
基于ImageNet预训练卷积神经网络的图像风格迁移
2022-01-19 10:17赵卫东施实伟
成都大学学报(自然科学版) 2021年4期
赵卫东,施实伟,周 婵
(1.成都大学 计算机学院,四川 成都 610106;2.西南大学 教育学部,重庆 400715;3.西北师范大学 教育技术学院,甘肃 兰州 730070)
0 引 言
随着社会经济的不断发展,人们对各类艺术作品有了更多的喜好和追求.相关应用表明,图像风格迁移技术能够将各种艺术画作的风格迁移到普通图像中,从而能够较为快速地生成不同艺术风格的作品.目前,在实际的应用场景中,人们可以通过利用如Prisma、Ostagram及Deep Forger等相关的应用处理软件,使作品实现图像风格迁移的效果[1].
图像风格迁移技术主要分为传统风格迁移技术和卷积神经网络风格迁移技术2类.传统的图像风格迁移技术主要通过分析特定风格的图像,并为其建立相应的数学统计模型,其局限性主要体现在一个模型只能做特定风格的转换且难以提取图像的高层抽象特征,使得其实际应用场景非常有限.而随着计算机视觉技术中深度学习技术的发展,借助卷积神经网络强大的特征提取能力,图像风格迁移技术已实现了突破性进展[2].相关从业者可以借助该技术,不再局限于建构特定艺术风格的数学统计模型,而可将更多的精力投入到新的艺术作品创作中去.
基于卷积神经网络技术,图像在进行风格迁移的过程中,需要将风格图像和内容图像作为卷积神经网络的2种输入,并随机初始化一张白噪声图像作为目标图像.与此同时,还需要构建风格损失函数和内容损失函数,并将这2种损失函数结合起来作为总的损失函数来对卷积神经网络模型进行评估.此外,在网络模型的训练过程中,还需要根据网络模型所提取到的特征图来计算损失,并通过不断迭代训练来降低生成图像的损失,从而得到理想的目标图像.基于此,本研究采用ImageNet[3]中预训练好的卷积神经网络来对风格图像和内容图像分别提取卷积层特征,并根据对风格图像和内容图像提取到的特征来生成风格迁移的目标图像.同时,网络也会对随机初始化生成的一张白噪声目标图像并提取相同的特征,通过与风格图像和内容图像所提取的特征进行对比,并通过融合风格损失函数和内容损失函数构成整个模型的损失函数,在不断训练优化后,生成最终所需要的目标图像.
1 ImageNet预训练卷积神经网络
1.1 ImageNet简介
事实上,ImageNet项目是一个巨大的可供视觉训练的大型可视化图像库,旨在提供较为全面和多样的图像数据.ImageNet就像一个网络,其拥有多个节点,每一个节点相当于一个类别,一个节点含有至少500个对应物体的可供训练的图像.
1.2 人工神经网络
神经元是人工神经网络的基本处理单元,一般情况下其是多输入单输出的单元[4].一个神经元可以接收n个输入,x=(x1,x2…xn),并对应n个权值,w=(w1,w2…wn),同时,还有一个偏置项b.神经元将所有输入参数与对应权值进行加权求和,得到的结果经过激活函数变换后进行输出,其计算式为,
y=f(w×x+b)
(1)
通常,人工神经网络由多个神经元及其之间的连接构成.通过学习训练,对网络中的参数赋予不同权重值,使其对网络输出结果产生较大的影响.而实现这种权重的函数是一种非线性激活函数,常用的激活函数有Sigmoid、Tanh及ReLu 等[5].此外,在神经网络的学习训练过程中,通过反向传播算法得出的输出结果,能够进行反向修改人工神经网络中的参数,从而更大概率地输出希望获得的目标结果.
1.3 卷积神经网络
卷积神经网络是人工神经网络的一种,其计算方式从输入到输出层层递进,而训练时用反向神经网络进行学习,可使用在图片的学习过程中.而连接的权重为待训练参数,可通过反向传播过程进行训练调整.
