
边缘计算网络中基于伪随机函数的可追溯假化名隐私保护研究
2022-01-10 08:08邢伟,耿琦
无线互联科技 2021年21期
邢 伟,耿 琦
(江苏金盾检测技术有限公司,江苏 南京 210042)
0 引言
随着万物互联的飞速发展及在社会中的广泛运用,网络边缘设备数量迅猛增长,预估到2021年年底将有800亿台设备连入互联网,使得这类设备运行所产生的数据量到达泽字节(ZB)级别。但是有限的计算能力和存储空间使边缘设备难以高效处理海量数据,同时边缘设备正在从单一的数据使用者转变为数据生产和数据使用的双重角色,逐渐具有利用收集实时数据、执行预测分析和智能处理等功能,对设备提出了更高的要求。
1 边缘计算数据安全与隐私保护体系
云计算接受了由本地用户产生的大批量数据文件和巨大的计算任务,在早期确实创造了有效的规模经济效益。然而,云计算的集中式处理模式已经无法满足当下的任务,主要还是集中式的云计算能力无法匹配指数级增长的边缘数据,从边缘设备到云计算服务中心的海量数据增加了传输带宽的负载率,并且在传输数据途中个人的隐私数据会被窃取造成安全问题。
1.1 新的边缘计算模型
许多新的计算模型被相继提出,雾计算[1]、Cloudlet[2]、海云计算[3]等。一种新的分布式计算概念—边缘计算[4]也被引入互联网,它是以网络边缘设备为核心的新型计算模式,将云计算中心的计算任务向网络边缘设备迁移,简单说就是让云服务器和本地用户之间的边缘节点合作完成计算任务,降低中心服务器计算压力,减缓网络传输负载,提高处理效率。边缘计算数据安全与隐私保护体系结构如图1所示。
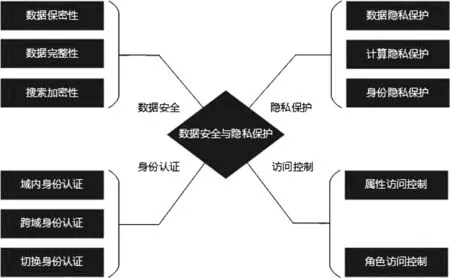
图1 边缘计算数据安全与隐私保护体系结构
边缘计算在解决了许多问题的同时,也面临着各种安全和隐私威胁。边缘节点有着对用户数据的控制权,这时很难保证数据的隐私和完整,同时未经授权的节点可能会利用用户的各项数据用作他途,且边缘计算设备比起云计算中心更靠近数据源,可以更容易收集到用户的敏感信息。在现今的大数据时代,如何保证分享信息的同时保护自身的隐私,是一个至关重要的问题。
1.2 基于边缘计算的隐私保护相关研究
目前,对于边缘计算的隐私保护研究在国内外都取得了一定的进展。
