
面向光学遥感图像典型目标检测的SSD模型优化①
2022-01-06 06:05薛俊达朱家佳李晓辉李子扬苑馨方李传荣
计算机系统应用 2021年10期
薛俊达,朱家佳,李晓辉,张 静,窦 帅,米 琳,李子扬,苑馨方,李传荣
1(中国科学院 空天信息创新研究院 定量遥感信息技术重点实验室,北京 100094)
2(中国科学院大学 光电学院,北京 100049)
随着计算机处理能力的显著提升以及深度学习、卷积神经网络(Convolutional Neural Network,CNN)技术在自然图像目标检测应用中取得巨大成功,为实现高精度、自动、高效的遥感图像目标检测提供了新的技术途径与动力.2016年,Liu等[1]提出了SSD(Single Shot multibox Detector)模型.作为单阶段目标检测模型的代表之一,SSD模型在目标定位与分类过程中借鉴了双阶段模型Faster-R-CNN[2]的“anchor boxes”以及多尺度特征提取的思想,使其在保持单阶段目标检测模型的高检测效率的同时,检测精度有了很大提升.SSD在自然图像PASCAL VOC 2007数据集的平均检测精度mAP达到75.1%,每秒检测帧率(Frame Per Second,FPS)达到58,很大程度上实现了检测精度与速度的平衡.SSD的上述技术特点,使其在遥感图像目标检测任务中展现出很好的适用性和技术潜力,受到关注.
相比自然图像,遥感图像的图幅更大、场景和目标更为复杂,将SSD模型直接应用于遥感图像目标检测中难以获得满意的效果,必须针对遥感图像特点与目标分布特征对SSD模型进行适当的改进与优化.朱敏超等[3]针对遥感图像目标检测提出了改进的FDSSD网络,借鉴特征金字塔网络(Feature Pyramid Networks,FPN)[4]增强低层特征空间语义信息,在DOTA遥感图像数据集[5]的检测精度较原SSD模型有一定提升,对飞机、小汽车的检测精度分别为71.98%和41.56%.史文旭等[6]提出了改进的FESSD模型,分别利用多分支卷积和双路径网络思想增强网络特征特征提取能力,在自己构建的遥感图像数据集上的mAP达到79.36%,对飞机的检测精度为80.96%.Wang等[7]提出了一种特征融合FMSSD模型,通过采用空洞空间特征金字塔模块、区域加权代价函数以及优化Loss计算方法等优化措施,对DOTA遥感图像数据集的飞机和小汽车等典型目标的检测精度分别达到89.11%和69.23%.
在光学遥感图像目标检测研究与应用中,飞机、汽车是最为典型且使用最为普遍的目标.一方面,这些目标在日常生活中非常普遍,包含这些目标的光学遥感图像非常容易获得,目标样本量大,对目标检测模型/方法进行训练和验证的可行性非常高.另一方面,飞机在光学遥感图像中表现为形态特征较明显、目标与背景对比度较高、目标样本尺度分布较宽(小到几十乘几十像素、大到几百乘几百像素)等特点; 汽车在光学遥感图像中则表现为与背景对比度较低、目标尺寸小且样本尺度分布窄(绝大部分目标框尺寸在50×50像素以下)、密集分布、数量很大等特点.在光学遥感图像目标检测研究中,这两类目标在形态、样本尺度分布、样本数量以及特征提取难度等方面具有非常显著的差异,对于分析和验证目标检测模型/方法的通用性和适用性具有实际意义.
本文面向光学遥感图像目标检测应用,以提升SSD模型对光学遥感图像中的飞机和汽车类典型目标的检测精度为目标,提出一种结合多尺度特征融合与目标框聚类分析的SSD优化模型:1)借鉴特征金字塔多尺度特征融合思想设计并引入多尺度特征融合模块,实现深层特征与浅层特征的融合以获得更多的特征上下文信息,增强网络对目标特征的提取能力; 2)根据数据集目标样本尺寸分布特征进行聚类分析获得更准确的默认目标框参数,以有效提升网络对目标位置信息的提取能力.
1 模型设计
本文模型框架如图1所示.
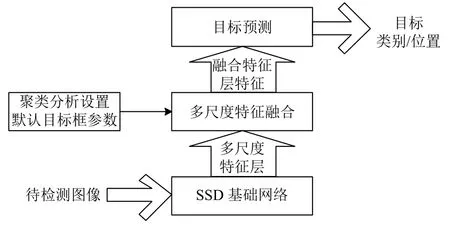
图1 本文模型框架图
本文模型充分考虑各特征层之间的上下文联系,在SSD模型的基础上引入由效率更高的反池化实现上采样的多尺度特征融合模块,同时辅以分类别K-means聚类分析获得更符合数据集目标框尺寸分布的模型默认目标框参数.在不显著增加模型运算量的情况下,提升SSD模型的特征提取能力以及目标定位精度.
1.1 多尺度特征融合
原始的SSD模型由改造后的VGG-16网络增加5个卷积层(FC7、Conv8_2、Conv9_2、Conv10_2、Con11_2)组成.SSD模型使用网络中的6个不同尺度的特征层组对目标进行分类和定位:浅层特征层(Conv4_3和FC7)主要用来预测小尺寸目标,深层特征层(Conv8_2、Conv9_2、Conv10_2、Con11_2)主要用来预测大尺寸目标,从而提升了SSD模型对于不同尺度目标检测的适用性.以上设计虽然考虑了多尺度特征的使用,但没有考虑不同尺度特征之间的关联信息,目标特征提取并不充分,特别是对小尺寸目标(如汽车)的检测精度提升有限.
为了能更充分提取目标特征,提升模型对小尺寸目标的检测精度,本文借鉴FPN思想,设计并引入了多尺度特征融合模块,采用如图2所示的“由深至浅+横向连接”的方式,提取SSD网络中的7个不同尺度的特征层(Conv4_3、Conv5_3、FC7、Conv8_2、Conv9_2、Conv10_2、Con11_2)的输出特征进行目标特征融合.

