
基于SuperPoint的轻量级特征点及描述子提取网络①
2022-01-06 08:05:26李志强
计算机系统应用 2021年11期
李志强, 朱 明
(中国科学技术大学 信息科学技术学院, 合肥 230027)
图像特征点及描述子提取是计算机视觉方向研究核心问题之一, 提取图像特征点可以将大量的图像信息稀疏化, 从而更好地进行信息压缩, 而提取描述子则是对特征点周围信息进行描述, 生成特征向量, 用以和其他区域进行区分.图像特征点及描述子提取正被广泛应用于图像匹配[1], 3D重建[2]和SLAM[3]等诸多领域, 优秀的图像特征点及描述子提取算法可以对计算机视觉的发展发挥巨大的作用.
自2012年以来, 深度学习[4]以其提取特征更丰富、鲁棒性更强、精度更高和不需要手工设计特征等优点在图像分类[5]、目标检测[6]和图像分割[7]等领域有了飞速发展.近些年来, 深度学习与特征点及描述子提取的结合也是该领域研究的一大热点问题.
1 概述
目前的特征点及描述子提取算法主要有以下两类:完全手工设计特征和通过深度学习提取特征.
完全手工设计特征指的是特征点及描述子提取的算法完全通过手工设计获得, 图像信息获取完全依靠手工设计的算法获取, 如SIFT和SURF算法.Lowe[1]提出的SIFT算法是通过构建图像高斯金字塔进而构建DOG金字塔, 在DOG金字塔中寻找满足条件的极值点作为特征点.SIFT算法是通过统计特征点邻域梯度分布信息提取出特征点主方向, 将坐标轴旋转到主方向, 计算以特征点为中心16×16窗口内像素梯度的幅度和方向, 归一化后形成128维特征向量作为描述子.而Bay等人[8]针对SIFT算法计算量较大的缺点进行改进提出了SURF算法, 利用Hessian矩阵提取特征点, 减少了图像下采样的时间消耗.SURF算法通过统计特征点邻域内的Harr小波特征获取特征点主方向,在沿着特征点主方向的邻域内, 提取Harr特征形成64维特征向量作为描述子.完全手工设计的特征点和描述子提取算法是通过数学公式对图片进行进化和抽象来提取信息, 其鲁棒性和泛化性较大规模数据集驱动的深度学习具有天然劣势.
通过深度学习提取特征点或描述子的过程不依靠手工设计的算法获得, 是通过卷积神经网络训练和推理获得.由于深度学习鲁棒性和泛化性较好, 因此这种方式获得的特征点或描述子也较手工设计的方式泛化性能更好.Tian等人[9]提出的L2-Net利用卷积神经网络在欧几里得空间学习图像块描述子的特征.网络输入是图像块, 输出是128维向量, 网络以L2范数描述图像特征之间的距离, 用损失函数约束匹配上的图像块对的描述子距离尽可能近, 不匹配上的图像块对的描述子距离尽可能远.Mishchuk等人[10]提出的HardNet在L2-Net基础上改进了损失函数.HardNet参照SIFT算法, 使用损失函数最大化最近邻正样本和负样本之间的距离.Barroso-Laguna等人[11]提出的Key.Net则是将手工设计和卷积神经网络结合形成新的多尺度特征点检测网络.DeTone等人[12]的SuperPoint、Ono等人[13]的LF-Net和Dusmanu等人[14]的D2-Net等均是端到端学习特征, 输入一张图片, 输出特征点和描述子.其中SuperPoint提出一种自监督方式训练网络提取特征点和描述子.SuperPoint网络有两个分支分别进行特征点和描述子的提取, 共享相同的编码器.LF-Net由两部分组成: 全卷积网络生成特征点和通过可微采样器在获取特征点附近图像生图像块并将图像块输入描述子提取网络生成描述子.D2-Net与之前完全手工设计特征算法的先生成特征点再提取描述子过程和SuperPoint算法的特征点与描述子并行生成过程均不相同, D2-Net只生成描述子, 再根据当前点的描述子在最大响应通道中是否为局部最大值判断当前的是否为特征点.
大数据驱动的深度学习能够比完全手工设计的算法提取更深层次的图像特征, 鲁棒性和泛化能力更强.而端到端学习特征的网络减少了工程的复杂度也减少了误差的累计.在端到端提取特征点和描述子网络中SuperPoint是其中效果较好的网络, SuperPoint网络输出的特征点和描述子精度较高, 网络结构较其他网络更为简单, 因此本文选择在SuperPoint网络上进行进一步优化.SuperPoint网络虽然网络结构较为简单, 但是对于计算能力较低的设备, 如嵌入式设备, SuperPoint网络参数量和运算量仍较大, 不能实现实时运行, 因此本文在SuperPoint网络基础上进行优化, 构造效果接近SuperPoint网络, 但参数量和运算量更低的轻量型网络, 实现在计算能力较低的设备上实时运行的目标.
2 轻量级特征点及描述子提取网络实现
为了实现SuperPoint网络的轻量化, 本文首先更改SuperPoint网络的卷积方式、卷积层数和下采样方式, 将普通卷积改成深度可分离卷积[15]并且减少了网络层数, 然后对网络进行进一步剪枝, 进一步减少网络参数和运算量.
2.1 基于深度可分离卷积的SuperPoint网络
SuperPoint是端到端的特征点及描述子提取网络,网络结构是类似语义分割网络的编码器-解码器结构,输入一张完整的图片, 经过共享的编码器提取图像深层特征, 再分别经过特征点和描述子两个解码器, 分别输出特征点和描述子, 与完全手工设计算法的先检测特征点, 再计算描述子不同, 特征点和描述子并行生成.SuperPoint网络结构如表1所示, 表中每一行为一个卷积通道, 第一个数字是输入通道, 中间两个数字是卷积核大小, 最后一个数字是卷积核数目, “+池化”是指在卷积后进行最大池化操作.共享编码器结构类似与VGG网络[16]的卷积结构, 前6层每经过两次3×3卷积后紧跟着进行2×2最大池化, 共享编码器经过卷积池化等操作后, 进行了图片降维, 提取了深层特征, 减少了后续的计算量.经过特征点解码器和描述子解码器输出的特征图大小为原图的大小的1/8, 为了输出了原图一样大小的特征图, 特征点解码器输出的特征图进行8倍的子像素卷积, 描述子解码器输出特征图进行8倍上采样.

