
改进PSO-BPNN算法在管道腐蚀预测中的应用
2022-01-17 08:06:28张恒宾刘宏伟
郑州大学学报(工学版) 2022年1期
肖 斌, 张恒宾, 刘宏伟
(西南石油大学 计算机科学学院,四川 成都 610500)
0 引言
管道输送在石油和天然气的运输中起着重要的作用,但随着管道服役时间的增长,管道会出现不同程度的腐蚀缺陷,在腐蚀严重的情况下,会引起管道泄漏或爆炸,不仅影响油气管道正常运输,甚至会危害人民生命财产安全和生态环境。因此,研究腐蚀管道的剩余强度具有重要意义。
目前,许多专家已经采用实验、数值分析或经验方法对腐蚀管道的剩余强度进行了深入研究。Abdalla等[1]分析了孤立点腐蚀缺陷的应力分布;Wang等[2]考虑管道几何形状等因素分析了管道强度极限状态;臧雪瑞等[3]分析了X100等级输气管道的失效压力模型。通过相关研究结果可以发现,腐蚀管道剩余强度预测的最常用方法是公式计算和有限元分析。但是公式计算方法的准确率较低,且无法适用于所有管道,而有限元分析过程又较为复杂[4],比如常规的有限分析过程包括确定边界条件,建立模型,设计变量、公式和求解方程,整个过程需要进行大量假设,并且需要耗费大量时间。
近年来,由人工神经网络建立的非线性映射关系预测模型受到众多学者的关注,三层的神经网络理论上可以拟合任意的非线性函数,相比起有限元分析和回归模型可以更加精确地拟合实验数据,实现更高质量的预测,具有非常广阔的应用前景。但传统的神经网络仍然存在容易陷入局部最优等问题,而启发式搜索算法不要求目标函数连续、可微等信息,具有较好的全局寻优能力[5],所以启发式搜索算法可对神经网络参数进行初始化。
本文提出了一种新的非线性递减惯性权重粒子群算法,以解决其存在的局部最优和易早熟问题;然后使用改进的粒子群算法对神经网络的初始权重和阈值进行优化,以解决神经网络本身的局限性,从而建立了预测模型;最后使用模型在2个真实的管道爆破数据集上进行实验,结果表明,相比其他模型,所提算法可以更准确地预测腐蚀管道的剩余强度。
1 相关工作
粒子群优化算法(PSO)是一种群体智能优化算法[6],粒子群优化算法的数学描述如下。
假设在一个D维的目标搜索空间中,有m个代表问题潜在解的粒子组成一个种群。第i个粒子的位置记为Xi=[xi1,xi2,…,xiD]T,其速度记为Vi=[vi1,vi2,…,viD]T。首先随机初始化m个粒子,然后迭代找到最优解。每一次迭代中,粒子通过跟踪2个极值Pi=[pi1,pi2,…,piD]T、Pg=[pg1,pg2,…,pgD]T进行信息交流。即根据式(1)和式(2)更新自己的速度和位置:
(1)
(2)

为了提高原始粒子群算法的收敛性能,Shi等[7]提出了一种改进的粒子群算法:在速度更新过程中引入惯性权重,新的速度迭代式如下所示:
