
一种基于OCR 深度学习的自动化站点审核方法
2022-01-06 10:53:52蔡金青
广东通信技术 2021年12期
[蔡金青]
1 引言
随着通信工程勘察设计数智化的发展,勘察设计审核过程逐步引入平台化流转模式,但是仍旧存在图纸审核过程为人工审核,人工记录设计图纸中的关键工程参数、站点信息。且多以办公软件或者小型数据库形式记录,并与后期勘察设计库中的信息进行校验,校验方法采用办公软件公式方法解决。人工审核存在效率低下、工作强度大、易错等缺点。在后期二阶段工程参数、站点信息数据库过程中也多以数据库校验方式判断综合资管平台数据库是否存在入库错误等问题。
本方法通过OCR 深度学习方式提取图纸关键信息,并与平台勘察设计模块中人工录入数据、综合资管平台数据进行自动校验,大幅提升省端站点信息数据审核效率、正确率。
2 原理概述
本方法实现原理主要包括图纸关键字识别、OCR(Optical Character Recognition,光学字符识别)深度学习及关键字入库校验3 个部分。
图纸关键字识别部分首先将可能在文字的区域检测出来,然后再进行识别。本质是识别图片中的文字,即在复杂的图片背景下对所需目标文字进行识别提取。
OCR 深度学习针对基站设计图纸,采用基于AI 训练的图片文字识别模型,对识别的文本框坐标进行检测。该算法结合了CNN(卷积神经网络)和LSTM(循环神经网络)的技术,通过CNN 提取深度特征,LSTM 用于序列的特征识别。基于AI 训练的OCR 模型与调用在线OCR 接口相结合处理模式。平台具体架构如图1 所示。

图1 OCR 深度学习的自动化站点审核平台架构
本方法采用对DXF(图纸格式)的OCR 深度学习,最终自动采集图纸信息,采用DXF 文件相较于原始DWG文件的好处在于:DXF 是Autodesk 公司开发的用于AutoCAD 与其它软件之间进行CAD 数据交换的CAD 数据文件格式。DXF 是一种开放的矢量数据格式,可以分为两类:ASCII 格式和二进制格式;ASCII 具有可读性好,但占有空间较大;二进制格式占有空间小、读取速度快。由于AutoCAD 现在是最流行的CAD 系统,DXF 也被广泛使用,成为事实上的标准。DWG 的来绘图更直观(DXF图纸中线条的相交处都会有个小圆),而用于数控加工的图纸则必须是DXF 文件(操作者必须把DWG 转换成DXF 后才可加工)。DXF 是工业标准格式的一种。
关键字抓取入库将识别出的工程参数、站点信息数据与平台存储的值进行校验,校验的结果会在勘察设计小区列表中呈现。如果信息不一致,可通过系统查看出不一致字段。其中牵涉到工程参数、站点信息一次校验、二次校验流程。具体流程如图2 所示。
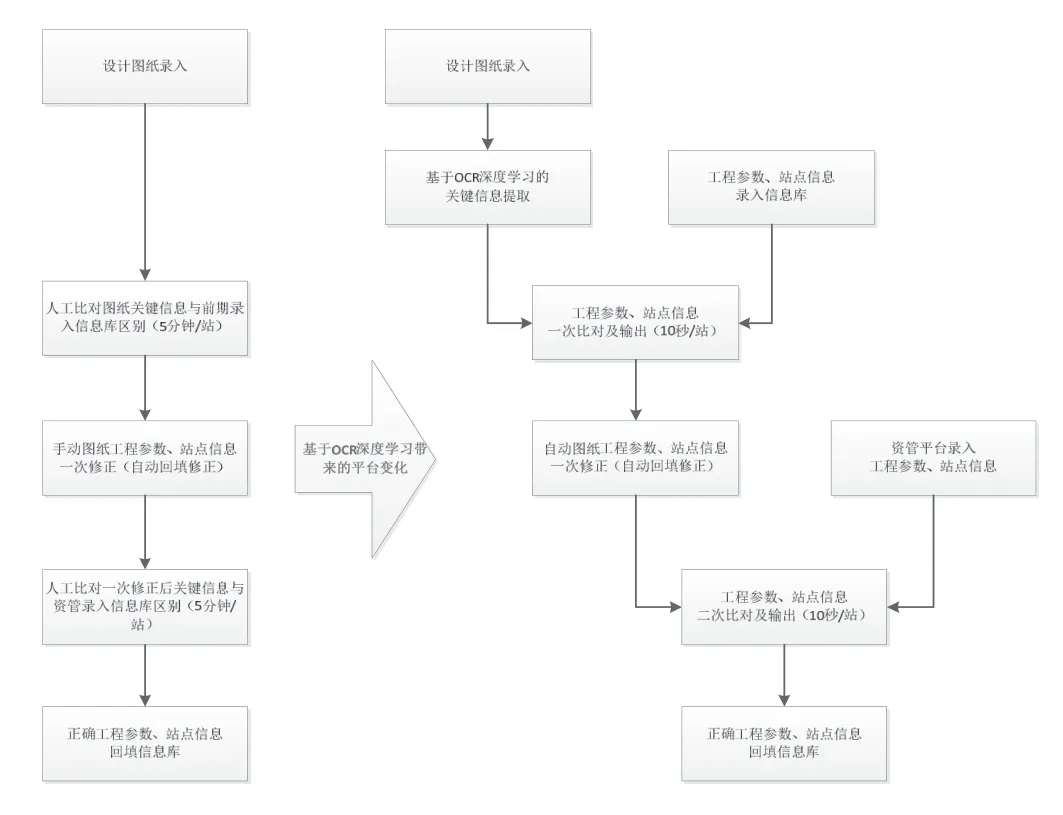
图2 OCR 深度学习的自动化站点审核平台流程
在时效方面,基于OCR 深度学习的自动化站点审核方法将原有站点审核校验回填时间由10 min 缩短至20 s(以单站实验结果),效率提升97%。随着站点数的增加(OCR 图纸深度学习模块以多线程并行服务运行,暂时开启8 线程并行服务),效率值会更进一步提升。