Lu等[5]利用同态加密为边缘计算中的计算设备开发了一种轻量级的数据聚合方案,从而保证数据的隐私性和完整性,但是该方案没有考虑拓展性和移动性。
Khan等[6]针对身份认证过程中的凭证泄露问题,提出了一种基于动态凭证的身份隐私保护方案,通过网络中的分组交换机对终端设备的身份凭证实时更新,以阻止凭证泄露。
Wang等[7]提出了一种在边缘计算场景中使用假名技术的匿名数据聚合方案,在保证边缘计算实体的真实性的同时考虑了本地设备的身份隐私。
Guan等[8]提出了一种将假名证书与Paillier同态加密相结合的方案。
Lin等[9]搭建了一个保护隐私的内核k均值聚类外包方案,对数据进行扰动运算来保护数据。
1.3 数据假名化技术
数据假名化是维护数据结构和信息保密的一种方法和技术,可以对敏感信息进行保密,例如个人位置、个人地址、邮政编码等。在《通用数据保护条例》的标准文件中定义了数据假名化的概念,即是对个人的数据的处理方式,在不使用附加信息的情况下,不再将个人数据归因于特定的数据主体[10]。
目前,实现数据假名化的基本技术都已经较为成熟并且都得到了广泛的使用。具体包括以下几种:(1)计数器技术是最简单的假名化方法,真实数据的标识符会由一个单调计数器计算出的数字来代替。该技术最大的优势就是简单易用,这也使得它成为一些不复杂数据集的合适选择。(2)随机数生成器是一种与计数器类似的方法,不同的地方是它产生一个随机数给对应的标识符,由于其随机性,所以很难取出关于原来标识符的信息,这提供了一种可靠的数据保护。它的缺点也很明显,很容易产生随机数的冲突。(3)加密散列函数[11]是一种直接作用于标识符以获得假名的方法,特点是单向性和无冲突性,保证了数据的完整性,但也容易遭受暴力破解的风险。消息认证码[12]与加密散列函数相似,在散列函数的基础上引入了密钥来生成假名,通过这个密钥来获取假名与原标识符的映射,是一种较为稳健的假名化技术。它有多个不同变体,HMAC是互联网协议中最流行的消息认证码设计。(4)对称加密技术,使用秘密密钥来加密标识符,是加密假名和恢复假名的密钥,例如DES技术,也是一种较为稳健的假名化技术。
2 假名化模型