图2 多尺度特征融合模块结构
由于反池化操作不需要参数学习,可以有效减少模型参数、提高学习及检测效率[8]; 并且反池化操作在非感兴趣特征处补0,可以更有效区分感兴趣特征与背景、更容易检出目标特征,本文在“由深至浅”过程中采用反池化操作代替目前普遍采用的反卷积操作来实现融合特征图上采样.表1显示了SSD模型在分别引入由反卷积与反池化实现上采样的多尺度特征融合后的目标检测效率对比; 图3显示了两种特征融合方式得到的融合特征图的对比.
从表1可以看出,SSD模型在使用反池化实现上采样后,检测效率没有明显下降,FPS仅减少了2,性能表现优于反卷积.从图3中可以看出,使用反池化实现上采样得到的融合特征图中的目标纹理更加清晰,与背景的区别度更高,更利于提取目标特征.

图3 两种特征融合方式所得融合特征图对比

表1 3种目标检测模型的目标检测效率对比
另外,为了支持多尺度特征融合模块进行多尺度特征融合,在SSD网络生成多尺度特征层的池化过程中采用最大值池化,并输出最大值位置索引,用于多尺度特征融合模块“由深至浅”过程中的反池化操作.
1.2 聚类分析设置默认目标框参数
本文模型利用多尺度特征融合模块输出的7个尺度的融合特征图进行目标预测,需要在模型训练前预设各融合特征图上的默认目标框参数.SSD模型利用经验公式设置默认目标框参数.但是,SSD使用的经验公式源于自然图像,并不能很好契合遥感图像中的目标分布特征,这也是SSD模型直接应用于遥感图像目标检测难以取得满意效果的原因之一.
如前文所述,在光学遥感图像中,飞机与汽车除了在形态上具有显著差异,在目标尺寸、数量以及尺度分布等方面都具有显著差异.以当前应用最广、样本最丰富的DOTA遥感图像数据集为例,表2列出了数据集中飞机和汽车样本目标框尺寸分布情况.

