
MySQL NDB 集群在“住建一张图”建设中的应用
2022-01-22 08:59马亚敏李守鹏
矿山测量 2021年6期
马亚敏,李守鹏,王 鹏,夏 真
(济南市房产测绘研究院,山东 济南 250001)
近几年来,随着互联网不断推广与普及,移动通讯网络不断完善和提速,使得数据访问量和数据体量爆炸式增长,大数据和云计算为“智慧住建”建设带来了契机,济南市“住建一张图”平台建设也在向信息化和智慧化转变。随着民众对方便快捷地获取公共服务的需求日益迫切,住建系统的业务量、访问量和数据流量快速增长,而传统单机数据库所支持的并发数、吞吐量难以满足这一现状。因此,亟需寻找一种新的数据库模式来实现系统的高并发、高吞吐率、高可用性[1-4]。
结合济南市“智慧住建”建设方案,决定采用MySQL NDB分布式存储引擎和负载均衡技术,使用一组普通性能服务器,搭建一套高吞吐、高并发和可动态扩展的MySQL NDB 集群数据库。MySQL NDB 集群采用分布式部署,由多台服务器存储数据,提高数据完整性和可用性;由多台服务器提供SQL客户端,有效提高并发访问数量;通过负载均衡技术,可实现读写分离,有效提高吞吐数据量[5]。
本文提出一套详细的MySQL NDB 集群解决方案,以普通服务器组建高吞吐、高并发和高可用的集群数据库,以及数据库集群负载均衡方法和数据库集群性能的具体测试方案。
1 MySQL NDB集群高性能解决方案
1.1 “住建一张图”的现状
济南市“住建一张图”管理系统逻辑框架共五层,分别为硬件支撑层、数据存储层、GIS分析层、接口层、应用系统层。其中,“住建一张图”系统“数据层”可以划分为两大类数据:空间地理数据和住建业务数据。济南市住房和城乡建设局主管全市住房建设工作,所需整合的地理空间数据包括全市的二维地图数据、房屋图层数据约100万房屋幢图斑、各业务专题图数据2 TB等;所需整合的业务专题数据包括项目报建、图审、工程监理、竣工验收、房产交易、维修资金、征收拆迁、物业管理、房屋安全、城市更新、老旧小区、直管公房、房改房、住房保障、房屋租赁等数据,数据量约9 000余万条,涉及数据种类繁多,数据繁杂,数据量巨大。