卷积神经网络也是利用反向传播算法在训练过程中,经过网络模型各层的计算后,对网络权重进行更新调整.卷积神经网络的结构包含卷积层、池化层及全连接层等.其中,卷积层可以学习到图像的特征;池化层在尽可能保留图像特征的基础上,可进一步减少计算量,常用的池化方法包括最大池化和均值池化;全连接层中的每个神经元与其前一层的所有神经元进行全连接,可以整合卷积层或者池化层中具有类别区分性的局部信息.
1.4 预训练网络
一般而言,预训练可提供较好的模型初始化,这通常会带来更好的泛化性能,并加速对目标任务的收敛.预训练可以看成是一种正则化过程,以避免少量数据引起的过拟合现象,同时也可节约大量的时间成本去训练网络模型.故本研究采用在ImageNet中预训练好的VGG-16和VGG-19 2种网络模型完成对内容图像风格的转换.
VGG-16和VGG-19 模型都属于经典的VGG网络模型,VGG-16网络模型包含13 个Conv layer 卷积层与3 个fully connectedlayer全连接层,而VGG-19网络模型则是16个Conv layer 卷积层与3 个fully connectedlayer全连接层[6].VGG网络模型全部使用的是3×3的卷积核,网络中还使用5个2×2的max pooling池化层进行分割.
在实验中,本研究采用了VGG-16和VGG-19 2种在ImageNet中预训练好的网络模型,其中VGG-16网络模型的结构如图1所示.VGG-19网络模型比VGG-16网络模型多出来的3层卷积层,conv3_4、conv4_4及conv5_4,用红色部分进行了标注,其结构如图2所示.
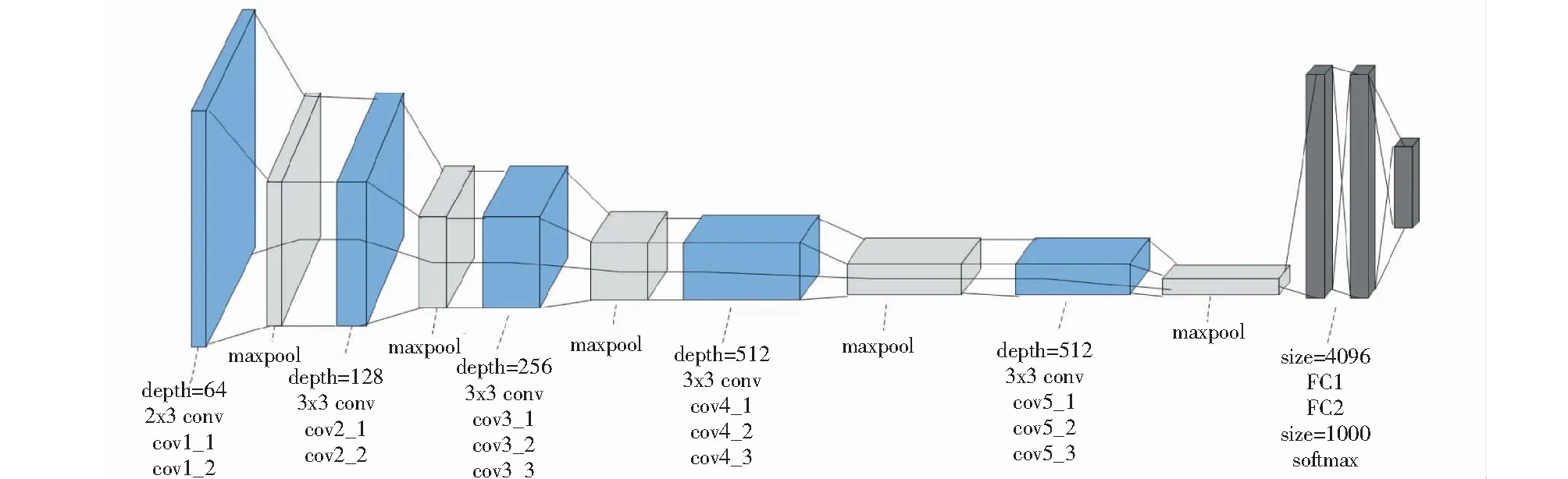
图1 VGG-16网络模型结构图
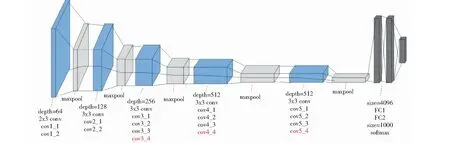
图2 VGG-19网络模型结构图
2 损失函数构建
2.1 损失函数简介
卷积神经网络的反向传播主要基于梯度下降方式向训练误差减小的方向进行调整,整个模型的训练目标就是使得模型总损失函数的值实现最小化[7].损失函数能够衡量当前模型生成的图像效果与预期效果之间的误差,即损失函数的值越小,生成的目标图像效果就越好,而损失函数的值较大,其最终生成的目标图像的效果则会较差.通常,网络模型在最开始训练时的损失函数的值都会相对较大,对此,本研究通过使用Adam优化算法[8]不断在网络模型训练的进行过程中,逐渐降低损失函数的值,从而得到目标图像输出效果较好的模型.
