
基于LSTM及Seq2seq模型的业务预测算法研究
2022-01-19 12:55:48刘旭峰钟志刚贾元启王宁史文祥马家豪郑州大学信息工程学院河南郑州50001中讯邮电咨询设计院有限公司郑州分公司河南郑州50007河南省智能网络和数据分析国际联合实验室河南郑州50001哈尔滨工业大学黑龙江哈尔滨609
邮电设计技术 2021年12期
刘旭峰,钟志刚,贾元启,王宁,,史文祥,马家豪(1.郑州大学信息工程学院,河南 郑州 50001;.中讯邮电咨询设计院有限公司郑州分公司,河南 郑州 50007;.河南省智能网络和数据分析国际联合实验室,河南 郑州 50001;.哈尔滨工业大学,黑龙江 哈尔滨 609)
0 前言
在网络建设中,需要根据用户数和业务量的预测进行规划设计,使网络既能够满足业务发展的需求,又能合理控制建设成本[1],近年来,不限量套餐的推出使得业务量激增,在业务量激增的前提下能及时保证用户的容量需求是容量优化及规划的关键,网络容量的优化工作受到了挑战[2]。业务预测是指对未来一段时间内业务量的预测,对业务预测算法的研究可以有效地在业务量激增情况下进行容量优化及规划工作,另外,随着5G时代的到来,业务预测算法有望在5G时代指导网络优化、规划。
在当前一波人工智能浪潮下,神经网络理论与实践得到不断发展,越来越多先进的人工智能算法被应用于工业与信息领域,为海量数据的分析和使用提供了便利。而每个小区都会记录过去一段时间内的业务数据情况,这为人工智能与业务数据的结合提供了基础。
因此本文引入了当前流行的时间序列预测算法:LSTM 算法和Seq2Seq 算法,并结合某小区7 个月内的业务数据分别对下行PRB 平均利用率和空口总业务量进行未来72 h、168 h及336 h的预测。
1 业务预测研究背景
传统的业务预测使用回归方程法进行预测,虽然精度有限,但在样本数较少时仍能达到与机器学习算法近似的预测效果。但面对较大数据量的预测时,回归方程法与机器学习算法相比便相形见绌。因此本文重点研究基于机器学习的业务预测。在业务预测的历史发展中,同样出现了很多其他算法,在文献[1]中提出了一种基于单隐层神经网络的业务预测算法,其主要思想是将某城市200 个小区的前2 周的数据作为输入,预测所有小区第3周的数据[2-5]。
一般而言,网络流量具有高度自相关、随机性和非线性等时间序列特征[6]。因此可以基于时间序列预测思想去进行业务预测。本文主要进行下行PRB 平均利用率及空口总业务量的预测。
在本文中,考虑到各个小区的业务趋势不同,因此以小区作为训练和预测单位,并且考虑到每个小区在不同粒度上的周期性(例如在每天中的小时粒度数据具有一定的周期性,从年的角度来看也应具有一定的周期性),由于数据不够充足,只有7 个月内小时粒度级别数据,因此本文难以从年周期性去做长期多粒度的趋势预测,只能去做小时粒度的短期内的业务预测。
2 数据预处理
