
一种改进混合文本密度的网页信息提取方法 ①
2022-01-14 03:05陈壮,葛斌
佳木斯大学学报(自然科学版) 2022年1期
陈 壮, 葛 斌
(安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
0 引 言
网页信息由内容信息和噪声信息组成。噪声信息如由广告,导航链接等,不仅影响网页信息检索的效率,而且会导致检索精度的降低。因此,如何准确、快速地识别和提取网页正文信息已成为网页信息提取的关键问题。
常见的网页信息提取的方法可以分为三类:第一类是基于模板的网页信息提取方法。通过特征对网页进行分块,对获得的组成块进行信息提取。缺点时当网页当中噪声信息较多时,会导致提取出错误的信息。文献[1]使用启发式规则构建可视树,通过对可视块筛选实现对网页信息的提取。文献[2]介绍了一种文本挖掘方法从互联网上爬取和提取专家信息,将专家属性矩阵转化为加权有向图,从而将专家推荐问题转化为加权有向图上的最长路径问题;第二类是基于机器学习的网页信息提取方法。利用标记好的网页数据集,来构建规则分类器,再利用该分类器区识别网页信息。文献[3]根据网页的结构属性对其进行聚类,来提高网页信息提取的性能。文献[4]以文本块信息以及相应文档对象模型结构信息作为选择特征,实现一个基于LSTM的深度学习信息提取方法;第三类是基于统计的网页信息提取方法。通过网页中的HTML标签将页面表示成DOM树,利用树中每个节点中的中文字符数选择包含网页信息的节点。文献[5]综合了网页词语的词频、词性、词长和位置特征,按照权值提取出关键词。文献[6-10]通过计算密度特征,对网页中的文本块和噪声块进行区分,最终提取出网页信息。
使用一种改进混合文本密度的网页信息提取方法,分别计算网页中各节点的文本密度、链接密度、链接文本密度、标点符号密度来对网页进行内容提取。
1 所提出的方法
1.1 信息提取的目标
研究目的旨在从网页当中提取出有用的内容信息。如图1所示,是一张新闻网页,左边是网页的源代码,右边是网页的界面,图中红色虚线部分是网页当中的内容信息。
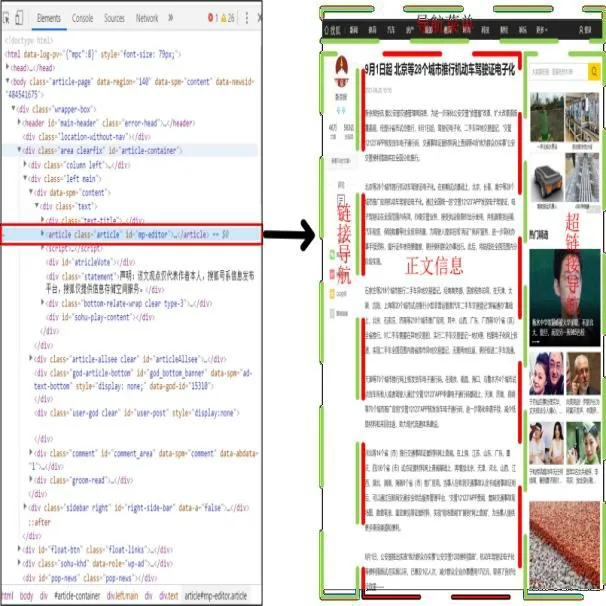
图1 网页分块图
为了使网页内容信息提取的方法具有有效性,先对网页进行预处理操作,得到的结果进行网页分割获得组成块,通过幂次关系对获得的混合密度进行计算,抽取信息内容。
1.2 网页预处理
利用视觉特征去噪的方式对网页进行预处理,得到一个新的网页视觉树。视觉特征去噪算法如算法1:
算法1.Visual Feature Denoising
输入:页面大小阈值H1, H2, H3, H4,
元素E,元素绝对坐标(a,b);
输出:网页中心区域t.
Begin
1 if b+height<=H1 then
//(width,height)为元素所占区域大小
2 E∈Head;
//head,foot,left,right为网页区域
3else if b>=H2 then
4 E∈Foot;
5 else if a+E.width<=H3 then
6 E∈Left;
