
D‐BERT:Incorporating dependency‐based attention into BERT for relation extraction
2022-01-12 07:05:44YuanHuangZhixingLiWeiDengGuoyinWangZhiminLin
Yuan Huang | Zhixing Li | Wei Deng,2 | Guoyin Wang | Zhimin Lin
1Chongqing Key Laboratory of Computational Intelligence, Chongqing University of Posts and Telecommunications,Chongqing, China
2Center of Statistical Research,Southwestern University of Finance and Economics,Chengdu, China
Abstract Relation extraction between entity pairs is an increasingly critical area in natural language processing. Recently, the pre-trained bidirectional encoder representation from transformer(BERT)performs excellently on the text classification or sequence labelling tasks.Here, the high-level syntactic features that consider the dependency between each word and the target entities into the pre-trained language models are incorporated.Our model also utilizes the intermediate layers of BERT to acquire different levels of semantic information and designs multi-granularity features for final relation classification. Our model offers a momentous improvement over the published methods for the relation extraction on the widely used data sets.
1 | INTRODUCTION
Relation extraction between target entities is one of the most crucial steps in information extraction.It is also widely applied in various domains, for example, knowledge graph construction,question answering system,knowledge engineering and so on. Relation extraction focuses on predicting the semantic relationship of sentences based on the given entity pairs. For example,given a text‘The <e1 >company </e1 >fabricates plastic <e2 >chairs </e2 >’, the head entity‘company’ and the tail entity ‘chairs’. In Table 1, the first entity is marked by<e1 >and </e1 >,and the second entity is marked by <e2 >and </e2 >.
Recently, many researchers utilize the variants of convolutional neural network(CNN)and recurrent neural network(RNN)to implement relation extraction[1–5].Some of these methods use high-level syntactic features derived from external natural language processing(NLP)tools,such as named entity recognizers, syntax parsers, dependency parsers. Inevitably,many irrelevant words are introduced when entity pairs are far away from each other. The semantic modification relationship of each component in the sentence should be considered to obtain long-distance collocation information, which can be achieved by the dependency parsers. Relation extraction is different from ordinary classification tasks in that it needs to pay attention to not only the sentence information but also the target entities. It is indispensable to effectively highlight the target entities and consider the dependency between each element and entity pairs in a sentence, which is competent in eliminating the influence of noisy words. Previous models based on syntax parsers or dependency parsers have achieved excellent results in relation extraction task,which indicates that the introduction of syntactic information is beneficial to relation extraction.Besides this,with the development of attention mechanism in visual tasks, many scholars have gradually applied attention mechanism to a great deal of NLP tasks and developed state-of-the-art research findings. One purpose of this study is to grasp the most crucial semantic information considering the dependency of each word on the target entities,and we present a dependency-based attention mechanism.
As far as we know, the pre-trained language model bidirectional encoder representation from transformer(BERT)[6]has proven to be advantageous for promoting the performance of NLP tasks [7–10], for example, question answering, text classification, sequence labelling problems and so on. BERT employs the transformer [11] encoder as its principalarchitecture and acquires contextualized word embeddings by pre-training on a broad set of unannotated data. Recently, Wu et al.[10]first applies the BERT model to relation classification and uses the sequence vector represented by ‘[CLS]’ to complete the classification task. Our study also aims to contribute to this growing area of research by exploring how to utilize the BERT intermediate layers for improving BERT fine-tuning.Different layers have different levels of feature representation for specific tasks.For instance,the low-level network of BERT learns phrase-level information representation, the middlelevel network of BERT learns rich linguistic features and the high-level network of BERT learns rich semantic information features. Thus, we incorporate two pooling strategies for integrating the multi-layer representations of the classification token. The previous methods have primarily implemented relation extraction by taking the single-granularity features as the input of classifier. Here, we utilize multi-granularity features for classification instead of single-granularity features to capture rich semantic information.

TA B L E 1 A sample of relation extraction
This study involves three fundamental contributions: (1)The dependency-based attention mechanism considering the dependency of each word on the target entities is applied in relation to extraction task, (2) we explore the intermediate layers of BERT and design multi-granularity features for final relation classification,and(3)in experiments,our model offers a momentous improvement over the previous methods for the relation extraction on the widely used data sets.