表1 SuperPoint网络结构
SuperPoint网络是使用自监督方式进行训练, 训练过程如下所示: (1)构建包含基础图形的虚拟图片, 如线、多边形和立方体等组成的图片.已知虚拟图片的角点, 训练编码器和特征点解码器提取特征点.(2)使用训练好的编码器和特征点解码器输出真实图片及其N个经过随机单应性变换图片的特征点, 将N个经过随机单应性变换图片的特征点通过逆向单应性变换还原到原图上, 与原图的特征点合并为增强的特征点数据集.(3)将真实图片及其经过单应性变换后的图片输入SuperPoint网络中, 根据特征点的位置和特征点的对应关系训练网络生成特征点及描述子.
本文使用的损失函数与SuperPoint网络的损失函数保持一致.损失函数由特征点损失和描述子损失两部分组成, 如式(1)所示:

其中,X,D分别为原图输入网络后输出的特征点特征图和描述子特征图,Y为原图特征点的的标签值,X',D'和Y'对应输入图片为原图经过单应性变换后的图片, 其余含义与X,D和Y相同,S由式(5)说明.Lp和Ld分别表示特征点损失和描述子损失, 超参数λ用来平衡特征点检测损失和描述子损失.Lp具体公式如下所示:

其中,Hc,Wc分别表示特征点特征图的高和宽.xhw,yhw分别表示X,Y在(h,w)处的值.lp具体公式如下所示:
其中,xhwk表示为xhw在第k个通道的值.lp使得xhw在标签值y对应的通道上尽可能大.

其中,dhw,dh′w′分别表示D,D′在 (h,w), (h′,w′)处的值.由于共享编码器经过8倍下采样, 因此输出的描述子特征图中的点对应输入图片中一个8×8像素点的图片单元.shwh′w′用来判断dhw对应输入图片单元的中心位置经过与原图一致的单应性变换后, 是否在d′h′w′对应输入图片单元的中心位置的邻域内,shwh′w′是用来判断dhw,d′h′w′在原图中对应位置是否相近.shwh′w′=1 表示在原图中对应位置相近, 为正向对应, 反之为反向对应.shwh′w′和ld具体公式如下所示:
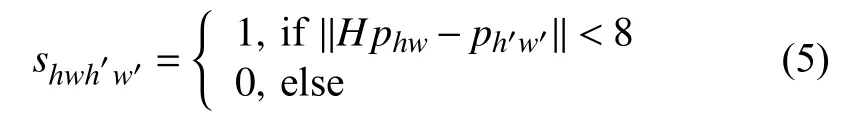
其中,phw,ph′w′分别表示dhw,d′h′w′对应的输入图片单元的位置中心.Hphw是对phw, 进行与原图相同的单应性变换.