7 else if a>=H4 then
8 else
9 E∈t;
//元素E属于center部分
10 return t;
End
1.3 网页分割
从网页设计者的角度出发,对网页进行简单的分割。对构建好的网页视觉树,从根节点开始判断是否进行了行列拆分:
(1)若当前节点有子节点或者当前节点的子节点有子节点,则判断结果为进行了列拆分,则增加一个粒度,继续扩展当前节点的子节点;
(2)若当前节点的子节点只进行了行拆分,则不进行扩展;
重复进行上述操作,当网页视觉树不再进行扩展时,所获得的组成块即为网页分割后的组成块。
1.4 混合密度提取
如图2所示,网页信息结果中除了正文信息以外还有其他的噪声信息。影响内容信息提取的主要因素是标题因素,超链接因素等。
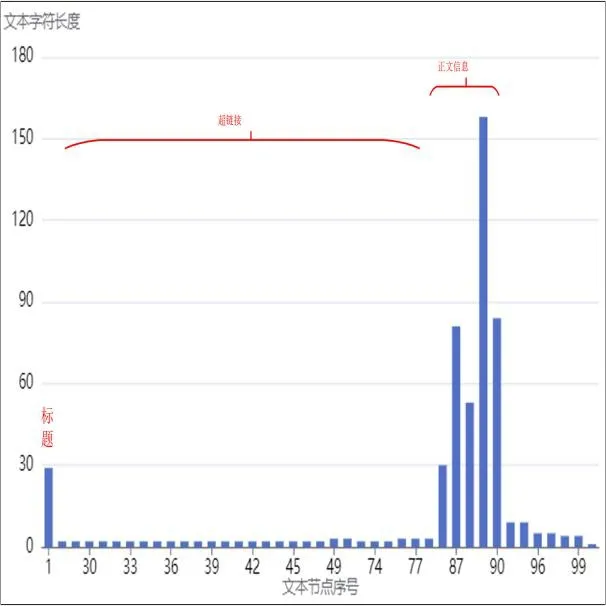
图2 文本节点字符长度图
通过混合密度和所设置的阈值进行比较,小于或者等于阈值的即为所需要的内容信息。下面给出文本密度、链接密度、链接文本密度、标点符号密度的定义以及混合密度的计算方式。
定义1.设i为DOM树中的一个节点,则文本密度(TD)、链接密度(HD)、链接文本密度(LTD)、标点符号密度(SD)分别为式(1)-式(4):
(1)
(2)
(3)
(4)
式中:texti为节点i代表的子树中,去除所有HTML标签后的字符数;hsyperlinki为节点i代表的子树中,所包含的链接数;ltexti为节点i代表的子树中,所有链接所包含的字符数;symboli为节点i代表的子树中,所包含标点符号长度;n代表节点个数。文本密度越大、链接密度越小、链接文本密度越小、标点符号密度越大,则代表越可能是主要文本信息。
混合密度利用幂次关系融合算法融合上述文本密度、链接密度、链接文本密度、标点符号密度,将网页当中的节点特征转化为可以计算的数值。利用幂次关系的特征,增大了正文信息内容和噪声信息内容的区分度。混合密度的计算公式如式(5):
CTDi=-log[TD+(1-HD)+(1-LTD)+SD+1]
[TD×(1-HD)×(1-LTD)×SD]
(5)
1.5 阈值设置
通过设置阈值,可以更加准确、快速的识别正文内容信息和非正文内容信息。判断方式为:混合密度如果小于或者等于阈值的即为正文内容信息,大于阈值的即为噪声信息。
阈值通常使用的方法有中位数或标准方差。标准方差可以反映数据集的离散程度,故本文将标准方差设置为阈值。标准方差的计算公式如式(6):
(6)
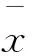
2 信息抽取框架
网页信息提取系统分为网页获取、网页分割、密度计算和信息提取模块。所提出的网页信息提取系统框架如图3所示。
(1)网页获取模块通过输入URL解析网页。
(2)网页分割模块通过网页预处理去除部分噪声信息,将得到的结果解析成DOM树结构,通过行列分割的方式对网页进行分块。
(3)密度计算模块通过遍历DOM树分别计算出文本密度、链接密度、链接文本密度、标点符号密度、混合密度以及阈值。
(4)信息提取模块通过比较混合密度和阈值的大小,区分出内容信息和噪声信息。