2 | RELATED WORK
2.1 | Syntactic analysis in relation extraction
Relation extraction is a paramount link in natural language processing. Based on neural networks, many scholars have further studied the improvement of syntactic features in relation to extraction task, especially in supervised relation extraction.For the first time,Socher et al.[1]applied RNN to relation extraction. Each node in the parse tree is assigned a vector and a matrix, where the vector captures the inherent meaning of the components, and the matrix captures how vectors change the meaning of adjacent words or phrases.Zeng et al.[2]introduced position embeddings that considered the relative distance between each word and the target entities and took advantage of convolutional depth neural network to study the features of vocabulary and sentence levels. Xu et al.[12] integrated the shortest path of dependency analysis tree and the characteristics of word vector, part of speech, and WordNet-based on long short-term memory(LSTM)network.Xu et al.[13]developed a CNN model based on a dependency analysis tree to extract the relationship between the target entities, and a negative sampling strategy was proposed to settle the problem of irrelevant information introduced by the dependency analysis tree when entity pairs are far away from each other. One dominant challenge with the previous approaches was the inadequacy of annotated data supporting model training.To enlarge the training data set,Mintz et al.[14]adopted an external domain-independent entity knowledge base (KB) to perform distant supervision. Nevertheless, the wrong labelling problem caused by the hypothetical theory of distant supervision is unavoidable. To alleviate the problem,the multi-instance learning in distant supervision relation extraction was developed by[15–17].Zeng et al.[18]proposed a variant of CNN network, piecewise-CNN (PCNN), which can automatically capture the features of semantic structure for distantly supervised relation extraction, and incorporated multi-instance learning into the PCNN for reducing the impact of noise in the training data. Cai et al. [19] presented a bidirectional recursive CNN based on the shortest dependent path,which combined the CNN with the dual-channel recursive neural network based on LSTM.
2.2 | Attention mechanism in relation extraction
Some researchers have recently applied attention mechanism to relation extraction to select more significant sentences or words and capture the most crucial semantic information from them. Based on the advanced features acquired by Bi-LSTM, Zhou et al. [20] introduced an attention-based Bi-LSTM(Att-BLSTM),an attention mechanism focusing on the different weights of words was proposed to capture the most decisive word in the sentence. Wang et al. [21] developed an innovative CNN architecture that relied on a two-level attention mechanism, namely the attention mechanism for target entities and the attention mechanism for relationships.Lin et al. [22] adopted an attention mechanism focusing on the different weights of sentences to take advantage of the advantageous sentences in the package to further reduce the noise generated by the wrongly annotated sentences. Ji et al.[23] added entity description to a model that was based on PCNN and sentence-level attention to assist the learning of entity representation, thereby effectively improving the accuracy. Lee et al. [5] developed an end-to-end RNN model,which applied entity-aware attention after Bi-LSTM and incorporated with latent entity type for relation extraction. As the effectiveness of the attention mechanism, it is increasingly being used to address the mislabeling problem introduced by distant supervision.
2.3 | Pre‐trained language models in relation extraction
Recently, the pre-trained language model BERT was the mastermind of the considerable advances in various NLP tasks.The first systematic study of applying the pre-trained BERT model to relation extraction was reported by [10]. The proposed model incorporated information from the target entities and appended special symbols to mark the position of entity pairs to highlight the target entities. Soares et al. [24]investigated the effects of different input and output modes of the pre-trained BERT model on the results of relation extraction.
3 | METHODOLOGY
3.1 | Task description
Given a set of sentences {x1, x2,…, xn} and two corresponding entities e1and e2, the goal of our model is to identify the semantic relationships between the head entity and tail entity.
3.2 | Pre‐trained model of BERT
The innovation of BERT[6] is that it utilizes the bidirectional transformer[11]for language models and pre-trains on a large amount of unannotated corpus for text classification or sentence prediction tasks.The input of the BERT model can be a text or a pair, and the representation of each word is the addition of three embeddings, namely token embedding,segment embedding and position embedding. For the text classification task, the BERT model inserts a [CLS] symbol in front of the text and takes the corresponding output hidden vector of the symbol as the semantic representation of the whole text, which is used for text classification.
