
基于元胞机与强化学习的多扰动车间调度算法
2022-01-07 01:57:54王昊天易文超吴光华
计算机集成制造系统 2021年12期
陈 勇,王昊天,易文超,裴 植,王 成,吴光华
(浙江工业大学 工业工程研究所,浙江 杭州310023)
0 引言
近年来,日趋激烈的市场竞争给大型装备制造业带来了新的挑战,复杂多变的市场环境给制造型企业带来了大量的扰动,如紧急插单、取消订单等,这类外部扰动对于生产周期漫长、体积与重量庞大的大型装备制造业的影响尤为巨大。除此之外,由于大型装备制造业小批量多品种的特性,设备的负荷与维护差异极大,很容易引起设备故障等内部扰动[1-3]。在这样的生产环境下,为提高多扰动车间的制造柔性,如何更有效地进行生产调度,成为未来研究的热点。
目前,对生产调度的研究主要集中在鲁棒调度方法、重调度方法和智能调度方法上[4-5]。陈勇等[6]考虑了订单不确定的扰动因素,建立了以交付满意度最大化、装配线平衡率最大化和完工时间最小化的多目标生产车间鲁棒控制模型。PAN等[7]针对产品不确定的加工时间以及交付时间,利用量子粒子群算法解决了作业车间柔性调度的问题。强化学习等新兴的智能算法已经在电梯调度、项目调度以及机器人控制等领域获得了成功的应用,表明了其解决调度问题的有效性,因此,近年来强化学习算法也越来越多地应用于生产调度领域[8-11]。何彦等[12]研究了机械车间柔性工艺路线对调度能耗的影响特性,提出一种改进的Q学习算法,解决了柔性工艺路线的动态调度问题。杨宏兵等[13]针对多态单机生产系统,基于模型最优方程设计了一种无模型强化学习算法,解决了以加工成本与维修费用最小化为目标的生产调度问题。元胞机是目前复杂系统领域最受关注的仿真工具之一。AGRAWAL等[14]以减少完工时间为目标提出了结合遗传算法的元胞机模型框架。陈勇等[15]利用改进的遗传算法优化了元胞机的演化规则,实现了大型机械零件的精确调度。
多扰动车间生产调度具有复杂性、强扰动性和多目标性等特点,要求模型能够客观描述复杂系统而不受“指数爆炸”的影响,并且能较好地表达个体之间的差异。由于多扰动车间存在的特点,上述方法已经不适用于该环境下车间的生产调度,需要结合多种方法进行研究。笔者以元胞机模型为框架建立多扰动车间生产调度模型,容易对个体差异进行离散化表达,能够对大规模复杂系统进行快速建模与表征,同时运用强化学习算法优化元胞机演化规则,能够很好地表征多扰动复杂环境下个体的自主决策行为,从而提高车间生产调度的柔性与鲁棒性。
1 基于元胞机的多扰动车间调度建模
元胞机是一种离散的动力学模型,可以用来模拟复杂系统的演化过程。元胞空间中的各元胞都有其自身的状态,在各个离散时刻下,各元胞的状态会根据邻近元胞状态和演化规则进行改变,从而模拟系统的演变过程[16]。一个标准元胞机的数学表达式为:
A=(Ld,S,N,f)。
(1)
式中:A表示元胞机系统;L表示元胞空间;d表示整数型元胞空间的维数;S表示有限且离散的元胞状态集合;N表示包括中心元胞的所有元胞组合;f表示局部演化规则,即状态转移函数。
