
基于深度学习的智能车牌识别系统研究
2022-01-17 06:28季丹
电子元器件与信息技术 2021年10期
季丹
(南京交通职业技术学院 电子信息工程学院,江苏 南京 211188)
0 引言
智能车牌识别是现代智能交通系统的重要组成部分,广泛应用于高速公路、停车场、路口等场景[1]。随着大数据、人工智能的不断发展,智能车牌识别在数据处理、自适应学习以及特殊场景训练等方面都有较大程度提升,具有更强的容错性和鲁棒性。通过车牌号码的自动识别与跟踪,能有效降低车辆自动化管理的成本,规范车辆不规范行为,为社会稳定与居民便捷生活提供坚实保障。
1 车牌识别的一般流程
车牌识别的一般流程包括原始车辆图片的获取、车牌检测与车牌识别三个步骤,如图1所示。其中车牌检测主要实现车牌在车辆图片中的检测、车牌图片的定位及预处理等,常用的检测技术包括基于传统的特征检测及基于深度学习的车牌检测。针对数据量一般,对雨雪、光照等环境要求不高的情况,可采用传统特征检测,对车牌色彩、纹理、边缘等关键特征进行提取。比如采用Mallat算法和小波变换进行区域边缘特征提取[2];结合颜色分割及Sobel算子实现车牌颜色边缘特征提取[3]。针对干扰因素较多的复杂场景,可采用深度学习算法,比如SSD卷积神经网络等[4]实现快速检测与定位。
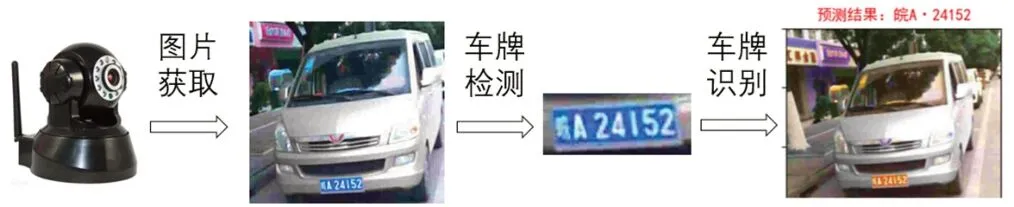
图1 车牌识别一般流程
随着深度学习在计算机视觉领域取得的重大突破,利用神经网络进行车牌识别也取得了丰硕成果,尤其针对车牌倾斜、脏污和复杂天气环境下等字符识别有较高辨识率,主要涉及基于切割及基于端到端的车牌字符识别技术。比如,通过反向学习策略,将局部连接层连接到卷积层,实现了CNN卷积神经网络对车牌字符的识别[5];提出了一种基于YOLO深度学习算法的航拍图像车辆检测方法[6];基于Faster R-CNN和YOLO算法提出了遥感大数据目标检测网络[7]等。
2 智能车牌识别系统的设计思路
为增强车牌检测的容错率以及车牌字符识别的精确度,本设计将采用CenterNet Resnet目标检测以及循环神经网络CNN共同实现智能车牌识别功能,其整体设计框架如图2所示。针对采集的车牌图像,采用CenterNet目标检测,对原始车辆图片进行车牌目标位置的定位、检测与保存,再对车牌图片进行直方图均衡、灰度处理、倾斜矫正等预处理操作后,得到较为精确的车牌图像信息。将处理后的车牌字符传入卷积神经网络进行模型的训练与优化,最终预测得到较为准确的车牌识别结果。

图2 智能车牌识别系统设计框架
3 基于深度学习的智能车牌识别系统的实现
3.1 基于CenterNet Resnet的车牌检测
2019年,Xingyi Zhou,等人在“Objects as Points”一文中提出了基于中心点的CenterNet Resnet目标检测网络,它通过关键点估计来找到物体中心点,并回归到对象属性上,如大小、3D位置、方向甚至姿势[8],相较于Faster-RCNN、Retina Net、YOLOv3等算法,该结构在速度和精度上都较占优势。