图3 系统框架图
3 实验评估
对使用算法进行了评估,通过与文献[9]中PPL,PPR,CETR,CEPR算法以及文献[11]算法进行比较,以便测试网页信息提取的性能。
3.1 数据集和评估指标
3.1.1 数据集
分别使用三个数据集对提出的算法进行验证。三个数据集的详细信息如表1所示。

表1 数据集统计
3.1.2 评估指标
分别使用准确率,召回率和F1度量对所提出的方法的进行评估,如式(7)-式(9):
(7)
(8)
(9)
式中:H1表示抽取结果的集合,而H2表示手工标记结果的集合。通过调节β的值来表示召回率和准确率的重要性,通常情况下认为准确率以及召回率同样重要,因此将β值设为1。
3.2 实验评估
3.2.1 实验结果
由表2到表4发现,平均准确率为96.33%,相比于基于统计的CETR提取方法,平均准确率提高了3.68%。提出的方法能够准确的提取出多种类型的网页信息,具有很好的通用性。但是也有一些问题会影响信息提取的准确性,一些网页的图片会包含注释,这说明网页正文信息前有提示等文本,会带有很多标点符号,所以会导致提取错误。
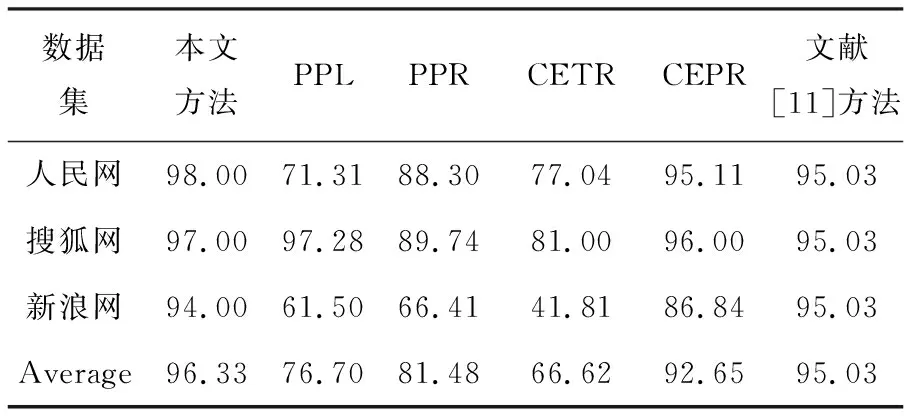
表2 准确率(P)对比结果(%)

表3 召回率(R)对比结果(%)

表4 F1值对比结果(%)
3.2.2 阈值设置
通过阈值σ可以更加准确、快速的识别正文内容信息和非正文内容信息。混合密度如果小于或者等于阈值的即为正文内容信息,大于阈值的即为噪声信息。阈值通常使用中位数或标准方差。以图2对应的网页为例,图4和图5分别代表使用标准方差和中位数作为阈值得出的结果图。图中,红色线条代表阈值。
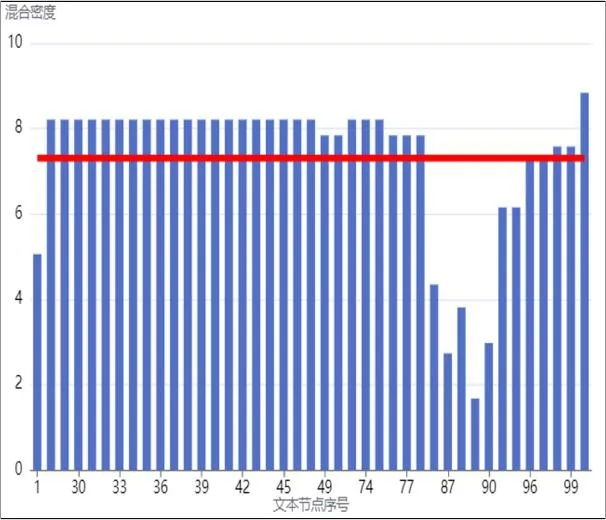
图4 标准方差图

图5 中位数图
标准方差既可以反映数据集的离散程度,同时通过图4和图5可知,当使用中位数作为阈值时,输出的结果可能会包含一些不属于内容信息的部分,故将本文阈值设置为标准方差。
4 结 语
提出了一种改进混合文本密度的网页信息提取方法,与PPL,PPR,CETR,CEPR等算法相比,能够快速高效地从网页中提取内容信息,同时准确率也有所提高。但从实验当中可以看出,该方法还不能自动清除网页当中掺杂的重要提示等信息,及时的去解决这些问题,将是今后需要改进的方向。
猜你喜欢
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
成都信息工程大学学报(2021年6期)2021-02-12
新世纪智能(语文备考)(2020年10期)2020-12-31
小天使·一年级语数英综合(2020年11期)2020-12-16
小读者(2020年4期)2020-06-16
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
小天使·二年级语数英综合(2018年1期)2018-06-29
初中生世界·九年级(2017年10期)2017-11-08
中学科技(2016年7期)2017-05-16