1.1 元胞空间构建
1.1.1 双层元胞空间
本文根据扰动车间的特点,提出建立双层二维元胞机调度模型,模型分为实体层(作业环境)和扰动层(生产环境的扰动因素)。
(1)实体层 模型的实体层以一个生产车间为研究对象,如图1所示,将该区域划分为一个二维网格,正方形网格代表各工位元胞,矩形网格代表各缓存元胞。偶数行表示加工性质相同的工位元胞,且同组间不同工位加工效率不同,一个工位组对应一个缓存元胞。
(2)扰动层 模型的扰动层以实体层元胞为基础,是对实体层元胞加工属性、缓存属性在扰动层面的扩展。由扰动元胞决定实体层相应位置上的元胞是否可用或在每一仿真时步监测是否有紧急插单或新订单情况,如图2所示。
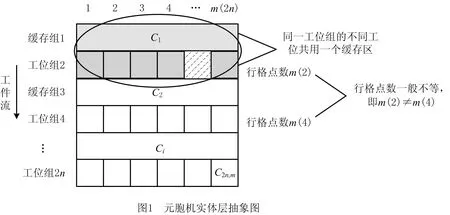

1.1.2 状态属性定义
元胞状态属性的定义是元胞机调度模型演化的基础,它能够反映生产环境的主要特点,元胞在某一时刻的状态可用状态属性集合表示。
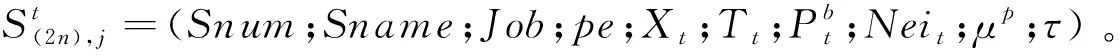
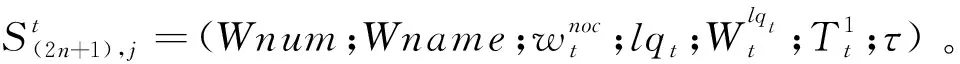
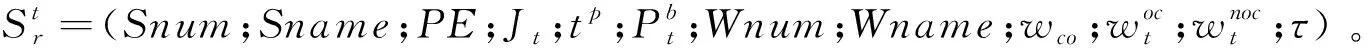
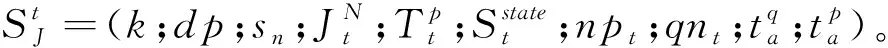
1.2 目标函数与演化规则设计
1.2.1 目标函数设计
针对车间频繁发生的扰动,本文主要考虑设备故障、紧急插单和新订单干扰3种。设备故障主要体现在影响工位的加工能力和利用率;紧急插单与新订单主要表现为不合格品返工、已有订单的交货期提前导致工件工序优先级提高等。为了提升车间调度在扰动环境下的自适应性和柔性,设计如下调度目标函数:
(1)所有工序的加权平均流程时间最短,即最小化F1,目标函数
(2)
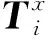
(2) 同一工位组所有工位的平均利用率F2最大,目标函数F2为:
(3)
(3)总目标函数需将双目标进行糅合,且进行归一化,为使总目标F最小化,将两项做如下处理,总目标函数F为:

(4)
生产约束条件如下:
(1)资源约束。
1)同一时刻,一台设备只能加工一个工件:
(5)
2)同一时刻,工件的同一道工序只能在一台设备上加工:
(6)
式中aiy表示工件i是否在工位组的第y个工位上加工,若是,则aiy=1,否则aiy=0。
(2)工艺约束。同一工件工序之间存在先后约束关系。
1.2.2 演化规则定义
演化规则是元胞机模型的关键部分,依据以上调度目标可归纳出本模型的工序选择、工件排序以及任务触发3种演化规则,以模拟在元胞机空间的调度行为,如表1所示。

表1 生产调度模型演化规则
1.3 算例验证
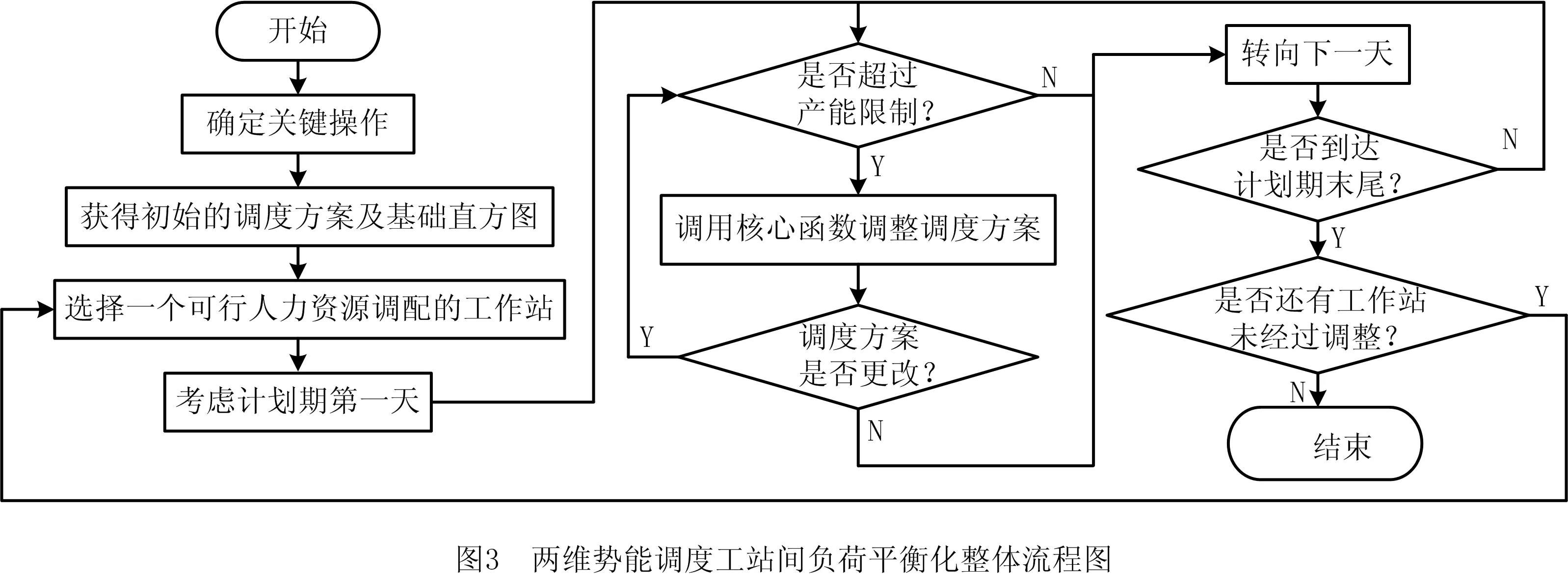
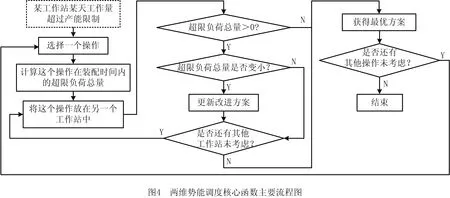
