
一种多模特征融合的方面信息情感分类方法
2022-01-20 06:08范守祥姚俊萍李晓军程开原
应用科学学报 2021年6期
范守祥,姚俊萍,李晓军,程开原
火箭军工程大学301 教研室,陕西西安710025
方面信息情感分类是方面级别情感分析的重要任务,其目的是判断给定文本中目标方面信息在上下文环境下的情感极性,基本思路是将目标方面信息的情感特征转化为数值特征以便进行自动分类,重点是解决相同文本中不同目标方面信息差异情感对应问题。比如在评论文本“The food was mediocre and the service was severely slow.”中,方面信息“food”和“service”分别对应了中性和负面的情感属性。早期研究主要使用情感词典匹配以及传统机器学习如支持向量机等分类方法,随着深度学习方法在各领域的广泛使用,方面情感领域也产生了各种基于循环神经网络(recurrent neural network,RNN)、卷积神经网络(convolutional neural network,CNN)、记忆网络(memory network,MN)、胶囊网络的情感分类方法。在这些方法中,注意力机制往往作为一种重要的信息筛选机制引入神经网络模型设计,起到提取情感信息特征的重要作用。
基于深度学习的方面信息情感分类方法优势在于可以自动提取方面信息情感特征,而无需人工构建特征集,模型经训练后可以达到较高的分类准确度。但此类方法同样存在一些问题,比如,目前在方面信息情感分类领域常用RNN 进行信息底层编码,虽能保留序列中的上下文信息,但随着序列长度的增加,信息传递过程中的丢失现象也更加严重[1],致使不同方面信息的情感特征差异严重弱化,导致多方面信息文本情感分类准确度降低。此外,注意力机制虽然能够模拟获取信息过程中不同信息重要性差异,但存在过于关注高频信息[2],忽略低频有益信息的问题,在方面信息情感分类任务中会导致两方面问题:一是多方面信息文本中不同方面信息情感同质化、中性方面信息情感化问题;二是除高频信息以外的外围信息在方面信息情感特征表示中的作用较弱,无法较好地提取非单一情感词表示的复杂方面情感特征。
针对上述存在的问题,本文提出一种多模特征融合的方面信息情感分类方法。将文本中方面情感信息分为单点情感信息、多点情感信息以及局部情感信息三类情感信息表达模式。首先利用传统注意力机制倾向于关注高频词语的特点提取并编码单点情感信息,并利用注意力分值与长度控制参数截取离散的多词组合作为多点情感信息,通过介词、连词以及符号等的位置信息确定局部情感信息;而后利用RNN 对提取的多点与局部情感信息进行编码,有效降低编码序列长度,融合三类情感信息特征形成最终方面信息情感的特征表达;最后在数据集上进行训练,优化注意力分布,使模型适应多种方面情感信息表达模式,提高对复杂情感表达的分类准确度。实验表明,本文提出的方面信息情感分类方法能够使分类效果得到较大提升。
1 方面信息情感分类方法研究进展
神经网络模型可以将原始文本特征提取为抽象特征,用于文本语义分析或情感分析。在方面信息情感分类任务中,需要将文本中的情感信息传播到最终特征表示中,最早文献[3]提出一种自适应递归神经网络(adaptive recursive neural network,AdaRNN)模型,可以通过上下文和句法结构将情感信息传播到最终特征表示中,解决目标依赖的情感极性分类问题。随着深度学习技术应用的深入,利用该技术进行方面情感分析受到越来越多关注。
