
面向无人机视频分析的车辆目标检测方法
2022-01-19 02:10:34陶英杰张维纬马昕周密
华侨大学学报(自然科学版) 2022年1期
陶英杰, 张维纬, 马昕, 周密
(1. 华侨大学 工学院, 福建 泉州 362021;2. 华侨大学 工业智能化与系统福建省高校工程研究中心, 福建 泉州 362021)
随着交通基础设施的发展,中国许多城市在市区安装了成千上万个交通监控设备.这些视频要传输到监控中心,并进行人工分析,成本昂贵且工作实效低.目前,无人机辅助作业因成本低、体积小、灵活方便等优点,成为一项极具发展前景的技术.然而,无人机的主要作用是拍摄车辆特征明显的视频,所拍摄的视频还是需要进行人工分析.因此,无人机要真正做到“无人”,主要面临以下困境:航拍的视频帧数巨大,若直接处理视频中的每一帧,计算量大;完整的目标检测模型部署在嵌入式设备上,会导致能耗高、计算量高、时延高等问题.目前,基于运动的车辆检测主要分为非参数法和参数法两类[1].非参数法主要以逐像素的方式分离前景和背景,如帧差法[2]在固定监控、低帧率的运动车辆检测中运用广泛,但是当该方法用于高帧率的航拍视频去除大量冗余帧时,会丢失大量目标帧.参数法主要分为背景建模、光流及其他方法.背景建模[3]主要针对视频流建立背景模型,应用前提是基于背景固定的假设.Zhan等[4]利用金字塔光流估计和形态学变换算子提取运动车辆目标,然而,光流法所需要的计算资源是嵌入式设备无法满足的.其他方法包括自适应运动直方图的方法[5]、基于运动模型的方法[6]和利用深度学习挖掘关键帧的方法[7]等,但是此类方法存在时耗长、计算量大及模型大的问题,难以部署在嵌入式设备上.
为了去除视频冗余帧,减少不必要的计算,研究者基于运动的车辆检测方法,结合其他方法进行了多种尝试.Zhang等[8]采用周期性固定间隔选取帧,再利用结构性相似的方案选取关键帧,但是固定间隔会导致目标帧丢失过多,检出率不高;Zhang等[9]以背景图像为参考帧,通过帧差图像判断并提取关键帧,但这种方法需要背景图像参考,对移动切换的场景不适用;Kang等[10]直接通过跳帧以减少视频数据量,这种方法简单,但会出现无目标帧剩余情况.另外,这些方法将预处理方法和检测模型均部署本地,边缘计算资源浪费.因此,本文提出一种面向无人机视频分析的车辆目标检测方法.通过在无人机设备上将实时拍摄的视频进行像素级及结构性差异过滤处理,得到关键帧,再通过部署在PC上压缩的检测模型进行检测.
1 无人机视频过滤机制
1.1 总体框架
文中提出的框架包括两级过滤器和目标检测器,其中,两级过滤器部署在嵌入式设备上,目标检测器部署在PC端,如图1所示.无人机拍摄的M帧视频通过灰度转换,输入像素差异检测器(PDD)判断相邻帧的相似程度,根据相似度选择丢弃或保留;一级筛选后将剩余的M-N帧输入结构差异检测器(SDD)中,根据更符合人类视觉的结构性判断帧之间的相似度,剔除P帧;最后,将两级过滤后的M-N-P帧送入压缩并添加计数模块的YOLOv3模型进行检测.