其中, 超参数λd用来平衡描述子内部正向对应损失和负向对应损失值, 超参数mp为正向对应阈值,mn为负向对应阈值.
为了降低运算量和参数量, 本文将SuperPoint网络中除共享编码器第一层以外的其余卷积更换成深度可分离卷积.深度可分离卷积将传统的卷积方式分成逐层卷积和逐点卷积两部分, 如图1所示, 左侧为逐层卷积过程, 右侧为逐点卷积过程.假设输入特征图大小为H×W, 通道数是Cin, 逐层卷积是对每一个通道使用S×S大小的1个通道的卷积核进行卷积, 逐层卷积对通道内的特征信息进行处理.逐点卷积是使用1×1大小的卷积核进行传统方式卷积, 处理通道间的特征信息.假设输入特征图大小为H×W, 通道数是Cin, 卷积核大小是S×S, 卷积核数目是Cout, 对传统卷积来说参数量为Cin×S×S×Cout, 运算量为H×W×Cin×S×S×Cout, 对逐层卷积来说, 参数量为Cin×S×S×1, 为传统卷积的 1/Cout,运算量为H×W×Cin×S×S×1, 为传统卷积的 1/Cout.对逐点卷积来说, 参数量为Cin×1×1×Cout, 为传统卷积的1/S2, 运算量为H×W×Cin×1×1×Cout, 为传统卷积的 1/S2.因此深度可分离卷积的参数量和运算量均为传统卷积的1/Cout+1/S2.通常来说, 卷积核大小S为3, 卷积核数目Cout远远大于9, 因此深度可分离卷积的参数量和运算量大概是传统卷积的1/9.深度可分离卷积既处理了通道内的特征信息也处理了通道间的特征信息, 可以替代传统卷积进行, 减少了网络的参数量和运算量.

图1 深度可分离卷积的卷积和剪枝过程
为了进一步减少网络参数量和运算量, 本文将原始共享编码器的卷积层数和下采样方式进行更改.具体操作如下所示: (1)原始编码器的8层卷积改成6卷积; (2)将卷积+最大池化的下采样方式更改为步长为2卷积, 这样卷积的运算量变为原来的1/2, 并且省去了最大池化的计算; (3)为了弥补这些操作带来的特征信息损失, 本文将共享编码器的输出维度设置成256维.
2.2 网络剪枝
为了进一步对网络结构进行优化, 本文进一步对网络进行剪枝, 寻找更优的网络结构.Liu等人[17]提出的通道剪枝算法是一种效果较好的算法, 该算法对VGG参数量压缩20倍, 运算量压缩5倍, 而没有影响精度.但是算法是根据传统卷积设计的, 本文将其进行改进应用于深度可分离卷积中, 压缩本文的网络.
Liu等人的通道剪枝算法是通过批归一化中γ参数衡量通道的重要程度, 删除低于某个阈值的通道,进而删除与之关联的卷积核, 重新训练进行微调, 完成剪枝过程.批归一化的过程如式(7)所示, 其中xi是批归一化的输入的一个通道的特征,yi是批归一化的输出的一个通道的特征, μB和 σB分别为批特征的均值和方差, γ和 β 为批归一化中的参数.对于某个通道而言, 若其批归一化中的参数 γ较小, 其归一化输出值也较小, 可认为该通道不重要, 则可以删除生成这个通道的卷积核与下一层卷积核中对应的该通道的通道.具体衡量标准是将网络中所有的批归一化参数 γ进行升序排序, 根据需要将前面一定比例较小的 γ对应通道进行删除.中间层的卷积核剪枝应该包括两部分:(1)输入通道的删除导致卷积核中对应通道的删除;(2)输出通道的删除导致对应卷积核的删除.卷积核剪枝意味着寻找到一个较优的网络结构, 再进行训练进行微调提升其精度.

