
基于深度森林的电费差错分析
2022-01-17 08:55广东电网有限责任公司客户服务中心
电力设备管理 2021年15期
广东电网有限责任公司客户服务中心 覃 浩
电费差错是指电网公司在运输、分配电力过程中的异常计量信息错误或者配电侧用户的窃电行为造成的电费数据异常,这类异常数据会给电网公司造成严重的损失甚至对国民经济的发展也十分不利。所以更新当前的计量系统平台并且高效的稽查出非法窃电用户一直是国内外学者研究的重点。
目前智能电表的普及使得各用户用电信息采集完善,积累的数据也越来越多,在近年机器学习以及人工智能技术的趋势下研究者们从数据挖掘的角度出发来进行反窃电行为的研究,利用历史用电数据特征建立与窃电行为的联系。现有的异常电费检测方法大致分为三类,即基于距离的方法、基于统计的方法、与基于智能学习的方法。目前,基于机器学习和深度学习的方法,如支持向量机、随机森林、人工神经网络等算法模型己取得较好的检测效果,该类方法对数据特征的识别率高符合当前的研究思路。
针对电力大数据流的异常检测问题,提出一种基于流式K-means 的聚类算法,在优化离线阶段聚类算法的同时,提高算法对用户异常用电行为的准确识别[1];将疑似窃电判断中引入Oneclass SVM 算法,提出了一种将电量波动特征和One-class SVM 结合的窃电识别模型[2],采用电量波动系数作为指标选取训练样本的方法,训练得到相应分类模型,通过该模型分析筛选出窃电用户;结合决策树(Decision Tree,DT)和SVM 进行异常用电行为的识别,先排除干扰用户,再导入处理后的用户用电量数据训练SVM分类算法,从而识别出异常用电行为[3];选择孤立森林算法应用到用户用电异常检测问题,该方法优点在于规则简单易于训练并且速度很快,但是检测精度并不高[4];在一维用电数据上对窃电行为检测准确率很低,无法获取到用电的周期性,因此提出了一种集合广度与深度的卷积神经网络(convolutional neural networks,CNN)来解决上述问题[5]。深度CNN 组件负责准确识别窃电的非周期性和正常用电的周期性。同时,广义CNN 组件负责识别一维用电数据的全局特征;还有一种基于主成分分析和深度循环神经网络(PCA-RNN)的异常用电行为检测方法[6]。利用核主成分分析对电力负荷数据进行降维处理,提取出主要用电特征该方法具有较高的准确率和鲁棒性。
通过以上的研究进行分析,同时为了挖掘出用电用户信息的特征,本文尝试采用将深度森林[7]分类算法引入电费差错检测领域,深度森林算法是基于决策树的深度学习算法,它的核心思想是对随机森林进行集成相较于其他深度学习模型,深度森林方法每一层都自主训练参数,不需要反向传播过程,因此对于训练数据的样本数量依赖较低,本文从电费差错用户特征提取出发,利用深度森林算法检测用户是否存在窃电行为,探究其应用在电费差错检测领域的可行性并且极大地减少了训练时间。此外,深度森林的最基本单元由决策树构成,使得该模型具有较好的可解释性。
2 深度森林
深度森林模型于2017年提出,该模型是一个非神经网络式的深度模型,采用多粒度级联森林(gcForest,multi-Grained Cascade Forest)方法构建。gcForest 主要包含两个结构多粒度扫描窗口和级联森林。先进行多粒度扫描计算,采用多个不同尺度的滑动窗口对训练数据特征进行重新表示。该方法是滑动窗口进行扫描特征,所扫描的特征向量作为新的数据样本;然后将扫描得到的结果用于构建级联森林;级联森林由多种随机森林组成,其作用为对输入特征进行表征学习,每个级联层均包括两个随机森林和两个完全随机森林,其中各随机森林均含有若干棵决策树,因此每个随机森林或者完全随机森林都会输出一个特征向量预测结果。在级联森林中,上一个级联层的输出结果作为下一个级联层的输入,可以将特征向量的特征信息传至下一层,每一层都可以接收到上一层的特征信息和原始特征信息,最后一层的级联层作为结果输出;其中完全随机森林是在完整的特征空间中随机选取特征来分裂,而普通随机森林是在一个随机特征子空间内通过基尼系数来选取分裂节点。
深度森林本质上是基于决策树和随机森林来构建,可以对离散型与连续型的数据高效的训练,同时为了对模型的预测精度进行提升,构建的级联森林与深度学习中的多层网络类似,保证了对数据学习的深度。本文将深度森林算法引入电力负荷预测领域,也解决了深度模型参数多、收敛速度较慢等问题。综上所述,深度森林算法非常适合电费数据的特点,能够有效的学习电费数据的相关特征以构建电费差错分析模型。
3 实验
本文的训练数据样本与测试数据样本采用的是中国南方电网公司收集的2020年某月某市的用电数据样本,数据规模为2500 (电费差错数据1139条、非电费差错数据1361条),总共有65个特征字段,如YHLBDM、DSJ、YDLBDM、JLDBH 等,分别表示用户类别代码、地市局、用电类别代码、计量点编号等电费数据特征。
3.1 数据预处理
由于本文数据集是电网公司收集的真实数据,数据中存在着数据缺失和重复以及特征冗余等问题,经过对数据的探索发现缺失数据主要是多为单个数值缺失,为了使数据对模型的干扰影响最小,本文的数据预处理工作主要包括删除重复值及冗余特征、缺失值填充、特征归一化。
在原始的用电用户数据中经人工判断存在大量与电费差错无关的特征,如计量点编号、用户编号等,直接删除这类无关特征字段,降低模型训练的特征维度至45维。再针对连续多个以上的负荷值为0的重复数据,同样直接删除。在删除冗余特征和重复数据后对模型的训练速率有所提升且对模型的训练效果没有影响。
针对样本数据中的缺失值采用以下方式进行填充:
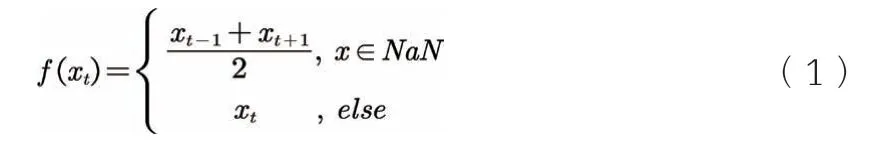
上式中,xt为用户在第t天的数据量,f(xt)为填充值,NaN 表示数据未定义或不可表示的值,即利用缺失值前后两天的数据量的平均值来进行填充。
在完成以上对重复值缺失值的处理后,为了使得深度森林模型在分类时具有更好的泛化能力,再对电费数据进行均值归一化处理。

