
基于深度强化学习的密集物体温度优先推抓方法*
2022-01-21 00:32李茂军胡建文赖志强李俊日
传感器与微系统 2022年1期
陈 满, 李茂军, 胡建文, 赖志强, 李俊日
(长沙理工大学 电气与信息工程学院,湖南 长沙 410114)
0 引 言
机器人的抓取在冶金、钢铁和原子能等工业中有着广泛的应用。上述工业中的抓取对象常具有形状不规则、危险系数高(高温、强辐射等)、密集堆叠等特性;有时还需优先考虑温度因素,即抓取动作需有温度优先性(在抓取过程中最大程度地优先抓取高温物体,以降低对设备与环境的危害)。这里重点考虑形状不规则、密集堆叠,需要优先考虑温度因素的动作场景,提出了一种基于深度强化学习的密集物体温度优先推抓(high-temperature priority pushing and grasping method for dense objects,TPG)方法,提高了抓取完成率和抓取成功率,并且具有优先抓取温度较高物体的能力。
1 相关研究
机器人抓取的主要方法有基于模型方法和无模型的数据驱动方法。传统的基于模型方法主要包括有Sanz P J提出的接触面建模法,通过对机器人和抓取对象的接触面进行力学建模来完成抓取操作[1],这类方法难以应用于非结构化场景。随着机器学习的发展,无模型的数据驱动方法成为了热门研究方向,主要思路是提取对象的特征,建立特征和机器人关节或末端执行器之间的映射关系,无需建立物理模型便可完成抓取任务,Zeng A等人使用全卷积网络(fully convolutional network,FCN)提取对象的特征并指导机器人抓取物体[2]。基于深度强化学习(deep reinforcement learning,DRL)的抓取方法也是一种数据驱动方法,在机器人抓取方面取得了出色的成果,Zeng A等人首次将推动和抓取动作进行联合处理,提出了基于DRL的推抓方法,得到了更好的抓取效果[3]。
本文针对密集堆叠、需要考虑温度因素的高难度抓取场景,提出了TPG方法。建立以FCN为基础的端到端映射,将红外图像添加到映射输入;建立推动和抓取的联合框架,改善了抓取效果;在奖励函数中考虑温度因素,使其适用于温度优先的抓取场景;创建温度优先度指标,评估动作的温度优先性。
2 深度强化学习简介
基本的强化学习以马尔科夫决策过程(Markov decision process,MDP)为理论框架:在t时刻获取状态st,智能体根据策略π选择并执行动作at,然后过渡到新的状态st+1并获取奖励r(st,at)。最终目的是找到一个最优策略π*,该策略可以最大化未来奖励之和
(1)
式中γ∈[0,1)为未来奖励的折扣系数。状态-动作值函数可以表示为
(2)
依据最优策略π*可以得到最佳的状态—动作值函数Qπ*(st,at),用贝尔曼最优性方程表示为[4]
(3)
式中a′为状态st+1能够执行的所有动作。
为解决传统强化学习(RL)的感知能力不强的问题,DeepMind团队提出了深度Q网络(deep Q network,DQN)模型[5]。DQN使用深度神经网络(DNN)作为非线性函数近似器来近似Q值,并通过目标Q网络计算目标值yt,以此更新Q网络参数,yt表示为
(4)
式中θ′为目标Q网络的参数。
3 密集物体温度优先推抓方法
3.1 场景分析
如图1中场景1所示,椭圆内物体之间密集排列且相互堆叠,为直接抓取造成了难度;温度优先抓取则需要最大程度地优先抓取温度较高的物体,若该物体位于堆叠物体下部,则抓取轨迹会被阻挡,普通抓取动作难以完成任务。TPG方法可以先对物体进行推动,为抓取动作提供足够的空间,部分后续抓取场景效果图如图1(b)~(d)所示。

图1 抓取场景效果
3.2 模型建立
3.2.1 TPG方法总体描述
TPG方法总体描述如下:1)首先由RGB-D相机与红外热像仪提取环境状态,经过点云匹配与正交变换转换成高度图;2)将高度图旋转16次(原因见3.2.3节),再分别经过两个FCN输出所有像素点的Q值;3)依据Q值和ε—贪婪策略指导动作,并获得奖励;4)不断通过目标Q网络进行训练。主要仿真设备环境如图2所示,TPG方法流程图如图3所示,下面分别对状态、动作、状态—行为值函数、奖励函数进行建模。
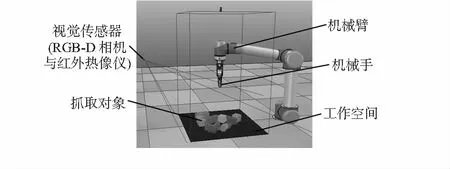
图2 仿真设备环境