Liu等人的通道剪枝算法是删除所有批归一化中γ中较小的值对应的通道.在深度可分离卷积中, 逐层卷积后续操作也是批归一化, 但是逐层卷积的输入输出通道数应该相同, 因此深度可分离卷积中只能通过逐点卷积中的批归一化衡量通道重要程度.逐层卷积剪枝是通过输入通道的删除而进行剪枝, 具体流程参见算法1.

算法1.深度可分离网络剪枝算法images/BZ_317_1898_3031_1923_3064.png1) 将所有非逐层卷积后的批归一化参数 进行升序排序, 删除前a%对应的通道;

2) 如图1所示, 图中白色部分代表特征图和核卷积核被删除.输入通道的删除导致逐层卷积核中对应通道的删除以及逐点卷积核中对应通道的删除;3) 输出通道的删除导致逐点卷积中对应卷积核的删除;4) 对剪枝后的网络重新训练进行微调.
本文中a设置为20, 剪枝前共享编码器的输出通道为[64, 64, 128, 128, 256], 特征点解码器输出通道为[256, 65], 描述子解码器输出通道为[256, 256], 剪枝后共享编码器的输出通道变为[35, 47, 94, 86, 147], 特征点解码器输出通道变为[256, 65], 描述子解码器输出通道变为[256, 256].可以发现, 共享编码器相对于解码器结构更为复杂, 存在较多冗余信息, 被删除较多.
3 实验分析
本文实验过程中使用操作系统为Ubuntu 18.04, 深度学习框架为PyTorch 1.3.在测试FPS时使用的硬件环境为NVIDIA Jetson TX2开发板和AMD Ryzen 5 4600U CPU, 其他情况下硬件环境为Intel Core i7-7800X CPU+ NVIDIA GeForce GTX 1080 Ti GPU.本文实验过程中超参数设置与SuperPoint网络保持一致,损失函数中λ=0.000 1,λd=250, 正向对应阈值mp=1, 负向对应阈值mn=0.2.训练过程中批处理大小为32, 使用ADAM优化器,lr=0.001,β=(0.9, 0.999).
本文分析了改进后的网络和SuperPoint网络在参数量、运算量以及HPatches数据集[18]评估效果对比.
3.1 参数量、运算量和FPS对比
参数量和运算量对比如表2所示, SuperPoint+2.1代表使用2.1节中的优化方法, 即将传统卷积改成深度可分离卷积, 改变卷积层数和下采样方式, SuperPoint+2.1+2.2代表在2.1节优化方法的基础上使用2.2节的优化方法, 即进一步进行网络剪枝.浮点运算数代表运行网络所需要的浮点运算次数用来表示网络计算量.实验结果表明, 使用2.1的优化方式后, 参数量被压缩为原始网络的22%, 运算量被压缩为原始网络的8%.使用本文最终的优化方法(2.1+2.2节优化方式)后, 参数量被压缩为原始网络的15%, 运算量被压缩为原始网络的5%, 大大降低了网络参数量和运算量.

表2 参数量与运算量对比
FPS表示网络每秒钟处理图片帧数, 反应网络运行速度.FPS对比如图表3所示, 480×640_tx2表示实验硬件环境为嵌入式NVIDIA Jetson TX2开发板, 使用其配置GPU进行推理, 图片分辨率为480×640.240×320_cpu和480×640_cpu则表示实验硬件环境均为笔记本小新PRO13 2020, 使用其配置的CPU AMD Ryzen 5 4600U进行推理, 图片分辨率分别为240×320和480×640.可以看出本文优化后网络的FPS在3次对比中分别提升5.07, 7.19和7.68倍, 均值为6.65倍,FPS 提升较大.在 480×640_tx2和 240×320_cpu条件下, 本文网络近似实现了实时运行的目标.