利用某小区2019-10-02—2020-04-30 的小时粒度下行PRB 平均利用率及空口总业务数据进行缺失值处理,补偿其数据缺失地方,便于后续预测,缺失值处理方法有多种[7],本文采用均值插补法,即取过去7天在该时刻的均值作为填充值。例如在2019-12-02 0 时的数据缺失,将其填充为过去7 天0 时的数据均值。该小区共计缺失数据96条,填充缺失数据之后该小区共计5 088条数据,即212天,每天24 h的数据。
接着进行数据的异常值处理,业务数据具有一定的周期性,在相似的时间段具有一致性,根据文献[8],模拟其异常值判断方法,要判断某值是否为异常值,首先提取出前后3 天共6 天在同样时刻的数据,并求其均值与标准差,若当前数据不在其(均值±5)×标准差之间,则视为异常数据,若异常数据过大,则将其填充为(均值+5)×标准差,反之填充为(均值-5)×标准差。该小区的异常值占比约2%。其中过大异常值占总异常值约95%,说明该小区的下行PRB 平均利用率及空口总业务量峰值波动较大。
图1 为数据处理后的下行PRB 平均利用率、空口总业务量与时间的关系图。该小区下行PRB 平均利用率与空口总业务量之间的相关系数为0.95,可知下行PRB 平均利用率与空口总业务量之间呈强烈的正相关。

图1 某小区7个月内小时粒度业务数据图
图2 为2019-10-02—2019-10-09 下 行PRB 平均利用率数据,从图2 可以看出,从天粒度看,PRB 平均利用率虽然具有随机性,但仍具有一定的周期性,另外总业务量图与此类似便不再展示。
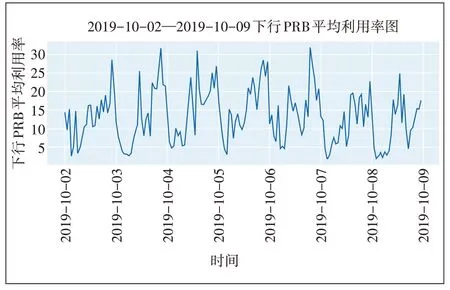
图2 该小区7天下行PRB平均利用率图
对于数据进行训练集与测试集的划分,将2019-10-02—2020-03-31 的数据作为训练集,将2020-04-01—2020-04-30的数据作为测试集。
3 基于LSTM模型的业务预测
3.1 数据归一化
归一化处理可以将数据的值转换为[0,1],并且可以加快神经网络的训练速度[9],因此本文将数据进行线性归一化处理。处理公式如下:

式中:
y——处理之后的值
x——处理之前的值
xmin——x中的最小值
xmax——x中的最大值
3.2 性能指标介绍
算法性能指标用平均百分比误差(mean absolute percentage error,MAPE)表示。MAPE计算公式如下:
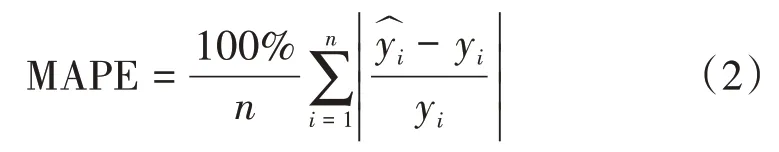
式中:
n——样本数
yi——第i个样本的真实值
由于在未来若干小时业务数据的预测过程中,真实值较低时(如深夜较少人使用业务时)指标意义不大,实际应用中更关注忙时业务数据。因此本文采用一个启发式性能指标,即对未来若干小时的业务数据的真实值求平均,只对真实值中大于上述平均值的点求真实值与预测值的MAPE,将每个样本中的预测多个小时的MAPE值再次求均值得到该样本最终性能指标。将测试集的样本均采用此法求该指标,再次求均值得LSTM模型的性能指标。
3.3 模型介绍及多尺度的业务数据预测
文献[10]中介绍了长短时记忆网络(Long Short Term Memory,LSTM),图3 为LSTM 的结构图。LSTM从根本上解决了循环神经网络[11](Recurrent Neural Networks,RNN)存在的无法处理长时间距离依赖的问题,但是LSTM 同样也增加了网络的复杂度,从而导致训练时间的延长。