本文从一个实际的假名化案例来分析。用户在终端机器上产生的数据通过互联网被传输到不同的边缘节点进行处理和存储,不同的边缘节点在功能或业务上会存在较大的不同,有的专门负责存储用户的相关数据,还有只负责计算用户需要的数据信息的节点。不同节点可能是不同的数据处理中心,也可能是不同的服务系统,如果要完成用户的数据处理任务,则这些节点之间的互相配合也是必不可少的(如图2所示)。这里的问题就是不同节点之间所需要的数据并不相同,对于所有节点来说完整访问用户所有记录是没有必要的,即个人隐私及部分非必要数据应该对单一节点进行隐藏。
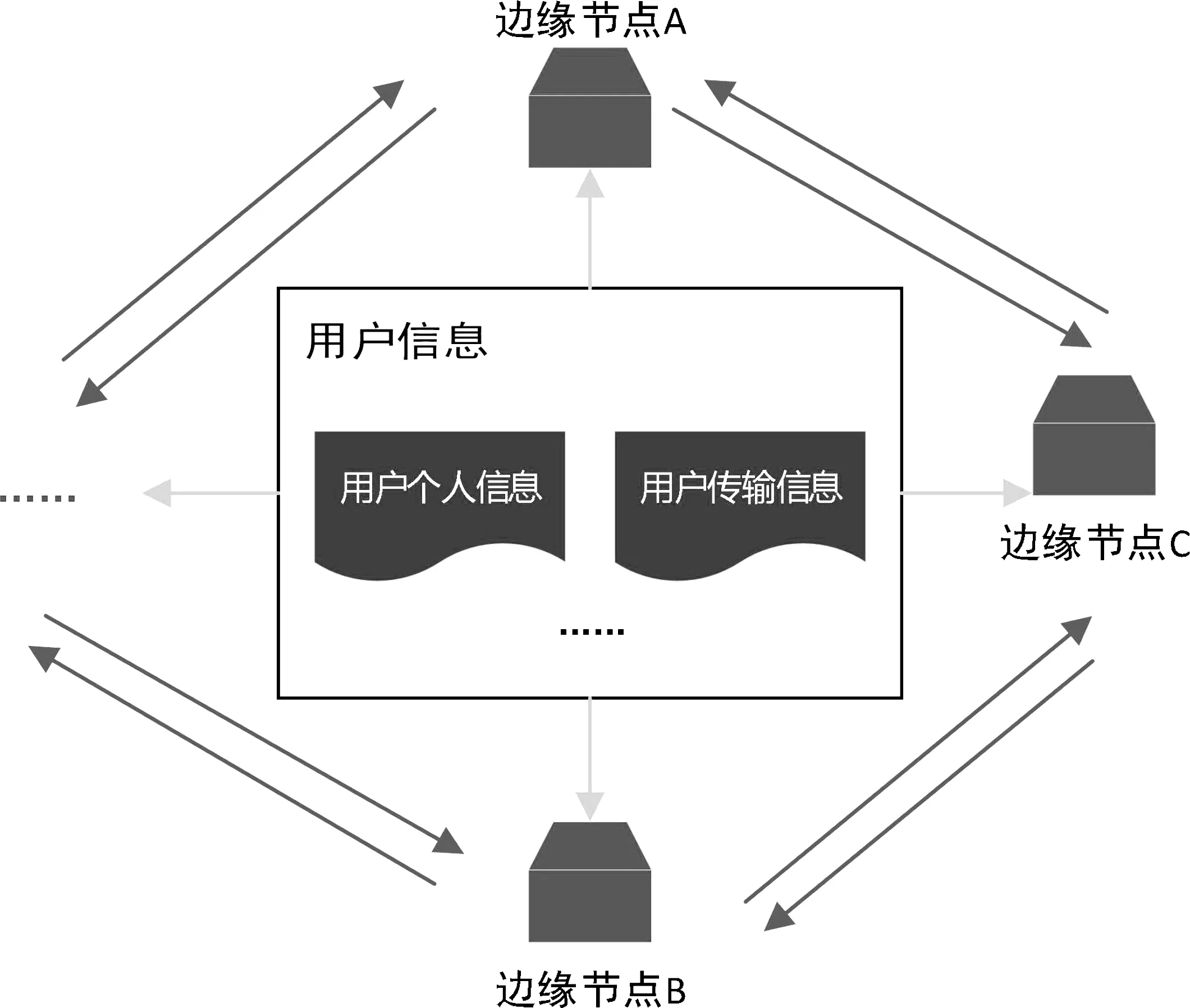
图2 边缘用户数据计算案例
用户的完整数据可以分为用户的个人基本信息(如姓名、地址、性别等)、用户的位置信息、用户的操作记录、用户发送的数据等部分。对这些数据信息分别进行假名化。本文以加密哈希函数技术来进行假名化操作为例,数据经过哈希再被传送到节点后,该节点只能使用和看到必要的数据,个人隐私数据则被隐藏起来,因为不同的数据产生了不同的哈希值,节点只能处理自己的数据。
使用哈希函数对各部分数据第一次假名化可以称为1级假名化,被1级假名化的数据叫作1级假名。对1级假名再次哈希加密后得到的数据为2级假名数据。假设用户数据被分为四大部分,每一个部分又通过几个小部分组成,将这些不同组的数据进行加密哈希计算也就完成了整个用户信息的假名化(见图3)。
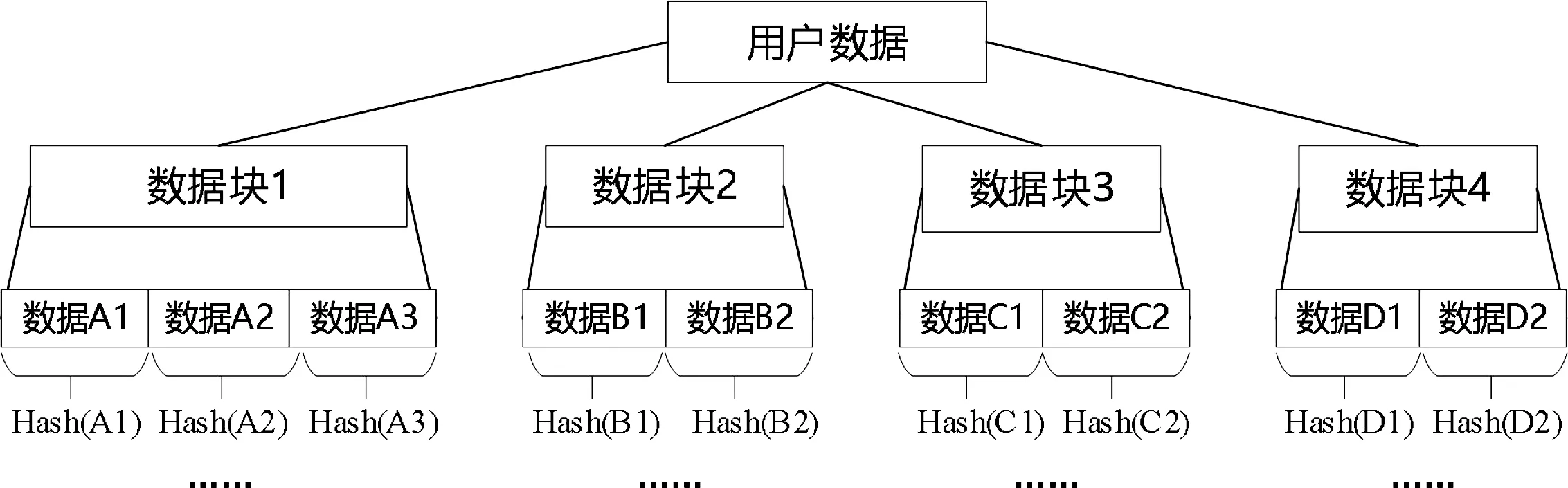
图3 基于树状的用户数据哈希化方法
基于树状的用户数据哈希化方法,每个用户的数据都会被分为不同的组,通过哈希函数产生许多组哈希值,即假名。通过这种模式的假名化后,数据之间的关联性将会被削弱,每一块数据与特定的个人之间的绑定关系将消失,例如用户的浏览行为将与任何特定主体无关。在不同的边缘节点上就可以对同一用户的不同数据部分进行单独的处理。
3 现有假名化技术的不足
虽然对于边缘节点来说,当用户数据被假名化后无法看到用户的个人隐私信息,但是单纯地使用加密哈希函数来对数据假名化仍然存在不少问题,主要有以下3个方面。
(1)假设某个用户频繁地通过某个边缘节点接入,那么Hash的个人信息会被边缘节点收集存储,而边缘节点可以通过收集的Hash形成专门的Hash库,通过对比与判断,可以知道某些数据是属于一个确定的用户,再结合访问的时间,访问的接口以及提交的公开数据,边缘节点仍然可以获取某个特定用户的部分隐私信息。