(3)
式中:w为惯性权重,决定了粒子当前速度对下次迭代时速度的影响。
多年来,文献中报道了自适应惯性权重[8]、随机惯性权重[9]、线性减少惯性权重[10]、非线性减少惯性权重[11]等多种权重变化策略。
交叉主要用于遗传算法中增加后代种群多样性,随着研究深入,已有很多学者将交叉思想引入粒子群算法来增加粒子的多样性[12]。
2 神经网络优化预测模型
2.1 改进的粒子群算法
在标准粒子群优化算法中,惯性权重为固定值,后来发现动态变化的惯性权重寻优结果比固定值好。在许多研究中,通常选择线性递减惯性权重[7],其算法如式(4)所示:
(4)
式中:t为当前迭代次数;tmax为粒子的最大迭代次数;wmax为惯性权重的最大值,wmin为惯性权重的最小值,通常取值为wmax=0.9,wmin=0.4。
为了更好地保持全局和局部搜索能力之间的平衡,Saxena等[13]提出了一种非线性递减惯性权重,但是使用时惯性权重会长时间保持在0.7,从而使粒子丧失局部寻优能力。本文在文献[13]的基础上提出了一种新的非线性递减惯性权重,如式(5)、(6)所示:
Δ=(wstart)2-(wend)2。
(5)
w=
(6)
式中:wstart为惯性权重的迭代的初始值,wend为惯性权重的迭代的结束值,通常取值为wstart=0.7,wend=0.4。
该权重在迭代的前期能快速下降,使得粒子能够快速拉进与最低点之间的距离,同时避免陷入局部最优解,在后期下降较为缓慢从而得到最优解。如图1所示,权重的递减速度在迭代过程中呈现出先快后慢的非线性模式。

图1 非惯性权重值下降曲线Figure 1 Non-linear inertia weight value decreasing curve
同时,基于引入的交叉思想[12],在每次迭代中,根据杂交概率选择一定数量的粒子,放入杂交池中,然后池中的粒子成对随机交叉生成相同数量的后代粒子,最后使用子粒子替换父粒子以增强粒子多样性。子粒子的位置和速度通过父粒子的位置和速度交叉获得。位置交叉公式如下:
qx=λpx(1)+(1-λ)px(2)。
(7)
式中:px为父粒子的位置;qx为子粒子的位置;λ为0到1之间的随机数。
子粒子的速度计算式如下:
(8)
式中:pv为父粒子速度;qv为子粒子速度。
2.2 IPSO-BPNN算法
针对神经网络收敛缓慢且容易陷入局部最优问题,本文使用改进的PSO算法(IPSO)对神经网络进行优化,提高神经网络寻找全局最优解的能力。IPSO-BPNN算法步骤如下。
Step1建立3层网络拓扑结构,确定输入层、隐藏层和输出层的节点个数。
Step2初始化粒子群参数。