The optimization process of BERT is to gradually adjust the model parameters so that the semantic text representation of the model output can depict the nature of the language and facilitate the subsequent fine-tuning for specific NLP tasks.
3.3 | Model architecture
The pre-training part of our model ultimately adopts the BERT model, and the input sentence is a single sentence, so the‘[CLS]’is added at the beginning of the sentence,and there is no need to add‘[SEP]’.To locate the positional information of two target entities, a special token is also added for the beginning and end of each entity. The head entity is represented by‘$’and the tail entity by‘#’.For example,a sentence with two marked entities, ‘company’ and ‘chairs’: ‘The company fabricates plastic chairs’. After adding the two special tokens, the original sentence will become: ‘[CLS] The $ company $ fabricates plastic # chairs #’.
The network architecture is detailed in Figure 1. Our model principally comprises the following three modules: (1)dependency-based attention that considers the dependency of each word on the target entities;(2)utilizing intermediate layers of BERT that captures different levels of features; and (3)integration of features that fuses features of different granularity for final relation classification.
3.3.1 | Dependency-based attention
Given a head entity e1, tail entity e2and sentence s, let Tmto Tndenotes the BERT's input of the entity e1, and Tito Tjdenotes the BERT's input of the entity e2.Suppose h={h1,h2, …, hn} be the final hidden states that the BERT model produced. The dependencies between each word and the two target entities are obtained using Stanford CoreNLP [25].Then, a randomly initialized word embedding matrix is adopted to map the two dependencies to the first real-valued vector di1and the second real-valued vector di2. The word vector embedding matrix is continuously updated as the training process. Different dependencies (the object of a preposition,nominal subject, indirect object etc.) contribute different degrees to the relation classification.And attention operation can automatically learn the contribution of each hiin a sentence.Thus,we utilize an attention module to combine hidden states of all tokens dynamically:
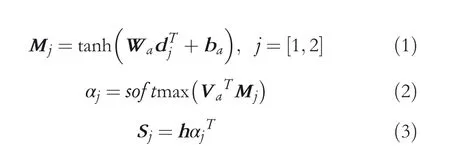
where dj∈Rl×d,h ∈Rdw×l,Wa∈Rd×d,Va∈Rd×1,dwis the hidden state size from BERT, d is the size of the dependency embeddings,l is the length of the sentence,Wa,Vaand baare learnable weights and VaTis a transpose. djrepresents the dependency vector between each word and the two target entities. Sjrepresents the vector representation of the whole sentence based on the dependency between each word and the two target entities.
Finally, we pass Sjto a fully connected layer after the activation operation, which can be where Wd∈Rdw×dw.
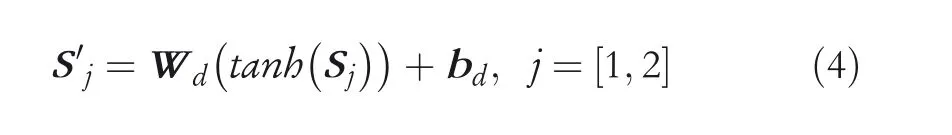

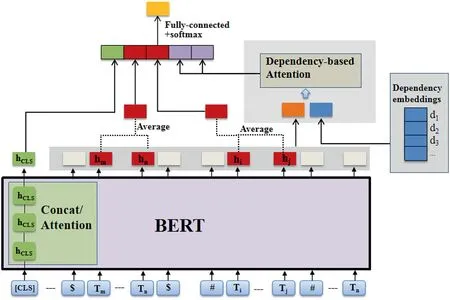
FIGURE 1 Overview of the proposed D-BERT model
3.3.2 | Utilizing intermediate layers of BERT the intermediate layers hCLS: Concat-Pooling and Attention-Pooling.The corresponding models are named BERT‐attention and BERT‐concat.