通过算例与文献[17]研究的启发式两维势能调度算法进行比较,以证明本文元胞机模型的科学性与有效性。二维势能调度算法兼顾时间维度与工作站之间两方面的均衡化,以实现整体工作量的均衡。其工作站之间的负荷平衡化整体流程如图3所示,整体流程还需调用核心函数,如图4所示。基于元胞机模型的调度流程依据元胞机的演化规则,整体流程如图5所示。
本算例研究的是文献[17]中的某企业大型产品装配生产调度问题,问题目标需提高各工作站之间的负荷平衡率。该算例的数据较大:2 000个订单,25 000个操作,20个工作区域,33个操作类型,18个月的工作时间跨度。生产调度存在如下约束:各订单的加工路径固定,即工艺流程固定;各订单之间存在优先级约束;个别订单加工时间固定。
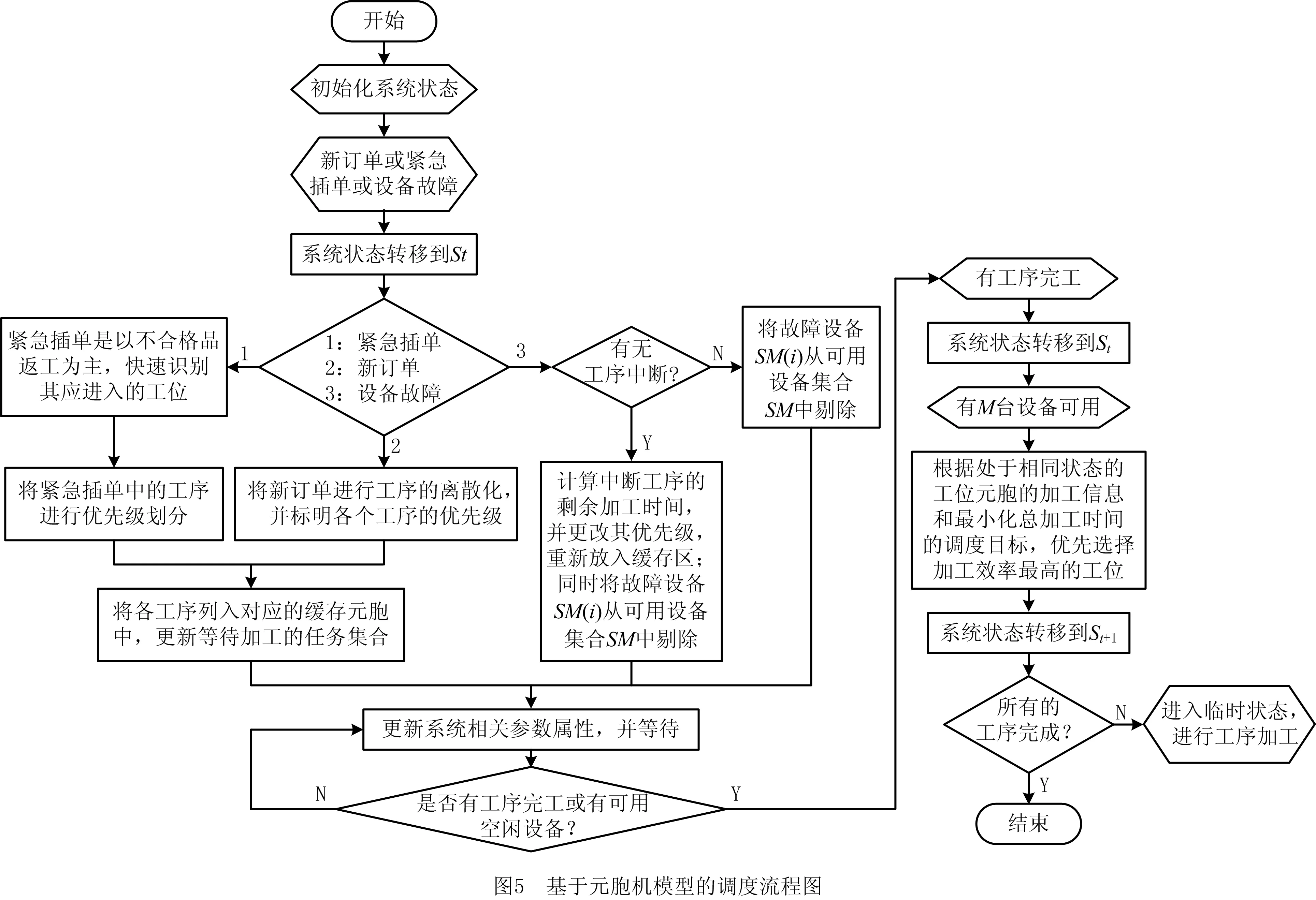
以上述案例作为算例对比验证的对象,统计工作区域的36个工作站数据,基于元胞机模型的调度算法与两维势能算法的调度方案结果对比如表2所示。可以看出,相对于两维势能算法,基于元胞机模型的调度方法的优化效果明显,能有效平衡各工位负荷,缩减调度时间,降低生产成本,从而验证了本文模型的科学性与有效性。

表2 不同算法调度结果对比表
2 基于强化学习的元胞机演化规则优化
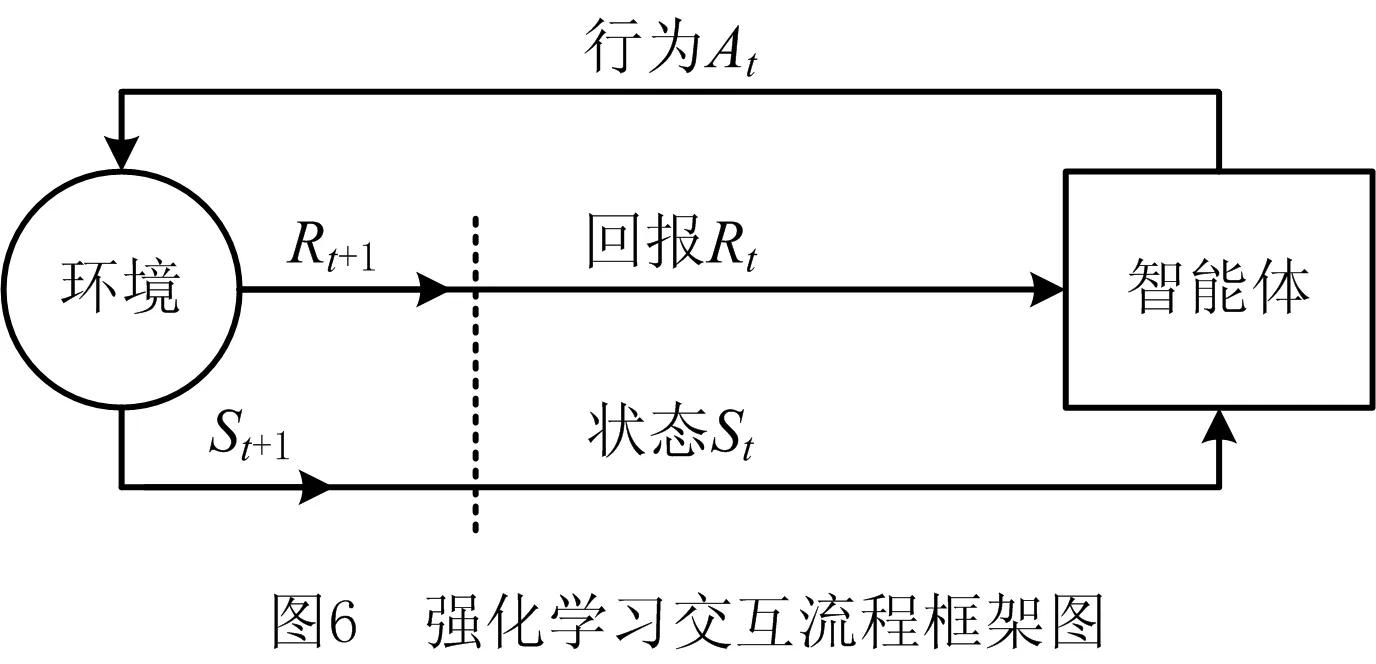
强化学习是一种能够达到全局最优的智能算法,适用于动态不确定环境中的决策问题。学习主体称为智能体,而与智能体交互的外部称为环境,智能体通过选择合适的行为使得环境反馈的期望回报值最大化[18]。
如图6所示为智能体与环境交互的过程,每一个时刻t,智能体根据环境状态St,选择要执行的动作At,然后环境对动作At进行评价,发送奖励Rt+1,并更新到状态St+1,此外,智能体会根据反馈信息,更新自己的策略,策略表示从状态到每种可能行为的选择概率之间的映射,记为πt(s,a),表示状态St=s时At=a的概率。
2.1 元胞机调度系统的强化学习表示
2.1.1 强化学习与元胞机调度模型
自组织演化规则是建立元胞机模型过程中最关键也是最难的步骤,不同元胞因功能不同具有不同的属性值,对应的演化规则也不同,本文选择强化学习算法来探索元胞机模型中最优的自组织演化规则。强化学习算法与元胞机调度模型相关结合点如表3所示。

表3 强化学习算法与元胞机调度模型结合点
2.1.2 状态表示与状态转移
强化学习算法是基于元胞机调度模型的,因此系统的状态也是在元胞状态的基础上进行定义的,公式为:
(7)
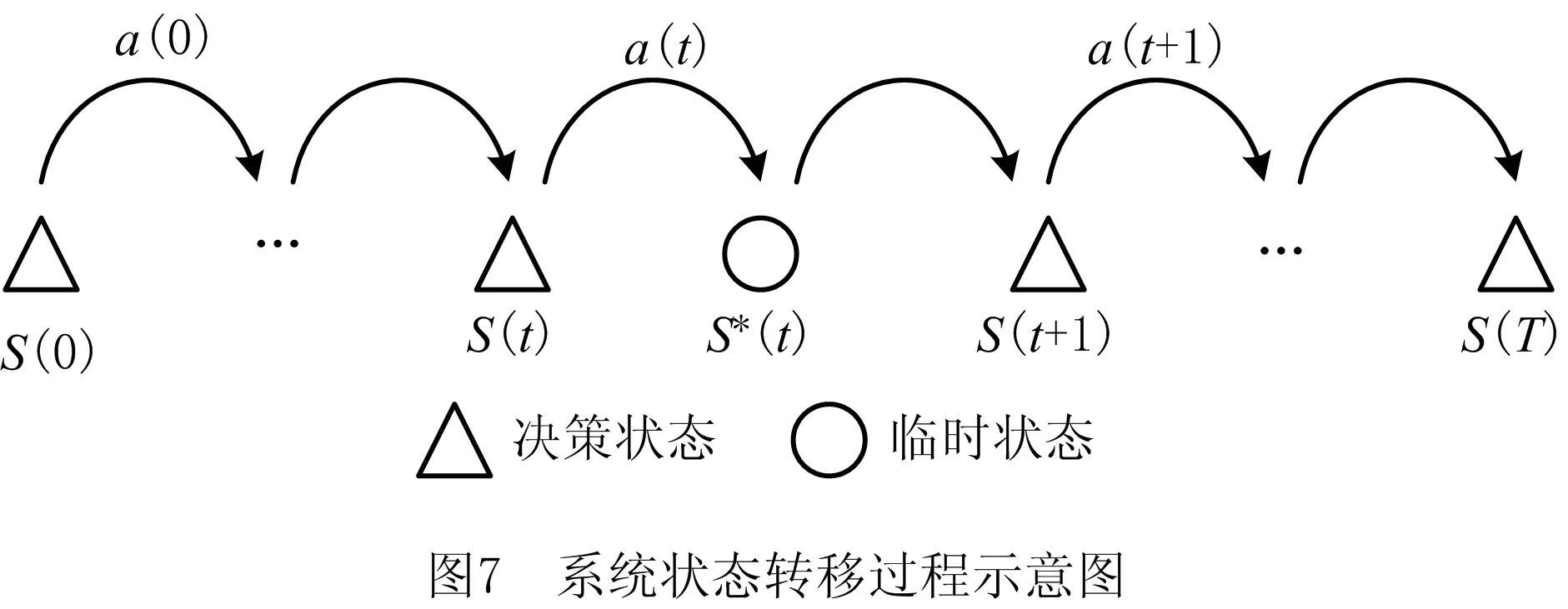
系统状态分为决策状态和临时状态两种。决策状态指要选择动作的状态,即指定工件选择机器和工件排序的任务状态;临时状态是指选择动作并执行后立即转移到的过度状态。
如图7所示为系统状态转移过程。触发系统从临时状态转移到决策状态的触发事件如下:任何一个作业工序加工完毕;有紧急订单或新订单(工序)进入调度系统;任何一个工位发生故障;任何一个工位故障结束。