3 图纸关键字识别
OCR 深度学习是检测、识别的基础。首先将文字的区域检测出来,然后再进行识别。本质是识别图片中的文字,即在复杂的图片背景下对所需目标文字进行识别提取。
文字识别可应用于许多领域,如阅读、翻译、文献资料的检索、信件和包裹的分拣、稿件的编辑和校对、大量统计报表和卡片的汇总与分析、银行支票的处理、商品发票的统计汇总、商品编码的识别、商品仓库的管理,以及水、电、煤气、房租、人身保险等费用的征收业务中的大量信用卡片的自动处理和办公室打字员工作的局部自动化等。以及文档检索,各类证件识别,方便用户快速录入信息,提高各行各业的工作效率。
3.1 文字识别基础步骤
(1)文字区域:检测存在文字的区域。
(2)文字检测:识别区域中的文字。
3.2 文字区域
对文字存在区域的检测方法,与目标检测领域的常用检测方法相当,分为一步和二步二种方法,后续也可以考虑使用无标记方法对文字区域进行检测。
(1)在文字识别领域,常用的二步方法为快速RCNN,单阶段方法。相比之下,前者的精度更好,后者速度更快。
(2)在文字识别领域,与传统目标检测的不同还在于文字的方向、扭曲程度等。
对于水平文字的检测。水平文字文本框是规则的四边形(4 个自由度),类似于物体检测。水平文字检测效果较好的算法为CTPN。
文本框是不规则的四边形,拥有8 个自由度,倾斜文字检测较好的算法由cvpr2017 提出。一般的检测套路为:检测文本框,采用拉东变换、霍夫变换等方法进行文本矫正,通过投影直方图分割单行文本图片,对单行文本进行OCR。
3.3 文字检测
文字采用分类模式,可以对字符进行分割后单独识别,也可以进行序列识别,显然易见的是,序列识别才是真正有意义的。
(1)定长文字:各个字符之间是独立的,需事先选定可预测的序列的最大长度,比较适用于门牌检测或车牌号码检测。
(2)不定长文字:可以产生任意长度的文字。
将文字检测和识别放在一个网络中进行联合训练,目前主流的两种模型。
①CNN 与RNN/LSTM/GRU 与CTC:卷积神经网络(Convolutional Neural Networks,CNN)与递归神经网络(Recurrent Neural Network,RNN)/长短期记忆神经网络(Long Short-Term Memory,LSTM)/门控循环单元神经网络(Gated Recurrent Unit,GRU)与时序类分类(Connectionist Temporal Classification,CTC)。
②引入注意力机制(CNN+RNN+Attention):其中注意力机制可以分为硬模式和软模式。其中硬模式能够直接给出硬定位,通常是直观展现文字区域的位置。软模式通常采用RNN/LSTM/GRU。
4 OCR 深度学习提取
将设计图纸文字提取出来后,拼接为整个文本串,再从文本串中识别提取关键字如挂高、天线方位角、电调下倾角、机械下倾角、经纬度等,最后从关键字前后识别非中文字符得到对应的关键数据。并通过文字识别校验,实现工程参数、站点信息关键核验功能。