系统采用CenterNet网络结构实现车牌检测,具体流程描述如下:
步骤1 选择Resnet50作为目标检测网络,即对输入车辆图片进行50次卷积操作,实现特征提取;
步骤2 通过反卷积模块,对上一步得到的特征图片进行三次上采样,得到增强后的特征图片;
步骤3 将上一步的特征图片放入三个分支卷积网络,分别预测检测目标的热力图heatmap、目标的宽度与高度占比以及目标的中心点坐标,所得参数可用于车牌图片的截取。
步骤4 采用仿射变换,在原图中实现检测目标的裁剪和缩放,用边框框出车牌位置,并显示位置比例,测试效果如图3所示。

图3 采用CenterNet实现车牌检测
3.2 车牌图像预处理
通过CenterNet截取出的车牌图像数据集中存在车牌位置倾斜、照明不均匀、车牌不清晰等多种特殊情况,因此车牌图像的预处理显得尤为重要,甚至直接影响车牌字符的读取和字符识别的精度。本系统车牌图片预处理的步骤描述如下:
步骤1 采用直方图均衡化方法,增强车牌图片的对比度。因每张图片都是彩色的,包括BGR三个通道,不同通道都可能出现暗部细节不足或丢失的情况,因此可将车牌图片的直方图分布变成近似均匀分布,从而实现图像增强功能;
步骤2 采用基于幂次变换的伽马校正实现图片的灰度处理,将输入图片的灰度值进行指数变换,从而拓展暗部细节,也便于加快运算速度;
步骤3 检测灰度变换后的车牌图片是否存在倾斜,如存在,则采用霍夫变换检测车牌的边界形状,不断拟合车牌的边界线条,然后通过空间角度的调整,实现车牌图片的矫正;
步骤4 通过统计边框像素出现的频率,对矫正后的车牌图片进行边缘去除。每一步处理效果如图4所示。

图4 车牌图像预处理过程
3.3 基于CNN的车牌识别模型的搭建
车牌识别较为常用的手段是基于车牌字符的分割,但实际情况中车牌图片容易出现倾斜、污损、不清晰等情况,导致字符分割不准确或不完整,因此系统采用基于CNN卷积神经网络实现端到端的车牌字符识别。
在网络搭建前先明确输入与输出变量。由于预处理后的车牌图片大小不一致,此处将所有图片统一缩放为宽240px,高80px的图片,灰度处理后统一选择一维通道。假设训练集样本数量为N张,则网络的输入层维度则为N×80×240×1。输出层要识别的车牌字符有7位,第一位为省份字符(共34个),后6位为除去“I”和“O”的字母及0-9数字的组合(共34个),由此可知网络的输出变量字对应离散的68个字符。
构建CNN卷积神经网络模型如图5所示,包含三个卷积图、1个扁平层、1个全连接层。其中每个卷积图都包含两个卷积层(C)、1个池化层(S)和1个丢弃层(D)。第一次卷积核为32,卷积形状为3×3,第二次为64,第三次为128,每次采用relu激活函数增强数据的拟合度,三次卷积图操作后实现重要特征的提取。展平层将三维数据信息展开成一维向量,随机丢弃30%后输入至全连接层。全连接层采用Softmax函数输对应字符信息。
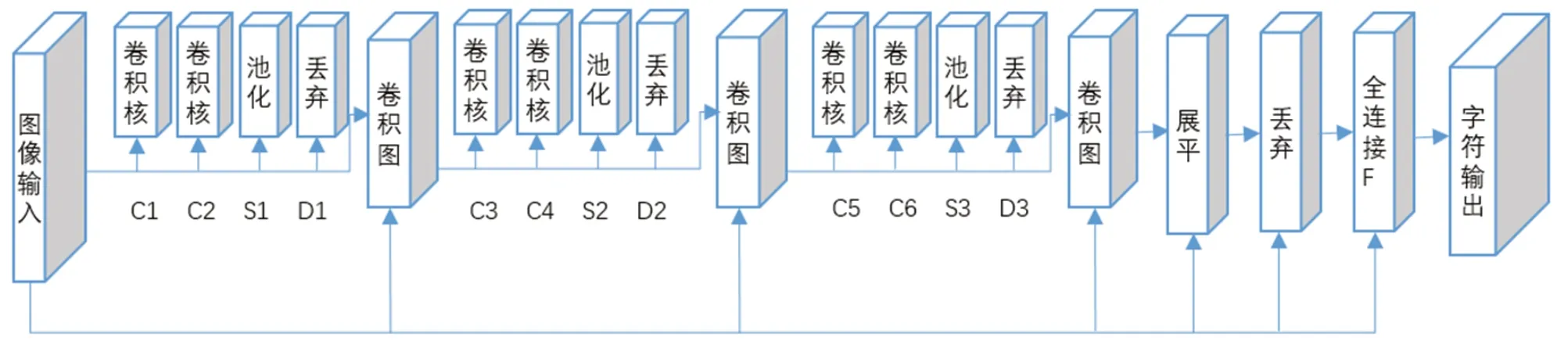
