
生猪检测模型及数据集构建方式研究
2022-01-19 11:48郝王丽李富忠胡欣宇
物联网技术 2022年1期
郝王丽,韩 猛,李 游,李富忠,胡欣宇
(1.山西农业大学 软件学院,山西 晋中 030801;2.山西财经大学 管理科学与工程学院,山西 太原 030006)
0 引 言
生猪检测是智慧养殖领域非常重要的研究问题,相应的模型在生猪表型信息采集等领域应用广泛,可为生猪育种提供重要的支撑信息。
鉴于生猪检测具有的重要价值,很多学者对生猪检测进行了研究。杨秋妹等使用Faster R-CNN对群居猪中的猪只头部和身体进行检测、定位,设计了一种猪头和猪体相关联的算法,并利用该算法对猪只的饲养行为进行监测。该算法对猪只饲养行为监测的准确率为99.6%,召回率为86.93%。薛月菊等提出了基于改进Faster R-CNN的哺乳期母猪深度姿态图像识别网络算法。该算法使用母猪深度视频图像作为输入,在ZF网络上集成残差模块形成新的ZFD2R网络,在保持实时性的同时可提高识别精度。ZF-D2R将监督信息连接入Faster R-CNN网络,通过这种方式来增强各类别间的内聚性并提高模型精度。该论文重点对哺乳期母猪的五种姿态动作进行识别,主要包括站立、坐姿、俯卧、腹卧和侧卧,平均识别精度高达93.25%,速度也有所提升。李丹等提出了基于Mask R-CNN模型的猪只爬跨行为识别。首先采集俯视角度的图像并利用Labelme工具进行标注从而获得预处理数据;然后利用Mask R-CNN网络将猪只从原图像中检测、分割并获取每只猪的Mask像素面积,获得了94%的分割性能;最后,根据正样本(爬跨行为)、负样本(非爬跨行为)确定阈值,即在检测过程中,若分割面积小于边界阈值,则不会发生爬跨行为,反之则发生,识别爬跨行为的准确率达到94.5%。
所谓目标检测,即为给定一张照片,通过模型准确给出图片中目标的位置。目前较流行的目标检测算法大致可以分为两类:一类为two-stage方法,包含R-CNN模型、Fast R-CNN模型、Faster R-CNN模型。它们首先采用启发式方法或卷积神经网络通过RPN网络生成候选区域(Region Proposal)并进行特征提取,然后进行分类与边界回归。另一类为one-stage方法,包含YOLO系列模型及SSD模型。此类方法将检测任务形式化为一个回归任务,并利用全卷积神经网络从输入图像中直接预测出目标物体的边界框。预测值包含物体的置信度及物体类别。第一类方法精度较高,运行较慢;第二类方法精度较低,运行较快。
为提升生猪检测的性能,本文从模型及数据集构造两个方面进行探讨,旨在找到一种良好的基于YOLO的生猪检测模型及较好的数据集构建方法。对比了基于YOLOv2、YOLOv3及YOLOv4的生猪检测模型;探讨了不同规模、不同视角、单图片不同目标个数的数据集构建方法。
1 方 法
YOLO模型的基本原理是将一张图像输入到YOLO网络中,对数据进行特征提取后,生成一张特征图,然后对其进行目标识别和位置预测,最终检测到目标。YOLO模型引入了非极大抑制(Non-maximal Suppression)方法去除目标置信度相对较低的重复边界框,可大大提高效率。YOLO算法的主要优点是网络实现简单、识别与训练速度快、对物体检测较准确。
1.1 YOLO模型