2.1.3 决策行为
系统从决策状态转移至临时状态是通过执行一个行为,从而改变系统的状态。本文根据生产环境和扰动情况的变化,逐步选择工位和工序,直至加工完所有工序,生成调度方案。
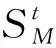
利用已有的调度规则定义如下行为:
(1)行为a1,根据加权最短加工时间选择作业(i*,j*)在机器k*上加工,即
(8)
(2)行为a2,根据最小加权利用率机器选择作业(i*,j*)在机器k*上加工,即
(9)
(3)行为a3,根据最小化加权修正交货期选择作业(i*,j*)在机器k*上加工,即
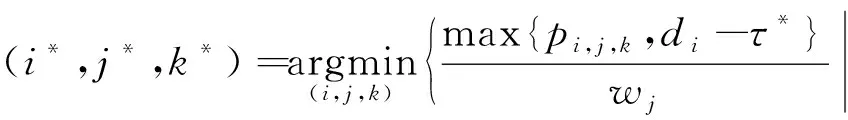
(10)
(4)行为a4,根据改进的排名算法选择机器和作业。
引入信息熵表征机器的不确定度,表达式为
(11)
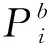
(12)
(5)行为a5,不选择任何作业加工。
2.2 回报计算与行为选择
强化学习的决策过程具有马尔科夫性质,因此采用马尔科夫决策过程来描述强化学习的决策和训练过程。值函数是强化学习算法中一个重要的概念,可通过值函数计算每一步策略的回报值,它将马尔科夫决策中的最优目标与策略联系在一起。
强化学习回报计算与行为选择密切相关,智能体根据每一步行为的选择与报酬函数,计算相应的报酬值,每一步中的报酬值都可能关系到下一决策状态中行为的选择。
2.2.1Q学习算法
强化学习问题的解决思路是寻找一个最优策略,使该策略作用于环境后能够最大化期望回报值。目前,寻找最优策略的方法主要有值函数估计法和策略空间搜索法两种。本文主要使用其中一种主要的值函数估计法——Q学习算法。Q学习算法能够利用经历过的状态—动作序列来决策最优的行为,是一种用于控制的基于行为值函数的强化学习算法。其更新行为的值函数增量式如式(13)所示。
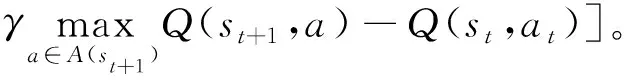
(13)
式中:α表示学习步长;rt+1表示回报值。对Q学习而言,并不需要提前知道环境模型和状态转移函数,它在探索环境并用学习的经验进行训练时,总是采用后续状态的贪婪行为的Q值更新当前状态-行为对的Q值。Q(s,a)值是逐步迭代学习得来的,通过与环境的持续交互来更新表值,直至Q表囊括了绝大多数环境状态下的Q值,随着交互过程的进行,最终收敛于最优状态动作值函数Q*(s,a)。Q学习算法伪代码如下。
算法1Q学习。
1:设置参数α和γ,初始化Q(s,a),∀s∈S,a∈A(s)
2:重复(对于每个片段)
3: 初始化状态s(当前时刻状态)
4: 重复(对于片段中的每一步)
5:根据Q(s,a)和控制策略π,选择行为a
6: 执行动作a,确定下一个决策状态st+1,计算报酬rt+1
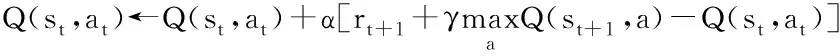
8: st←st+1
