
基于集成学习的乳腺癌生存预测研究
2022-01-01 11:39张继婕覃庆洪刘雪萍王康权魏薇
广西科技大学学报 2022年1期
关键词:乳腺癌
张继婕 覃庆洪 刘雪萍 王康权 魏薇

摘 要:为对乳腺癌5年生存状态进行预测并分析其影响因素,首先,选取SEER数据库中2004—2010年乳腺癌相关数据,对选取的特征进行数据预处理;其次,在数据层面上,对数据进行SMOTE上采样以解决数据类别不平衡问题;在算法层面上,比较LightGBM、CatBoost和GBDT这3个模型在预测乳腺癌5年生存状态上的优劣;最后,根据重要性对乳腺癌5年生存状态的影响因素进行排序,并通过SHAP值对影响因素进行解释分析。本文构建的乳腺癌5年生存状态预测模型比单一模型具有更好的性能,其准确率、AUC、召回率、精确度和F1值分别为0.906 0、0.844 3、0.983 7、0.916 0和0.948 7;发现乳腺癌5年生存状态与肿瘤大小、检出的淋巴结总数、淋巴结转移数、雌激素受体、孕激素受体、年龄等因素有较大关系。本预测模型选择出的重要性特征与目前的临床结果保持一致,能为临床预后预测提供一定的技术支持。
关键词:SEER数据库;乳腺癌;集成学习;预后预测
中图分类号:TP181;R737.9 DOI:10.16375/j.cnki.cn45-1395/t.2022.01.015
0 引言
乳腺癌是女性中最常见的肿瘤之一,也是人类第二大致死癌症[1]。据2018年国际癌症研究机构调查的数据显示,全球女性乳腺癌的发病率为24.2%,位居女性恶性肿瘤首位,严重威胁着女性的身心健康[2]。
