
倾斜车牌识别方法的研究*
2022-01-15 06:24:44张玉祖罗素云
计算机与数字工程 2021年12期
张玉祖 罗素云
(上海工程技术大学机械与汽车工程学院 上海 201620)
1 引言
据统计,截至2018年底全国汽车保有量达2.4亿辆,道路交通问题出现的越来越频繁。仅仅依赖增加多条道路的数量和人力资源的监督,已经不能够解决当今的交通道路问题。为了从根本上解决交通安全问题问题,建立智能交通系统(ITS)已成为必然的趋势[1]。ITS为解决道路交通安全问题,全面考虑了汽车、行人、道路等多种因素。汽车牌照作为一种识别标志,能够既快速又准确地识别车牌号码在ITS中尤为重要。对于倾斜车牌矫正技术,我国提出了霍夫变换[2~3]、Radon变换[2]等方法实现车牌的矫正。但是上述方法在边框遮挡或车牌模糊的情况下却仍然很难达到期望的效果。又因为识别系统采集的车牌图像存在倾斜、字符粘连的情况,难以快速定位、矫正等问题,导致识别效果差,故本文提出一种倾斜车牌定位与矫正方法,实现车牌定位、倾斜矫正与字符分割、识别。
2 图像预处理
2.1 灰度处理
从彩色(REB)图像中提取出有效信息,往往采用灰度化处理[5]。由于计算机处理灰度图像更加快速,且占用的内存更小,故将彩色图像转换为灰度图像。灰度化处理指的是将RGB图像中三原色R、G、B分量分别乘上不相同的权值,再加权平均。公式[6]为
其中:经过实验论证,为得到较为合适的灰度图,WR、WG、WG分别取值0.299、0.587、0.114。Y为灰度化处理后的图像的像素值,R、G、B分别为彩色图中红、绿、蓝三原色的分量。效果如图1(a)所示。

图1 图像预处理
2.2 滤波处理
噪声会影响图像的质量,故为降低噪声对图像的干扰,本文使用高斯滤波的方法将图像进行去噪处理。高斯滤波属于线性平滑滤波,是图像减噪中应用最广的,其主要是用来消除高斯噪声。图像高斯滤波简单来说,是通过高斯核函数对图像进行卷积运算。高斯核函数[6]的公式为
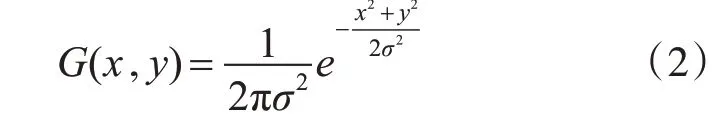
其中,x和y分别表示距离坐标原点的水平和垂直距离,σ为高斯分布中的标准差。本文为了去除掉在图像中的多余噪声,且保留更多的车牌字符信息,选用高斯滤波器5×5的核函数,进行降噪处理。效果如图1(b)所示。
2.3 基于颜色信息二值化处理
基于颜色的二值化处理就是通过颜色信息将图像二值化,正常曝光的车牌各个通道的颜色信息大约是Blue=138,Green=63,Red=23。但是颜色信息有一定的偏差,因此在二值化时放宽颜色条件,然后再通过其他特点来精确寻找车牌区域。本文设置各个通道的偏差值为50。