2.2 内容损失函数
本研究采用的内容损失函数[2]的计算式为,
(2)
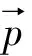
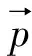
2.3 风格损失函数
图像风格的本质是在各种空间尺度中图像的纹理、颜色及视觉图案等特征,而不同卷积核所提取到的图像特征也不同.随着网络层数的深入,卷积核提取到的特征也会变得更加复杂和抽象.而深层网络特征的提取也需要综合底层网络提取到的边缘、形状与颜色等信息.这些不同卷积层提取到特征结合起来才能表示图像的风格.
研究表明,Gram 矩阵可计算在卷积过程中多维特征图下不同维度之间特征向量的相关性,其可将目标图像和风格图像的差异进行量化,并把图像特征之间隐藏的联系提取出来,即各个特征向量之间的相关程度[2].如果2个图像的特征向量的Gram矩阵的差异较小,就可以认定这2个图像的风格是相近的.利用Gram矩阵计算风格图像的纹理等特征信息的计算式为,
(3)
在第l层中,卷积特征的通道数为Nl,卷积的高与宽的乘积为Ml,对应第l层的Gram矩阵分别为Al和Gl,则第l层的总损失[2]的计算式为,
(4)
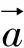
(5)
2.4 总损失函数
本研究的网络模型总损失函数是由内容损失函数和风格损失函数进行加权求和而成,其中α和β2个超参数是用来调整内容损失函数和风格损失函数在总损失函数中各自权重的比重,其目的是实现调整目标图像的风格转换程度更接近于内容还是更接近于风格[9].总损失函数的计算式为,
(6)
3 实验与结果
3.1 实验环境
本研究的实验运行环境为python3.7、tesorflow2.3和cuda10.2,实验硬件平台为Intel(R)Core(TM)i7-8700K CPU ,主频为3.70 GHz,内存为16 GB.其中,为本实验提供计算资源的是NVIDIA GeForce GTX 1080Ti GPU,使用cuda10.2作为GPU计算平台的底层加速框架.实验测试表明,此架构为网络模型的优化过程节省了大量的计算时间.
3.2 数据预处理
首先,在网络进行训练之前,将内容图像、风格图像及随机初始化白噪声图像的宽度修改为450 px,高度修改为300 px,图像默认通道数为3.因为本实验中训练权重使用的是ImageNet数据集上的平均值与标准差,所以在对输入图像进行归一化处理时,也使用相同的值.
3.3 实验过程
本实验采用4幅不同的原始风格图像与2幅不同的原始内容图像,具体如图3、图4所示.

图3 4幅不同的原始风格图像

图4 2幅不同的原始内容图像
实验选择在ImageNet中预训练好的VGG-16网络模型与VGG-19网络模型对图像特征进行提取,同时舍弃其中的全连接层,Adma作为优化器,使用@tf.function修饰符,将训练过程转化为图执行模式,从而加快训练速度.因为α与β2个参数是用来调整目标图像效果更接近于内容还是更接近于风格,所以本研究分别对α/β为10-1、10-2与10-3进行了测试.