BERT-attention:Representation of the‘[CLS]’shows the semantic information of the whole sequence, and different layers of BERT focus on different information of the sequence.Since the attention mechanism can dynamically learn the contribution of each hiCLSon the final classification, we utilize a dot-product attention module to combine all informative features in given intermediate layers effectively. HCLSrepresents the final vector representation of the ‘[CLS]’. After the step of the activation operation,the fully connected layer is also added to HCLS. The process can be expressed as follow:
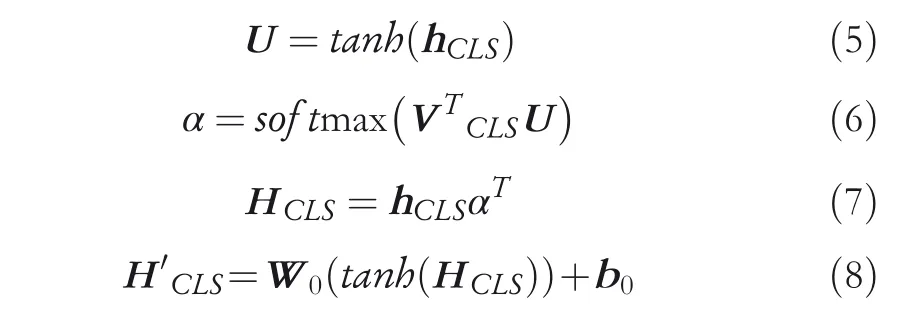
where hCLS∈Rdw×L, VCLS∈Rdw×1, W0∈Rdw×dw, L is the number of intermediate layers used and dwis the hidden state size from BERT. W0, VCLSand b0are learnable weights.
BERT-concat:We apply the concat operation to connect all intermediate representations of the ‘[CLS]’. Then, we also pass HCLSto a fully connected layer after the activation operation, which can be where W0∈Rdw×Ldw(dwis the hidden state size from BERT).
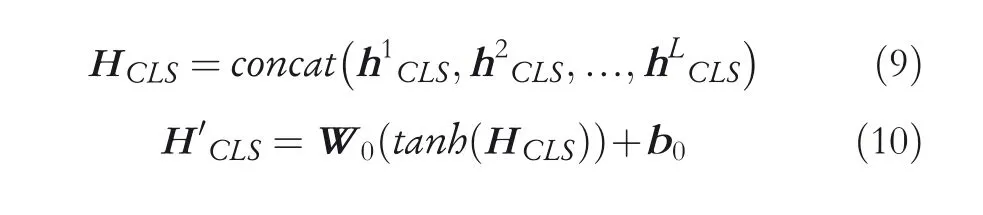
3.3.3 | Integration of features
Given the final hidden states from BERT h = {hCLS, h1,h2, …, hn}, we suppose the hidden states hmto hnis the hidden states of entity e1, and hito hjis the hidden states of entity e2. The average operation is used to obtain the vector representation of two target entities. After the step of the activation operation, the fully connected layer is also added to the two averaged feature vectors, the corresponding outputs are H′1and H′2. The formula is as follows:
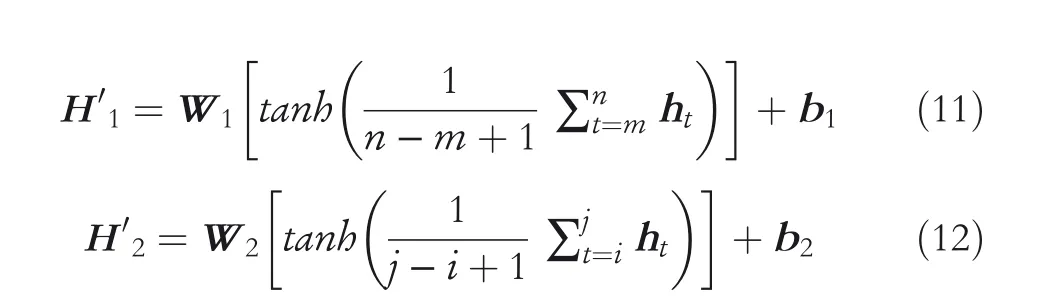
where W1∈Rdw×dw, W2∈Rdw×dw.