图5 CNN卷积神经网络结构
具体参数及函数选择如下:
(1)卷积图:第一个卷积图中,C1的卷积核大小为32,卷积形状为3×3,C2的卷积形状为2×2,随机丢弃50%样本;第二个卷积图中,C2的卷积核大小为64,卷积形状为3×3,C4的卷积形状为2×2,随机丢弃50%样本;第三个卷积图中,C5的卷积核为128,卷积形状为3×3,C6的卷积形状为2×2,随机丢弃50%样本。卷积后采用relu非线性函数增强数据的拟合度。
(2)池化层:基于最大值原则,根据池化形状进行欠采样,有效降低特征维度,一般选择2×2的池化形状。
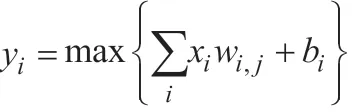
(4)输出层:将全连接层得到的神经元分类结果输入Softmax函数,并映射至(0,1)区间内。模型训练期间以交叉熵为损失函数,不断监控损失最小值,由此判断字符匹配的概率。
4 智能车牌识别系统的训练与测试
本系统以公开的中国城市停车数据集(Chinese City Parking Dataset, CCPD)为基础,随机选取了6000张车辆图片,包含了不同天气、不同光照角度、不同车辆位置以及倾斜和模糊的车辆样本。实验选取4000张作为训练集进行模型的训练与优化,2000张作为测试集进行结果验证。
将所有车辆图片经过CenterNet网络进行车牌检测与截取后,进行对比度增强、灰度处理、倾斜校正以及去边缘化等预处理操作,并获取处理过后的图像通道信息转换为tensor变量传入CNN网络。模型编译时选择Adam自适应优化器,以交叉熵作为监控损失值,在训练过程中保存损失值最小的模型参数,便于测试样本的验证。实验中epoch设为200,训练时最小损失值为0.0315,模型的识别准确率达到94.7%。
该模型针对不同的光照变化、不同角度、不同清晰度的车牌识别都有较高的辨别度,识别效果如图6所示。

图6 不同场景下车牌智能识别
5 结论
随着人工智能的不断发展,将深度学习算法应用于车牌识别领域屡见不鲜,然而部分算法在简单场景下有较高的识别效果,但对于不同光照、不同环境、不同天气、不同清晰度等多变的场景识别,还存在一定难度,且不同神经网络的选择或者网络参数的自适应调整都会进一步影响车牌识别效率。本系统选择CenterNet网络进行车牌定位与检测,选择直方图均衡化、倾斜度矫正等图像预处理技术增强车牌的对比度,都为后续卷积神经网络的训练提供了有效保障。测试结果显示,该系统能有效辨别不同场景下车牌信息,且平均识别准确率高。
猜你喜欢
温州大学学报(自然科学版)(2022年2期)2022-05-30
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
数字通信世界(2019年3期)2019-04-19
制导与引信(2017年3期)2017-11-02
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
工业设计(2016年11期)2016-04-16