表2 DOTA数据集样本目标框尺寸分布统计表
从表2中可以看出,飞机样本的目标框尺寸在51×51-454×454像素间,其中,85.02%的样本尺寸在51×51-200×200像素间; 汽车样本的目标框尺寸在2×2-200×200像素之间,但87.75%的样本尺寸小于50×50像素,目标尺寸总体偏小.飞机比汽车具有更宽的目标样本尺度分布,同时汽车的样本量远大于飞机的样本量,占总样本量的95.37%.上述差异都为预设目标框参数增加了一定难度.
YOLOv3模型[9]使用基于全局目标框K-means聚类方法来进行预设目标框大小,但此方法容易导致聚类结果偏向样本量大的一方.本文借鉴聚类方法预设目标框参数的思路,采用分类别K-means聚类分析法,以得到更具代表性的默认目标框参数.
图4显示了对DOTA数据集的训练数据集中的两类目标样本的目标框进行分类别K-means聚类分析得到的聚类个数k值与目标平均覆盖度[9]的变化关系.由图4可以看出,随着聚类个数的增加,平均覆盖度变化趋于稳定,且根据函数趋势可以看出,两类目标的平均覆盖度变化开始趋于稳定的临界点均在聚类个数k=8附近,可以认为聚类个数k>8时的聚类结果比较理想.
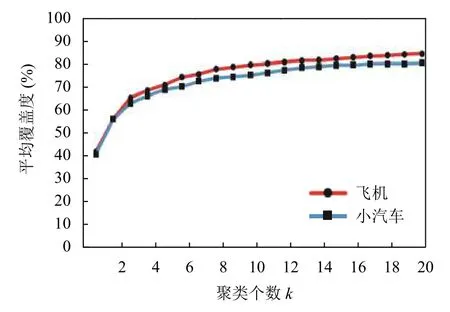
图4 两类样本目标框K-means聚类折线统计
经过进一步的聚类分析,针对汽车和飞机分别选择k=8和k=15时的目标框聚类结果进行整合得到最终的23个默认目标框参数,分别为[5,10]、[10,6]、[9,11]、[9,18]、[20,11]、[21,20]、[14,21]、[36,37]、[47,48]、[28,29]、[56,67]、[41,39]、[18,18]、[44,61]、[142,135]、[68,67]、[90,69]、[94,93]、[77,84]、[55,54]、[108,110]、[178,174]、[254,256].图5给出了采用分类别聚类方法和全局聚类方法获得的目标框尺寸聚类结果对比.表3显示了采用SSD经验公式、全局聚类和分类别聚类方法获得默认目标框参数的目标尺寸平均覆盖度定量评估结果.
从表3可以看出,采用分类别聚类方法获得默认目标框参数,对飞机和汽车目标的平均覆盖度均优于80%,说明该方法获得的默认目标框参数能够更好反映遥感数集中飞机和汽车这两类目标的尺寸分布.从图5和表3可以看出,基于全局K-means聚类方法得到的聚类结果大多集中在50×50像素以下,在50×50-512×512 像素之间仅有一个聚类中心,对飞机目标的平均覆盖度较低,极大限制了模型对于飞机目标的检测;而分类别K-means聚类方法在保证平均覆盖度有一定提升的情况下,避免了聚类结果偏向样本数量大的一方的问题,聚类结果能够同时很好契合汽车和飞机目标的分布特征,能够获得更高和更均衡的目标平均覆盖度.
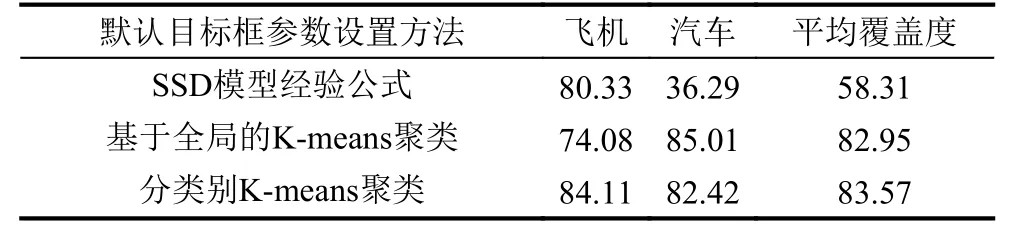
表3 3种默认目标框参数设置结果的平均覆盖度对比(%)

图5 分类别聚类方法与全局聚类方法的聚类结果分布对比图
本模块最终选用Conv4_3、Conv5_3、FC7、Conv6_2、Conv7_2、Conv8_2以及Conv9_2 七层特征用于后续目标预测.同时沿用SSD模型默认目标框在各特征层上的分布范围,将分类别聚类结果设置到各特征图上,分布结果见表4.
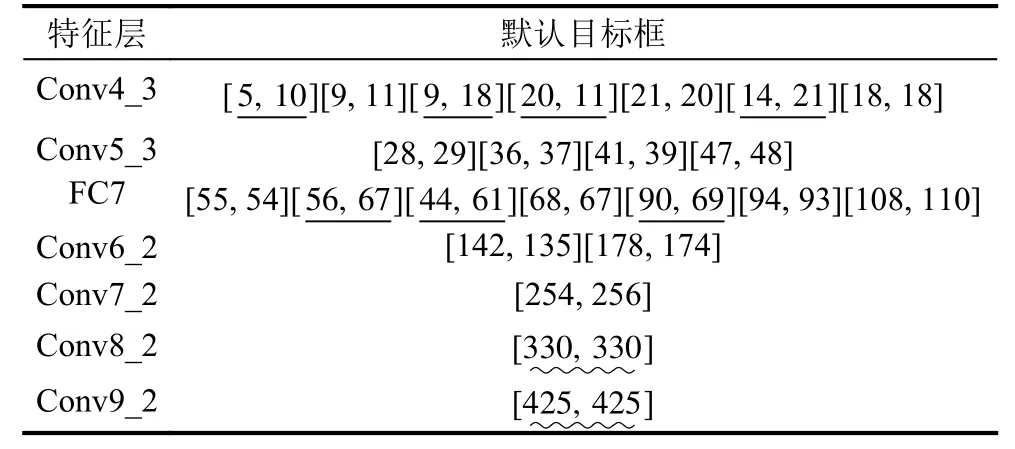
表4 各特征层默认目标框参数设置
2 实验结果与分析
2.1 模型训练
本文选择DOTA数据集中的飞机和小汽车两个目标类别组成数据集进行模型训练和验证.由于DOTA数据集原图较大,为了便于训练,将影像按200像素重叠裁剪为512×512,并将裁剪所得影像1/2用于训练,1/6用于验证,1/3用于测试.
实验配置的显卡为两块NVIDIA TITAN V,操作系统为Ubuntu 18.04,深度学习框架为Caffe.在模型训练阶段,设置初始学习率=0.001,batch size=16,decay=0.0005,momentum=0.9; 当训练迭代次数在40 000及60 000次时,设置学习率衰减率=0.1,以使模型更快收敛.
图6为模型训练过程中损失值与mAP随迭代次数的变化.模型收敛在损失值2.5左右,mAP达到86.67%.