H′CLSrepresents the sentence-level feature vector of the whole sequence, which gathers the semantic information of all words and belongs to the coarse-grained features. S′1and S′2are combinatorial features of different syntactic components, which take into account the dependencies with entity pairs and belong to the fine-grained feature. The H′CLS, H′1, H′2, S′1and S′2are concatenated as the final output vector. Finally, the softmax operation is applied to all relation types:
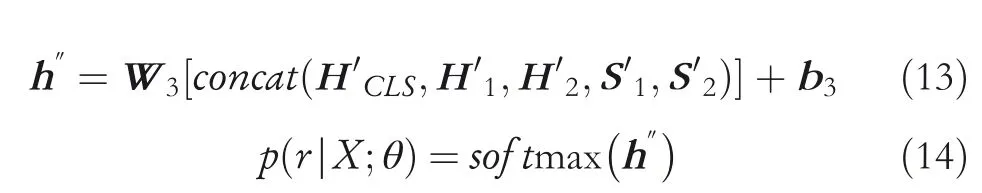
where W3∈Rr×5dw(r is the defined number of relation types)and p(r|X; θ) is the probability value that the input sentence belongs to the relation r. During the optimization process, we adopt the cross-entropy loss function.When we use the concat method with higher F1 score than attention to synthesize the intermediate layers of BERT, we call our model D-BERT.
4 | EXPERIMENTS
4.1 | Data sets
We evaluate our model on the widely used data sets,SemEval-2010 Task 8[26]and KBP37[27].For the SemEval-2010 Task 8 data set[26],there are 18 directional relations and an‘Other’class. The data set contains 8000 instances in the training set and 2717 instances in the test set. When the directionality of the relationship is considered, a relationship type is divided into two subtypes, namely the forward relationship and the reverse relationship.For instance,Member-Collection contains Member-Collection (e1, e2) and Collection-Member (e2, e1).The KBP37 data set includes 18 semantic relations and ‘no relation’class.Similar to SemEval-2010 Task 8,the relationship is directional, so the actual number of relation types is 37. It contains 17,641 training instances and 3405 test instances.During the optimization process of training, the F1 score was utilized as the evaluation framework for D-BERT.
4.2 | Parameter settings
The prominent hyper-parameters involved in the experiment are listed in Table 2. We conduct all experiments with an uncased large BERT model [6] with different weights. Moreover, The dropout operation is applied before each add-norm layer.
5 | RESULTS
To measure the validity of our method,the following published methods are referenced as our comparison objects, including RNN, MVRNN, CNN + Softmax, CR-CNN, BiLSTM-CNN,Attention-CNN, Position-aware Self-attention, Entity Attention Bi-LSTM, R-BERT and Matching the Blanks.

TA B L E 2 Parameter settings
RNN: Zhang et al. [28] utilized a bidirectional recurrent neural network architecture for relation extraction task.MVRNN: Socher et al. [1] proposed an RNN model that each node in the parse tree is assigned a vector and a matrix to grasp the combined feature vectors of phrases and sentences. CNN + Softmax: Zeng et al. [2] introduced the position embeddings of each word relative to entity pairs.The model concatenated the sentence-level feature and lexical level feature and fed them into a softmax layer for prediction. CR-CNN: Nogueira dos Santos et al. [3] mainly improved [2] the CNN model and designed a margin-based ranking loss, which can effectively diminish the influence of artificial categories. BiLSTM-CNN: Zhang et al. [29] proposed a model that combined the advantages of CNN and LSTM, and took the higher-level feature representations obtained by LSTM as the input of CNN. Attention-CNN:Shen et al. [4] made full use of word embeddings, part of speech marking embeddings and position embeddings information. Attention-CNN introduced an attention mechanism into CNN to pick up the words that were conducive to the sentence meaning. Position-aware Self-attention: Bilan et al. [30] applied the self-attention encoder layer and an additional position-aware attention layer to the relation extraction task. Entity Attention Bi-LSTM: Lee et al. [5]introduced a self-attention that considered contextual information to boost the learning competence of word representation. At the same time, they added entity-aware attention after Bi-LSTM to incorporate the two features of position features and entity features with the latent entity type. R-BERT: Wu et al. [10] both located the target entities and incorporated the information from the target entities based on the hidden vectors of the BERT’s last layer for relation extraction task. Matching the Blanks: Soares et al.[24] investigated the effects of different input and output modes of BERT on the results of relation extraction.