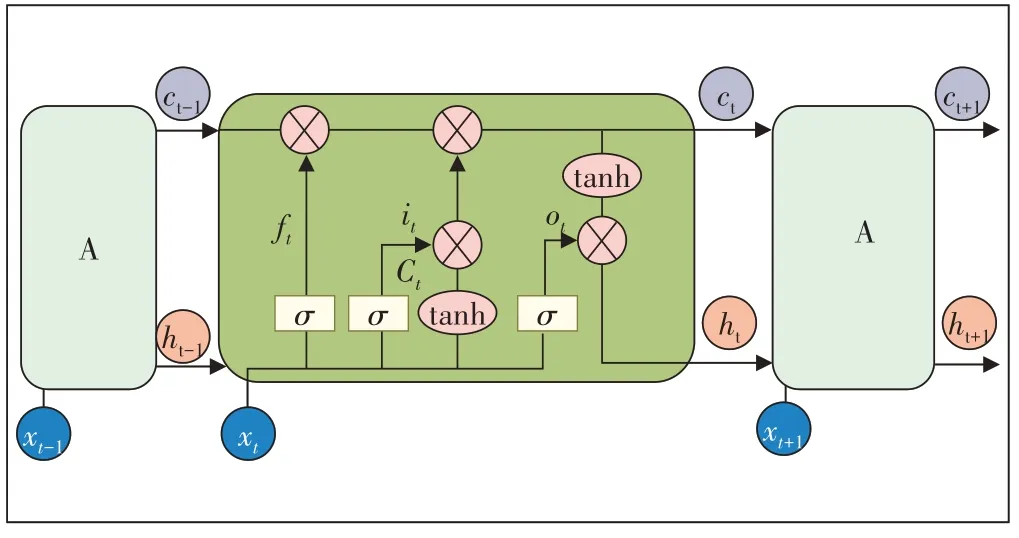
图3 LSTM结构图
当进行业务数据预测时,下行PRB 平均利用率和空口总业务量的特征尺度及预测尺度如表1所示。即设置预测尺度与特征尺度一致,例如在预测未来72 h的下行PRB 平均利用率时,就将过去72 h 的下行PRB平均利用率作为特征,未来72 h 的下行PRB 平均利用率作为标签去训练模型。训练模型时使用Adam 优化器[12]。
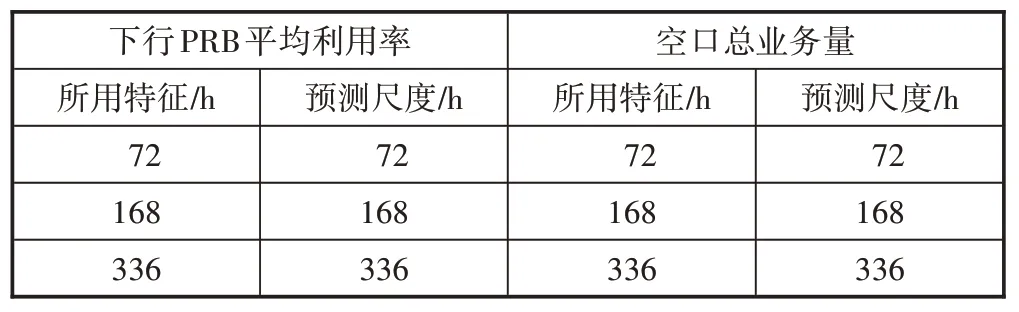
表1 所用特征尺度及预测尺度说明
LSTM 算法应用于下行PRB 平均利用率及空口总业务量的预测性能如表2 所示,其性能指标即为上述启发式MAPE值。该值越低表明对于业务量较大的值的预测越准确。
由表2可知,对于未来72 h、168 h、336 h的业务数据预测启发式MAPE 值大约都在24.2%。因此可以认为采用此模型在对未来的业务数据进行预测时,对于较大的业务数据预测误差约为24.2%。
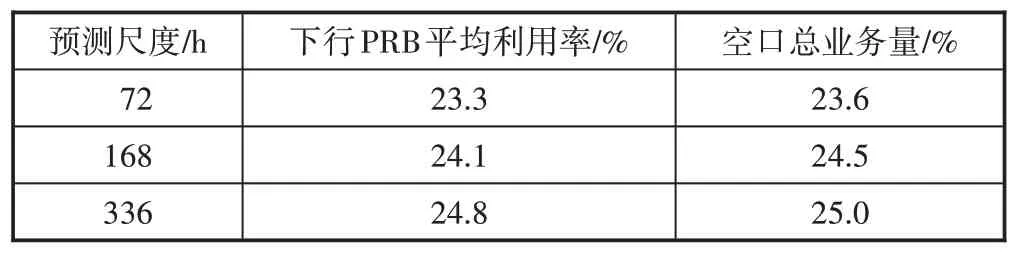
表2 LSTM算法用于业务数据预测性能
LSTM 模型对于不同尺度的下行PRB 平均利用率和空口总业务量的某些预测样本如图4 所示。从图4中可以看出,此模型能准确地预测出趋势,较为准确地预测出峰值,但也存在一定误差。
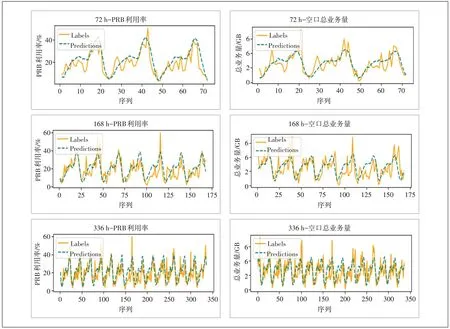
图4 LSTM模型于某些样本结果图
4 基于LSTM的Seq2Seq模型的业务预测
该模型所用特征尺度及预测尺度和所用性能指标与上述LSTM模型完全相同。
4.1 数据平滑及中心化处理
一般来说,对数据取对数之后不会改变数据的性质和关系,且所得到的数据易消除异方差问题,因此对模型使用数据取对数。接着再对数据进行中心化处理。
4.2 模型介绍及多尺度的业务数据预测
文献[13]介绍了Seq2Seq模型,该模型有2个部分组成,一个是用于读取输入序列并将其编码为固定长度矢量,另一个是用于解码固定长度矢量并输出预测序列。Seq2Seq模型结构如图5所示。

图5 Seq2Seq结构图
将LSTM 作为编码器和解码器使用,有利于提升模型解析度,从而在业务数据预测中提升预测精度。基于LSTM 的Seq2Seq 模型应用于下行PRB 平均利用率及空口总业务量的预测性能如表3 所示,其性能指标仍为启发式MAPE值。

表3 基于LSTM的Seq2Seq模型的预测性能
由表3 可知,对于下行PRB 平均利用率和空口总业务量的启发式MAPE 值大概为27.7%,因此可以认为采用此模型在对未来的业务数据进行预测时,对于较大的业务数据预测误差约为27.7%。
基于LSTM 的Seq2Seq 模型对于不同尺度的下行PRB平均利用率和空口总业务量的某些预测样本如图6所示。

图6 基于LSTM的Seq2Seq模型于某些样本结果图
5 未来规划方案
5.1 大区域