部分代码如图3 所示。
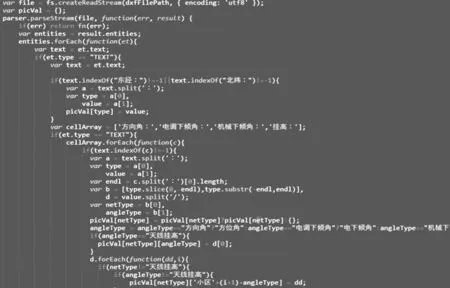
图3 文字识别部分关键代码
具体技术原理及步骤包括3 步。
(1)设计人员将CAD 图纸的存储为更易识别的DXF 格式(DXF 是一种开放的矢量数据格式,易解析),并上传至规划审核平台的勘察设计模块。
(2)勘察设计模块上传CAD 图纸的同时,系统会同时启动OCR 深度学习模块提取关键信息功能,将图纸中所需的工程参数、站点信息数据自动识别(调用DXFparser 模块模糊找出DXF 中需要读取标记的字段,存储在内存中),并且与勘察设计中人工录入的参数信息进行校验。
(3)将识别出的工程参数、站点信息数据与平台存储的值进行校验,校验的结果会在勘察设计小区列表中呈现。如果信息不一致,可通过系统查看出不一致字段。
图纸中关键工程参数、站点信息如图4 所示。

图4 关键工程参数、站点信息提取
5 关键字入库校验
勘察设计模块上传CAD 图纸的同时,系统会同时启动启动OCR 深度学习模块提取关键信息功能,将图纸中所需的工程参数、站点信息数据自动识别抓取入库与勘察信息库进行关键信息校验。具体校验如图5 所示。

图5 关键工程参数、站点信息入库
将识别出的工程参数、站点信息数据与勘察信息库的值进行校验,校验的结果会在勘察设计小区列表中呈现。如果信息不一致,可通过系统查看出不一致字段。具体比对如图6 所示。
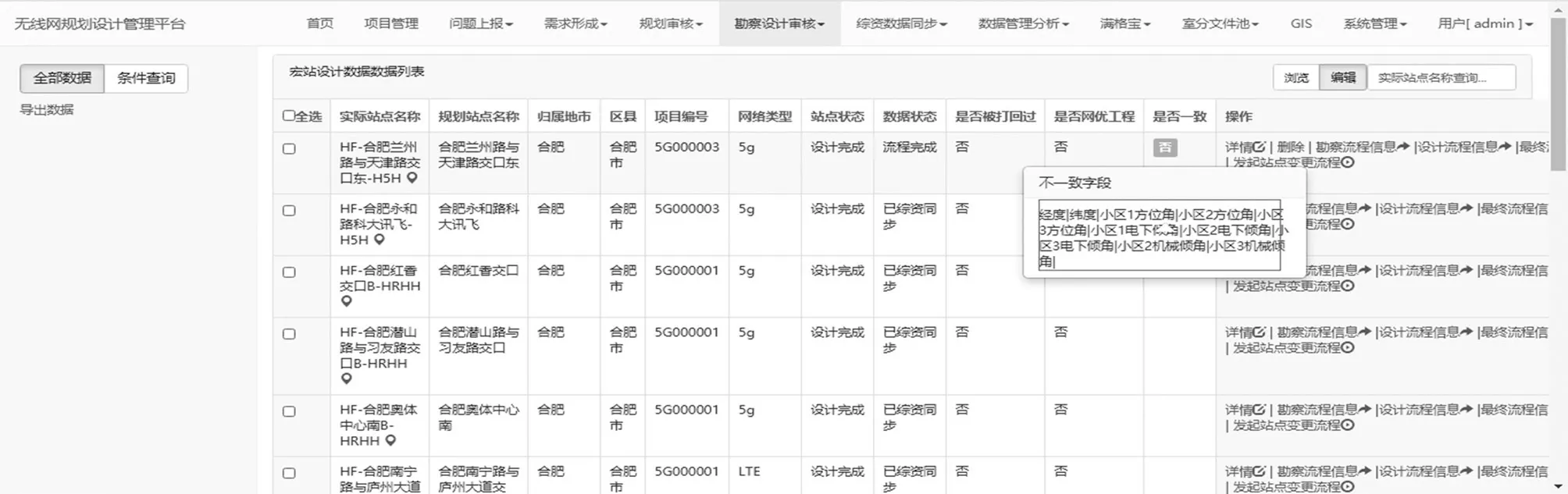
图6 关键工程参数、站点信息校验比对
后期待施工完成入网后,再将关键信息与综合资管平台进行二次校验,并保证站点信息全平台准确唯一。
6 总结
一种基于OCR 深度学习的自动化站点审核方法,该方法通过数智化手段针对站点图纸通过OCR 深度学习的方法提取设计图纸中的关键工程参数、站点信息(挂高、天线方位角、电调下倾角、机械下倾角、经纬度、区域位置、环境描述等)入库。将从图纸中提取出的站点关键工程参数、站点信息与勘察设计库中的信息比对以校验审核设计阶段出现的工程参数、站点信息错误,以及后期资管平台关键信息错误。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
电子制作(2019年14期)2019-08-20 05:43:42
国际呼吸杂志(2019年1期)2019-01-28 09:37:02
中国铸造装备与技术(2017年6期)2018-01-22 01:50:04
中国自行车(2017年1期)2017-04-16 02:53:52
故事会(2016年21期)2016-11-10 21:15:15
电测与仪表(2015年1期)2015-04-09 12:03:02
电测与仪表(2015年19期)2015-04-09 11:32:44
设备管理与维修(2015年9期)2015-03-16 02:24:04
NBA特刊(2014年7期)2014-04-29 00:44:03