对癌症患者生存数据的分析一直备受国内外学者的广泛关注。目前多数研究都是通过单因素和多因素分析筛选出癌症的预后因素,再将预后因素放到Cox比例风险模型中进行预后分析。然而,Cox比例风险模型通常假设预测因子与生存结果呈线性相关,基于这样的假设,乳腺癌的预后模型有可能将复杂关系过度简化[3],且Cox比例风险模型多用于评价群体,不适合评价个体,在预后判断上起到的作用有限[4]。
近年来,机器学习算法广泛应用于人脸识别[5]、工业预测[6]等方面,越来越多的学者也开始将机器学习应用于医学领域。继Delen等[7]首次采用数据挖掘的方法建立乳腺癌患者5年生存预测模型后,其他学者[8-11]也相继采用不同的机器学习模型来研究乳腺癌患者的生存情况,但都存在一些弊端。与单一机器学习相比,集成学习有更好的性能和泛化能力[12]。有研究表明[4,13],相较于单一机器学习算法,采用集成模型预测不同癌症患者的存活率时,集成模型都展示出更好的效果。
Boosting方法是训练一系列弱分类器集成来得到一个强分类器的一种集成学习方法[14],既有集成学习的优势,又能灵活处理连续型和离散型数据[15]。鉴于集成学习在其他癌症预后上的优良表现,本文利用SEER数据库中乳腺癌患者相关数据,通过Boosting集成学习方法来预测乳腺癌患者5年生存状况并分析其影响因素,为临床预后预测提供支持。
1 方法
1.1 SMOTE算法