9: Until st是终止状态
10: Until收敛
2.2.2 报酬函数构造
报酬函数的构造需要考虑生产调度的目标。每一仿真时步获得的即时报酬反映的是执行动作的短期效果,所有时步的累积报酬反映的是执行动作的长期影响。本文涉及两个优化目标:①最大化设备的平均利用率;②最小化加权平均流程时间。下面分别给出这两个目标的报酬函数。
(1) 由最大化设备平均利用率定义的报酬函数。
首先定义设备繁忙、空闲或者故障状态的示性函数ηk(t),即
(14)
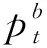
定义报酬函数如下:
(15)
式中:m表示设备的数量;tk与tk-1表示第k与k-1个决策时刻;rk表示系统在时刻tk获得的关于设备平均利用率的即时报酬。可以看出,在决策时刻,工位组处于繁忙状态的设备越多,即时报酬越高。该报酬函数的意义在于:最大化设备平均利用率等价于最大化运行一次试验获得的总报酬R。为此,证明如下。
假设K为一次试验中决策的总次数,则

(16)

(17)
由式(17)可知,最大化报酬值R等价于最小化最大完工时间Tmax,由于所有工件在各设备上的总加工时间是固定的,最小化最大完工时间Tmax等价于最大化设备的平均利用率,证明定义的报酬函数有效。
(2)由最小化加权平均流程时间定义的报酬函数。
首先定义t时刻第i个工件状态的示性函数μi(t),即
(18)
定义报酬函数如式(19)所示:
(19)
式中:n表示工件的数量;wi表示工件i的权重;tk与tk-1表示第k与k-1个决策时刻;rk表示系统在时刻tk获得的关于加权平均流程时间的即时报酬。可以看出,在决策时刻,已经完工的工件越多,即时报酬越高。该报酬函数的意义在于:最小化加权平均流程时间等价于最大化运行一次试验获得的总报酬R。为此,证明如下(假设工件i的到达时间和完工时间分别为ai和ci):
(20)
由式(20)可知,最大化累积报酬等价于最小化ci和ai的差,即最小化工件在系统中的流程时间,从而证明定义的报酬函数有效。
(3)考虑以上双目标优化,将双目标定义的报酬函数糅合为加权的总报酬函数,即

(21)
式中:W1,W2分别表示两个目标的加权系数,W1+W2=1;其他符号意义同上。将双目标转换为单目标的报酬函数,通过控制加权系数W1,W2的大小,决策者可以决定优化目标的偏好。
2.2.3 行为选择
智能体行为的选择与Q值的估计密切相关。强化学习优化生产调度问题时,由于工位、工件、扰动情况等组合后的状态规模异常庞大,各状态行为对的Q值无法用列表一一表述,本文将使用函数泛化器的形式表示状态行为值函数。
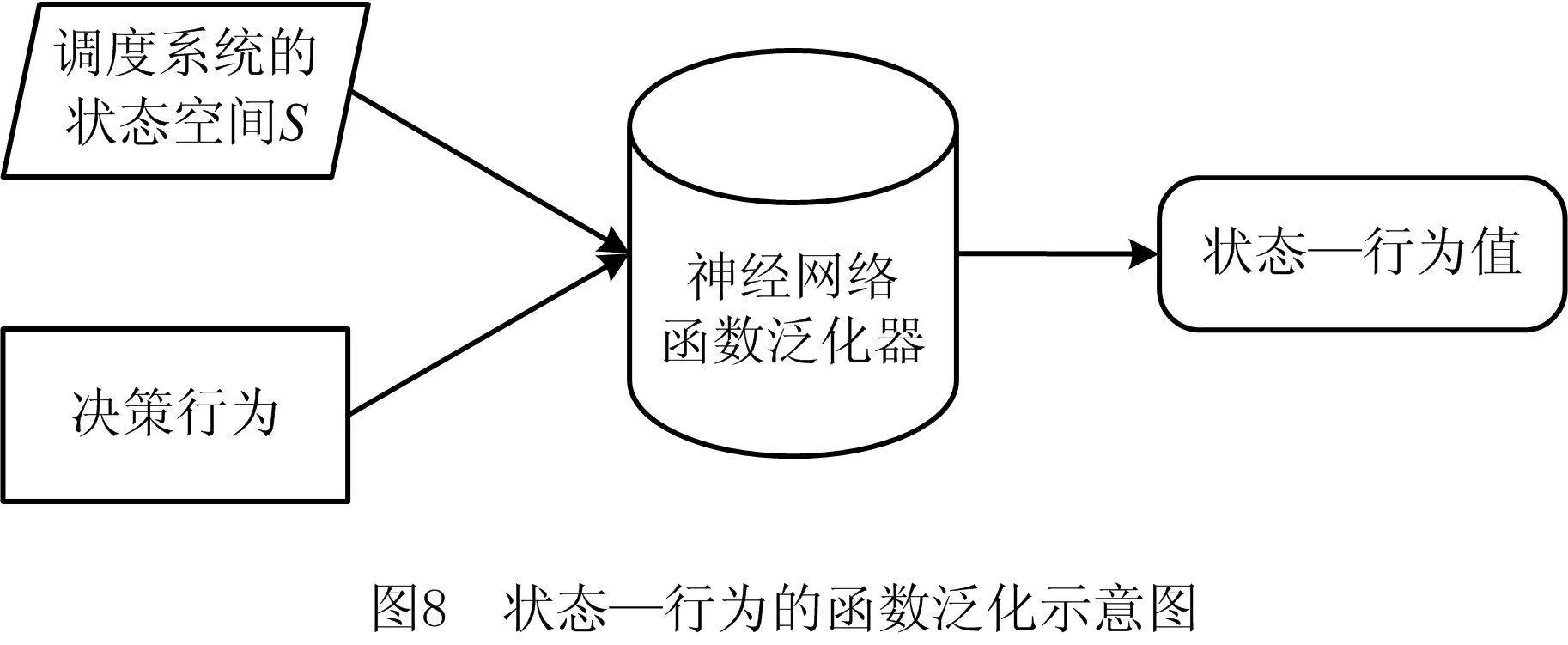
神经网络是常用的函数泛化器,本文采用BP神经网络作为泛化器训练模型。神经网络的输入为调度系统的状态,输出层为状态行为对的Q值。采用函数泛化器的实质就是将具有多扰动的复杂生产调度系统进行降维表示,通过不断优化各神经元之间的权重值,达到优化模型的目的,图8表示了从状态到行为值的转化过程。