图1 文中算法的结构框架Fig.1 Structural framework of this paper algorithm
1.2 两级过滤器的设计
1.2.1 像素差异检测器 像素差异检测器通过计算相邻帧之间的像素距离确定这两个帧是否相同.Himeur等[11]通过直方图的方法捕捉颜色信息的相似性,但是无人机拍摄的视频分辨率较高,一张像素为200 px×200 px的图片就有40 000个像素点,每一个像素点都保存着一个RGB值,信息量相当庞大,而无人机拍摄的视频图片像素远不止200 px×200 px.Gao等[12]的实验结果显示,如果将RGB图像转化为灰度图,会降低计算成本,且不影响效果.因此,首先将M个视频帧转换为灰度图;其次把图片缩放到非常小,根据对比显示缩放到9 px×8 px是相对合理的,因为每行9个像素值,会产生8个差异值,刚好构成一个字节,可以转化为2个16进制值进行后续计算.
将M帧缩放过的灰度图输入差异检测器,判断相邻帧的相似程度,如果相似,则保留相似帧中的一帧.第i帧图像相邻像素差值的判断方法为
ai(x,y)=fi(x,y)-fi(x,y+1).
(1)
式(1)中:x,y为图像像素的横、纵坐标;fi(x,y)为第i帧图像的x行y列的像素值;ai(x,y)表示2个像素差值.
第i帧图像的相邻像素强度的判断方法为
(2)
式(2)中:产生全为0和1的8×8矩阵,而每8位可以组成2个16进制值,连接起来转换为字符串,得到哈希值.
第i帧和第j帧图像的差异值的判断方法为
Di,j(k)=Hi(k)⊕Hj(k).
(3)
式(3)中:Hi(k)和Hj(k)分别为第i帧和第j帧图像的第k个哈希值转换的二进制值;⊕表示异或运算;Di,j(k)为第i,j帧哈希值的运算结果.
两帧图像的相似判断图为
(4)
式(4)中:Δi,j为两帧之间的相似度度量参数,当Δi,j=5时,能有效度量两帧航拍图像之间的相似度.
1.2.2 结构差异检测器 通过PDD的过滤,可以初步过滤掉70%以上的冗余帧,但是交通拥堵事件发生的平均时间不超过5%[13],而且无人机的应用场景和固定摄像头不同,场景随时切换,图像结构会发生变化,还应进一步过滤.而结构相似性倾向于通过统计指标(如熵、灰度平均值、协方差)和图像质量评价指标(如峰值信噪比(PSNR)和结构相似性指数(SSIM))对图像进行全局比较.Hore等[14]的实验结果表明,SSIM是一个完整的参考图像质量评价指标,它结合了亮度、对比度和结构衡量图像的相似性,在图像相似性评价上优于PSNR.因此,结构差异检测器采用SSIM算法度量图像的结构相似性.
给定2幅图片,SSIM计算式为
(5)

根据实验发现,利用SSIM算法将无人机拍摄的视频进行相邻帧的相似度度量并做保留或丢弃处理,会产生相似度传递,并累积错误,如图2所示.

图2 SSIM算法产生相似度传递Fig.2 SSIM algorithm produces similarity transfer
由图2可知:对于M帧的视频,连续的帧与帧之间的相似度非常高,最坏的可能是最后保留M-1帧图像,只进行相似度度量,没有过滤帧.因此,对应用航拍视频的SSIM算法进行改进.
伪代码描述如下.
算法:基于航拍视频的帧结构差异过滤算法
输入:Aerial Video,SSIM,相似度判定阈值β
输出:相似度小于β的帧
1: i ← 0
2: j ← 0
3: read Aerial Video
4: save first frame
5: frame numbers save to array A
6: B ← A
7: while length[A]>i and length[B]>j
8: do取出A[i],B[j]
9: if SSIM(A[i],B[j])>β
10: then j ← j+1
11: End if
12: if SSIM(A[i],B[j])<β
13: then save B[j]
14: i ← j
15: end
1.3 YOLOv3模型的压缩
为实现在线实时高精度检测,选取精度较高的YOLOv3作为基础网络,其速度和精度在相同情况下均优于SSD[16],fast R-CNN[17]等主流算法,在工业界也有广泛的应用[18-21].YOLOv3模型能避免车辆大量漏检情况的发生,具有较高的精度和可优化的空间.考虑到目前的压缩方法[22-23]对精度和速度单方面的需求,没有将速度与精度进行权衡.故将通道剪枝和层剪枝方法结合,保证精度需求的情况下对YOLOv3模型进行加速.
受到SlimYOLOv3[24]的启发,为了便于通道修剪,为每个通道分配一个比例因子,其中,比例因子的绝对值表示通道的重要性.在YOLOv3中的每个卷积层之后都有一个BN层,用以加速收敛和提高泛化能力,BN层使用小批量归一化卷积特征,即
(6)
式(6)中:μ和σ分别为输入特征的均值和标准差;γ和e分别为比例因子和偏差.
直接采用比例因子作为通道重要性的指标,为了有效区分重要通道和不重要通道,对γ增加一个正则项[25],即
(7)

通道剪枝示意图,如图3所示.