当前济南市住房和城乡建设局多系统独立并存的工作模式,造成各类业务数据资源数据指标不一、条块分割、壁垒严重,丧失了信息应有的流动性;数据存在重复存储、重复更新问题且信息不能横向互联互通,难以提供有效的科学分析和决策支持;信息研判多停留在对单项业务信息的分析、判断,未能充分整合数据资源,进行全方位、多角度的剖析和提取,没有深层次挖掘大数据的价值以辅助各部门科学决策。因此,根据济南市“智慧住建”的规划方案和大数据中心建设需求,将数据和业务进行集成,建设全市统一的住建信息数据库,提供高效海量数据存储、快速访问和更新、全业务综合分析应用等数据服务。
1.2 MySQL NDB集群架构方案
1.2.1 逻辑架构
MySQL集群采用NDB Cluster高冗余的存储引擎,以保证数据的完整性,集群采用的是MySQL Cluster + MySQL Router的四层集群负载均衡部署方案,集群逻辑架构图如图1所示。
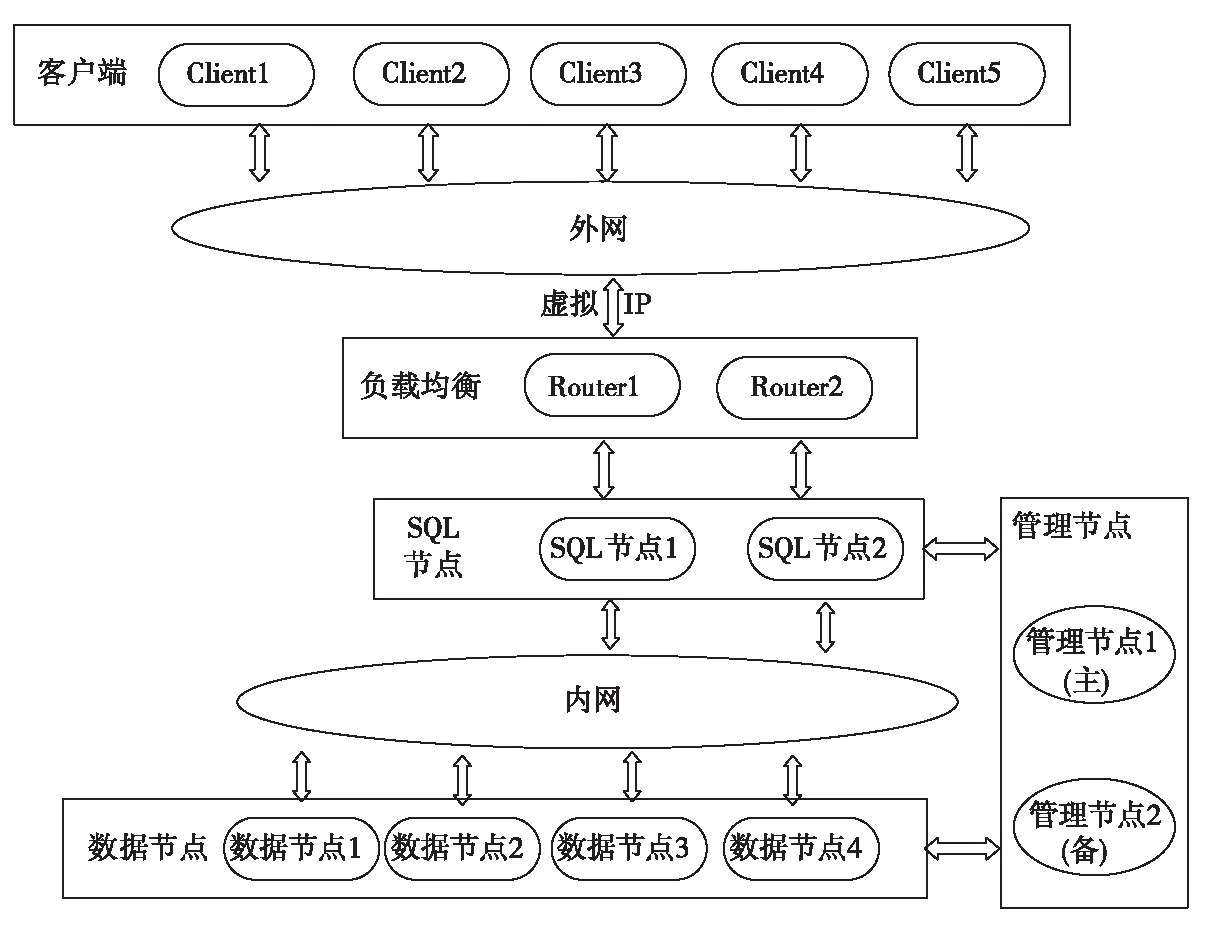
图1 集群逻辑架构图
该MySQL集群系统由客户端应用程序、Router节点、SQL节点、数据节点和管理节点五部分组成。客户端首先访问负载均衡的Router节点,而Router节点循环连接各SQL节点来访问数据节点[6-7],各个节点由管理节点统一管理。
(1)Router节点
Router节点代理流量转发,实现负载均衡。多客户端可并发访问Router节点时,该节点循环连接各SQL节点,如果其中一个SQL断开,Router节点会自动寻找下一SQL节点,确保集群正常使用。
(2)SQL节点
SQL节点提供客户端访问集群数据的接口,存储集群数据的表结构,并且每次插入数据,所有数据节点均同步保存。
(3)数据节点
MySQL集群中,数据节点用于存储集群中的数据,NDB引擎会根据数据节点数目将数据进行分布式存储,确保各数据节点上数据分片的完整性。
(4)管理(MGM)节点
它负责对集群中各节点进行管理,包括对各类节点的启动、停止、维护等操作,并记录集群的操作日志。
1.2.2 部署架构
根据济南市智慧“住建一张图”的建设需求,构建了MySQL NDB 集群数据库,并部署在浪潮政务云上,部署架构图如图2所示。
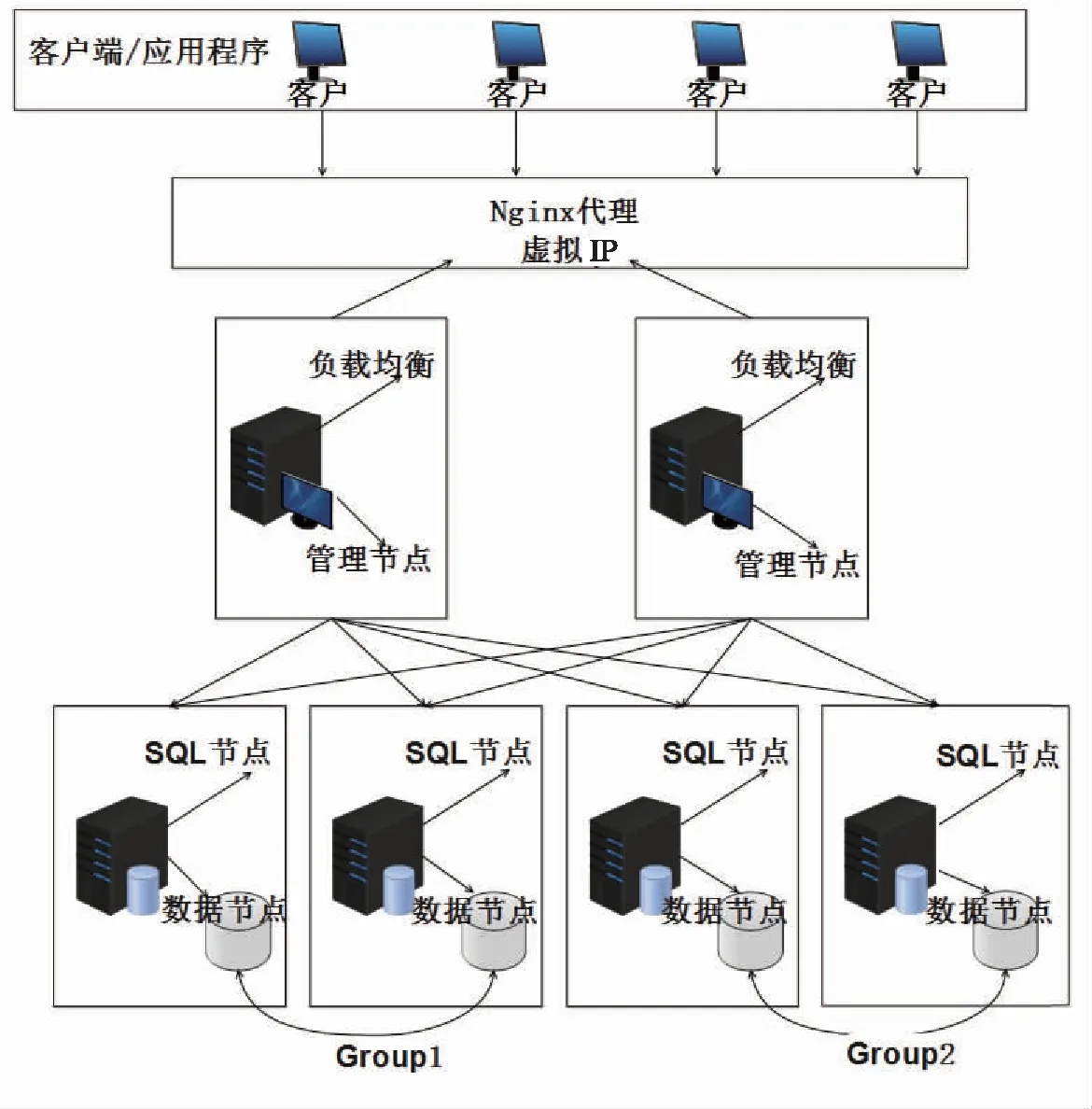
图2 集群部署架构图