(2)在哈希加密的基础上进行加盐(Add Salt),即进行哈希加密前在原标识符的特定位置,可以是头部或是尾部加上一串字符,也可以是一次性随机字符串。例如对用户的位置信息进行加盐加密,aS&kv*(G+南京。显然每次加盐后的数据Hash值都不一样,如果没有一个机制来控制,每次加盐的个人隐私信息都不一样,又不可恢复。这就造成了不可追溯,变成了匿名化。
(3)通过加密标识符生成的假名方式,通常又会额外生成一张假名与原始标识的映射表用来还原标识符。为了安全性,这张映射表和假名化的数据是分开保存的。但是攻击者只要一旦获得这张映射表,则用户的个人信息将会无可避免地被泄露。
4 方案思路
4.1 伪随机序列与种子
给定一个数字序列,它既是可以预先确定并可重复出现的,又是具有某种随机特性的序列,则可以称为伪随机序列。检验一个数学序列是否为随机序列的方法有很多,具体有卡方检验、KS检验和频率测试等。伪随机数都是通过计算机再选取随机种子并根据一定的计算方法得到的,所以只要确定种子和计算方法,那么就可以复现随机数。可以把种子看作是控制随机序列的密钥。
线性同余法是最早的伪随机数生成算法之一,并且被广泛使用。通过递推关系可实现随机关系的复现,也就是只需要输入种子就可以生成特定的随机序列。公式如下:
Xn+1=(aXn+c),mod(m)
其中,X为伪随机数列,m为模数(m>0),它是生成序列的最大周期,a是乘数(0<a<m),c为增量(0≤c<m),且当c=0时称为乘同余法,c≠0时称为混合同余法,X0为种子点(0≤X0<m),即起始值。这里的m,a,c是设定的常数。
4.2 伪随机盐值生成
如果使用随机字符串作为盐值进行加密,则会产生数据的不可控性等问题。所以采用伪随机序列来作为盐值生成器则可以解决这一问题。伪随机生成器会生成可控的随机数据作为Hash加密使用的盐值,再把伪随机数加入原标识符,最后对整个数据进行Hash假名化。
5 方案实现
本文提出了一个采用伪随机序列生成盐值的方法实现哈希假名化,即这个盐值是由伪随机生成算法获得的,这个盐值作为密钥加入原标识符,再通过Hash对用户隐私数据进行Hash加密。
边缘节点与用户数据流时序如图4所示。整个方案的实现过程如下。
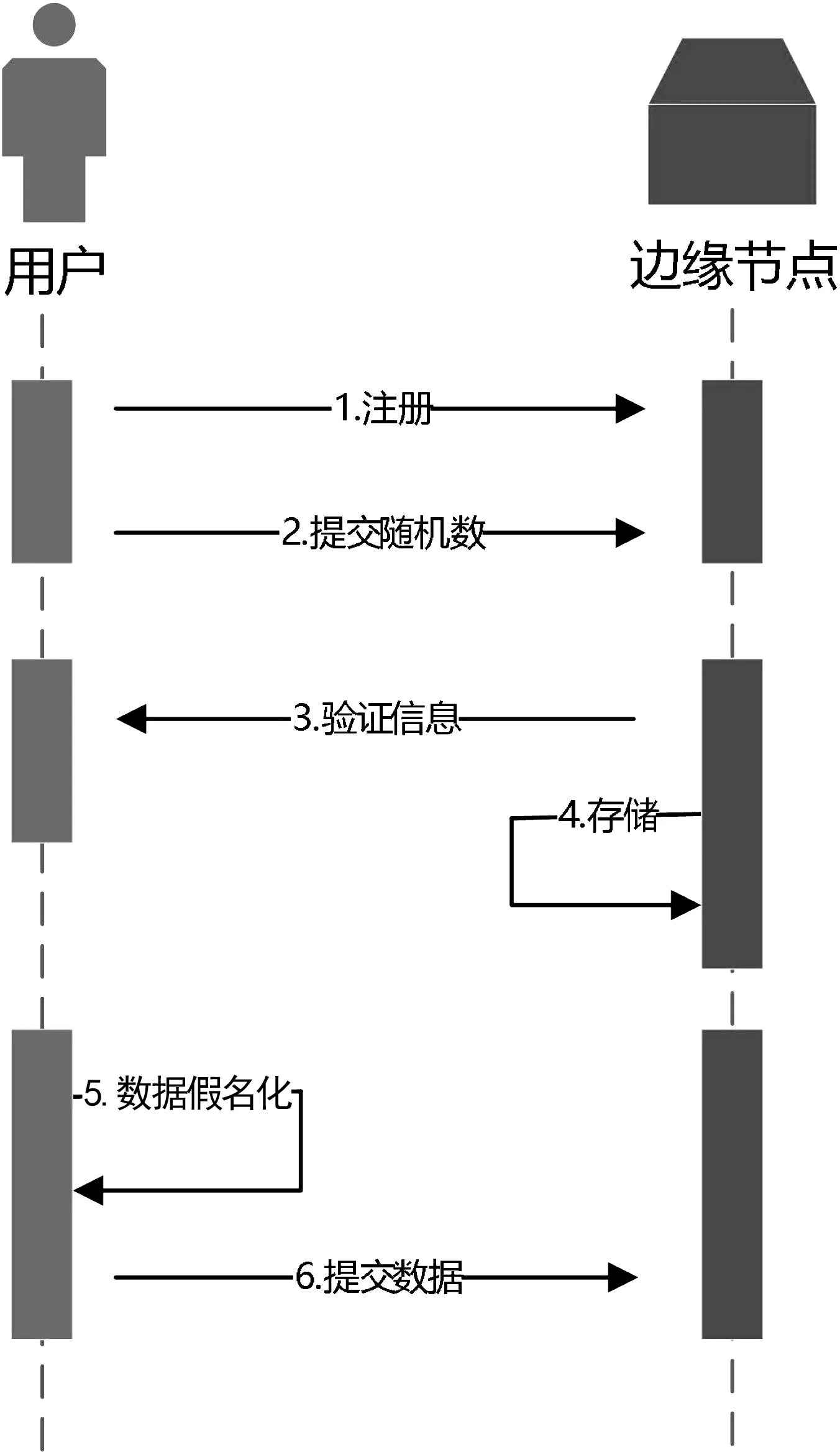
图4 边缘节点与用户数据流时序