類别不平衡问题是指目标变量的类别分布不均,数据集中于某一类的样本量远高于其他类的现象[16]。本文采用SMOTE算法[17]来进行上采样,其基本思想是:对少数类样本进行分析后,人工合成新的少数类样本。具体算法流程为:
Step 1 计算少数类中每一个样本[a]到其他少数类样本的欧式距离,得到其[k]近邻;
Step 2 从少数类样本[a]的[k]近邻中随机选择若干个样本,假设选择的近邻为[b];
Step 3 对于每一个随机选出的近邻[b],分别与原样本按照式(1)构建新的样本[c]。
[c=a+rand(0, 1)×|a-b|]. (1)
1.2 Boosting算法
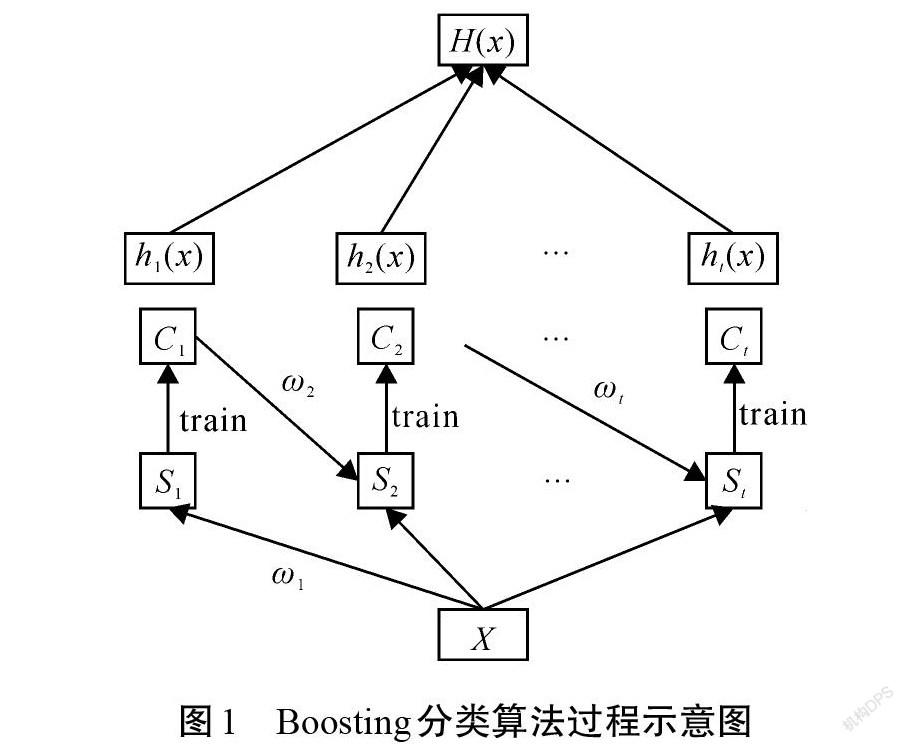
Boosting算法是一种通过训练产生多个简单分类器集成从而提升弱分类器为强分类器的过程[18],如图1所示。其具体实现步骤是[19]:
Step 1 给定一组训练样本[S],[S={(x1, y1)],[(x2, y2)][, …][, (xn, yn)}],初始化每一个样本的权重系数[ω(1)i=1/n, i=1,2,…,n];
Step 2 在每一次循环[t=1, 2, …, r],重复以下步骤:
1)使用弱分类器训练有权重的样本[{S,ω(t)}],得到分类器[ht]和权重训练误差[εt],依靠权重训练误差检查得到一个终止准则;
2)选择弱分类器权重[αt],更新权重系数[ωt];
Step 3 输出强分类器[H(x)=argmaxy∈{-1,1}t,ht(x)=yαt]。