其中,4台服务器部署SQL节点和数据节点,2台服务器部署2个管理节点。通过负载均衡技术,将SQL节点地址路由映射为政务云内网IP地址,再通过Nginx代理,将政务云IP地址代理为外网虚拟IP地址。负载均衡节点与管理节点均采用主从配置,可有效减少宕机风险,提高集群可用性。每个SQL节点均独立部署,避免单点故障;4个数据节点分为两个Group和四个分区,每个分区都在同一个Group里面有多个拷贝,确保数据的完整性[8-9]。
1.3 负载均衡方案
使用MySQL Router中间件代理流量转发,实现负载均衡,具体解决方案如图3所示。
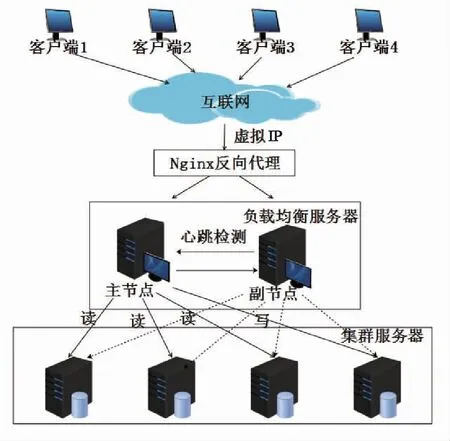
图3 负载均衡逻辑架构图
负载均衡节点采用主从配置,若主节点出现故障,副节点会主动接管,主从节点之间采用心跳监测确保有效通信。
MySQL Router实现了流量分发,避免了只向一个SQL节点导入流量,如果当前的实例宕机了,就会向集群的下一个SQL导入流量。同时,MySQL Router实现了读写分离,根据集群使用场景读写任务的轻重,合理分配读写SQL节点数量[10]。
2 应用案例
2.1 安装与配置
本次数据库集群搭建使用了七台浪潮云服务器,其中一台在政务外网,可登录Internet访问该服务器,其它六台在政务内网,Internet不能直接访问,二者之间通过网闸控制连通实现隔离。部署环境为CentOS8.0和64位处理器架构,MySQL集群数据库版本为mysql-cluster-8.0.22-el7-x86_64.tar.gz,MySQL负载均衡版本为mysql-router-cluster-8.0.22-el7-x86_64.tar.gz。
2.1.1 集群管理
集群数据库安装版本为 MySQL NDB Cluster 8.0,集群节点部署在六台服务器上,各节点IP分配如表1所示。
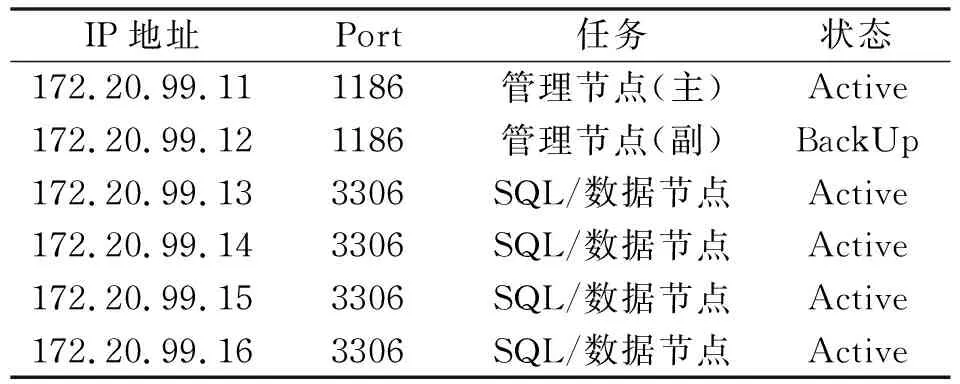
表1 节点IP与Port
其中,11和12两台服务器是管理节点;13~16四台服务器为数据节点和SQL节点,需要配置大内存,其配置内存是数据量的2倍时,集群运行效率较佳。
2.1.2 Router配置
启用两台服务器作为负载均衡节点,分别安装负载均衡软件MySQL-Router 8.0,安装版本与MySQL数据库版本一致。负载均衡节点配置的主要文件为mysqlrouter.conf,主要配置负载均衡规则、负载均衡绑定IP地址、Port端口和需负载均衡SQL节点地址,具体配置如表2所示。