强化学习行为的选择还与探索策略相关。本文选择ε-greedy的动作探索策略。ε-greedy策略是指在每一步学习与训练中,智能体以概率ε(0≤ε≤1)选择当前的最优行为决策,即贪婪行为,以期尽快达到最优结果;以概率1-ε选择探索动作,即从行为集合中依概率随机选择动作,以试探可能存在的更优动作。
2.3 基于强化学习的调度策略
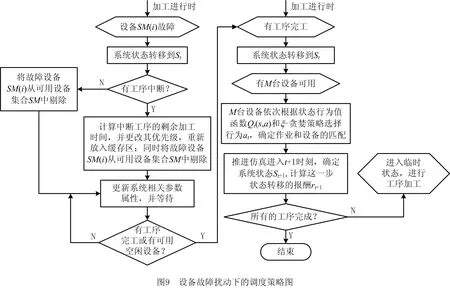
完成了对元胞机调度系统的强化学习表达之后,即可建立完整调度流程。本文采用Q学习算法优化决策过程,通过对每一步状态动作值函数的计算和选择,达到优化调度行为的目的,针对多扰动车间设备故障、紧急插单与新订单干扰3种典型的扰动问题,本文提出了以下调度策略,调度流程如图9和图10所示。
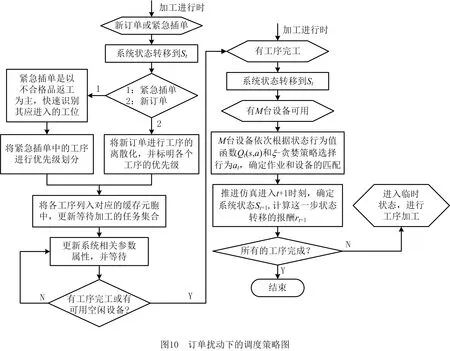
3 实例验证
HY公司是一家大型零件制造企业,生产具有产品体积大、种类多、生产周期长、小批量、通用设备多等特点,其生产车间是典型的多扰动车间,适合作为本文的研究对象,用以验证本文算法与模型的有效性。
3.1 元胞机模型构建与初始化
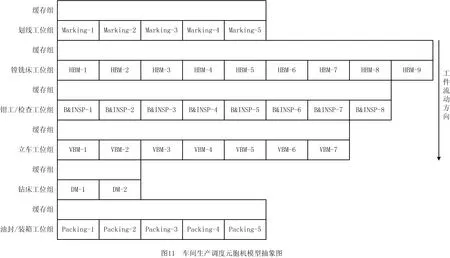
本文针对HY公司最近某年第三季度到达的20种产品共计43个工件的加工排产进行研究。该车间主要工序有7道:划线、钳工、检查、镗铣、车、钻、包装,生产布局根据元胞机模型特点抽象后如图11所示。
利用强化学习算法与元胞机调度模型进行学习和训练之前,需对现场采集的数据加以分析,为模型训练提供必要的输入数据。
由于案例涉及信息过多,就不同工位组而言,整个动态柔性调度过程原理相同,没有重复的必要,本文选择生产车间的瓶颈——镗铣工位组进行具体模型的训练与学习,仿真参与加工的工件粒子按照第三季度实际到达为43个。元胞与粒子状态属性定义已在前文进行说明,这里不再赘述,具体数据依照车间真实信息进行初始化设置。
仿真触发事件的确定是调度演化过程中的关键环节,本实例中的设备故障、新工件到达以及不良品返工扰动是HY公司在实际生产过程中最为典型且不可忽略的因素,因此在模型训练过程中设置设备故障开始、维修结束、新工件到达、不良品返工和工序完工作为仿真触发事件,用来确定调度过程中的实时优化时间,以应对各种突发扰动。
3.2 仿真结果的分析与评价
3.2.1 多扰动下的调度分析
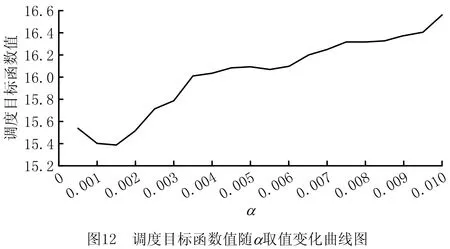
结合BP神经网络函数泛化器的Q学习算法的参数,包括学习步长α,折扣率γ,行为策略因子ξ以及神经元数量K,本文通过实验对比分析,确定本次仿真学习过程中各参数的值。由于α和γ都是Q值更新的重要参数,关联性较强,可以先确定α和γ的参数值,再依次确定ε和K的值。