Step3进行IPSO算法训练,计算每个粒子适应度值,根据式(3)、(2)更新粒子的速度和位置,根据式(6)更新粒子权重,更新Pi和Pg。
Step4进行交叉。根据杂交的概率选择一定数量的颗粒进行杂交,根据式(7)和(8)计算子粒子的位置和速度。
Step5重复Step 3和Step 4,直到算法误差满足要求或训练次数达到最大迭代次数。
Step6使用Step 5得到的全局最优值优化神经网络的初始权重和阈值。训练神经网络,输出网络的预测值,计算网络误差,将误差传播回输出层并调整权重和阈值。重复上述过程,直到满足算法的终止条件或达到最大迭代次数为止。
2.3 时间复杂度对比
在IPSO算法中,对于n个样本,使用两层循环寻优,第1层循环为最大迭代次数j,第2层循环为种群粒子数k,由于k和j都是常量,因此得到粒子群算法的时间复杂度为O(1)。而对于一个l层的全连接神经网络,如果在输出层通过激活函数输出最后结果,则P轮训练进行了2(l-1)mn次计算,由于l和m为常量,因此整个算法的时间复杂度可以近似为O(n)。
在有限元分析中重要的步骤是联立方程组求解,其主要方法包括Gauss消元法、共轭梯度法等。Gauss消元法的时间复杂度为O(n3),共轭梯度法和其他迭代法的时间复杂度为O(n2)。而且在实际应用中,FEA方法通常还需要花费大量的时间来建模,此步骤花费的时间通常多于求解计算的时间。因此IPSO-BPNN算法能有效提高预测效率,节省时间。
3 实验与分析
3.1 IPSO算法对比实验
实验选择了如表1所示的4个基准函数作为测试函数。其中F1,F2是单峰函数编号,只有一个最优值,F3和F4则是多峰函数编号,具有多个局部最优值。同时,还对IPSO算法与标准粒子群算法(PSO)、线性递减惯性权重粒子群算法(LPSO)、自适应权重粒子群算法(APSO)和随机权重粒子群算法(RPSO)[14]进行了对比分析。
3.1.1 实验设置
为了对5种使用不同权重策略的粒子群算法进行公正和客观的比较,惯性权重的最小值和最大值分别设为0.4和0.9,算法最大迭代次数设为1 000,学习因子c1和c2的取值均为2,粒子种群规模大小为40,交叉池大小比例为0.1,交叉概率为0.8,对每个基准函数进行了30次重复实验,并记录了实验过程中的最优值、平均值用于评估算法的优化精度,使用标准差(SD)评估优化稳定性。

表1 4个基准测试函数Table 1 Four benchmark test functions
3.1.2 结果分析
仿真结果如表2所示。从表2中可以看出,IPSO在前2个测试函数中的平均值、标准差优于PSO、LPSO、APSO和RPSO,而在后2个函数中也表现出了较好的效果。
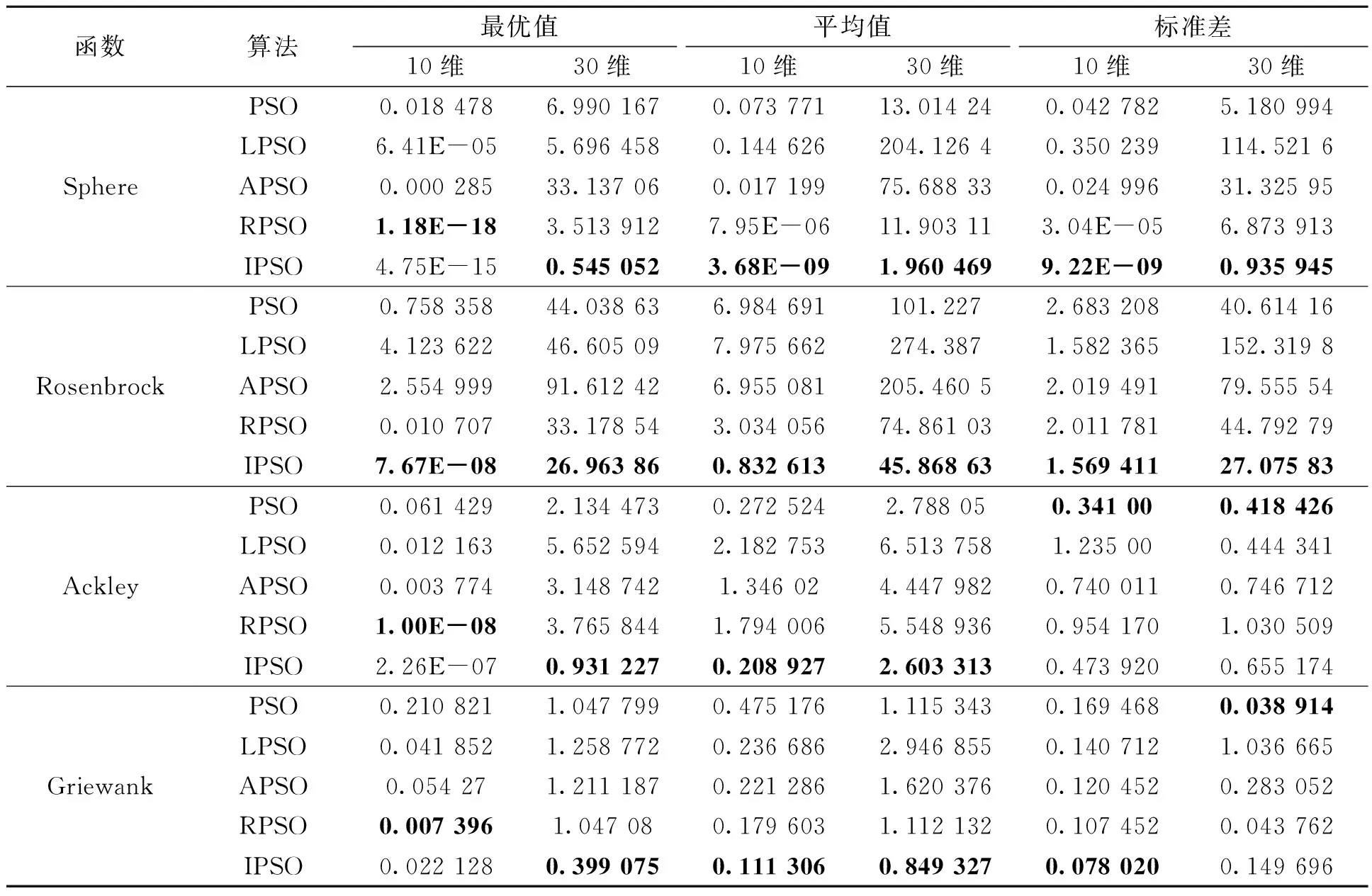