The F1 scores of the above methods are demonstrated in Table 3.Results on rows where the model name is marked with a * symbol are reported as published, the row of data in bold represents the best model and the corresponding F1 score.We can observe that D-BERT significantly outperforms previous baseline methods on the SemEval-2010 Task 8.On the KBP37 data set, the performance of D-BERT model is highly consistent with Matching the Blanks model and the F1 score of our model far higher than other models.
5.1 | Ablation studies
We have certified that our approach can achieve reliable empirical results. On this basis, we design three more variants of the model to examine the specific effects of each ingredient on the accuracy of the model.
1. BERT‐INTER: We feed the preprocessed sentences into the BERT model and utilize the intermediate layers ofBERT to get the final hidden vectors of‘[CLS]’.The hidden vectors of target entities and the final hidden vectors of‘[CLS]’ are concatenated into the softmax layer for classification.During utilize the intermediate layers of BERT,the model corresponding to the BERT-attention mode is called BERT‐INTER‐Attention, the model corresponding to the BERT-Concat mode is called BERT‐INTER‐Concat.

TA B L E 3 Results for supervised relation extraction tasks
2. BERT‐DEPEND:We feed the preprocessed sentences into the BERT model to get all hidden vectors of the last layer and use a dependency-based attention module to combine hidden vectors of all tokens dynamically. The hidden vectors of ‘[CLS]’ and the target entities, and the hidden vectors based on dependencies are concatenated into the softmax layer for classification.
3. BERT‐BASELINE: We feed the preprocessed sentences into the BERT model to get the hidden vectors of ‘[CLS]’.The hidden vectors of ‘[CLS]’ and the hidden vectors of target entities are concatenated into the softmax layer for classification.
We report the performance of the above three variants in Table 3. We discover that D-BERT achieves the highest F1 score of all other methods we consider. Of the methods, the BERT-BASELINE model performs worst. The results corroborate that both the dependency-based attention and the intermediate layers of BERT make essential contributions to our approach. To further study the effect of the dependency-based attention for relation extraction, we empirically show the F1 score with different epochs on the SemEval-2010 Task 8 and KBP37, as indicated in Figure 2.According to Figure 2(a), as the training progress, the F1 score of the BERT-DEPEND is strikingly higher than that of the BERT-BASELINE on the SemEval-2010 Task 8 data set. According to Figure 2(b), on the KBP37 data set, the F1 score of the BERT-DEPEND improves to 0.684, rather than the baseline of 0.672. The study indicates that the proposed dependency-based attention is beneficial. It can effectively filter out meaningless words and learn fine-grained feature by pre-trained language models.
Furthermore, we performed the effectiveness of utilizing the intermediate layers of BERT, as detailed in Figure 3.According to Figure 3(a), on the SemEval-2010 Task 8, the F1 scores of the BERT-INTER-Concat and the BERTINTER-Attention model are improved remarkably compared with the BERT-BASELINE. Especially after adding the intermediate layers of BERT to the BERTDEPEND, the F1 score reaches 0.901. Compared with the BERT-BASELINE of 0.892, it achieves excellent improvement. On the KBP37 data set, utilizing the intermediate layers also improves the performance of BERT-BASELINE,As shown in Figure 3(b). Compared with the BERTBASELINE score of 0.672, we increased the F1 score to 0.692.Moreover,boththeBERT-INTER-Concat and BERT-INTER-Attention pooling strategies help improve the performance for relation extraction, and the results are exceedingly comparable.
The relation extraction task is different from the ordinary text classification task in that it also needs to focus on two entities. The semantic knowledge of the sentence is essential for the relation prediction. Nevertheless, we find that a sentence contains not only the target entities but also other irrelevant entities in the supervised relation extraction data set. On the one hand, how to identify the words associated with the entity pairs in one sentence is a significant breakthrough. The reason why the dependency-based attention module enhances the classification accuracy of the model is that it reduces the noise caused by hardly necessary words in the case of considering the dependency of each word on entity pairs. On the other hand, it is not enough to take advantage of the feature vectors of the BERT’s last layer for classification. Moreover, relation extraction needs to focus on both linguistic-level features and semantic-level features, which can help to make a more accurate prediction.Our experiments also reveal that the features of different granularity are beneficial to excavate the relationships between entity pairs.