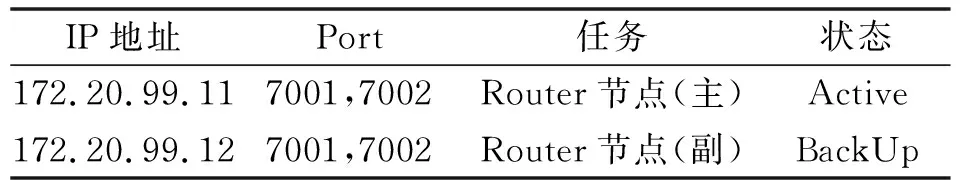
表2 负载均衡节点IP与Port
MySQL Router有两种路由规则:循环访问与优先访问,此实例中,7001端口对应循环访问,7002端口对应优先访问。负载均衡SQL节点地址为:172.20.99.13: 3306, 172.20.99.14:3306, 172.20.99.15:3306, 172.20.99.16:3306。
2.1.3 Nginx代理
政务外网上服务器使用Nginx代理政务内网上的数据库集群,将负载均衡生成的虚拟IP和Port代理为政务外网地址,进一步隔离内网数据,提高数据安全。其中,Nginx的配置文件为nginx.conf文件,主要完成代理IP端口和目标URL的配置,一个Nginx服务可以代理多个URL,具体Nginx服务器IP地址为:172.20.99.10,其具体配置如表3所示。
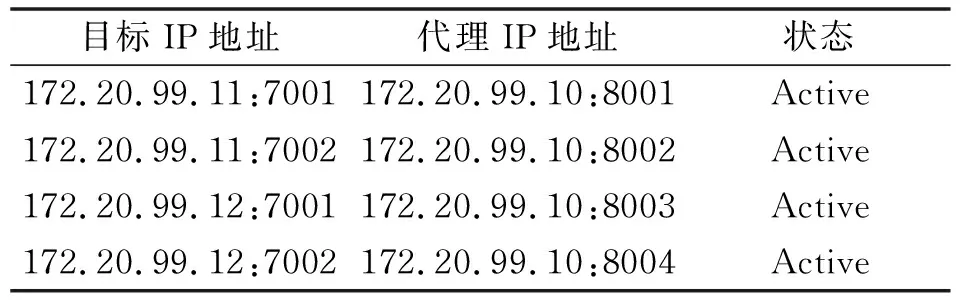
表3 Nginx代理IP与端口号
将浪潮云内网上的数据集群访问地址,均通过Nginx服务器代理为浪潮云外网地址,端口也可以重新映射,将内网集群数据有效隔离在内网中。
2.2 数据库构建
MySQL NDB集群可创建两种类型的表,分别为内存表和磁盘表。磁盘表仅将主键、索引字段保存在内存中,其他字段数据皆保存至磁盘文件中,因此,磁盘表检索效率比较低。内存表将所有字段和索引数据都保存在内存中,同时,也在磁盘上保存一份数据文件,数据节点会在启动的时候把数据加载到内存,因此,内存表的检索效率较高。
2.2.1 创建内存表
MySQL集群默认创建内存表,创建过程如下:
drop table if exists zjjdb.tb_test1;
create table zjjdb.tb_test1 (
f_id int(10)not null auto_increment,
f_addr varchar(255)default null,
primary key(f_id) using btree
)
engine=ndbcluster auto_increment=1 ;
2.2.2 创建磁盘表
MySQL Cluster磁盘表有以下三种:
Undo log files:存储事务进行回滚需要的信息。
Tablespaces:表空间,作为磁盘表的容器。