图1中:[X]对应训练样本[S];[St(t=1, 2, …, r)]为[r]次迭代的样本分配;[Ct(t=1, 2, …, r)]为在一定权重条件下训练数据得到的分类法,可以根据[Ct]的错误率调整权重,每一个[Ct]对应每一个弱分类器[ht(x)];[ω(t)]为第[t]次循环初始化样本权重[ω(t)i(i=1, 2, …, n)]的集合;[ωt(t=1, 2, …, r)]为样本更新权重;[αt(t=1, 2, …, r)]为每一个基分类器权重。
为了预测乳腺癌患者5年生存状态,本文选取的单一模型为逻辑回归(Logistic Regression)、决策树(Decision Tree)和K近邻(Knn);集成模型则选择Boosting集成模型的代表性算法:Light Gradient Boosting Machine(LightBGM)、Categorical Boosting(CatBoost)和Gradient Boosting Decision Tree(GBDT)。
1.3 SHAP方法
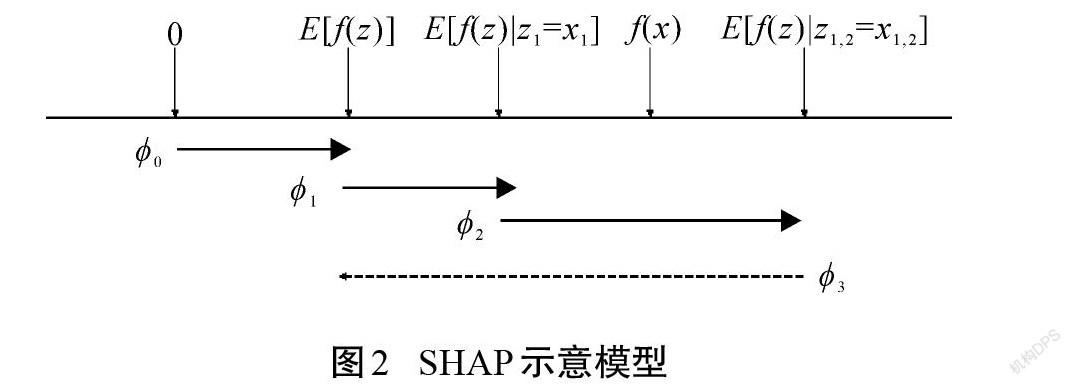
SHAP[20]是shapley additive explanation的缩写,是一种可以对复杂机器学习模型进行解释的方法。SHAP方法的核心是shapley值,即贡献值。如图2所示,假设集合中有3个特征[z1]、[z2]、[z3],[f(x)]表示某一样本的最终预测值。