5.2 | Effect of number of intermediate layers
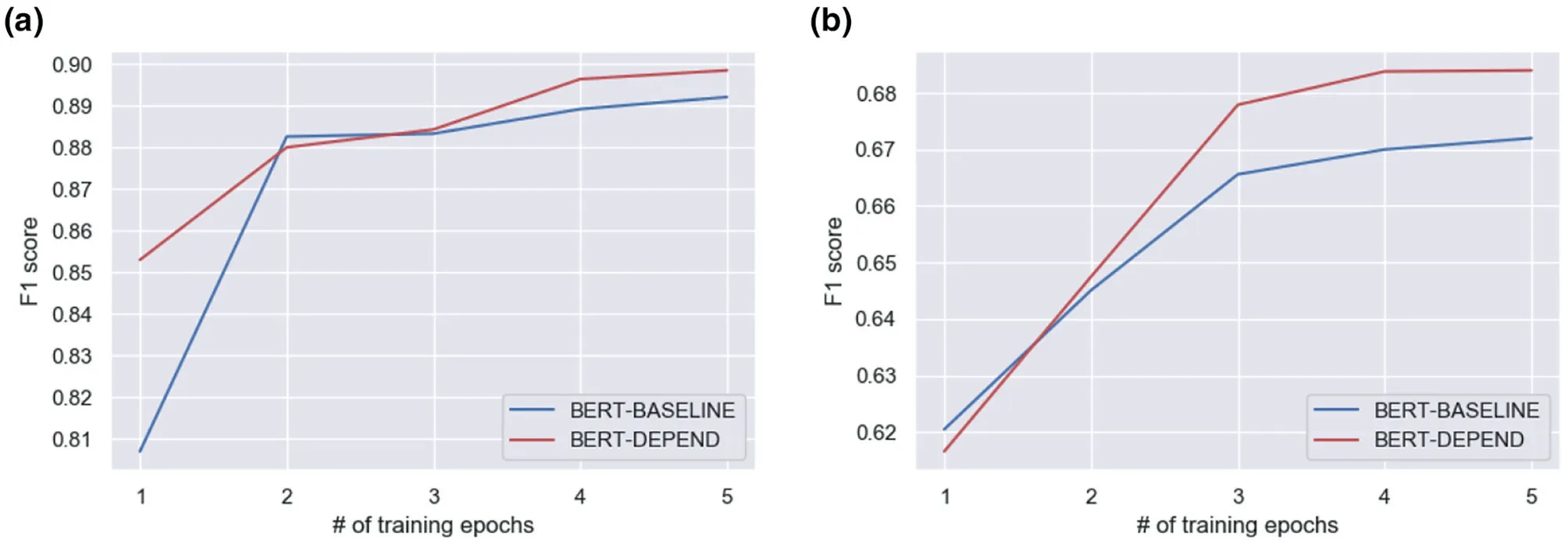
FIGURE 2 The effect of the dependency-based attention on the SemEval-2010 Task 8 (a) and KBP37 (b)

FIGURE 3 The effect of utilizing intermediate layers of BERT on the SemEval-2010 Task 8 (a) and KBP37 (b)
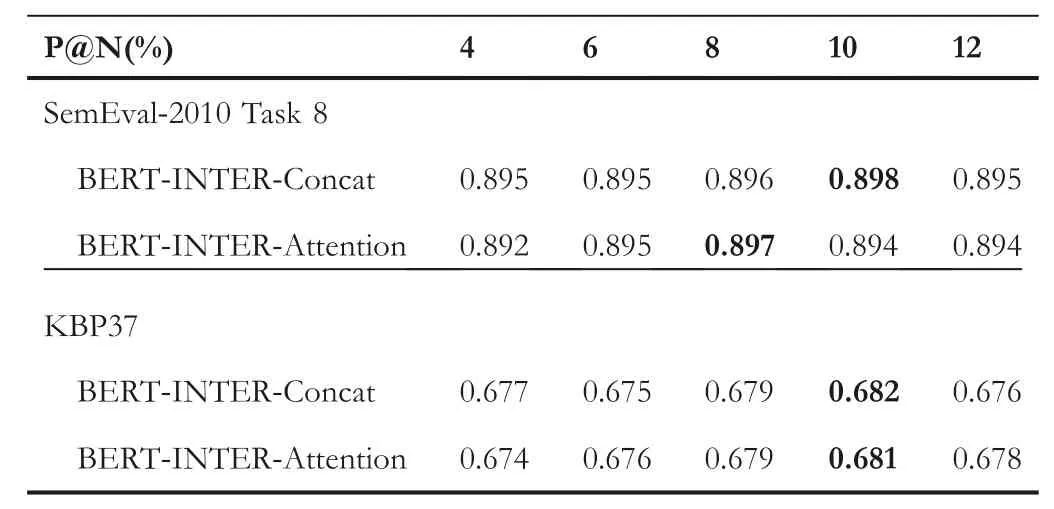
TA B L E 4 F1 scores on the BERT-INTER-Concat and BERTINTER-Attention with different number of intermediate layers of BERT
We analysed the effect of our model while varying the number of intermediate layers of BERT to capture the sentence-level feature vector of the whole sequence.Table 4 reports the P@4,P@6, P@8, P@10 and P@12 for the BERT-INTER-Concat and BERT-INTER-Attention models, the row of data in bold represents the corresponding F1 score on the best model.From the table,we can observe that(1)BERT-INTER-Concat performs slightly better as compared to BERT-INTERAttention and the difference between their performance is imperceptible. Both BERT-INTER-Concat and BERT-INTER-Attention can integrate the multi-layer representations of the classification token and acquire rich linguistic features and semantic features. (2) The experimental performance is the best in P@8 and P@10 for the BERT-INTER-Concat and BERT-INTER-Attention models.However,when the number of intermediate layers of BERT grows, the performance of BERT-INTER-Attention and BERT-INTER-Concat has almost no improvement.It even drops gradually in P@12 as the number of intermediate layers increases.It could be speculated that the features captured by the deeper intermediate layer of BERT are more basic and abstract, and the extracted features apply to most classification tasks.The results further support our argument that different levels of feature representation from intermediate layers of BERT are beneficial to capture the sentence-level feature vector.
6 | CONCLUSION