图3 TPG方法流程图
3.2.2 状 态

(5)
状态st经过3D点云匹配和重力方向投影生成高度图,其中高度图的边缘是依据末端执行器的工作空间来定义的,工作空间为一个面积为S的正方形(图2中黑色区域),取S=4482mm2。
3.2.3 动 作
动作at包括三个要素:1)动作类型ω,有推动和抓取两种类型;2)动作方向f,f反映了末端执行器的旋转角度,由于直接建立从状态到旋转角度的映射较为困难,因此,将输入高度图旋转16次(每隔22.5°旋转一次),对应输出16张Q值图,采用这种方法使机器人对旋转方向的选择近似为对16张Q值图的选择;3)动作位置p,动作位置是末端执行器推动或抓取的像素点。因此动作at描述为
at={ω,f,p}
(6)
3.2.4 状态—动作值函数——FCN
使用FCN进行状态—动作值函数近似。如图3所示,设置两个FCN(推动网络χp和抓取网络χg),将推抓动作联合在同一个框架内。对两个网络输出的16张Q值图进行拼接,最终在两张Q值图(均由16张图片拼接而成)中选择最大Q值的像素点作为最佳动作点。
χp和χg具有相同前向传递结构。首先两个网络的DenseNet—121分别在ImageNet上预训练,然后经过通道级联和两个1×1的卷积层(每层包括一个批量归一化BN层和一个非线性激活函数ReLU层)。DenseNet由多个Dense Block组成,每一层的输入都与前面所有卷积层的输出有关。
3.2.5 奖励函数
(7)
式中I为红外图像的热值,L为热像仪的热平,R为热像仪的热范围,X为伪彩色值。再利用热值与绝对温度的关系,可得出对应点的温度值[6]
tp=B/log[(Aτξ/I+1)]
(8)
式中τ为透射率;ξ为物体发射率;A,B为热像仪标定曲线常数;tp为温度值。由上述式(7)、式(8)可知,抓取点伪彩色值和温度的关系为非线性关系。温度奖励Rg-hot为
(9)
式中tmax为所有像素点的最大温度值,ρ为奖励因子,取值为7.5。
综合以上三部分奖励,可得奖励函数
(10)
3.3 训练过程
使用Huber损失函数进行训练
(11)

在训练过程中使用的动量梯度下降方法,具体参数为:动量0.9,权重衰减2-5,学习率10-4;未来奖励折扣γ恒定为0.5;使用优先经验重播方法,对于不同的经验集设置不同的采样权值,采样权值与经验集的时间差分有关;使用ε—贪婪策略,贪婪因子ε为随机选择下一步动作的概率,在前500次动作中取值为0.5,在500~1 500次动作中从0.5逐步衰减到0.1,并在后续训练中保持不变。
综上可得基于深度Q网络的机器人密集物体温度优先推抓决策算法,用该算法进行训练,算法流程图如图4所示。

图4 算法1流程图
输入:未来奖励折扣γ、学习率、权重衰减、动量、目标网络权重参数更新周期;
初始化:容量为N的记忆池D;初始化经验集;初始化Q网络并随机权重θ;初始化目标Q网络和权重θ′,使θ′=θ
Begin
1)For episode=1,Mdo
2)初始化机器人工作空间,获取初始状态s1
3)Fort=1,tmaxdo
4)使用ε—贪婪策略选取动作
5)执行动作at,过渡到新状态空间,st+1并获得奖励r(st,at)
6)如果记忆池D的经验集为N,则删除最早的经验集
7)组成经验集〈st,at,r(st,at),st+1〉存入D中
8)更新经验集的被采样概率
9)使用优先经验重播方法从D中抽取一个经验集j
10)依据经验集j计算目标值yj
11)ifsj+1为最终状态
yj=rj+1
else
yj=rj+1+γmaxa′Qθ′(s′,a′)
12)使用动量梯度下降方法更新Q网络的权重参数θ
13)隔C步更新一次目标Q网络权重参数,使θ′=θ
14)更新贪婪因子ε// 500~1 500次迭代
15)End for
16)End for
End for
4 实验与结果分析
4.1 仿真实验
使用RTX 2080Ti显卡进行训练,使用V-REP仿真软件中的UR5机械臂和RG2机械手进行动作,使用内部的V-REP逆运动学模块进行运动规划。为了建立与实际场景相似的环境,每次生成温度、颜色、形状随机的10个物体。
4.2 训练实验与结果分析
对TPG方法进行了2 500次训练,并绘制训练过程中的抓取成功率曲线图(图5)。