二值化指的是在图像中选中一个阈值T,当图像中存在某个灰度值大于T时,将其灰度值设置为255,否则即为0。公式如下:
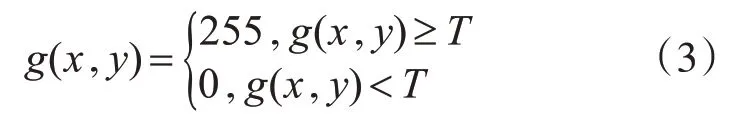
选择阈值T时,采用自适应阈值法。二值化后的图像如图1(c)所示。
2.4 形态学处理
从二值化的图像可以看出车牌区域基本完整,其他地方有一些细小的干扰,接下来进行形态学处理,消除小区域干扰。形态学闭操作——先膨胀后腐蚀,其特点是填充细小空间,连接临近物体和平滑边界,不同矩形窗的大小会有不同的结果[5]。形态学效果如图1(d)所示。
3 车牌定位
鉴于车牌本身就存在特殊性,如轮廓尺寸、形状等,故能够依据其特点来进行定位。
3.1 车牌的特点
1)车牌的长、宽比例在一定范围内。车牌宽度为440mm,高度为140mm,宽高比大约为3.14。
2)车牌是一个矩形的边框,在其边框中存在均匀间隔的字符。
3)车牌的矩形区域中,有规则的纹理特征和丰富的边缘信息。
4)字符和车牌底色的灰度值差异明显,有突变。
5)车牌中字符的宽度和高度分别为45mm和90mm,其比值为0.5。
国内标准的车牌外轮廓为矩形,尺寸为440×140mm2,其宽高比的比值约为3∶1[13]。故可以利用这种固有特征进行车牌边框提取车牌。
3.2 车牌定位的方法
先对原图进行灰度化、降噪,再进行基于颜色信息图像二值化,使用形态学的膨胀闭处理使图片中的边缘连通起来,形成类似矩形的区域。最后运用尺寸验证算法得到车牌的区域。
处理步骤如下:
1)寻找各个空白区域外轮廓并计算面积;
2)为各个空白区域增加外接矩形并计算面积;
3)通过外轮廓面积与外接矩形的比值,判断区域的矩形度;
4)进一步判断长宽比;
5)满足全部条件确定车牌区域。
6)提取车牌区域。
车牌定位图像如图所示。

图2 车牌区域
图3 提取车牌
4 车牌矫正
在汽车车牌字符识别系统中,较为理想的是其采集的图像中的车牌区域应均近似为矩形,但在实际的道路环境中,拍摄的相机的位置是固定不变的,车辆的形态是变化的。这样相机拍摄的角度有差异,会导致相机拍摄出来的车牌图像存在倾斜的情况。其进行初步定位时,其阈值会存在一些偏差,造成初步定位后的车牌图像会包含非车牌的部分图像,如边框、铆钉等。这样若直接进行下一步的字符分割与识别,可能会出现误差[7,10]。所以,在车牌进行初步定位之后,需要将车牌倾斜矫正,再进行后续的车牌字符分割等处理。