对于整个数据,可以用原始模型[f]预测后的预测值来计算平均值[E[f(z)]],记作[ϕ0]。[ϕ1]、[ϕ2]、[ϕ3]分别表示考虑特征[z1]、[z2]、[z3]的贡献值。贡献值可正可负,如图2中实线[ϕ1]、[ϕ2]表示正影响,虚线[ϕ3]表示负影响。
1.4 模型评价指标
通过5个二元分类性能指标来评价各模型的性能:准确率(Accuracy)、AUC、召回率(Recall)、精确度(Precision)以及F1值。5个指标的区间都是[[0, 1]],值越接近1表示分类效果越好。
2 数据来源和处理
2.1 数据来源
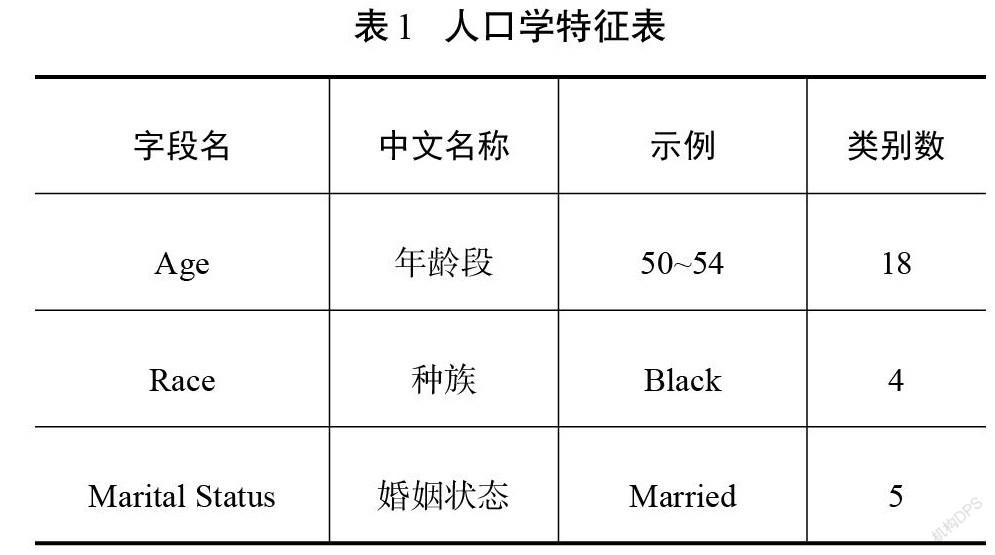
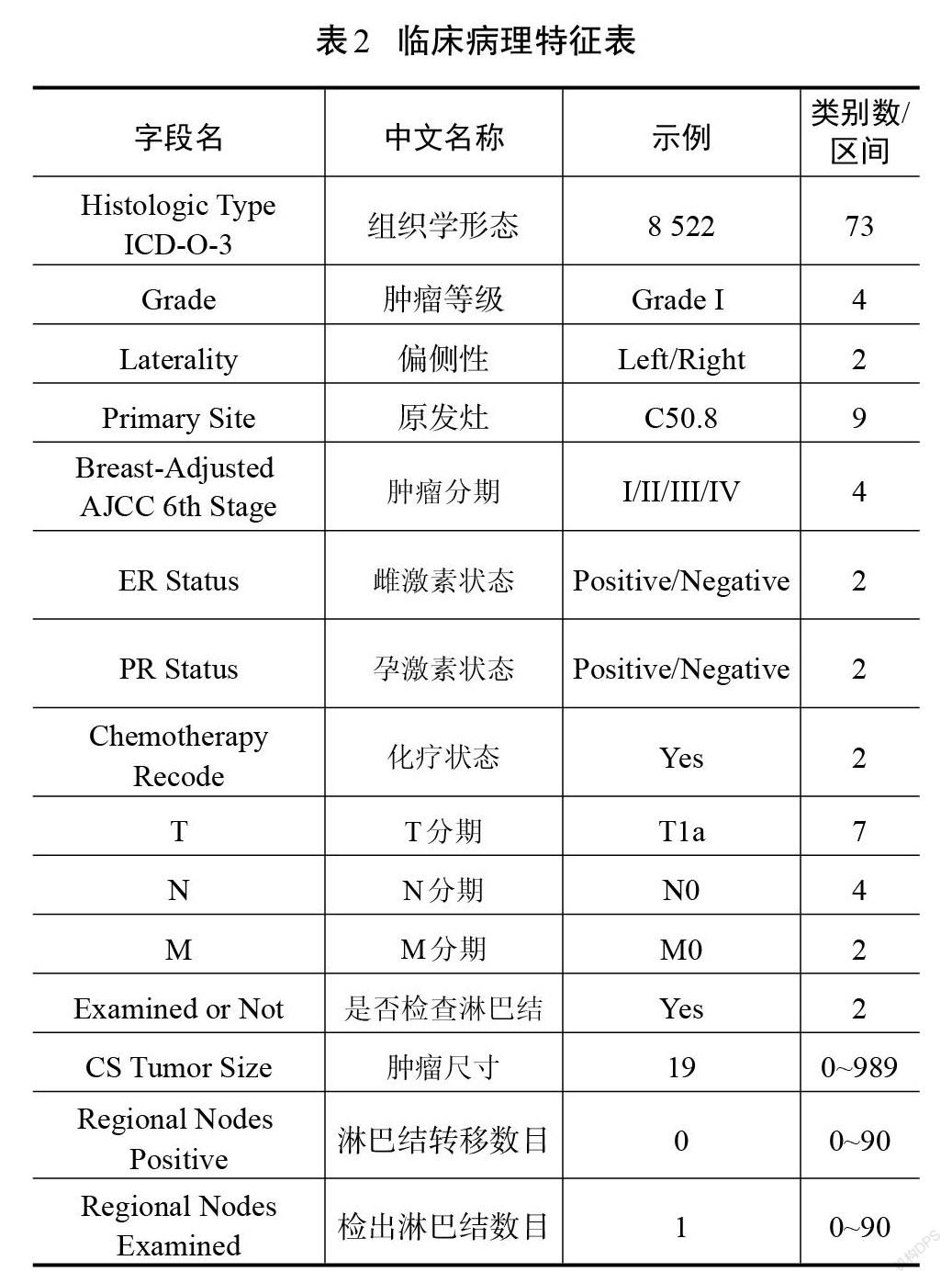
本研究数据来源于监测、流行病学及预后数据库(surveillance, epidemiology and end results, SEER)[21],通过SEER*Stat 8.3.9软件提取更新于2021年4月15日的数据。依据第7版AJCC临床指南、NCCN临床指南以及临床医师的指导,从原始数据中,筛选出性别、诊断年份、种族、年龄段、原发灶、组织学形态、偏侧性、肿瘤等级、肿瘤分期、雌激素状态、孕激素状态、肿瘤大小、化疗与否、肿瘤患者发病部位、婚姻状态、检出淋巴结数目、淋巴结转移数目、死亡原因、存活月数、T分期、N分期、M分期和生存状态一共23个字段作为原始数据。
2.2 队列选择