图5 机器人抓取训练过程曲线
由训练结果可以看出,随着机器人迭代次数的增加,抓取成功率逐渐上升,其中前500次训练过程上升效果最为明显,说明机器人使用TPG方法在该场景下的抓取效果逐渐变好。
4.3 测试实验与结果分析
设置三组测试实验:TPG方法,无红外图像与温度奖励(no temperature factor,PG)方法,无推动(no pushing,TG)方法。对于每组测试实验进行40次重复测试,每次实验设置10个随机物体,均在工作空间内密集堆叠放置5组,计算平均结果。测试实验的结果也与文献[4]中的结果进行对比。
设置四个主要评价指标:1)平均完成率C;2)平均抓取成功率GC;3)温度相关度TR,表征机器人抓取动作对高温对象的优先性,具体公式为
(12)

E=num(obj)/num(all)
(13)
式中num(obj)为抓取对象的数量,num(all)为所有动作数量之和。
由表1可知,TPG方法、PG方法和VPG方法均可以成功抓取所有物体,而TG方法存在抓取未完成现象,这表明推抓方法在整体完成率上要由优于仅抓取方法。平均抓取成功率GC方面:TPG方法和PG方法分别高于TG方法11.2 %和8.6 %,表明推抓方法可以提升抓取成功率,此外TPG方法的GC分别高于PG方法和VPG方法2.6 %和1.7 %,TG方法的GC高于Grasping-only方法2.4 %,这是由于红外图像的加入丰富了输入特性,有利于机器人充分提取环境信息,从而选择更好的动作,提升抓取成功率。

表1 测试实验结果对比 %
平均温度相关度TR方面:TPG方法和TG方法均显著高于PG方法,PG方法仅为-6.3 %,这符合无温度奖励情况下TR期望为0的预期,说明加入红外图像和温度奖励后,温度优先性得到显著提高;TPG方法的TR高于TG方法18.4 %,这是由于TG方法没有推动动作,而部分温度较高物体位于堆叠物体下部,抓取轨迹受到阻挡,TG方法难以优先抓取高温物体。平均动作效率E方面:TPG方法和PG方法分别高于TG方法4.5 %和8.9 %,这表明推抓方法的动作效率优于仅抓取方法,值得注意的是,TPG方法相比于PG方法和VPG方法有所降低(分别为4.4 %和3.6 %),这是由于TPG方法考虑了温度因素,需要执行推动动作为温度较高物体创造足够的抓取空间,从而导致num(all)上升,动作效率E下降。
由上述实验结果和分析可知,本文提出的TPG方法对温度优先的密集物体抓取场景具有较好的效果。TPG方法和PG方法在完成率、抓取成功率和动作效率方面均优于TG方法。虽然TPG方法的动作效率E相比于PG方法略有降低,但是平均温度相关度TR明显优于PG方法,因此,在温度优先抓取的场景下,TPG方法不失为一种较好的选择。
5 结 论
对于物体密集堆叠、需要优先考虑温度因素的高难度抓取场景,提出了TPG方法。该方法以DRL为基础,使用两个FCN,将推动和抓取放在一个框架内联合动作,并设置温度奖励,使抓取具有温度优先性。仿真实验结果表明:该方法抓取效果优于无推动的方法,并且具有优先抓取温度较高物体的功能。
猜你喜欢
文苑·感悟(2019年8期)2019-08-06
文苑(2019年15期)2019-08-01
时代英语·高一(2016年4期)2016-09-21
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
科普童话·百科探秘(2015年4期)2015-05-14
小说月刊(2014年12期)2014-04-19
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