车牌矫正的主要方法有两种:霍夫变换和Radon变换。霍夫变换主要是对上下边框的检测,当车牌的边框存在不清晰或被污染的时候,无法实现计算需要倾斜的角度值[10]。Radon变换是将图像在不同的角度的投影直方图进行比较,来得到车牌需要倾斜角度,这种方法比较复杂,且计算量高,且容易受到噪声的干扰,其鲁棒性较差。
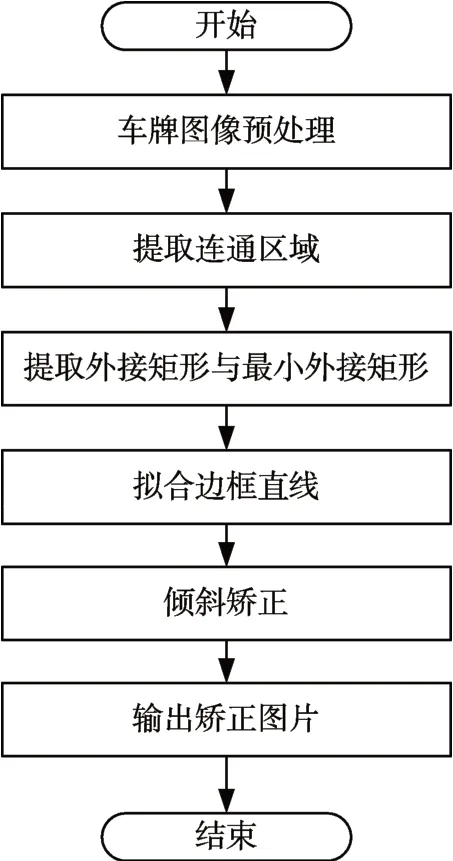
图4 车牌倾斜矫正算法流程图
本文提出了一种基于外接矩形与仿射变换相结合的车牌矫正方法,首先提取每个字符的外接矩形和最小的外接矩形;再利用RANSAC算法作直线拟合;最后采用仿射变换的方法,将车牌四个顶点仿射变换后的矩阵,得到变换后的车牌标准尺寸。
4.1 图像的预处理
图像的预处理能够提取到感兴趣的连通区域,并且去除了部分噪声[15]。本文主要的预处理步骤如下。
1)直方图均衡化。将定位后的车牌图像进行灰度化处理,将灰度图像进行直方图均衡化,作用是使得图像的对比度提高,且亮度更加均衡。
2)形态学去噪。将图像采用3×3的形态学算子进行先腐蚀后膨胀的操作,作用是除去细小噪声区域。
4.2 提取车牌字符外接矩形
在预处理后的车牌图像中,提取字符外接矩形,字符的外接矩形端点位置大致分布在一条直线上,其余偏离此直线的点为噪声点。在实际应用中获取到的数据,存在噪声数据不利于模型的构建,噪声数据点称为outliers,反之,有积极作用的数据点就为inliers。RANSAC算法是随机的选取一些点构建一个模型,用此模型去筛选其余的数据点,若该数据点在误差范围内,判为inlier,否则为outlier。inliers的数量需满足设定的某阈值,则数据点集就可以接受,否则需要不断重复该步骤,直到满足该阈值。此时构建的模型为最优模型。
因此,车牌图像需要进行以下处理:
1)首先先建立候选点集合P包括全部的外接矩形端点。
2)采用RANSAC算法对P中的点随机取点,拟合直线L。
3)从P中删除掉距离该直线L上最远的点。
4)重复步骤2)、3),直到点集中,且剩余点的个数为14。
执行以上步骤后,能够删除掉字符区域以外的大部分的噪声点。设置阈值T为22.5,将外接矩形的端点到直线L的距离小于T的矩形作为侯选矩形集合。
4.3 基于仿射变换的倾斜矫正
仿射变换属于线性变换,表示的是两幅图之间的一种映射关系。仿射变换可表示:旋转(线性变换)、平移(向量加)、缩放操作(线性变换)。其优势是图像能够保持平直性、平行性。仿射变换主要利用getRotationMatrix2D()函数得到。
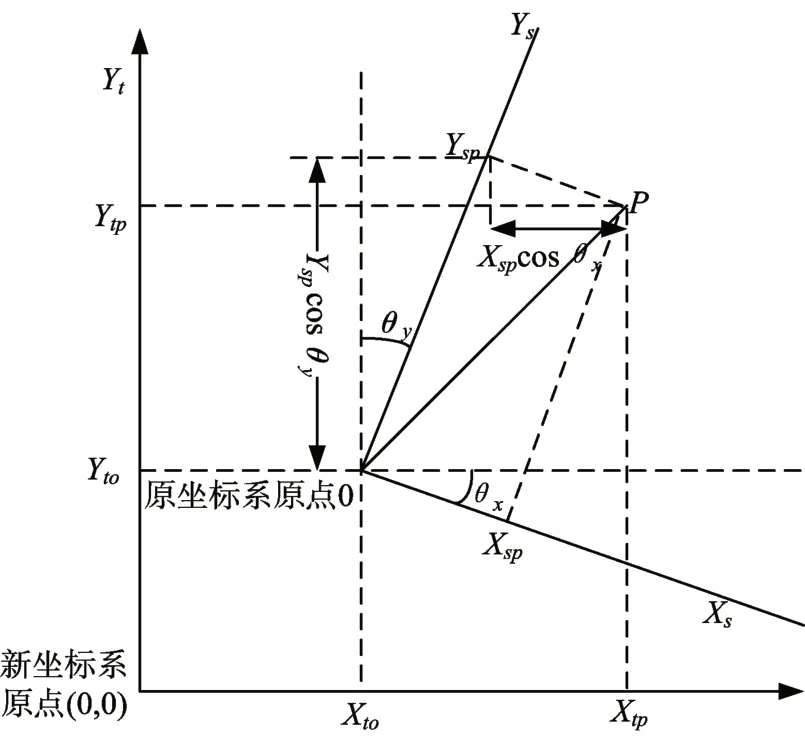
图5 仿射变换原理图