(1)Step1:约定随机种子。用户首先需要在边缘计算平台进行注册,然后提交自己的一个随机数,接着平台需要验证用户的随机数是否符合基本标准,如确定无误后通知用户注册成功,不成功则要求用户重新提交。这个随机数将作为随机种子为后来的数据解析作准备。
(2)Step2:存储种子。边缘节点会收集来自各方用户大量的随机数,这时需要建立一个专门的数据库来存储这些随机数种子,这些种子在数据库中会被重新打乱以便隐藏与建立时间有关的信息。
(3)Step3:数据假名化。用户在提交数据到边缘节点时,先随机生成一个整数N,再通过随机序列种子与伪随机生成器生成随机数列,然后选择该序列中的第N个整数作为Hash key来对用户隐私数据进行Hash加密,从而实现假名化。
(4)Step4:数据发送。当用户数据被提交到边缘节点的同时,整数N将作为公开的信息附加到提交的数据中。
有时,边缘计算服务平台需要追溯某个用户的身份,则可以通过随机数N来确定某次所服务的用户,具体过程如下。
(1)在边缘计算平台上,如果需要追溯某次服务的用户对象,则首先需要从用户数据中取出随机数N。
(2)边缘平台上已经事先存储了每个用户注册时提交的种子,这时候将它取出,然后再使用它生成随机数序列,取出对应的第N个数据。
(3)以该数据作为Hash key对平台上的每个用户信息进行Hash,然后将两者比对即可确定某次边缘计算服务的用户。
6 结语
本文针对边缘计算节点可能收集或利用用户隐私带来的安全问题提出了一个基于伪随机函数的可追溯假名化隐私保护方法。利用伪随机生成器生成随机数学序列,并通过随机种子来控制产生的随机数,以这个随机数据作为哈希的密钥加入原标识符再进行哈希操作从而完成假名化。在用户提交数据到边缘节点时附加一个随机整数作为追溯参数,边缘计算节点使用这个参数即可完成用户的追溯。
猜你喜欢
中国设备工程(2023年16期)2023-08-29
计算机应用(2022年8期)2022-08-24
计算机系统应用(2020年8期)2020-03-22
太原科技大学学报(2019年3期)2019-08-05
信息安全研究(2016年10期)2016-02-28
计算机工程(2015年8期)2015-07-03
电子设计工程(2015年17期)2015-02-27
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年12期)2014-02-27