上述2种算法的优点是从小区级别、多时间尺度、小时粒度去预测下行PRB 平均利用率及空口总业务量,可以做到对每个小区的业务数据预判。同样这也是限制其性能的原因,因为直觉上从小区角度来看,业务数据每天波动较大,随机性较大,预测也就相对困难。未来可进行区域角度的实验,即规划一片区域,对该区域内总业务数据进行训练及预测,从区域角度去做这个实验相信性能更佳,预测难度降低。因为直觉上来说区域越大随机性相对较低,波动起伏较小,并且从基站规划建设的角度看,同样是大区域的指导意义更佳。
5.2 多时间尺度多粒度
由于数据不充分的原因,只有小时粒度7 个月内的数据,若要进行容量的长期规划,则需要进行多时间尺度多粒度的业务数据预测,此时则需要有多年的数据去进行训练,使得算法可以学习到数据更粗粒度上的规律性以进行多尺度多粒度的业务数据预测。该方向正是进行容量长期规划的关键,也是下一步的研究核心。
5.3 注意力(attention)机制
若进行长期的预测,可以在现有模型的基础上加上注意力(attention)机制,文献[14]首次将注意力机制引入到自然语言处理领域,说明注意力机制对于时间序列预测算法有一定的性能提升。注意力机制的Seq2Seq模型如图7所示。
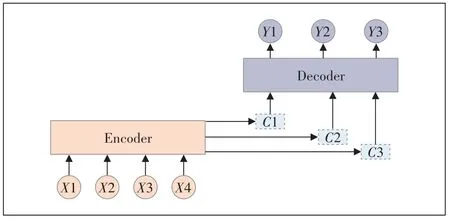
图7 注意力机制的Seq2Seq结构图
对于业务数据的预测任务来说,注意力机制的引入可以有效地选择对输出序列影响最大的输入特征,从而增加预测精度。
5.4 辅助特征
还可以找一些可以辅助业务预测的特征来提高精度,例如一些关于时间的特征,月初、月中、月末、周末、五一、国庆、春节等。还有一些天气特征可以进行辅助训练以提高精度,例如温度、湿度、大雨、小雨、晴天等。
本文意在抛砖引玉,提出将业务预测与现在流行的LSTM 及Seq2Seq 算法结合。未来在数据充足的情况下利用人工智能算法,从时间序列预测的角度进行大区域多尺度多粒度的业务数据预测。
6 结束语
流量预测模型对未来移动通信网络的扩容建设与资源优化分配具有重要研究意义[15]。本文将2种时间序列预测模型和某小区的业务数据进行结合,从小区角度进行训练,对多尺度小时粒度的业务数据进行预测并取得较好的性能。可以对未来的网络规划设计,基站建设、容量优化等工作提供参考。
猜你喜欢
现代经济信息(2023年22期)2023-08-25 21:02:25
粉末冶金技术(2021年3期)2021-07-28 06:26:16
中国经济周刊(2021年1期)2021-02-05 09:49:38
南京大学学报(自然科学版)(2021年1期)2021-01-30 14:01:04
21世纪(2019年9期)2019-10-12 06:33:46
电子测试(2018年6期)2018-05-09 07:32:12
单片机与嵌入式系统应用(2018年5期)2018-04-15 14:09:55
人民交通(2017年10期)2017-10-25 11:13:08
通信产业报(2017年11期)2017-04-28 05:37:44
系统工程与电子技术(2016年12期)2016-12-24 07:19:14