在原始坐标系下,点P的坐标是(Xsp,Ysp)。旋转坐标系中某个点,能够等同于旋转坐标轴,故建立屏幕水平垂直和以(Xs0,Ys0)为中心的虚线坐标系。在此坐标系中找到P的坐标,和在原坐标系中旋转后P的坐标是等同的。故只需计算出P在新坐标系中的坐标,P在新坐标系中的X和Y坐标为(Yspsin θy+Xspcos θx,Yspcos θy-Xspsin θx)。仿射变换模型为
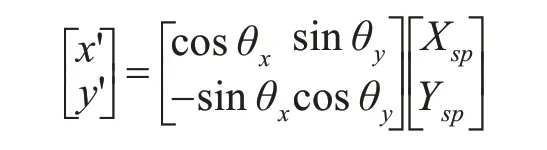
旋转后,在P在新坐标系中的位置基础上加上其在X轴、Y轴的偏移量,得到:
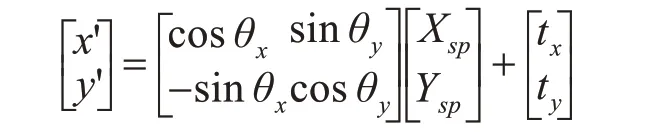
使用仿射变换的倾斜矫正主要分为三个步骤:求解仿射变换矩阵,对顶点直接的映射,解出变换矩阵。对于定位后的车牌,首先进行旋转角度的判定,在-5°~5°范围内车牌直接输出,在-60°~-5°和5°~60°范围内车牌,首先进行偏斜程度的判定,如果偏斜程度不严重,旋转后输出,否则旋转角度后还需要仿射变换。

图6 算法效果图
本文提出的算法与传统算法相比,在车牌边框残缺或无边框时,其矫正速度快且准确率较高。为验证本文算法的有效性,设计了两组实验:车牌边框不完整的图像和去除车牌边框的图像各100张。分别采用Hough变换、Radon变换和本文方法进行车牌图像倾斜矫正,实验结果如下。
实验一,对车牌边框残缺图像进行矫正,结果见表1。
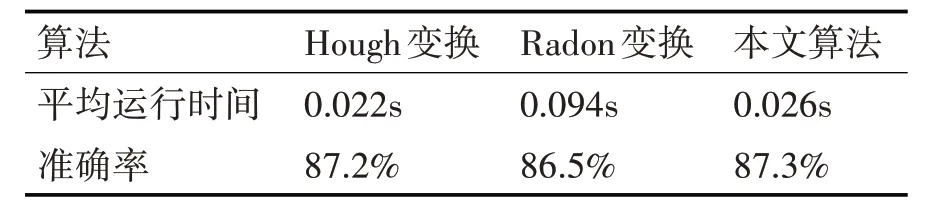
表1 实验一
实验二,去除车牌边框的图像进行矫正,实验结果见表2。
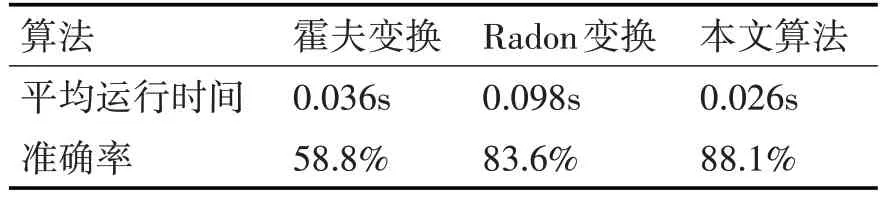
表2 实验二
从以上实验结果可以看出:Hough变换由于缺失边框信息,其矫正的准确率明显下降。在没有车牌边框时,其准确率最低。Radon变换虽然准确率较好,但其矫正速度过慢。本文算法对于边框的有无,几乎没有影响,且矫正速度较快,准确率也好。
5 字符分割
汽车车牌上的第2和3个字符中间,存在一个圆圈的间隔点,在字符分割时,容易被误判为一个字符,使得字符分割错误。首先,去除间隔符,以免分割时误认为车牌字符[9]。本文基于数学形态学的相关知识,在OpenCV中,进行核为(5×5)的开运算(先腐蚀后膨胀),消除掉间隔符,如图7所示。

图7 去除间隔符后图像
字符分割的基本方法是将字符进行垂直投影。简单来说,以(x,y)处像素值来进行判断,当像素值为255时,p(x,y)的值为1;像素值为0时,p(x,y)的值就为0。由此所得的f(x)会有峰谷的特征,在每个相应的波谷处,进行垂直方向的分割,便获得了单个的字符[14],如图8所示。