Here, the dependency-based attention mechanism is introduced into the BERT architecture, which can learn high-level syntactic features that consider the dependency between each word and the target entities. Besides, we explore the potential of utilizing BERT intermediate layers to acquire different levels of semantic information and design multi-granularity features for final relation classification. The experimental data reveal that D-BERT offers a momentous advancement over the published methods on the widely used data sets.
Future studies will include:(i)extending the D-BERTmodel to entity and relationship joint extraction, question answering system and so on and(ii)enriching the representations of target entities by leveraging the relation triples involved in the knowledge graph to obtain more background information of the target entities.
ACKNOWLEDGEMENTS
This study is supported by the National Key Research and Development Programme of China (Grant no. 2016YFB1000 905), the State Key Programme of National Nature Science Foundation of China(Grant no.61936001).The authors thank our tutors for their careful guidance, various scholars and monographs cited here for their heuristic ideas, and the laboratory team for their helpful comments.
 CAAI Transactions on Intelligence Technology2021年4期
CAAI Transactions on Intelligence Technology2021年4期
- CAAI Transactions on Intelligence Technology的其它文章
- Constrained tolerance rough set in incomplete information systems
- Nuclear atypia grading in breast cancer histopathological images based on CNN feature extraction and LSTM classification
- A multi‐agent system for itinerary suggestion in smart environments
- Low-rank constrained weighted discriminative regression for multi-view feature learning
- Modified branch-and-bound algorithm for unravelling optimal PMU placement problem for power grid observability:A comparative analysis
- Steganography based on quotient value differencing and pixel value correlation