图3 通道剪枝示意图Fig.3 Schematic diagram of channel pruning

图4 层剪枝示意图Fig.4 Schematic diagram of layer pruning
在通道剪枝的基础上,对每一个shortcut层前面一个CBL(YOLOv3网络结构中的最小组件,由conv+BN+Leaky_relu激活函数三者组成)进行评价,对各层的γ均值进行排序,最小的γ均值进行层剪枝.为了保证结构完整性,每剪掉一个shortcut结构,会同时剪掉一个shortcut层和前面2个conv层.对于YOLOv3,有23处shortcut,共有69个层剪层空间.
层剪枝示意图,如图4所示.图4中:γi<γi+1.根据选取交并比(IoU)≥0.5的预测框,进行计数,统计预测车辆的数量.
2 实验结果与分析
2.1 实验环境配置
系统为ubuntu18.04,搭建Pytorch框架进行训练,通过Python进行测试.训练硬件配置为Intel(R) Xeon(R) Gold 5118 CPU@2.3 GHz,NVIDIA GeForce TITAN Xp;测试硬件配置为PC机Intel(R) Core(TM) i5-8300H CPU@2.30 GHz,NVIDIA GeForce GTX 1050;jetson nano为64位4核ARM A57@1.43 GHz,128核NVIDIA Maxwell@921 MHz.实验方案如下:首先,使用部署在嵌入式设备jetson nano上的两级过滤器对采集的无人机视频进行预处理并进行效果对比;再将处理后的剩余帧传输到部署在PC端的轻量化目标检测器进行检测;最后,展示效果.
2.2 性能评价标准
实验训练数据为UA-DETRAC,VisDrone2018数据集,采集一段无人机视角的交通视频,分辨率为1 280 px×720 px,帧数为3 634帧.其中,目标帧数为185帧,由于目标帧之间也存在冗余,故每5帧取1帧作为实际目标帧,即认为实际目标帧为37帧.
为了能够评估无人机视频过滤系统性能,对时延、帧总过滤率、目标帧保留率、目标帧占比率、冗余帧过滤率等参数进行评估.
帧总过滤率(RTFF)表达式为
(8)
目标帧保留率(RTFR)表达式为
(9)
目标帧占比率(PTF)表示被过滤的剩余帧数中含有多少目标帧,其表达式为
(10)
冗余帧过滤率(RRFF)表达式为
(11)
式(8)~(11)中:Ftot为测试视频的总帧数;Ftot_t为测试视频包含的目标帧帧数;Ffil为测试视频被过滤的帧数;Ffil_t为测试视频被过滤的目标帧帧数.单一的目标帧保留率或冗余帧过滤率无法验证过滤器的性能,因此,将二者结合来评估过滤器性能,帧总过滤率作为参考.
为了能够评估加速的目标检测器的性能,采用平均精确率均值(PmA)、检测速度及参数总量作为评价准则,其中,平均精确率均值是目标检测任务中最重要的指标,决定了检测效果.为了在计算机中更快速精确地求出PmA的大小,通常使用以下方法,即
(12)
2.3 结果分析
为了验证过滤系统的效果并评估其性能,在jetson nano平台将文中方法与文献[8]、文献[9]、文献[10]中的方法进行对比实验.不同方法下的过滤时间和过滤效果的对比,如图5,6所示.图5中:t为过滤时间.

图5 不同方法下的过滤时间对比 图6 不同方法下的过滤效果对比Fig.5 Comparison of filtering time Fig.6 Comparison of filtering effects in different methods in different methods
文中方法通过PDD将高分辨率帧进行像素级压缩,再进行哈希值相似度判断,大大减少了计算量,时耗仅为11.7 s.过滤系统不仅要提高速度,还要提高目标帧的保留率,因此,使用SDD根据人类视觉,通过结构化相似度判断,进一步去除冗余帧.由于已经通过PDD初步筛选,因此,SDD需要判断的帧数相对减少,时耗仅为20.77 s.由图5可知:文献[8]和文献[10]方法的过滤时间分别为25.30,16.34 s,这是由于文献[10]直接进行了跳帧处理,文献[8]在选择跳帧后进行了相似度检测,因此,两种方法的速度都较快.
由图6可以看出:文中方法的目标帧保留率RTFR明显优于文献[8]、文献[9]、文献[10]的方法,达到97.30%,几乎可以保留所有目标帧;文中方法、文献[8]、文献[9]和文献[10]方法的冗余帧过滤率RRFF都非常高,分别是99.38%,95.96%,96.83%和99.64%.但单一指标无法评估性能,由综合目标帧占比率PTF可以看出,在剩余的帧数中,使用两级过滤器的文中方法含有目标帧的帧数分别是文献[8]、文献[9]、文献[10]方法的1.54,4.29,5.14倍.
YOLOv3通道剪枝压缩情况,如表1所示.采用层剪枝的方式将YOLOv3中的shortcut层进行修剪,为了保证结构的完整性,同时将shortcut层对应的2个CBL层也剪掉.YOLOv3层剪枝压缩情况,如表2所示.