目前使用基于深度学习的方法解决方面信息情感分类问题主要有以下3 种思路。1)从文本整体语义中提取方面信息情感特征。文本语义是情感的载体,于是可以把语义特征作为情感特征对方面情感极性进行分类。比如文献[4]利用长短时记忆(long short-term memory,LSTM)网络可以捕获序列语义信息的特点,提出了TD-LSTM(target-dependent long short-term memory)和TC-LSTM(target-connection long short-term memory)两种构建特定方面信息情感特征的方法,构造两个分别从句子左侧和右侧捕获语义信息且将方面信息分别作为语义传播终点的LSTM 网络,并将两个网络序列末尾的隐层串联起来形成最终情感特征表示;文献[5]利用CNN 的特征抽取能力抽取文本的情感特征,使用序列方向上最大池化操作进一步剔除不重要的情感信息,获取了方面信息情感的特征表示,解决了LSTM 网络结构复杂及序列依赖等问题;文献[6]认为与方面信息相关的情感语义往往是连续词语组成的语块而非孤立词语,提出利用双向LSTM 网络(Bi-LSTM)和条件随机场(conditional random field,CRF)注意力相结合产生方面情感特征的方法。2)利用方面信息与上下文关系提取方面情感特征。表达方面信息情感的往往是句子中具有强烈情感信息的部分,如具有修辞关系的形容词或短语。文献[7]利用MN 多层注意力机制多次从记忆中提取情感信息;文献[8]使用注意力机制从两种不同的记忆模块中分别提取与方面信息相关的单词级和短语级情感信息;文献[9]提出使用交叉注意力使上下文与方面信息中词语相互关注生成有侧重的方面情感特征的方法;文献[10]提出在底层Bi-LSTM 编码的不同位置加入不同类型注意力机制,从不同角度提取上下文情感信息,且融入方面语义信息提升情感分类能力。3)考虑句间关系提取方面情感特征。在方面情感分类任务中,常将整个评论或者方面信息所在句子作为分析对象,但句间关系对方面的情感信息也有很大影响。比如文献[11]利用分层LSTM 网络获取句内与句间信息,且利用注意力机制分别提取方面信息的局部与整体特征;文献[12]提出一种双层Bi-LSTM 模型,第1 层Bi-LSTM 网络捕获句子内部的情感信息,而第2 层Bi-LSTM网络捕获其他句子传递来的情感信息;与之类似,文献[13]根据标点符号和一些连词将评论切分为独立子句,在双层Bi-LSTM 网络结构基础上,在各层中加入注意力机制,兼顾句内与子句间重要情感信息。
与上述方法和思路不同,本文使用门限循环单元(gated recurrent unit,GRU)网络以及注意力机制作为情感信息提取的基本工具,在多点情感信息获取上,通过注意力分值和预设长度参数控制序列离散情感信息的选择与截取,克服常规注意力机制在提取情感信息时过度倾向于高频信息的问题,优化注意力在离散情感信息上的分布情况,同时利用GRU 网络对提取的多点情感信息进行编码,减少长序列信息在编码中的信息丢失的问题,提高序列情感信息编码效果。在局部情感信息上,虽然与文献[13]相类似使用连词与符号对文本进行分割,但关注点不同,且本文利用介词对文本进行分割,重点关注情感信息的局部连续性以及封闭性。通过对三类情感信息特征的提取与有效整合,达到提高方面信息情感分类效果的目的。
2 多模特征融合的方面信息情感分类模型
本文提出一种多模特征融合的方面信息情感分类模型,分别对单点情感信息、多点情感信息以及局部情感信息三类方面情感信息进行提取与编码,并融合三类情感信息特征形成最终目标方面信息情感特征表示。使用双层双向GRU 网络(Bi-GRU)对文本进行初始编码,利用注意力机制对单点情感信息进行提取、利用单点情感信息提取过程中的注意力得分以及预设长度控制参数获取多点情感信息,再利用位置信息定位局部方面情感信息。接下来对上述三类情感信息提取与编码过程进行详细描述,模型整体结构如图1所示。
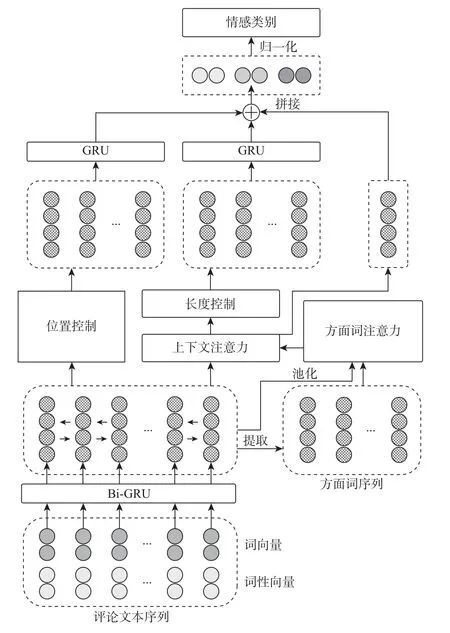
图1 模型总体结构图Figure 1 Overall structure diagram of the model
2.1 问题描述与符号说明