由于参数设置过程相似,这里仅介绍α的设置过程,省略K,ε,γ参数的设置介绍。当α较大时,函数泛化器的权重在更新过程中的波动会比较大,从而影响泛化的精度。根据经验可知,当α≤0.01时算法效果较好,因此取α的参考区间为(0,0.01]。实验采用调度目标的函数值作为参考依据,令K=20,ξ=0.9,γ=0.1,α分别取0.000 5,0.001,0.001 5,…,0.01,试运行模型50次。调度目标的函数值随α的变化情况如图12所示,当α取0.001 5时调度目标的函数值最小,因此取α=0.001 5。
最终可得到Q学习算法的参数,参数设置α=0.001 5,γ=0.2,ε=0.1,K=30。系统初始化与参数设置完成后,即可进行模型训练。仿真时间从0开始,以调度周期T或所有工件完工为结束时间,训练次数N=2 500,每一仿真步时依据动作策略选择动作,设备故障、不良品返工插单、新工件到达等扰动依据分布函数出现,驱动仿真实时动态调度行为,调度结果甘特图如图13所示。

本文针对的车间因规模庞大,扰动情况多,因此优化过程无法一一阐述。下面对车间三季度中首次出现的扰动和动态优化过程进行说明,即图13中虚线时刻处,分别是首次出现设备故障、不良品返工和新订单扰动。
(1)第一次设备故障扰动出现在HBM-7工位上,此时在该触发事件的驱动下,更新该工位元胞的状态,工位HBM-7状态为不可用,进入维修状态,无正在该设备上加工的工件。待维修结束后,再一次作为触发事件驱动调度任务。根据强化学习的训练结果,计算得到5个状态—行为对(St,a)的Q值:Qt(St,a(1))=-13,Qt(St,a(2))=-15.3,Qt(St,a(3))=-18,Qt(St,a(4))=-19.6,Qt(St,a(5))=-16.1,可见,行为a(1)是该状态下的贪婪行为,即最优的行为决策,因此根据行为a(1)选择工件P2在该工位上加工。
(2)第二次扰动出现在t=Jul.31时刻,车间有不良品返工工件的到来,返工工件进入缓存元胞与原待加工工件一起等待加工,更新所有待加工工件粒子本身的属性和缓存区域的任务集合,此时工位HBM-1空闲,根据Q学习训练结果,计算得到5个状态—行为对(St,a)的Q值:Qt(St,a(1))=-24.6,Qt(St,a(2))=-20.3,Qt(St,a(3))=-25,Qt(St,a(4))=-25.6,Qt(St,a(5))=-20,可见,行为a(5)是该状态下的贪婪行为,根据行为a(5)选择返工工件P16在该工位上加工,图中的斜线填充的矩形表示不良品返工工件。
(3)第三次新订单扰动出现在t=Aug.30时刻,将新订单中的工件放入缓存元胞中,更新工件属性和待加工任务集合,然后观察系统是否有空闲设备,若有,则依据Q学习算法训练结果,选择该状态下的最优行为,如上文所述;若无,则更新完系统状态后不做任何行为选择,进入临时状态等待完工工件的触发。
3.2.2 调度结果对比与评价
将本文模型调度的仿真结果与实际调度方案进行对比。实际调度的甘特图如图14所示,优化前后调度目标函数值对比如表4所示。
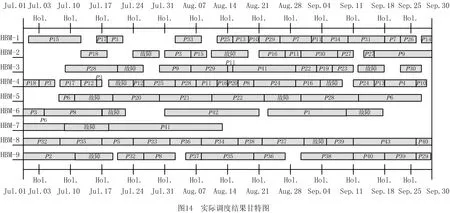