表2 4种算法仿真结果Table 2 Simulation results of five algorithms
图2是5种算法对30维的4个测试函数的平均适应度曲线,纵轴为每一次迭代中适应度函数值的平均值,横轴为迭代次数,因为函数值波动较大,对函数的适应度值取对数[15]。从图2中可以看出,相比其他几种算法,IPSO具有更快的收敛速度和更好的平均适应度,表明该算法有更好的鲁棒性和适用性。

图2 5种算法在4个测试函数上的平均适应度曲线(30维)Figure 2 Average fitness curve of five algorithms for four test functions (30D)
3.2 IPSO-BPNN预测腐蚀管道剩余强度实验
3.2.1 数据来源
为了验证本文提出的IPSO-BPNN模型的预测性能,从文献[16-21]中收集了161组真实管道爆破数据用于管道剩余强度预测。数据集1有79组数据,其中66组数据参与训练,13组数据用于验证;数据集2有82组数据,其中66组数据参与训练,16组数据用于验证。本文选择了5个因素作为输入变量,分别为管线钢级(取值X42~X100,包含了常用的高等级管线的主要钢级)、管道直径(取值323~1 320 mm)、管道壁厚(取值4.67~22.9 mm)、缺陷深度(取值0~15 mm)、缺陷长度(取值0~1 110 mm)。爆破压力是输出变量,单位为MPa。
3.2.2 数据预处理
首先对数据里的非数值数据如管线钢级进行处理,转换成数值类型。由于数据集中的5个变量分别对应于不同的纲度和数量范围,有必要对数据进行规范化处理。这里采用归一化操作,归一化表示如式(9)所示:
(9)
3.2.3 评估标准
评估该模型预测性能的指标是平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)[22],其定义为
(10)
(11)
(12)
式中:yir为第i个样本的真实值;yip为第i个样本的预测值;n为样本数量。
3.2.4 参数设置
本文选择3层神经网络,包括5个输入层节点和1个输出层节点。隐藏层中的节点数根据式(13)为3~13个:
(13)
式中:nin为输入层节点的个数;nout为输出层节点的个数;α为0~10的常数。
根据计算得到的节点范围进行测试,选择均方根误差最小的节点数作为隐藏层节点的最终数目。由图3可知,当隐藏层中的节点数为9时,神经网络预测的均方根误差最小。
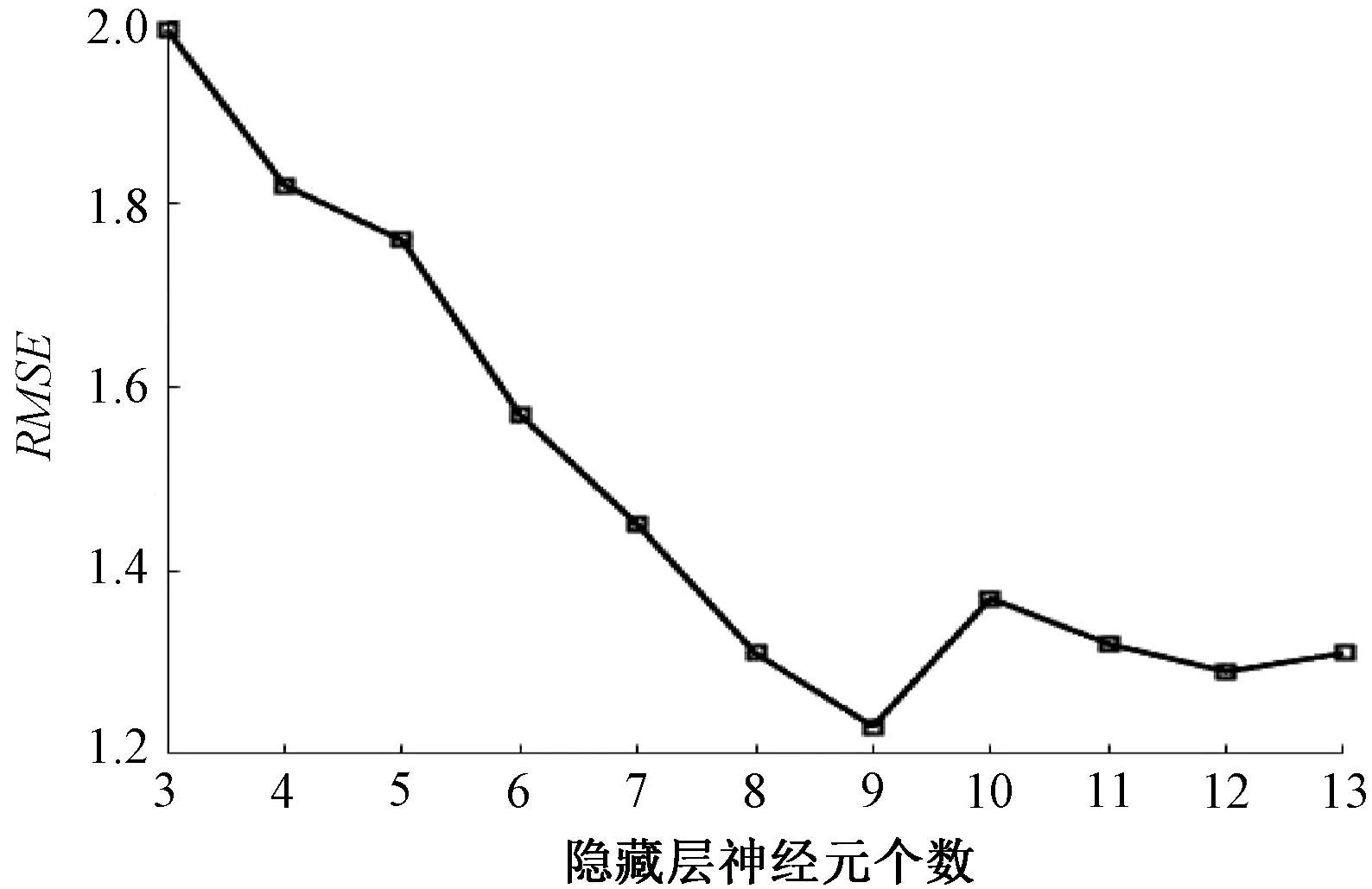
图3 均方根误差与隐藏层节点之间的关系Figure 3 Relationship between root mean square error and hidden layer notes