方面信息情感分类是在给定具有方面信息情感表达的文本序列S={x1,x2,···,xn}以及句中方面信息序列A={xn-i,xn-i+1,···,xn-i+k}(k≤i) 条件下,判断方面信息A的情感极性C属于{正面、负面、中性} 的问题。为便于模型描述,文中使用E={e1,e2,···,en}表示文本序列对应词向量矩阵,使用P={p1,p2,···,pn}表示文本序列对应的词性向量矩阵。
2.2 单点情感信息特征提取
单点情感信息特征提取针对文本中使用单一情感词承载情感信息的模式进行特征提取。传统注意力机制倾向于关注高频信息,基于这一特点,本文将此类高频信息作为单点情感信息。同时,对于构建方面信息情感特征来说,重点是建立具有当前方面信息特殊性的情感特征,一般做法是引入当前方面信息特征到方面信息情感特征中。在此,本文借鉴文献[7]构建当前方面信息情感特征的方式,将方面信息特征与情感特征点对点相加。在底层,使用Bi-GRU 对文本序列进行编码,使用输出层作为序列中每个词的当前特征表示,使每个词语融入上下文信息,更好地适应当前语句的整体语义。在文本序列中加入词性信息,有助于模型加强依据词性信息选取情感信息的能力。单点情感信息具体计算过程如下:
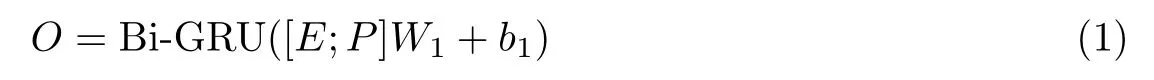

式中:“;”表示词向量与词性向量在特征方向上的拼接操作,O ∈R2n表示文本序列的输出向量矩阵,n表示GRU 网络隐状态大小,t ∈Rn为当前方面信息融入情感特征后的特征向量,d(S,A) 为注意力衰减系数,s ∈Rl表示当前方面信息对文本序列中各词的注意力分值,c ∈Rn表示当前方面信息的情感特征向量,l表示当前文本序列长度,W1,W2∈R2n×n,b1,b2∈Rn为可学习参数。在计算t时,利用式(3)~(5) 反复提取特征3 次,得到t最终特征表示,并将其作为单点情感信息特征表示。t的初始输入为当前方面信息特征向量,由于方面信息本身经常出现多词表达形式,其中的每个单词在整体方面信息含义中所起作用并不相同,故方面信息特征向量同样采用注意力机制进行计算,公式如下:
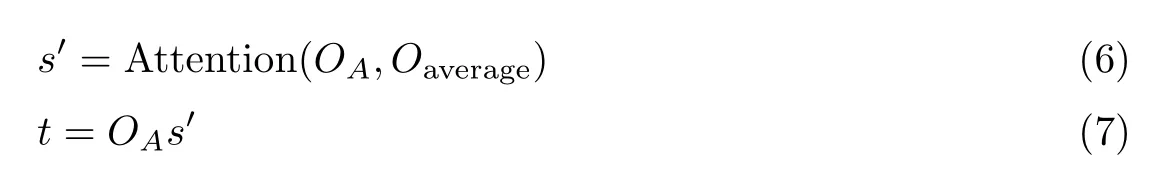
式中:OA为从输出向量矩阵中提取的方面信息特征向量矩阵,Oaverage表示输出向量矩阵沿序列方向求均值得到的文本整体含义特征向量。一般而言,与当前方面信息相关的情感信息位于其较近范围内,比如修辞关系、主系表关系等,故在式(3) 计算注意力分值时加入衰减系数1/d(S,A),对注意力分值进行修正,d(S,A) 通过lg(10+Δ) 进行计算,Δ表示文本序列中各词与方面信息距离,对于多词方面信息,以方面信息首尾词作为距离计算基准。

文本中单个词语注意力采用如下方法:
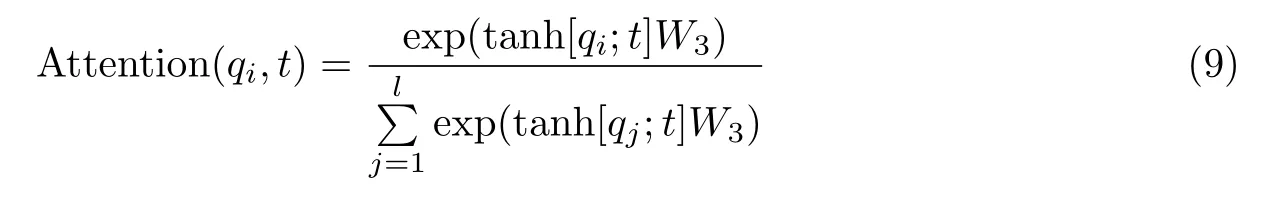
式中:“;”表示向量在特征方向上的拼接操作,W3∈R2n为可学习参数。
2.3 多点情感信息特征提取
在文本情感实际表达过程中,一方面,除了经常使用单一情感词表达当前方面信息情感外,也常表现为文本中多个离散词语共同决定当前方面信息情感的表达模式。此时,情感载体并非简单的具有情感信息的单一词语,而是呈现出诸如叙述、比喻、反问等更加复杂的情感表达模式。比如在文本“we requested they re-slice the sushi,and it was returned to us in small cheese-like cubes.”中,方面信息“sushi”的情感并不能借助其中的某个词语来表达,而是融入到语义的叙述中。另一方面,根据对句子的理解,文本中承载情感信息的词语并不是所有词语,而是其中一部分,这说明句子可以被简化为包含核心情感以及语义词语的简洁形式。比如在上例中,“requested re-slice returned small cheese-like cubes”这些词语所构成的语义叙述核心基本决定了方面信息“sushi”情感极性为负向情感。在不同的句子中,对情感信息表达没有贡献的词语数量不同,但对情感表达发挥作用的词语却是有限的,可以在一定程度上进行量化,故可以通过控制参与情感表达的核心词语长度来增强方面信息情感特征的差异化水平,降低非情感信息在特征提取过程中对情感特征的不良影响。基于上述两种考虑,本文设计了结合注意力分值提取定长情感信息的多点情感信息提取策略,并将这些定长情感信息输入到GRU 网络中进行编码,得到多点情感信息的特征表达。计算过程如下所示:

式中:函数f(O,s,η) 表示从当前文本序列特征向量矩阵O中,按照s中注意力分值由高到低排序,提取前η个词语对应特征向量表示,即Oη ∈Rn×η作为当前文本序列的简化特征表示形式;hη ∈Rn表示Oη输入单向GRU 网络后得到的隐状态向量,作为当前文本序列的多点情感信息特征表示。
2.4 局部情感信息特征提取
情感信息具有一定的封闭性,即情感信息存在于相对完整的语义表述单元中。在多方面信息的文本中,适当切割文本将每个方面信息的情感信息封闭在各自的子句空间中,可以对方面信息情感分类起到很好的促进作用。之前的研究大多在修辞结构分析的基础上以连词和标点符号作为分割子句的标志,比如文献[13]利用了连词对句子进行切分。在对方面情感信息进行建模研究过程中,本文对具有错误分类结果的样本进行了大量分析,发现在具有中性情感的方面信息情感判断上存在较大问题。中性方面信息往往没有相应的情感词语作为表达,常存在于条件、陈述事实等表达模式中,此时使用注意力机制往往因关注高频信息而产生情感极性判断错误的问题。比如在文本“the sauce is excellent(very fresh) with dabs of real mozzarella.”中,“dabs of real mozzarella”是具有中性情感极性的方面信息,但是常规注意力会将分值更多地分配给具有显著正向情感信息的“excellent”,导致该方面信息情感极性判断错误。可以看出,方面信息“dabs of real mozzarella”仅仅作为该句中另一个方面信息“the sauce”表现为正向情感极性的条件,本身不具有正向或负向情感。针对这个问题,本文提出在方面信息的整体特征表示中加入了局部情感信息特征编码,可以增强对此类情感特征判断能力。在实际处理过程中,根据当前方面信息的位置信息,使用预定义分割控制信息,按照就近原则选择距离当前方面信息最近的分割控制信息,确定局部情感信息序列,并将该文本序列输入到GRU 网络中进行编码,得到局部情感信息的特征表达。具体计算过程如下:

式中:函数g(O,p,λ) 表示局部情感信息序列截取操作,p表示当前文本序列对应的词性序列,λ ∈{“,′′,“.”,“WP”,“WDT”,“CC”,“IN”,“WRB”,“WP$”} 表示预定义分割控制信息,Oλ ∈Rn×η′表示当前方面信息局部情感序列特征矩阵,hλ ∈Rn表示Oλ输入单向GRU网络后得到的隐状态向量,作为当前文本序列的局部情感信息特征表示。
2.5 特征融合与模型训练
通过上述模型计算后,可以得到当前方面信息的单点情感信息特征、多点情感信息特征以及局部情感信息特征,将此三类特征进行拼接作为当前方面信息最终的情感特征表示,使当前方面信息特征中融入三类情感表达模式的特征信息,而后对此特征进行情感分类,分为正向情感、负向情感以及中性情感三类,具体计算过程如下:
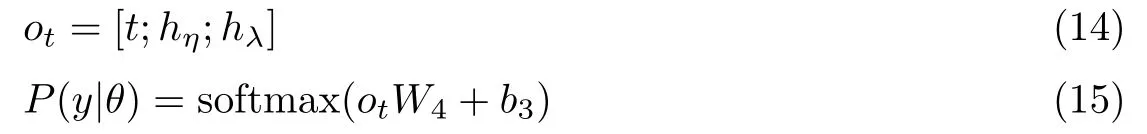
式中:“;”表示三类情感特征在特征方向上的拼接操作,ot ∈R3n表示当前方面信息最终情感特征表示,P(y|θ)∈R3表示当前方面信息预测的情感极性概率分布,y={positive,neutral,negative},θ表示模型中所有参数,W4∈R3n×3,b3∈R3为可学习参数。最终,通过交叉熵计算模型损失并对模型参数进行训练,其中模型参数的函数为