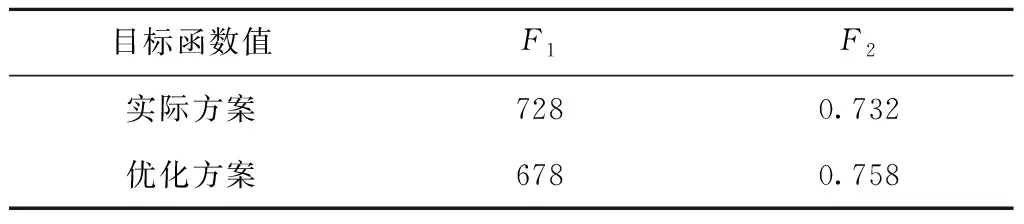
表4 实际方案和优化方案目标函数值对比表
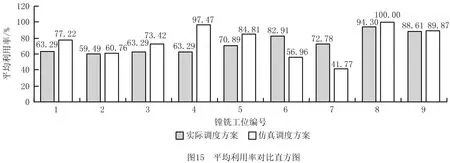
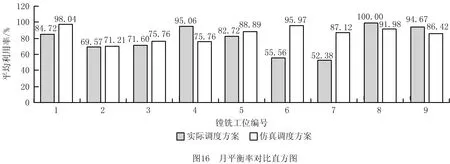
实际调度方案和仿真调度方案中各工位平均利用率和月平衡率对比直方图分别如图15和图16所示。
通过甘特图、目标函数值表以及直方图的对比,可以得到如下结论:
(1)通过调度甘特图对比可知,仿真调度方案切实可行,加工时间紧凑,生产流程能够在扰动事件的驱动下实时优化,具有较强的鲁棒性和柔性,相比于实际调度方案,优化后的生产节奏更为一致,在受到干扰之后依然能保持较高的生产效率。
(2)由目标函数值对比可知,仿真调度方案在总加工时间最小、工位组所有工位的平均利用率最大两个子目标上都要优于实际调度方案。
(3)由工位平均利用率和月平衡率对比直方图可以看出,仿真调度方案的工位平均利用率以及月平衡率都明显优于实际调度方案,体现出仿真调度方案在设备利用、维护和寿命控制方面的优越性。
4 结束语
随着市场竞争加剧,大型装备制造企业受到内外部扰动的影响愈发显著,企业需要在多扰动环境下快速做出合理的生产调度,以提高制造的柔性与鲁棒性。本文利用元胞机模拟复杂系统的优势,将车间生产系统抽象为双层二维元胞机模型,根据设计的目标函数定义了模型演化规则,并引入算例验证了元胞机模型的科学性。为了解决多扰动车间调度的“指数爆炸”难题,以便能在全局上寻找到最优解,引入了强化学习算法来改进元胞机的演化规则,针对3种典型扰动提出了基于Q学习算法的调度策略。最后,通过对HY公司生产车间实例采用算法模型求解得到优化调度方案明显优于实际调度方案,从而有效地提高了生产的柔性与鲁棒性。
未来将基于本文所提出的车间调度算法,在以下方面进行进一步研究:①大型装备体积大,在调度中需进一步考虑物流拥堵造成的延误。②在事件驱动的基础上,考虑周期性驱动或混合驱动,进一步提高生产调度的稳定性。③在Q学习算法的基础上,考虑更优的深度强化学习算法与参数组合,进一步提高算法模型的求解效率。
猜你喜欢
中国新闻周刊(2023年42期)2023-12-03 14:39:41
数学物理学报(2022年4期)2022-08-22 04:06:36
物流技术与应用(2020年5期)2020-06-25 02:48:12
意林(2020年10期)2020-06-01 07:26:37
数学物理学报(2019年4期)2019-10-10 02:38:56
智富时代(2018年5期)2018-07-18 17:52:04
贵州师范学院学报(2016年3期)2016-12-01 03:53:52
北京测绘(2016年2期)2016-01-24 02:28:28
杭州(2015年9期)2015-12-21 02:51:49
电源技术(2015年11期)2015-08-22 08:50:38