图8 字符分割结果
6 字符识别
车牌字符主要分为三种:阿拉伯数字、汉字和英文字母。阿拉伯数字0~9;英文字母取A~Z(其中数字1和字母I、数字0和字母O不容易辨别,故去除英文字母O、I);汉字共有31个,除专用号牌外,一般为省、自治区、直辖市的简称,如“豫”,“沪”,“苏”等。
本文采用KNN算法实现。k近邻法是一种基本分类与回归方法[4]。对于分类问题,给定l个训练样本(xi,yi),其中,xi和yi分别代表特征向量和标签值,k和a分别代表设定的参数和类型数,x代表待分类样本的特征向量。
其算法的流程:在训练样本集中取k个距离x最近的样本并将选取的这些样本的集合记为M。统计集合M中每一类样本的个数Ai,i=1,…,a,其得到的最终分类结果为arg maxiAi。距离函数采用的是欧几里得距离[11~12]。对于Rn空建中有两个点x和y,这两点间的距离函数为
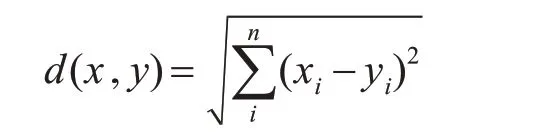
车牌字符识别步骤:
1)采集车牌字符的图像:训练图片有数字0~9,字母A~Z(除O、I外),汉字,各30张图片。
2)提取图像特征:将图像转换为由0和1组成的txt文件且大小都为32×32。
3)kNN算法识别:将二进制的图像32×32转换为向量1×1024。对测试样本进行kNN分类并得到测试样本的结果。识别结果如图9所示。

图9 车牌识别号码
7 结语
本文利用了颜色特征与形态学相结合方法对车牌区域进行粗定位,并基于车牌字符外接矩形与仿射变换相结合的方法来进行车牌的矫正方法。字符分割采用垂直投影的方法,可以有效地分割字符,并用KNN算法对字符进行识别,取得了较好的效果。但在实际的道路应用中,情况会更复杂多变,车牌图像会受到很多因素的干扰,故还需要进一步提高识别率和速度。
猜你喜欢
智能制造(2022年4期)2022-08-18 16:21:14
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
电子制作(2019年12期)2019-07-16 08:45:16
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
摄影之友(影像视觉)(2018年1期)2018-03-22 01:12:04
摄影之友(影像视觉)(2017年11期)2017-11-27 02:39:53
小猕猴智力画刊(2017年5期)2017-05-25 21:44:09
电子制作(2017年22期)2017-02-02 07:10:11