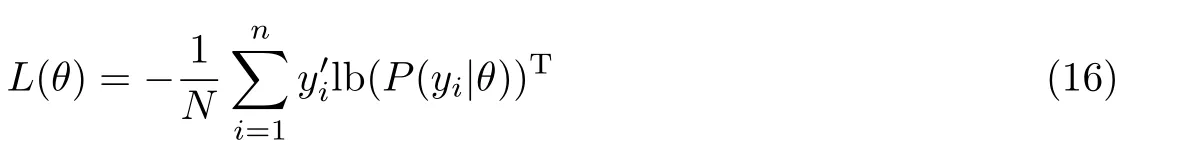
式中:y′表示标准情感类别对应索引值。在当前方面信息中融入三类情感表达模式的特征,可以优化模型在训练过程中注意力分布,弱化其中某一类情感表达模式特征的错误对整体分类效果的影响,达到提高分类精度的目的。
3 实验部分
3.1 实验数据与设置
本实验采用SemEval-2014 任务4[14]中的评论数据集,包含Laptop 评论数据集和Restaurant 评论数据集,该数据集是方面情感分析领域使用最为广泛的数据集。采用与文献[1]实验相同的处理方式,去除掉数据集中具有“Conflict”标签的评论样本,故数据集中样本情感标签类别分为“Positive”“Neutral”“Negative”三类,详情参见表1。评论预处理过程中使用NLTK(Natural Language Toolkit)[15]将文本分割为单词序列,使用斯坦福大学的自然语言处理工具包Stanford-CoreNLP[16]对评论文本进行词性解析,获取单词词性信息。
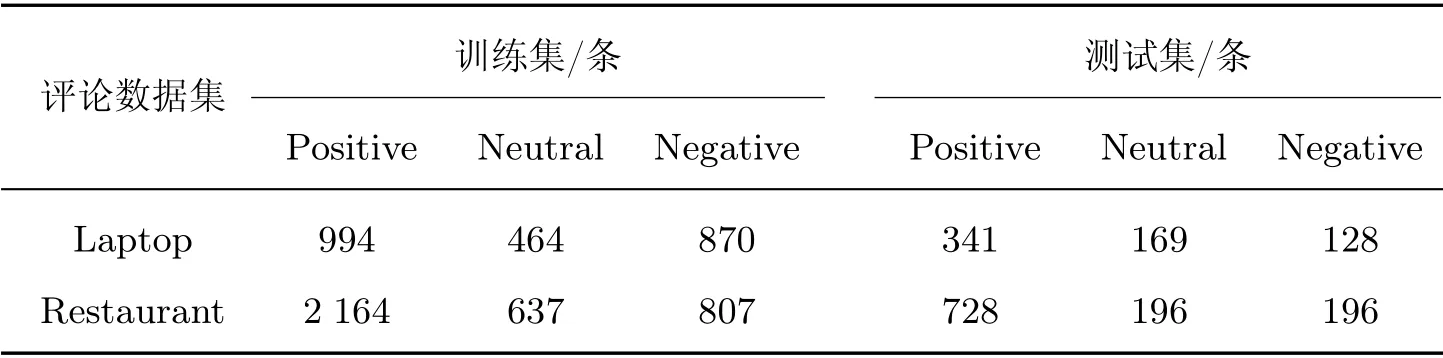
表1 样本数据信息统计表Table 1 Statistical of sample data
为提高模型通用性与实验可对比性,词向量以及词性向量使用300 维Glove 预训练词向量进行初始化,未登录词以及词性标签采用随机初始化。模型中所有GRU 网络隐层大小设定为300,采用dropout 策略防止参数过拟合,dropout 率设定为0.1,batch 大小设定为32,使用Adam 优化算法[17]更新模型参数,学习率设定为0.001。使用准确率与F1 值作为评价指标。
3.2 对比方法
为充分评估模型的有效性,将与下列3 类方法进行对比,第1 类为基于RNN 或注意力机制的方法,即单独使用RNN 或注意力机制提取方面情感信息的方法;第2 类为基于RNN 和注意力机制的方法,即同时使用RNN 以及注意力机制提取方面情感信息的方法;第3 类为其他方法,包括使用卷积网络或知识迁移等方法。
3.2.1 基于循环神经网络或注意力机制的方法
1)TD-LSTM[4]:利用LSTM 网络分别从文本序列首尾两个方向开始进行序列情感信息编码过程中,并将目标方面信息作为信息传递的终点,得到特定目标方面信息情感特征。
2)记忆网络(memory network,MemNet)[7]:利用注意力机制多次从记忆空间中抽取方面情感信息,最终形成方面情感信息特征表示。3)注意力编码网络-全局向量(attentional encoder network-global vectors,AEN-GloVe)[18]:使用注意力机制替代RNN 对文本信息进行编码,提取有效方面情感信息,从而以较轻量的模型以及资源占用提供有效的方面信息情感分类结果。
3.2.2 基于循环神经网络和注意力机制的方法
1)ATAE-LSTM(attention-based LSTM with aspect embedding)[19]:在LSTM 网络的输入和输出端均加入方面信息特征表示,强化方面信息对其特定情感信息传递的控制,并通过注意力机制对情感信息进行提取,形成最终方面信息情感分类特征表示。
2)交互注意力网络(interactive attention networks,IAN)[9]:使用LSTM 网络和注意力机制作为基本编码组件,通过在上下文与方面信息之间相互学习注意力,分别得到上下文以及方面信息的特征表示,而后将两者拼接得到当前方面信息的情感特征表示。
3)RAM(recurrent attention network on memory)[1]:使用Bi-LSTM 网络编码文本序列构造记忆信息,并通过位置权重适配针对当前方面信息的记忆,而后通过多层以非线性方式相连接的注意力机制获取方面情感信息分类特征表示。