图6 损失值及mAP随迭代次数变化
2.2 目标检测定量评价
在相同训练方式下,将本文训练好的模型与SSD模型、YOLOv3模型对比,各模型在DOTA遥感数据集的测试数据集与NWPU VHR-10遥感数据集[10]中的检测精度(mAP)与效率(FPS)如表5所示.其中,SSD*及YOLOv3*分别表示模型使用本文分类别聚类方法设置默认目标框参数.
从表5中可以看出,针对光学遥感图像中飞机和汽车典型目标检测,本文模型在DOTA数据集中的mAP较SSD及YOLOv3分别提升了26.78%和18.32%,在NWPU VHR-10数据集中的mAP较SSD及YOLOv3分别提升了20.42%和10.19%; 由于本文模型在设计时,通过引入多尺度特征融合以及设置默认目标框参数等措施,对尺寸小的汽车目标给予了更多的关注,使得本文模型相比SSD模型,对于汽车的检测精度提升更为显著,在DOTA数据集和NWPU VHR-10数据集中,分别提升了34.46%和32.63%.在使用本文提出的分类别聚类方法设置默认目标框参数后,SSD*及YOLOv3*对于两类典型目标的检测精度相比SSD和YOLOv3也均有一定提升,尤其是对于小尺寸目标占绝大多数的汽车目标的检测精度有了较大的提升,验证了分类别聚类方法设置默认目标框参数的有效性.在检测速度方面,由于默认目标框参数有所增加,导致模型运算量相应增加,本文模型的检测速度(FPS=16)较SSD模型(FPS=26)有所下降,但优于模型更为复杂的YOLOv3(FPS=13).

表5 各模型在DOTA、NWPU VHR-10数据集检测精度与速度对比
2.3 目标检测结果目视判别
图7为SSD模型和本文模型对DOTA数据集目标检测结果对比,蓝色框为汽车类目标的检测结果,绿色框为飞机类目标的检测结果.从图7中可以看出,SSD模型针对汽车与飞机目标进行检测时均存在一定程度的漏检,而本文模型对SSD模型的漏检情况有一定的改善,检测精度大大提升.

图7 检测结果对比
3 结论与展望
本文针对光学遥感图像中的飞机和汽车类典型目标检测提出一种改进的SSD模型:通过引入多尺度特征融合模块增强模型对目标特征的提取能力; 采用分类别聚类方法设置更符合目标样本尺寸分布特征的默认目标框参数,以优化网络对目标位置信息的提取能力.模型既对小尺寸、数量大、密集分布的汽车目标进行了重点关注,又很好兼顾了尺度分布宽的飞机目标,从而实现对这两类典型目标检测精度的提升.
通过在当前常用、公开的DOTA遥感图像数据集和NWPU VHR-10遥感数据集上的测试结果表明,相比SSD、YOLOv3等当前典型单阶段目标检测模型,本文提出的SSD改进模型在检测速度优于YOLOv3的情况下,对于飞机和汽车目标的检查精度有了很大提升,验证了上述改进措施的有效性.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
社会科学战线(2022年7期)2022-08-26
汽车实用技术(2022年4期)2022-03-07
China’s foreign Trade(2021年6期)2021-12-26
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中华奇石(2015年7期)2015-07-09
中华奇石(2015年5期)2015-07-09
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
祝你幸福·午后版(2008年4期)2008-03-22