其中,X为待归一化数据,Xscaled为均值归一化获得的数据,mean(X)为数据样本的均值,std(X)为数据样本的标准差。
3.2 模型评估指标
基于深度森林的电费差错分析实验中,目标是为了区别出电费差错数据与非电费差错数据属于二分类问题,采用准确率、召回率、F1值以及AUCROC 曲线来评估实验性能。
本文使用混淆矩阵评估深度森林分类模型在测试样本上的效果,对于窃电用户与正常用户的分类问题,其混淆矩阵如下表1,这其中,TP 是指被深度森林模型正确分类的电费正常用户;FN 是指被错误标记为电费异常用户的电费正常用户;FP 是指被错误分类为电费正常用户的电费异常用户;TN 是指被正确分类的电费异常用户。

表1 电费差错分析模型混淆矩阵
在电力客户用电数据中,电费差错与非电费差错用户数据量极度不均衡,因此采用如下评估标准:
查准率,代表模型预测为正常数据的样本中真正常数据占的比例:

F1值,综合了查准率和召回率的调和平均结果:

AUC-ROC 曲线是针对各种阈值设置下的分类问题的性能度量。ROC 是概率曲线,AUC 表示可分离的程度或测度,表明我们多少模型能够区分类别。AUC 越高,模型预测的效果越好。根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图就得到了ROC 曲线该曲线的纵轴是“真正例率”(True Positive Rate,TPR),横轴是“假正例率”(False Positive Rate,FPR),基于表1中的符号,两者分别定义为:

其中AUC 定义计算是ROC 曲线下与坐标轴围成的面积,该数值范围为0至1.0之间。又因为ROC曲线一般都处于y=x 这条直线的上方,则AUC 的取值范围在0.5和1.0之间。AUC 越接近1.0,表明检测方法可靠性越高。
3.3 实验结果
本文将预处理后的电费数据训练样本与测试样本以8:2划分,训练样本与测试样本分别为2000条和500条,其中训练样本中包含电费差错数据911条,测试样本中包含电费差错数据228条。将训练样本导入深度森林模型进行训练,再使用测试样本进行预测,测试结果如下表2所示:

表2 电费差错分析模型测试结果
综合以上所有实验结果,本模型的三项评估指标均达到了0.89以上,其中准确率和F1值较好的表现说明该模型对本电费差错分类效果良好,在图1中AUC-ROC 曲线中可以判断出AUC 是0.904属于0.85以上也证明了本算法的可行性,综合三项评估指标,可以看出本文基于深度森林的电费差错分析模型较好的完成了电费差错分析的任务。

图1 电费差错分析模型AUC-ROC 曲线
4 结语
本文提出了基于深度森林的电费差错分析方法,在电网公司的真实数据样本上取得了准确率、F1值均大于0.89的良好效果,AUC 曲线的数值为0.904也证实了本分类算法能够有效挖掘用电数据特征,区分电费差错用户与非电费差错用户。总体而言,基于深度森林的电费差错分析方法能够帮助电网公司更新当前的计量系统平台并且高效的稽查出非法窃电用户,大幅度的提升电网工作人员在电费差错方面的工作效率。
猜你喜欢
吉林电力(2022年1期)2022-11-10
军民两用技术与产品(2021年1期)2021-07-28
中学生数理化·中考版(2020年12期)2021-01-18
活力(2019年15期)2019-09-25
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
中华建设(2017年3期)2017-06-08
福建中学数学(2016年7期)2016-12-03
新闻传播(2016年17期)2016-07-19
财经界(学术版)(2015年20期)2015-12-23