4)LSTM+SynATT+TarRep[20]:使用预定义目标方面信息加权和对当前目标方面信息进行重新表示,并在注意力机制中融入句法信息,底层使用LSTM 进行编码。
3.2.3 其他方法
1)门控卷积网络(gated convolutional network with aspect embedding,GCAE)[5]:使用不同大小卷积核提取文本中语言模式信息,并通过Tanh-Relu 门单元过滤出情感信息,构建当前方面信息情感分类特征表示。
2)PRET+MULT[21]:使用LSTM 和注意力机制作为底层编码组件,通过共享预训练模型参数以及多任务学习两种方式将文档级别的情感分类信息迁移到方面级别情感分析任务中,达到增强分类效果的目的。
3)TransCap(transportation system capability)[22]:通过构建迁移胶囊网络,将文档级别的情感标注信息迁移到方面级别情感分类任务中,以此来增强方面信息情感分类效果。
3.3 实验结果与分析
本文提出方法与对比方法的性能情况如表2所示。在表2中,带“#”的测试数据取自文献[1],带“*”的测试数据取自文献[22],其余数据取自各自论文中实验结果数据,分项最高分值使用加粗字体标记;测试结果数据在长度控制参数η=6 条件下得出。总体上,从表格中可以看出,本文提出方法在所有方法中呈现出较高性能水平。同时,所有方法都存在Restaurant 评论数据测试结果好于Laptop 评论数据测试结果情况,说明在方面信息情感表达模式上,Laptop 评论比Restaurant 评论更加灵活多变,规律性更难被模型学习。另外样本数据的不平衡性也可能是导致这种现象的原因之一。
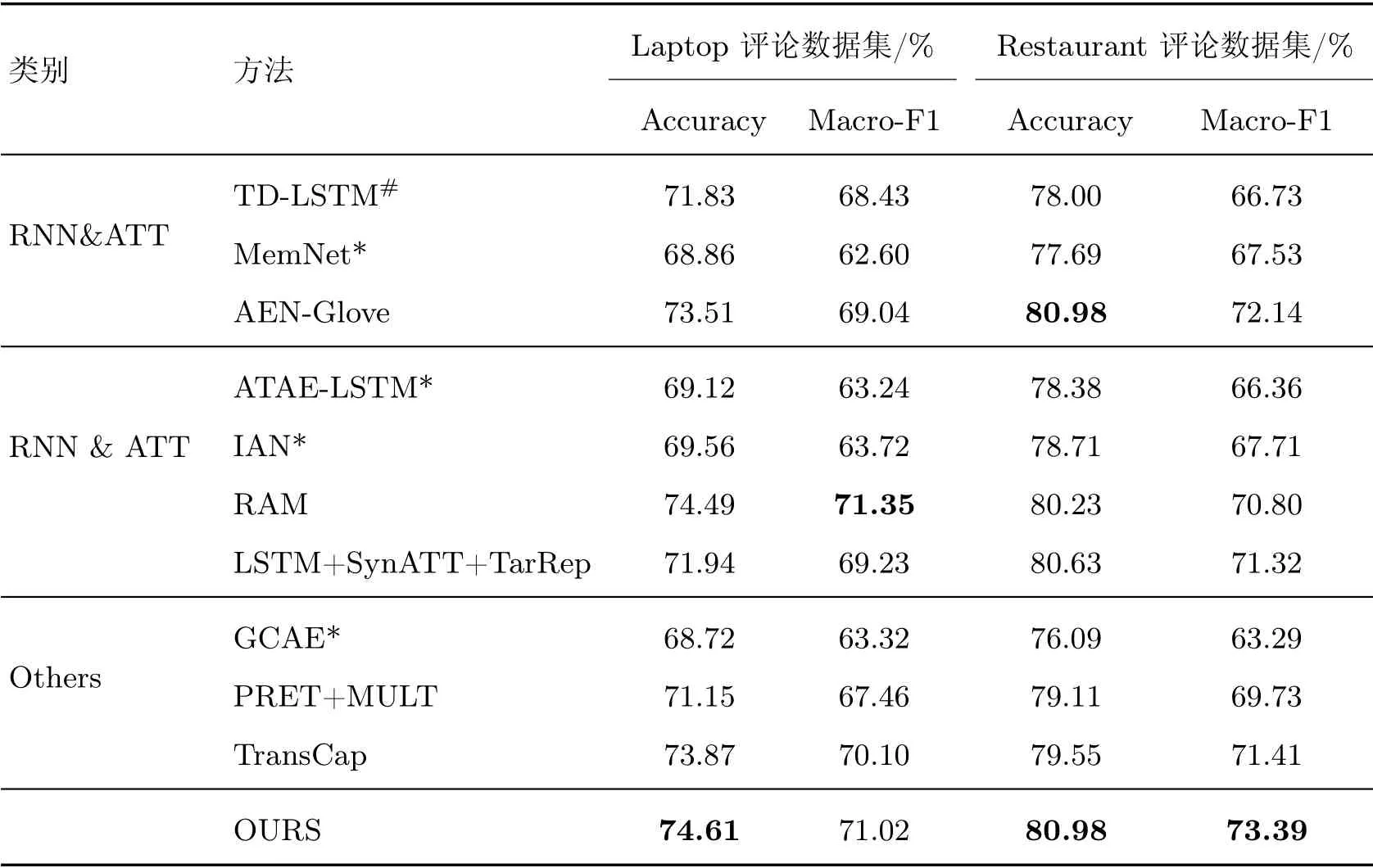
表2 方法性能对比统计表Table 2 Statistical of method performance comparison
在“RNN&ATT”类方法中,TD-LSTM 方法仅使用了LSTM 网络对文本信息进行编码,在构建区分不同方面情感信息能力上将方面信息作为Bi-LSTM 编码终点,但仍无法摆脱长距离文本信息在LSTM 网络编码过程中的信息丢失问题;在MemNet 方法中,仅使用多层注意力从记忆中提取情感信息,由于注意力本身倾向于关注高频信息,且在多层注意力之间特征使用线性方式连接,使得该方法对正确情感信息的提取以及不同方面情感信息的区分能力均偏弱,在两个数据集的测试结果上,与本文提出方法在准确率上的差距分别达到5.75%、3.29%,在F1 值指标上的差距分别达到8.42%、5.86%;AEN-Glove 方法虽未使用LSTM 网络作为模型编码组件,但是使用了Intra-MHA(intra multi-head attention)和Inter-MHA(inter multi-head attention)两种注意力机制分别对上下文以及方面信息进行编码,且在注意力编码组件中加入了逐点的卷积变换操作进一步提取情感特征,整体性能水平比MemNet 有较大提升,在Restaurant 评论数据集上的测试准确率与本文提出方法相同,但在F1 值指标上,两个数据集的测试结果上均弱于本文方法,分别存在1.98%、1.25% 的差距,说明在不同情感表达模式中正确提取情感信息的综合能力上不如本文所提出方法。