Data files:是与表空间相关联的数据文件。
2.2.3 数据表的分片存储
MySQL集群中的NDB表默认自动分片,分片的数量等于数据节点数目,也可手动分库分表进行分片。
2.3 住建数据导入
在数据导入之前,首先,创建好要导入的数据库及数据表结构,以规避不同数据库之间数据类型及编码差异造成数据导入的失败。有以下三种常用数据导入方式。
2.3.1 数据包导入
对接的业务科室,如果不在同一网段,则需要对方提供静态的数据,包括Excel文件、oracle数据库导出的dmp数据包、MySQL Migration Toolkit工具生产的sql文件等,将这些静态的数据包导入到集群数据库。
2.3.2 Navicat数据传输
对接的业务科室,如果可以相互ping通,则用Navicat直连,用其自带的“数据传输”工具,进行数据导入。
2.3.3 Kettle增量传输
如果对接的业务数据每天都有新增,则需要用Kettle每天增量抽取,在抽取之前,应与相关业务部门商榷,规定好时间戳字段,以便日后维护使用。
2.4 性能测试
根据业务需要,主要测试MySQL Cluster数据库并发读写能力、并发事务处理能力和吞吐能力,以及数据库的可用性和稳定性,得到集群较优配置,来满足用户对数据库的应用需求,为公司大型应用的去IOE提供科学依据。
本次测试使用的服务器CPU参数为 Intel Core i7-9700K 3.60 GHz,运行内存为32 G。
2.4.1 并发写能力测试
将数据节点的水平扩展,选择了百万和千万两种量级的数据规模,进行对数据库的并发写测试,以考察扩展数据节点对集群连续写性能的影响,测试结果如表4所示。

表4 2~4个数据节点并发写能力测试结果汇总表/s
2.4.2 吞吐能力测试
将数据节点的水平扩展,测试MySQL集群在百万和十万两种量级的高并发请求下吞吐能力的变化趋势,以考察数据节点的扩展对吞吐能力的影响,测试结果如表5所示。

表5 2~4个数据节点吞吐能力测试结果汇总表/(请求数/s)
2.4.3 并发事务处理能力测试
采用对比测试方案, 横向扩展SQL节点和数据节点,对比集群并发事务处理能力,数据规模维持在百万量级,由5个SQL客户端,测试多个用例在同一时刻并发执行。
在4个SQL数据节点情况下,横向扩展NDB数据节点,其测试结果如表6所示。
在4个NDB数据节点情况下,横向扩展SQL节点,其测试结果如表7所示。