在计算过程中,由于收敛速度趋势的重复性较高,故选取VGG-16网络模型与VGG-19网络模型在图3(a)与图4(e),且α与β参数比值不同情况下模型的训练过程进行展示,模型总损失值(loss value)随迭代次数(epoch)的收敛过程如图5所示.
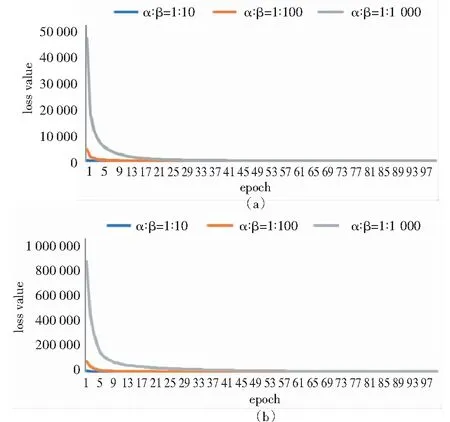
图5 VGG-16网络模型与VGG-19网络模型在图3(a)与图4(e)且α与β权重比值不同情况下的训练过程结果
本研究根据收敛速度与损失值,最终将α/β的参数比设定为10-1,其余参数设置见表1.

表1 VGG-16网络模型与VGG-19网络模型训练参数设置
在实验测试中,使用VGG-16网络模型与VGG-19网络模型提取图像特征,其损失值都能够快速达到收敛,并且都能得到效果较为不错的目标图像.同时,将2种网络模型在不同迭代次数生成的目标图像进行对比,结果如下:
1)当原始内容图为(e)时,与4幅不同的原始风格图像(a)、(b)、(c)与(d)进行结合,选取第100、1 000、10 000次迭代生成的目标图像,结果如图6所示.

图6 原始内容图(e)生成的不同风格目标图像
2)当原始内容图为(f)时,与4种不同的原始风格图像(a)、(b)、(c)与(d)进行结合,选取第100、1 000、10 000次迭代生成的目标图像,结果如图7所示.

图7 原始内容图(f)生成的不同风格目标图像
3.4 结果分析
为了将内容图像(e)、(f)与4幅不同风格图像(a)、(b)、(c)与(d)在VGG-16与VGG-19 2种在ImageNet预训练好的网络模型生成的目标图像效果进行量化评价,本研究将实验过程中2种网络模型的总损失值进行了输出,结果如表2所示.
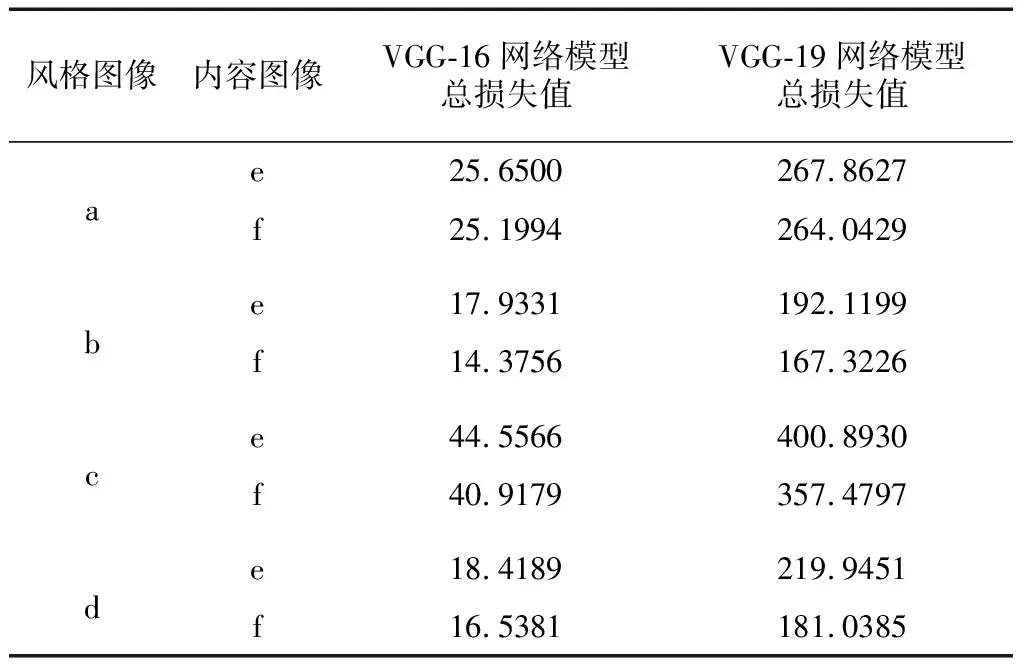
表2 内容图像与不同风格图在VGG-16网络模型与VGG-19网络模型迭代10 000次时的损失值
由表2数据可以看出,风格图像(b)和内容图像(e)、(f)的结合,经过10 000次迭代后,风格图像(b)使用2种预训练的网络模型与不同的内容图像进行结合后损失值最小的.因此,相同的网络模型下,影响最终生成的目标图像效果也与原始风格图像自身的艺术纹理特征相关.而从2种不同类型的预训练网络模型对比来看,VGG-16网络模型的总体损失值都比VGG-19网络模型低,反映在最终生成的目标图像的效果上也是使用预训练模型为VGG-16的网络模型更好.