2.2.1 5年特异性生存
本研究以乳腺癌患者5年生存情况为预测目标,用存活月数构建分类变量。存活月数>60,记为1,认为该患者在首次确诊为乳腺癌后的5年后仍存活;存活月数≤60,记为0,认为该患者在首次确诊为乳腺癌后的5年内因为乳腺癌而死亡。
2.2.2 队列筛选
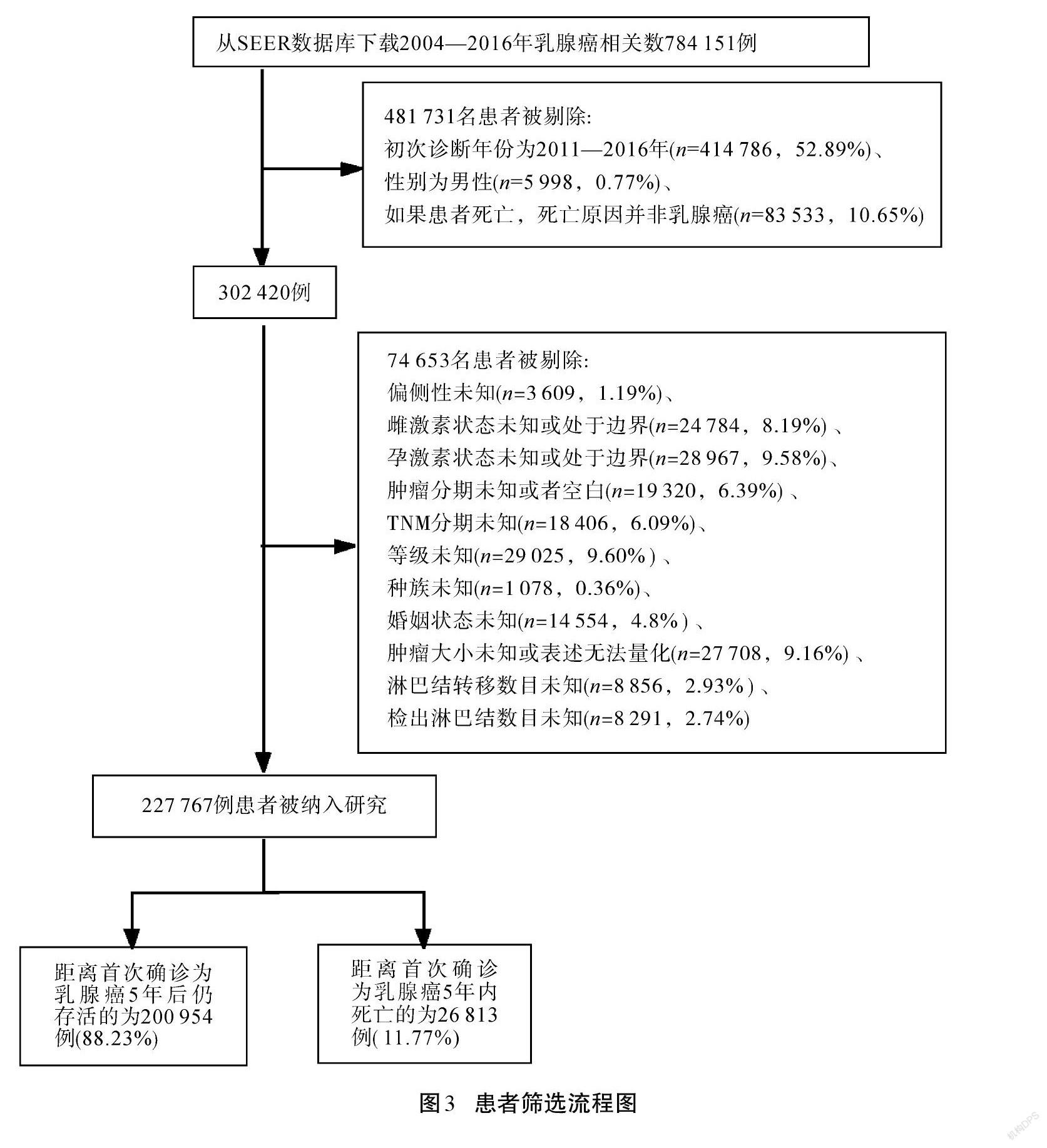
从2004—2016年共784 151条数据中按要求筛选,最终得到数据227 767条。具体要求如下:
1)初次诊断年份为2004—2010年。入选病例随访截止时间为2016年12月31日,为保证患者随访时间在5年以上,仅选择初次诊断年份为2004—2010年的患者。
2)性别为女性。
3)肿瘤患者发病部位为乳腺。
4)若患者死亡,则死亡原因为乳腺癌。
5)患者信息须准确。SEER数据库中存在缺失值,被记录为不知道(unknown)和空白(black())。除此之外,还存在信息表述不清的情况,例如肿瘤大小这一变量除被记录为不知道(unknown)和空白(black())数据之外,还存在两类数值:第一类是当数值在0~989 时,其值对应具体肿瘤大小,该数值以mm为单位;第二类是991~995之间的具有特殊意义的数值,该类与第一类中采用精确数值来表示肿瘤大小不同,采用区间来表示肿瘤大小,如995表示肿瘤大小[<]5 cm。考虑到无法为其进行精确量化,同时原始样本量大,该类信息表述不清的样本占比较小,故直接将这些记录删除。筛选过程如图3所示。