Redmon等人提出了性能良好的目标检测系列模型YOLO,包括YOLOv1、YOLOv2、YOLOv3三大类。它们均是端到端的模型且不用直接提取Region Proposal,通过一个网络便可实现数据输出(包括目标类别、置信度、坐标位置)。虽然YOLOv1检测速度快,但是其对于密集型小目标检测精度偏低。YOLOv2是在YOLOv1基础上进行改进而得到的一种目标检测算法。YOLOv1直接通过回归求得一个目标位置坐标(,,,),而YOLOv2预先根据设定的候选框大小,在每个目标位置特征图的中心预测5种不同大小和比例的Region Proposal,再通过回归计算候选框的偏移值。这样便可在目标框的长宽比相差较大时,增加回归目标框的准确性,并同时加快训练速度。具体步骤为将图片的特征提取网络修改为DarkNet-19网络,输入后该图片尺寸从448×448×3变为416×416×3,特征图尺寸从26×26变为13×13,用于预测更小的物体。YOLOv3模型是在YOLOv2模型基础上进一步改进的,特征提取网络由 DarkNet-19变为DarkNet-53;输入三种尺寸的图像,分别为320×320、416×416、608×608,提取特征效率由快到慢,检测精度由低到高。对应三种输入,加入层数为3的特征金字塔网络,提取三种不同大小和尺度的特征,便于处理多尺度样本检测的问题。
1.2 YOLOv4模型
为进一步提升目标检测性能,文献[10]提出了YOLOv4模型,该模型在速度和精度方面均优于现在较流行的检测模型。YOLOv4模型结构具体如下:CSPDarkNet53为骨干网络(BackBone),空间金字塔池化模块(Spatial Pyramid Pooling, SPP)为Neck的附加模块,路径聚合网络(Path Aggregation Network, PAN)为Neck的特征融合模块。YOLOv4继承了YOLOv3的Head。与其他模型相比,YOLOv4有以下4个较突出的创新点:(1)针对输入端,引入Mosaic数据增强,通过随机裁剪、随机图片缩放、随机图片排放等多种方式对四张输入图片进行随机拼接,旨在解决训练数据集小、目标较少、对小目标检测性能较弱的问题。另一方面,引入了Self-Adversarial Training(SAT)自对抗数据增广方法,具体为通过神经网络在原始图像上增加一些扰动。(2)针对Backbone,使用CSPDarkNet53模型替换DarkNet53,因其具有更高的输入图像分辨率、更深的结构、更多的模型,能获得更好的感受野,并能检测出各种类别和尺寸的目标。同时,CSPDarkNet53模型在轻量化的同时还可以保持精度,且可通过减小内存成本而减少计算量。(3)针对颈部,采用了空间金字塔池化模块(SPP),可处理每张图片中猪的长短和远近不同的情况,所以会造成每头猪的高宽比和尺寸不同并引起一些问题。同时,PAN比YOLOv3中的特征金字塔(FPN)网络更好,可聚合不同主干分支层的参数,为YOLOv4的头部提供更丰富的信息。(4)针对损失函数,YOLOv4模型采用了性能更好的CIOU损失和DIOU-NMS损失,可进一步改善模型的收敛速率及回归精度。考虑目标框重叠的面积、中心点的距离以及长宽比,CIOU分别增加了长、宽的损失以及检测框尺度的损失,使预测框回归速度和精度进一步提升。图1为YOLOv4网络结构图。

