要的情感特征。因此,情感词是情感分析任务中的基础情感单元,也叫做情感语义单元。 情感语义单元的构字影响着该单元的基本情感倾向,其语境决定最终情感倾向,在计算其情感权重时必须同时考虑到构字和所在语境。对于一个情感单元WS,设WS=L1,…,LNL,其中,NL为WS中包含的字L的个数,WS的上层是Cs,则其情感权重计算公式如下: weight(WS)=λF(score(Cs))+ (10) 基于情感词构字方法的主要思想是利用贝叶斯公式[23],根据已有的情感词典,通过计算候选情感词构字在给定语料库中的正负面情感倾向概率得到其极性和权重,以下是对文献[23]所提出的方法的改进: 根据第3节的层次体系,原文选择的情感词典既包含元情感词也包含复合情感词,如“不犹豫”为褒义词,而“犹豫”为贬义词,在计算时,将否定词“不”也作为情感词。但是,“不”实际上只是起到改变极性的作用,在复合情感词中“不”本身并没有情感倾向,所以在计算之前需要先处理已知情感词,将复合情感词中的程度副词和否定词去除,并根据式(2)反向计算得到元情感词权重。同样,在计算时也应该只计算元情感词的权重,再根据式(2)计算得出复合情感词的权重。 (11) (12) 由此: (13) 由于情感词典中的词有正负面之分,所以需要分别计算其属于正负面的概率,如式(14)所示: (14) (15) 其中,σ为一个很大的数,本文选取为数据集总字数。 最后根据权重排名便可以得到准确率较高的情感词典。 同一个词在不同语境中可能会有截然不同的情感极性,如,“他讲了个笑话,大家笑的很开心”,“小明今天闹了个笑话,觉得很没面子”,这2句中的“笑话”一词在前句中为褒义词,在后一句中为贬义词。因此,在计算情感词的情感权重时必须考虑到其所在语境。 基于候选情感词语境的思想是,在一个单句中,句内的情感倾向保持一致,其组成该单句的所有复合情感词具有相同的极性,假设每个情感单元对SS的情感值贡献了相同的情感得分,则可据此推测出未知复合情感词的极性和情感得分。再由式(2)反推出元情感词的权重。如果某一单句中不含已知情感词,无法通过已知情感词典直接计算得出该句的情感值,可以通过句间关系来计算,在表1中提到过4种句型规则,同样选取转折关系和递进关系,具体计算方法如表2所示。 表2中H为权重因子,表示递进句后句较前句的强烈程度,H>1。综上所述,未知复合情感词的权重计算公式如式(16)所示: (16) 其中,NS为包含该情感词的句子个数,n为单句中包含的复合情感词的个数。 在实验中发现,部分词的情感极性不明显,既在负面情感句中出现,也在正面情感句中出现,且出现的频率相差不大。为了避免这部分词对最终结果造成影响,对所计算的情感单元增加置信度权重,根据其在正负面句子中出现的概率分别计算其正负面置信度,最终根据置信度的大小确定其极性。 Table 2 Calculation method and example of the sentiment score of compound sentiment words 将基于构字和基于语境的方法以最终加权的方式结合,即可得到准确率较高的情感词典,其中基于情感语义单元语境的权重计算方法的权重较高。由于本文的2种方法都是基于已知情感词典的,在每次计算出未知情感词典之后,都可将其加入到已知情感词典中进行迭代计算。同时对于已知情感词典中的情感词权重,该方法也会进行更新调整,最终得到更准确的情感词典。本文将2种方法加权结合的方法称为基于层次体系的方法。 本文的数据集选自真实评论数据,包含谭松波酒店评论数据(Hotel)正负面各3 000条,京东上采集的水果(Fruit)、衣服(Clothes)和平板电脑(Ipad)评价,正负面各5 000条,以及豆瓣(Douban)上采集的17万条电影评论,筛选后保留正负面影评各5万条。本文的情感词典选自台湾大学的NTUSD(National Taiwan University Sentiment Dictionary)、清华大学李军中文褒贬义词典以及知网的HowNet,将3部词典中极性相同的词放到一起,极性不同的词去除不用。本文的否定词词典和程度词词典选自知网,其中程度词按照知网的分类给予不同的权重,权重对应如表3[28]所示,关联词选自新华字典,具体如表4所示。 Table 3 Weight of intensifiers Table 4 Transition words and progressive words 根据文献[23]中提到的方法,对结果按照计算得出的权重排序,计算排名前200的情感词的准确率。本文将基于情感语义单元构字的权重计算方法(4.1节)、基于情感语义单元语境的权重计算方法(4.2节)、基于点互信息(SO-PMI)的权重计算方法、基于词向量的权重计算方法与本文基于情感层次体系的权重计算方法进行对比,实验结果如表5所示。 Table 5 Accuracy of different methods on the first 200 words with positive and negative sentiment 表5的结果表明,基于构字方法构建的情感词典的准确率较差,而只使用语境的方法得到的情感词典的准确率接近构字和语境都用的方法,这说明语境对情感词的影响较大。