IPSO参数设置:种群大小为40,粒子维度为64,学习因子c1和c2均为2;惯性权重的最小值和最大值分别为0.4和0.9;粒子速度值为[-1,1];粒子位置值为[-4,4];杂交池的大小比为0.1,杂交的概率为0.8。
3.2.5 结果分析
为了更好地对比和评价模型的准确性,将IPSO-BPNN与线性回归(LR)、有限元分析(FEA)、前馈神经网络(BPNN)和粒子群算法优化神经网络(PSO-BPNN)在2个数据集中的预测结果进行了对比,各项指标如表3所示,预测结果的相对误差对比如图4所示。

表3 5种模型测试结果 Table 3 Test result of five models
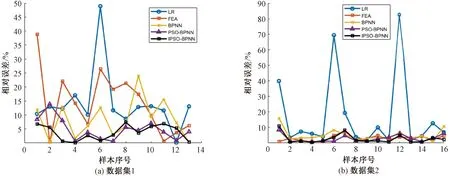
图4 数据集相对误差变化曲线Figure 4 Relative error curve of the dataset
从表3可以看出,在2个数据集中,本文提出的IPSO-BPNN预测模型的各项指标均优于其他对比模型,显示出了更高的准确性。从图4可以看出,IPSO-BPNN在测试集中的相对误差都保持在10%以内,表明该模型对数据的整体拟合效果较好,显示出了较高的稳定性。
4 结论
传统的神经网络在预测腐蚀管道的剩余强度时波动很大,很容易陷入局部最优状态。本文使用PSO-BPNN算法来预测腐蚀管道的残余强度,通过非线性递减惯性权重和杂交增加粒子的多样性,克服了神经网络容易陷入局部最优的缺点。与LR、FEA、BPNN和PSO-BPNN模型相比,IPSO-BPNN模型可以提高腐蚀管道残余强度的预测精度。所提算法适用于各个钢级的单腐蚀输油管线的剩余强度预测,可以为管道检查提供较为准确的依据。本文只考虑了单一腐蚀缺陷管道的剩余强度情况,下一步的研究重点是对复合型腐蚀缺陷管道进行分析和评价。
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21 00:40:16
中学生数理化·八年级物理人教版(2022年3期)2022-03-16 05:55:06
当代陕西(2020年17期)2020-10-28 08:18:18
测控技术(2018年10期)2018-11-25 09:35:54
人大建设(2018年5期)2018-08-16 07:09:00
浙江工业大学学报(2017年5期)2018-01-22 02:03:46
中学生数理化·八年级物理人教版(2017年3期)2017-11-09 03:05:23
电信科学(2017年6期)2017-07-01 15:44:57
小学科学(学生版)(2016年1期)2016-10-09 01:53:02
河南科技(2014年15期)2014-02-27 14:12:51