图1 YOLOv4网络结构图
2 实验设置
2.1 实验平台
DarkNet框架是现阶段非常流行的目标检测框架,由文献[11]首次提出,为较轻型的基于CUDA和C语言的深度学习框架。与目前较流行的Tensorflow和Caffe等框架相比,DarkNet拥有如下优点:易安装、平台无关、可支持CPU和GPU两种计算方式。尽管DarkNet是基于C语言进行编写的,但其提供了Python接口,故可通过Python函数进行调用。本文使用的目标检测算法YOLOv2、YOLOv3、YOLOv4均基于DarkNet深度学习框架。
2.2 模型评估准则
为比较模型性能,本文使用精确率(P)、召回率(R)、F1值以及平均检测精度(mean Average Precision, mAP)作为各比较模型的评价指标。F1就是精确率和召回率的调和均值。TP(True Positive)表示模型预测为猪只目标框且实际也为猪只目标的检测框数量,FP(False Positive)表示模型预测为猪只目标框但实际并不为猪只目标的检测框数量,FN(False Negative)表示预测为背景但实际为猪只个体框的样本数量。具体公式为:

3 数据处理及实验设置
3.1 数据集的采集与预处理
数据采集持续了两个月,去除外部环境干扰导致的无效或质量较差的视频,共收集了2 TB视频数据。
对视频数据进行如下预处理后得到猪只检测数据集:
(1)对采集视频每间隔25帧进行切割处理,得到分辨率为2 560×1 440的图片,将图像的分辨率统一调整为608×608,并采用LabelImg图像标注工具对猪只个体进行标注。
(2)对标注的数据进行180°翻转,从而丰富数据集使模型泛化能力增强。
(3)对标注的图片使用Mosaic数据增强,对每四张图片进行随机裁剪、随机拼接、随机缩放等,以解决数据集中小目标较少的问题。结果如图2所示。

图2 图像处理过程
通过标注共获得猪只图片12 000张,其中包含两个侧视视角图像各4 000张,一个俯视视角图像4 000张。本研究共设计了三个部分的实验,对应每部分分别构建了相应的数据集:(1)研究不同规模样本集对猪只检测结果的影响,构建了规模分别为4 000张、8 000张、12 000张的猪只检测数据集,且每种规模进行了三次随机并以平均值为最终报告结果。(2)研究不同视角样本集对猪只检测结果的影响,构建了两个侧视视角数据集各4 000张、俯视角度数据集4 000张。(3)研究单张图片中目标物体数目不同时对猪只检测结果的影响,构建了单张图片少目标(1~2个)的数据集4 000张、多目标(3~4个)的数据集4 000张以及包含2 000张少目标和2 000张多目标的数据集。每个数据集按7∶3的比例划分成训练集和测试集。
3.2 模型训练配置
为进行公平比较,模型训练的动量系数为0.9,权重衰减系数为0.000 5,最大迭代次数为12 000,初始学习率约为0.001;迭代至9 600次、10 800次时,学习率开始衰减。
本实验所采取的硬件设备配置如下:GTX TITANXP 12G显卡、i77800 X 处理器。实验环境如下:CUDA10.1,CUDNN7.6.4,Python3.6.9,YOLOv2、YOLOv3、YOLOv4均基于DarkNet框架完成。需要注意的是,文中所有实验均在TITANX GPU上执行。
4 实验结果与分析
4.1 模型对比
4.1.1 不同网络模型检测性能比较
为验证不同模型的性能,本节对比了YOLOv2、YOLOv3、YOLOv4网络模型的检测性能。使用的数据集为既包含不同视角又包含目标数规模为12 000张的数据集,交并比阈值(Intersection Over Union, IOU)为0.5。实验对比结果见表1所列。

表1 YOLO模型的性能比较
从表1可以看出,YOLOv2、YOLOv3、YOLOv4网络模型的精确率分别为90.00%、93.00%、95.00%,召回率分别为67.20%、68.50%、69.30%,F1值分别为76.00%、78.00%、73.00%,平均检测精度分别为79.54%、83.12%、86.20%。实验表明,YOLOv4模型在所有的评价标准上均取得了最好的结果,且YOLOv3比YOLOv2结果更好。部分测试结果如图3所示。

图3 测试集在不同网络模型上的预测结果示例
4.1.2 不同IOU阈值对YOLO检测性能的影响
IOU是真实标记框与预测框的交并比,交并比越大,模型对目标的检测会更精确。本节实验主要探究IOU取值对模型性能的影响,这里对比IOU阈值分别为0.2、0.35、0.5和0.65时不同模型的性能指标,结果见表2所列。