同时与基于构字的方法相比,本文方法在准确率上有约3%的提升,所得到的情感词典更加准确。表6为由层次体系方法得到的情感词权重的部分结果示例。在实验结果中发现,基于构字的方法计算得到的情感词典会出现矛盾的情况,如表7所示,如在水果评论的数据集中“贵”和“不贵”的情感倾向是相同的,表7的结果表明在不加入情感层次体系区分元情感词和符合情感词前,基于构字的方法在元情感词及其组成的复合情感词权重上有很大的误差。如“贵”和“挺贵”的权重相同,“大”和“不大”的权重相同。在引入情感层次体系之后,所得情感词权重符合情感层次体系,根据不同的组成,使不同的复合情感词有不同的权重。 Table 6 Examples of weight of some sentiment words Table 7 Comparison of partial results of the sentiment hierarchy and the original method 实验结果主要从精确率P(Precision)、召回率R(Recall)、F1值和准确率acc(accuracy)4个方面进行分析,分别计算5.2节中的5种方法在正负面数据集上的P、R、F1,以及整体的准确率。 实验设置如下:在Ipad、水果、衣服和豆瓣的评论数据集上,使用基于情感词典的方法,分别使用5.2节中的5种方法构建适用于该语料的情感词典,然后用基于规则的方法对语料进行情感评分,结果如表8所示。 Table 8 Experimental results of sentiment dictionary obtained by five methods based on sentiment words in sentiment analysis method 从表8可以看出,本文方法得出的情感词较原有情感词在计算情感值时准确率提升了9%。这表明本文方法得到的情感词典更准确且更适合这个领域,证明了本文方法的有效性。 为了验证本文提出的情感语义单元构建方法的贡献,本文在BiLSTM(Bi-directional Long Short-Term Memory)模型上进行了深度学习的对比实验,实验设置如下:所有实验均采用jieba分词,利用word2vec得到词向量,最后使用BiLSTM模型进行训练。前2组实验输入为整句,不同的是,第2组实验在jieba 分词前将基础情感词典加入到用户词典中。剩下的6组在训练数据输入BiLSTM模型之前都要进行处理,去掉不在情感词典中的词。其中第3组使用公开情感词典的情感词,第4组是通过SO-PMI[9]方法构建的情感词典,第5组是使用word2vec权重递增法[21]构建的情感词典,第6组是使用构字方法得到的情感词典,第7组是使用语境方法得到的情感词典,第8组是使用层次体系方法得到的情感词典。将数据集随机选择30%作为测试集进行实验,准确率如表9所示。 从表9可以看到,第1组和第2组的结果相差不大,但是前2组的结果要比后6组的结果差,这说明情感词在情感分析中起着重要的作用,准确、全面的情感词典可以提高情感分析的准确率。后6组只使用情感词的实验表明,较当前的情感词典构建方法构建的情感词典,本文方法构建的情感词典在情感分析实验上准确率更高,表明了本文方法的有效性。 Table 9 Accuracy of different methods on different datasets 本文首先提出了从字到篇章的情感分析层次体系,针对每层都提出了该层的情感权重表示方法和计算公式,可以通过下层情感单元计算得到相应的情感权重。在此基础上,本文提出了基于构字和语境的情感语义单元自动构建,同时使用情感词的构字情感倾向和语境的情感值计算其权重,可以提取出更适合该语料的情感词典,提高对该语料情感分析的准确率。通过真实评论数据集的实验,验证了本文提出的情感语义单元构建方法可以提升情感词典构建的准确率。与基于规则方法和深度学习方法的情感分析对比实验表明,本文构建的情感语义单元均有良好的表现,较当前的公开词典和构建算法构建的词典,本文方法构建的词典的情感分析准确率分别提升了9%和3%。
4 情感语义单元的自动构建


4.1 基于情感语义单元构字的权重计算方法
4.2 基于情感语义单元语境的权重计算方法

5 实验与分析
5.1 数据集与情感词典


5.2 基于候选情感词构成的情感词典构建方法对比

5.3 基于情感词典方法的对比实验

5.4 基于深度学习方法的对比实验

6 结束语
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26
韩国语教学与研究(2021年2期)2021-11-24
散文百家(2021年7期)2021-11-12
华北电力大学学报(社会科学版)(2021年2期)2021-07-21
青年文学家(2018年17期)2018-07-27
时代英语·高二(2015年2期)2015-05-18
时代英语·高二(2015年1期)2015-03-16
时代英语·高二(2014年4期)2014-08-27
时代英语·高二(2014年5期)2014-08-26
西安航空学院学报(2014年4期)2014-07-13