同时,由图6与图7中第1 000次迭代生成的目标图像可以看出,在训练过程中,VGG-16网络模型生成的目标图像能够更快地接近原始风格图像的风格特征.反映在对应图中的损失值可视化效果图中,VGG-16网络模型达到收敛的速度快于VGG-19网络模型,即在相同的迭代次数和相同的原始内容图像与原始风格图像情况下,VGG-16网络模型的风格迁移效果较VGG-19网络模型具有更为丰富的风格图像细节特征.
此外,由于卷积神经网络采用的是ImageNet中预训练好的模型,所以在训练过程中直接通过tf.keras.applications加载预训练模型即可,其中最为重要的工作是进行损失函数的构建与模型总损失值进行不断优化.最终2种网络模型都达到收敛之后,在α/β参数比为10-1的基础上,2种网络模型生成的目标图像都具有不错的风格迁移效果.
4 结 论
本研究通过使用基于ImageNet中预训练好的卷积神经网络VGG-16网络模型与VGG-19网络模型,实现了对原始内容图像的风格迁移,通过使用了2幅不同的原始内容图像和4幅不同的原始风格图像对网络模型进行训练,同时,分析了不同的网络模型在保持各项训练参数与权重相同的情况下,生成目标图像过程的差异性.
实验结果表明,基于ImageNet中预训练好的卷积神经网络,利用深度学习卷积神经网络的特征提取能力与Gram矩阵计算图像风格差异,并基于现有图像风格进行艺术创作过程中,具有节省训练时间,从而更高效地推广应用等更多的优势,促进了计算机视觉技术在不同的领域的实际应用与发展.事实上,除了在专业的影视娱乐与游戏设计等领域外,在用户的日常创作场景中,图像风格迁移技术也拥有广泛的具体应用前景.
此外,针对图像风格迁移算法,如果使用生成对抗网络(generative adversarial networks,GAN)[10]完成这项工作或许会有令人惊艳的效果.因为在GAN中,可以使用多个判别器分别来约束图像风格、图像结构和图像细节等要素.这项工作有待今后去做更多的探究与验证.同时,在人工智能教学课程中,以本实验项目为基础单元,将GAN用于风格迁移项目可以作为学习者后一个单元的学习材料,从而在人工智能教学过程中使得学习者能够更好地掌握相关知识.此外,另一个值得探究的问题是,通过计算机技术生成的艺术作品是否具有美学与艺术价值,以及其评价指标与体系如何构建等相关问题,也是未来人工智能技术应用于艺术创作领域亟待思考的重要课题.
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小天使·二年级语数英综合(2019年10期)2019-11-08
电子制作(2019年24期)2019-02-23