在“RNN & ATT”类方法中,4 种方法均同时使用了LSTM 网络以及注意力机制构建模型,但都仅将LSTM 网络作为底层编码组件,借以在各词的特征表示中融入当前上下文信息,以便更好地适应当前语义环境。而本文在使用LSTM 网络对文本进行底层编码的基础上,在多点情感信息以及局部情感信息的顶层特征表达上同样使用了LSTM 网络提取情感特征,充分利用其对短距离序列情感信息的优异提取能力,故综合性能水平均优于此类中4种方法。ATAE-LSTM 方法与IAN 方法在模型架构上较为相近,但IAN 方法中引入了交互注意力机制,根据上下文对方面信息进行了重新编码,使得测试结果略好于ATAE-LSTM 方法;RAM 方法与本文提出方法在性能水平上较为接近,原因在于构建记忆组件时不仅使用了LSTM 网络融合上下文信息,而且加入了位置权重,在多层注意力使用上层间采用非线性连接,提高了对多方面情感信息识别能力;LSTM+SynATT+TarRep 方法在注意力使用上借助了句法信息,但目前句法信息解析易出现错误,导致在利用此类信息时实验结果会出现波动;本文在模型中加入了词性信息,虽也存在受词性解析结果错误影响的问题,但利用了多模特征的相互确认与纠正得到一定改善,使综合性能得到一定提升。
GCAE 方法仅使用卷积网络以及特定门机制提取情感信息,虽然它的性能较弱,但其并行性好、计算速度快;PRET+MULT 方法和TransCap 方法中均利用了文档级情感标注数据提升方面级情感分析任务,对于提升文本特征融合上下文信息的能力具有积极意义,但在应对多样情感表达模式的情感判断上能力较弱。
3.4 参数η 对提取效果的影响
直觉上,文本中影响当前方面信息情感极性的词语是有限的。为进一步分析多点情感特征提取过程中长度控制参数η对情感特征提取效果的影响,本文使η在[2,8]范围内变化,得到如表3所示的实验结果。从表3中可以初步看出,当长度控制参数η=6 时,得到各数据集测试最佳性能值。当2 ≤η<6 时,测试性能指标呈现波动上升趋势,而当6<η≤8 时呈现下降趋势。初步分析认为,在长度控制参数小于最佳参数值时,保留的多点情感信息缺乏不同方面信息情感极性区分能力,容易丢失重要情感信息,致使性能指标下降,而在大于最佳参数值时,由于保留的多点情感信息中掺杂部分无用信息,弱化了有益情感信息在最终方面信息情感特征表示中的作用,导致性能指标出现下降。
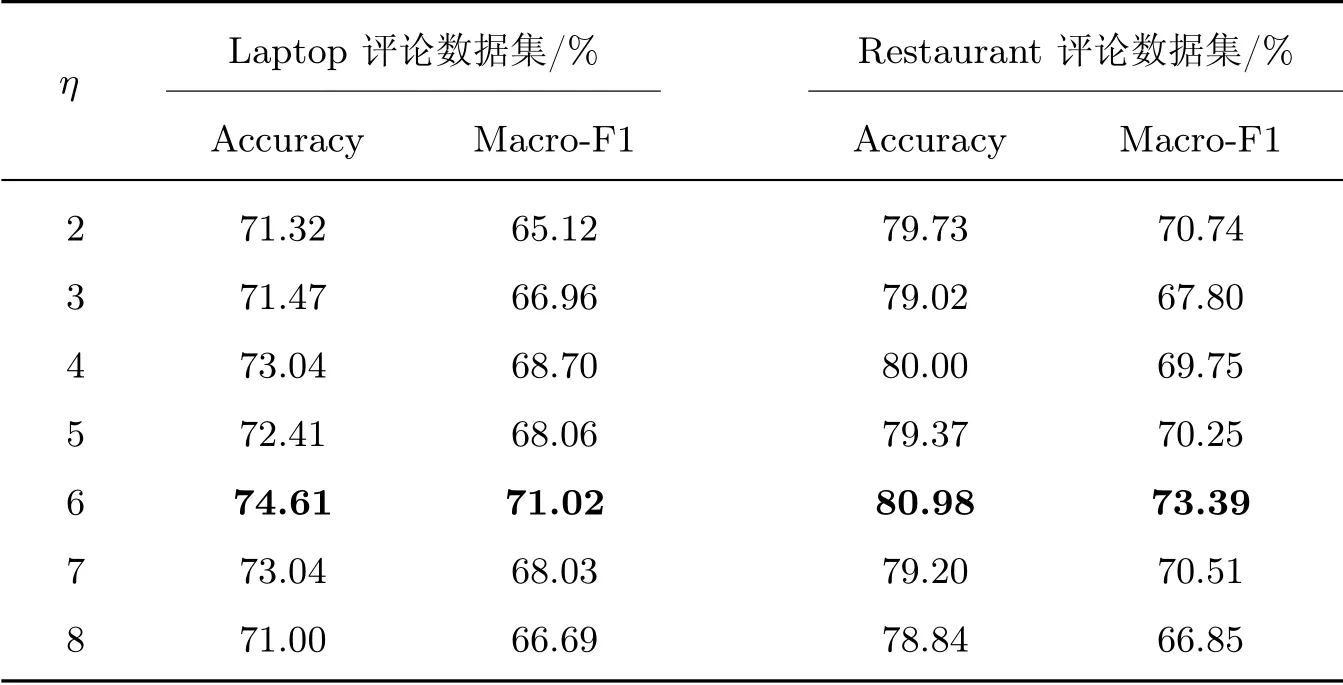
表3 长度控制参数效果Table 3 Results of length control parameter
3.5 消融实验
为进一步验证所提方法在最终方面情感特征融入各类特征有效性,本文进行了相关消融实验,主要包括排除单点情感特征实验(OURS-w/o-SSR)、排除多点情感特征实验(OURS-w/o-MSR)、排除局部情感特征实验(OURS-w/o-PSR)、排除多点与局部情感特征实验(OURS-w/o-MSR&PSR)、排除单点与局部情感特征实验(OURS-w/o-SSR&PSR)、排除单点与多点情感特征实验(OURS-w/o-SSR&MSR),具体实验结果如表4所示,其中,包含多点情感特征(MSR)实验测试结果数据在长度控制参数η=6 条件下得出。
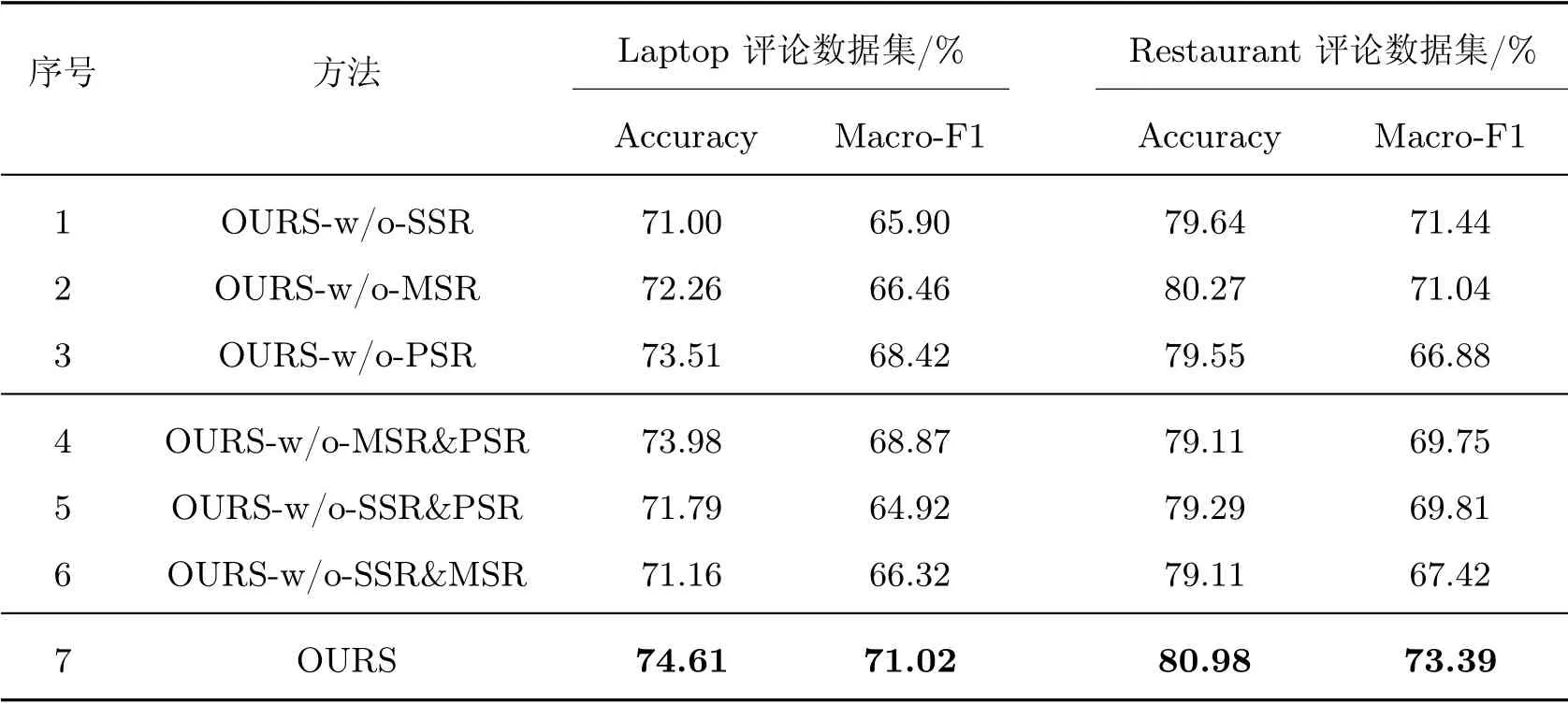
表4 消融实验结果Table 4 Ablation results
从上述实验结果可以看出,排除三类情感特征中的任意一种或两种,性能指标均出现不同程度下降,表明三类特征对文本中方面信息情感极性判断均发挥重要作用。在Laptop 评论数据集测试结果中,在分别排除了SSR(1)、MSR(2)、PSR(3) 情感特征后,准确率与F1值出现上升趋势,而在分别保留SSR(4)、MSR(5)、PSR(6) 情感特征后,准确率与F1 值出现下降趋势,初步表明在Laptop 评论数据集中,SSR、MSR、PSR 特征对最终方面信息情感极性判断发挥作用依次减弱。在Restaurant 评论数据集测试结果中,仅排除PSR(3) 与仅保留PSR(6) 情感特征均出现同类组中最差性能指标结果,表明上述情感特征并非独立发挥作用,而是在相互关联中发挥作用,既相互印证又弱化彼此出现错误对整体性能的影响。