表1 YOLOv3通道剪枝压缩情况Tab.1 YOLOv3 channel pruning compression situation

表2 YOLOv3层剪枝压缩情况Tab.2 YOLOv3 layer pruning compression situation
压缩后的YOLOv3模型的各项指标,如表3所示.为了评估压缩YOLOv3的效果与性能,在PC端将压缩模型与YOLOv3模型和轻量化YOLOv3模型的各项指标进行对比,结果如表4所示.表3,4中:V为模型参数量;tf为前向推断耗时;F为检测速度.
通过通道剪枝,模型大小为33.2 MB,参数压缩了86.8%,再通过层剪枝,剪了12个shoutcut,相当于剪了36层,模型大小为22 MB.
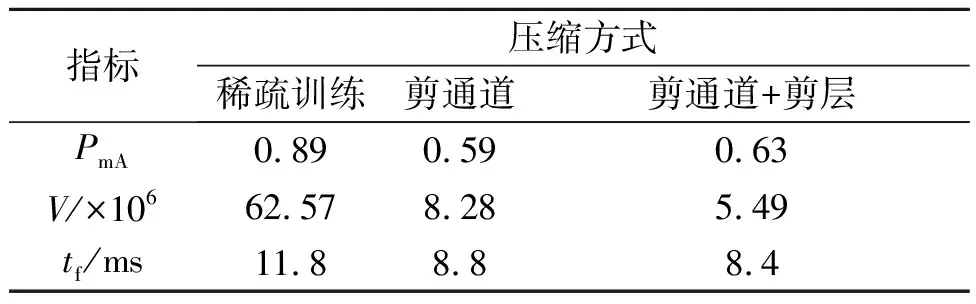
表3 压缩后的YOLOv3模型的各项指标Tab.3 Various indicators of compressed YOLOv3 model
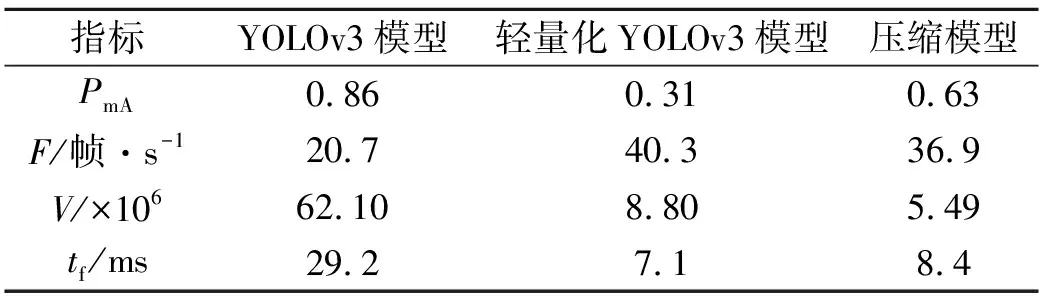
表4 压缩模型与YOLO模型对比Tab.4 Comparison between compression model and YOLOv3 model
通过层剪枝和通道剪枝的结合,去除对网络输入结果影响小的卷积核和卷积层,压缩了模型的深度和宽度,从而加快了模型检测速度;YOLOv3模型的参数量压缩了91.23%,大大减少了计算量.由表4可知:与YOLOv3模型相比,压缩模型虽然在精度方面降低了20%左右,但是检测速度提高了78.3%,推断速度提升了71.2%;相较于轻量化YOLOv3模型,压缩模型的精度提高了103%,而检测速度差别不大.3种模型各截取一帧,检测效果如图7所示.

(a) YOLOv3模型 (b) 轻量化YOLOv3模型 (c) 压缩模型 图7 3种模型检测效果Fig.7 Detection effects in three models
3 结束语
针对视频帧大量冗余的问题,进行了大规模且有效的过滤;另外,对全功能模型检测速度慢的问题,进行了压缩加速,在保证精度的情况下,减少模型的参数总量和模型体积,与现有的模型相比,实现了精度与速度的均衡.然而,研究的最终目的是将过滤器及检测模型全部部署在无人机上,充分利用边缘设备计算资源.因此,在今后工作中,将会进一步研究模型的压缩和改进,从而实现无人机实时在线全功能过滤交通视频检测异常的情况.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
保健医苑(2022年5期)2022-06-10 07:47:22
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
中国交通信息化(2017年9期)2017-06-06 07:14:57
天津诗人(2017年2期)2017-03-16 03:09:39
工业设计(2016年11期)2016-04-16 02:49:43
CHIP新电脑(2016年3期)2016-03-10 14:22:03
计算机工程(2014年6期)2014-02-28 01:26:33