表2 YOLO模型在不同IOU下的性能比较
鉴于猪只个体与其所在背景为二分类,故这里选择置信度值为0.5,当预测值大于0.5时视其为预测正确,预测值小于0.5时视为预测错误。
实验结果表明,随着IOU阈值的增大,模型的各项指标变化有较大差异。YOLO模型的各项性能都随着IOU阈值的增大而变小。虽然在IOU为0.2和0.35时,模型各项性能较高,但是由于预测框与真实标记框的交并比太小,预测结果并不理想。另一方面,当IOU阈值为0.65时,各个检测模型的性能剧烈下降达到10%~20%,检测性能较差,不能对猪只个体进行准确的检测。考虑交并比以及检测性能,本文选择IOU为0.5。
4.2 数据集构建方法验证
4.2.1 不同规模数据集训练模型性能的比较
为验证不同规模数据集对模型性能的影响。本节对比了包含4 000张、8 000张、12 000张图像的数据集下模型的检测性能。对比实验结果见表3所列。从表3可以看出,数据集规模越大,性能越好。验证了数据集规模对检测性能的正向影响。

表3 不同规模数据集下的模型性能比较
4.2.2 不同视角数据集训练模型性能的比较
为进一步深入研究不同视角的图片对所需要训练网络性能的影响,从侧视两个机位共计8 000张图片中随机选择4 000张图片制作一个数据集、制作一个包含4 000张俯视图片的数据集、制作一个既包含2 000张侧视图片又包含2 000张俯视图片的数据集。分别利用三个数据集来训练YOLOv4网络,并进行了对比和分析。训练后的模型所得结果见表4所列。从表中可以看出,包含两个视角的数据集取得了最好的效果,说明了视角多样性对检测结果起正向的影响。
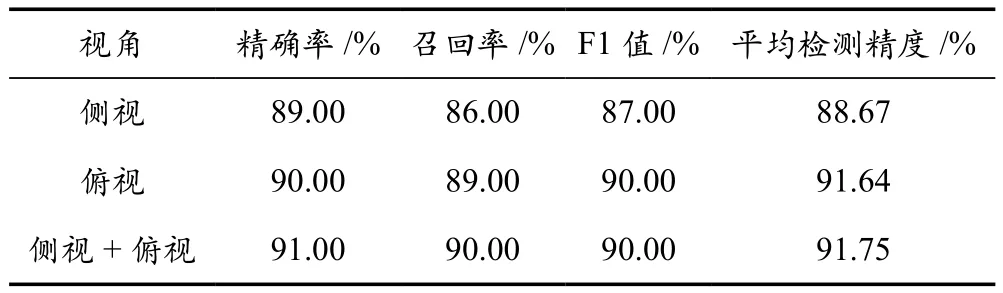
表4 不同视角训练集所训练的模型性能
4.2.3 不同目标数数据集训练模型性能的比较
为验证图片中包含目标物体个数对检测性能的影响,本节对比了三组实验,分别是少目标数据集、多目标数据集、少目标+多目标数据集。实验结果见表5所列。由表5可以看出,图片中包含目标物体多的数据集可以获得更好的性能,说明单图片中目标物体个数多可大大提升模型性能。

表5 不同目标数训练集所训练的模型性能
5 结 语
本文提出了基于YOLO模型的猪只检测模型;同时为了提高准确率,探讨了数据集构建方法。通过实验验证得出,YOLOv4模型可以获得最好的生猪检测性能;构建数据集可以选择大规模、多视角及多目标个体的样本,这种数据集包含的样本具有多样性,可提升检测模型的性能。
猜你喜欢
猪业科学(2022年11期)2022-12-17
中国畜禽种业(2020年4期)2020-12-16
河南畜牧兽医(2020年21期)2020-01-10
家庭影院技术(2019年8期)2019-08-27
猪业科学(2018年5期)2018-07-17
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
火炸药学报(2014年1期)2014-03-20
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