为进一步说明模型在解决多方面信息文本中不同方面信息情感同质化、中性方面信息情感化问题的效果,在消融实验的基础上对多方面信息文本(MUL_AS)、多方面信息且存在不同极性情感类别的文本(MUL_DIF_AS)以及中性情感极性文本(NEU_AS)的情感分类性能进行了统计,具体数据见表5,其中Laptop 数据集对应上述三类文本数量分别为367、101 和169,Restaurant 评论数据集相应文本数量为818、219 和196。从表5可以看出,在两个数据集上,均表现出保留情感特征的种类越多、分类效果越好的情况,说明各类情感特征在解决不同方面信息情感同质化、中性方面信息情感化问题上发挥重要作用;在MUL_AS、MUL_DIF_AS、NEU_AS 文本中,情感分类的性能呈现明显下降趋势,说明三类文本情感分类难度逐渐增加;在仅保留SSR(4、11)情感特征的实验中,文本情感分类性能基本均为最低水平,说明MSR 和PSR 在多方面信息以及中性方面信息的情感分类上发挥重要作用,同时在去除PSR(3、4、5、10、11、12)情感特征的实验中,中性方面信息情感分类水平均处于较低水平,再次说明了其在中性方面信息情感分类上发挥的重要作用。
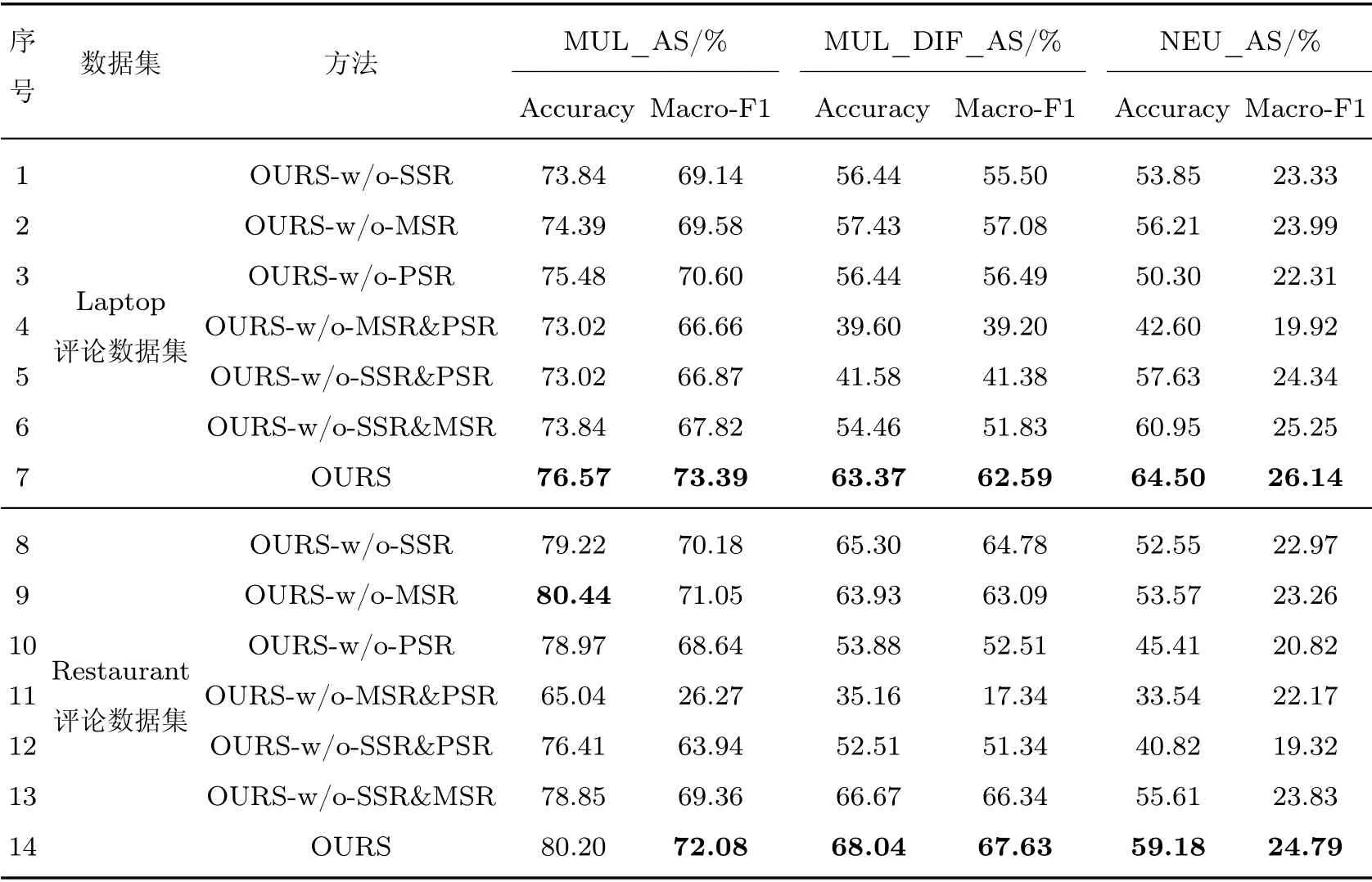
表5 三类方面信息情感分类性能Table 5 Performance based on three kinds of sentiment classification information
表6展示了消融实验中对特定样本注意力分布以及情感类别跟踪结果。其中,序号1 的数据为本文完整模型下数据,序号2~6 的数据分别对应于表3中1~5 的方法,由于方法6中仅保留了局部情感特征,故没有注意力数据。
从表6可以看出:注意力随着保留情感特征的不同发生相应变化。在本文完整模型1 中,方面信息“Indian”“food”对上下文的注意力分布集中在“know”“real”“n’t”“it”几个词语上,较为准确地表达出方面信息情感;在排除MSR(3) 和仅保留SSR(5) 情感特征的两个模型中均出现了注意力过于集中的情况,表现出传统注意力机制的关注偏置问题;在排除SSR(2)和仅保留MSR(6) 情感特征的两个模型中能明显看出,由于MSR 的作用,上下文中各词的注意力分布趋于平缓,反映出MSR 能够有效缓解传统注意力过于关注高频信息的问题,强化上下文中高频信息以外词语对情感特征的作用。
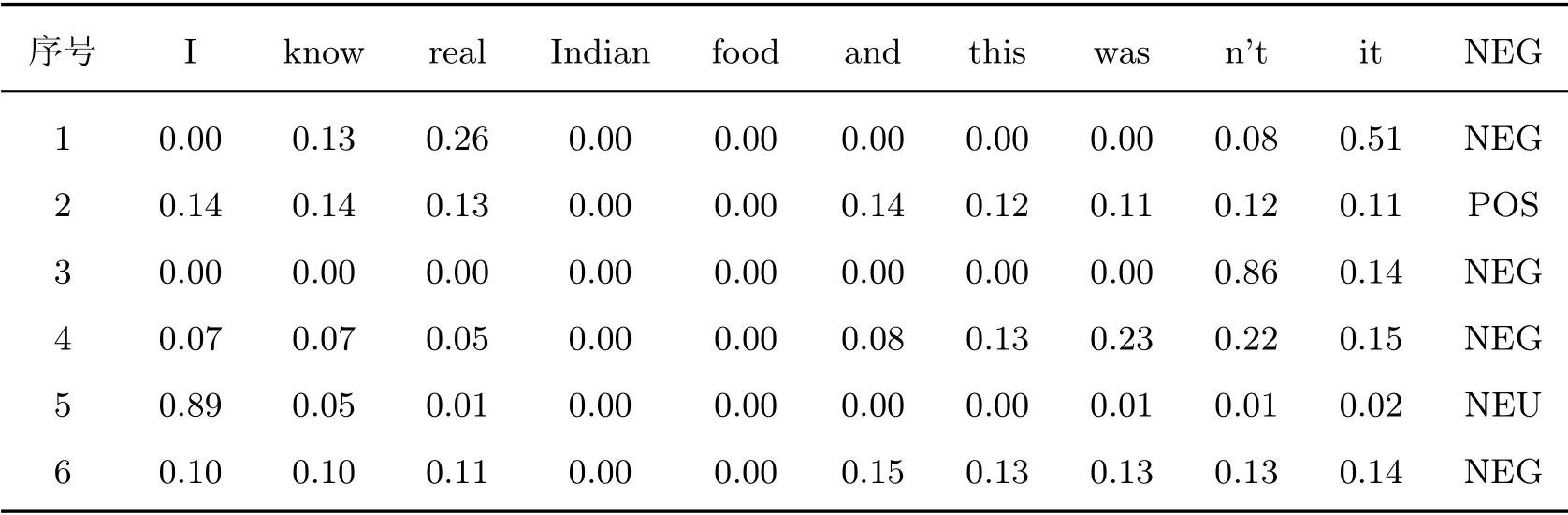
表6 特定样本注意力分布以及情感类别跟踪结果Table 6 Tracking results of Attention distribution and sentiment of specific sample
4 结 语
本文针对方面信息情感分类任务,提出一种基于多模特征融合的方面信息情感分类方法,根据方面信息情感表达模式不同,区分为单点情感信息、多点情感信息、局部情感信息三类。在实现方式上,结合注意力机制和循环神经网络自身特点,使用多层注意力重点提取单点情感信息,利用注意力分值和长度控制参数提取离散情感词作为多点情感信息,通过词性与符号等位置信息提取局部情感信息,通过信息融合实现各类特征相互确认与纠错,达到增强复杂情感表达模式下方面信息情感分类能力的目的。实验结果表明,通过区分三类情感信息并提取融合相应特征的方式可以有效提升方面信息情感极性判断效果,与对比方法相比,在两个数据集上可以使准确率平均提高3.31%、4.17%,F1 值指标平均提高2.04%、4.89%,并且三类情感特征对整体分类效果的作用呈现强弱变化以及相互关联的特点。在后续的工作中,将对各类特征的作用机理进行深入研究,进一步优化模型对特征的提取与利用效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
疯狂英语·新读写(2018年3期)2018-11-29
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