表3 FPS对比
3.2 Hatches数据集评估效果对比
本文参照发布SuperPoint论文中的评估方式, 在Hatches数据集进行评估, Hatches数据集是2017年发布的特征点及描述子评估数据集.Hatches数据集内部包含属于116的696张照片, 其中57个场景属于大幅度的光照变化, 59个场景属于大幅度的视角变化.本文接下来分别对比SuperPoint和本文方法在特征点检测和特征点匹配效果的对比, 对比实现过程中网络使用的超参数设置均相同.
本文使用可重复率和定位误差来判断特征点检测效果.可重复率指是: 在视角或者光照变化的两张图片中, 同时出现的特征点对占总的特征点数的比率.定位误差指的是: 同时出现的特征点对的像素点距离的均值.本文中同时出现的特征点对指的是在相同视角下特征点间距离小于3个像素点, 视角不同的特征点对需对其中一张照片经过逆向变换, 从而到相同视角.SuperPoint和SuperPoint+2.1的对比显示: 经过将传统卷积改成深度可分离卷积、改变卷积层数和改变下采样方式后, 虽然使得网络模型变得更简单, 但是可重复率上表现更好, 增加了1.12%, 定位误差也仅仅增加0.11.SuperPoint+2.1和SuperPoint+2.1+2.2的对比显示: 进行网络剪枝后, 可重复率降低0.32%, 定位误差降低0.02, 网络剪枝带来的特征点检测效果损失可以忽略不记.表4证明, 本文的优化方法(SuperPoint+2.1+2.2)在大幅度降低运算量和参数量的情况下, 并没有导致特征点检测效果大幅度下降, 甚至可重复率表现上更优.

表4 特征点检测效果对比
要实现特征点匹配效果对比, 首先要通过特征点和描述子获得两幅输入图片的单应性变化矩阵.获取单应矩阵的过程如下所示: 首先图片1和图片1经过单应性变换产生的图片2分别送入网络中生成特征点和描述子, 描述子通过暴力方式进行最近邻匹配进行配对, 配对的特征点和描述子调用OpenCV中find-Homography()函数, 方法选择RANSAC算法, 生成两个图片之间的估计的单应性变换矩阵.表5中单应估计准确率指的是: 图片1经过真实的单应变换矩阵的图片边界角点和经过图2流程产生的估计的单应变换矩阵的图片边界角点的距离在一定的容忍距离差e下的数目占总的数量比例, 单应估计准确率可以反映图片间特征点匹配效果.表5中对比SuperPoint和SuperPoint+2.1, 可以发现: 本文使用的方法, 在e=1时下降0.03, 在e=3时下降0.02, 在e=5时下降0.02, 仅用轻微的降幅, 在可以接受范围内.SuperPoint+2.1和SuperPoint+2.1+2.2的对比表明: 剪枝算法几乎没有降低单应估计准确率, 仅在e=1时下降0.02.表5证明,本文使用的方法并没有导致的特征点匹配效果大幅降低, 匹配精度仍然较高.

表5 单应估计准确率对比
图2展示的为原始SuperPoint网络、使用2.1节优化后的网络和最终优化后的网络的在同一幅图片上特征点检测和匹配的效果图对比图, 红色点为检测到的特征点, 绿色线为匹配特征点.对比3幅图片可以发现3个网络检测到的特征点数和匹配的特征点数都比较相近, 说明本文最终优化后的网络在参数量压缩为原来的15%, 运算量运算量压缩为原来的5%和FPS提升6.64倍的同时, 特征点检测和匹配的效果几乎没有降低.

图2 特征点检测与特征点匹配效果图
4 结论与展望
本文针对SuperPoint网络的参数量和运算量较大,在嵌入式设备上不能实现实时运算的缺点, 对其网络结构进行精简和优化.首先, 本文将深度可分离卷积应用于SuperPoint网络中并且改变了网络的层数和下采样方式.然后本文将Liu的通道剪枝算法进行改进, 使其可以应用于深度可分离卷积中.实验结果表明, 最终优化后的网络网络参数量被压缩为原始网络的15%,运算量被压缩为原始网络的5%, 运行的FPS较原始网络提升6.64倍, 在计算资源有限的嵌入式和CPU上也能近似实现实时运行, 网络特征点检测和匹配效果较原始网络仅有轻微幅度下降.
下一步的研究工作在于将本文的网络与SLAM等算法进行结合, 用本文提出的特征点和描述子提取算法代替传统的特征点和描述子提取算法, 构建一个更鲁棒的SLAM算法.
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
中学生理科应试(2019年3期)2019-07-08 03:54:24
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
湖南教育·C版(2018年3期)2018-06-05 16:54:36
天津诗人(2017年2期)2017-03-16 03:09:39
电子设计工程(2017年20期)2017-02-10 03:39:29
福建中学数学(2016年7期)2016-12-03 07:10:28
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