2.4.4 可用性测试
测试MySQL集群的管理节点、SQL节点、数据节点是否存在单点故障,强制某一节点服务器关机,测试集群依然能正常运行。
2.4.5 稳定性测试
MySQL集群运行10 d以上,访问十亿余次,表现稳定。
2.4.6 测试结论
(1)横向扩展SQL节点和数据节点,集群性能近似线性增长。
(2)MySQL集群的可用性高。
(3)MySQL集群有较高的稳定性。
(4)MySQL集群横向扩展成本低,易动态扩展。
(5)扩展内存对数据节点性能影响较明显;提高CPU频率对SQL节点性能影响较明显。
3 应用总结
3.1 建立集群数据库的应用场景
已优化SQL语句及索引,且单台数据库服务器难以满足访问需求时,需建立集群数据库,将通信压力分摊到各个集群节点,可初步解决数据通信瓶颈问题。
3.2 提高数据库集群性能
面对千万级别访问量,且单机数据库服务器性能无法显著提高时,可使用多台普通性能服务器架构数据库集群,以应对数据库高并发、高负载,提高数据库可用性。
3.3 现阶段存在问题
访问量越大,请求响应速度越慢;更新或插入数据量较大时,会出现锁表和线程阻塞等。以上问题可以通过限制访问数量或者更新数据量进行规避,目前并未找到更好的解决办法。
4 结 语
本文针对济南市“住建一张图”项目的具体应用需求,提出一套基于NDB引擎的MySQL集群数据库高性能解决方案。该方案集群系统可由普通性能设备组建,由MySQL Router中间件代理流量转发,实现系统高并发和高吞吐,且同步更新每个数据节点上的分片,确保各数据节点的完整性,基本能够满足项目需要。目前,集群已完成部署测试,初步达到预期效果,且运行稳定,实现负载均衡、数据同步及故障切换。
猜你喜欢
小学生优秀作文(高年级)(2022年10期)2022-11-04
园林科技(2021年2期)2022-01-19
纺织科学研究(2021年6期)2021-07-15
军事运筹与系统工程(2019年4期)2019-09-11
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
信息化建设(2019年2期)2019-03-27
齐鲁周刊(2017年18期)2017-05-18
知识就是力量(2017年2期)2017-01-21
电脑爱好者(2015年21期)2015-09-10