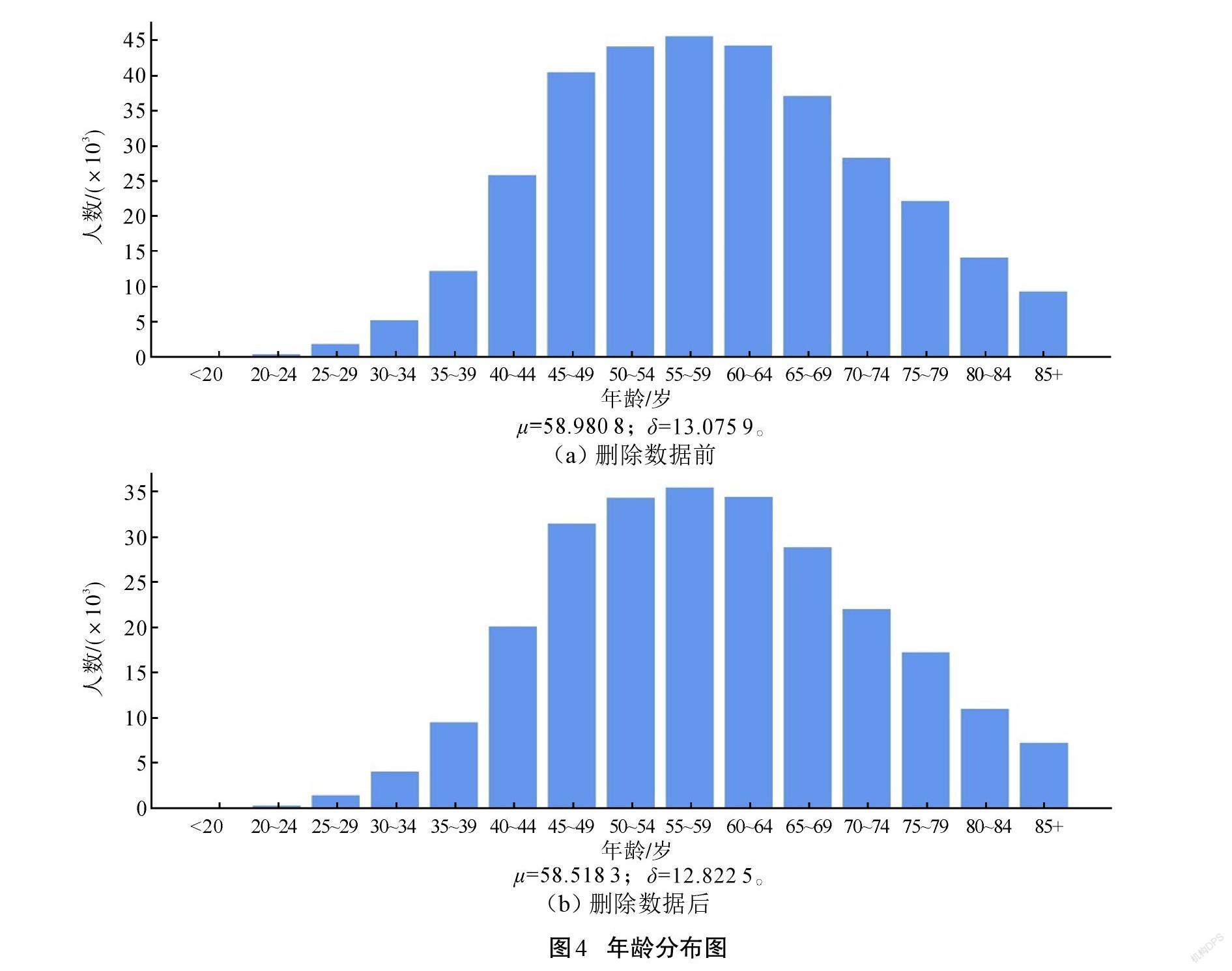
进一步分析,检查删除这些记录对于其他变量的影响。结果表明,删除这些记录对其他变量分布的影响不显著,认为删除这部分数据合理。如图4所示,删除数据前后,年齡这一变量的分布变化不显著。同时,将年龄段组值计算加权平均数代替平均值,计算标准差进行比较,发现差异较小。
2.2.3 特征选择
除直接从SEER数据库中获得变量外,淋巴结转移数目这一变量的值,大部分为0~90之间的整数,除此之外,还存在一个特殊的数值为98,表示该患者未检查淋巴结。考虑到在临床中不对淋巴结进行检查,可能的原因是该患者的临床症状不明显或病情较轻而无需对淋巴结进行检查,所以将该特殊数值98修改为0,并创建一个新的类别变量——examined or not,用来表示患者是否对淋巴结进行了检查。若淋巴结转移数目为0~90,表示检查了淋巴结,用Yes表示;淋巴结转移数目为98,则用No表示。
最终纳入模型的18个特征分为人口学特征(表1)和临床病理特征(表2)。
2.3 数据预处理
将数据按照7∶3的比例划分训练和测试数据,并进行以下预处理:
1)标准化
对数据进行zscore标准化来避免数据变量量纲不同、自身变异或者数值相差较大等问题造成的预测误差。
2)yeo-johnson变换
日常生活中的数据普遍满足高斯分布,因此,对原始数据做转型操作,转换方法设置为“yeo-johnson”变换[22]。
3 模型建立与结果
3.1 模型的建立
227 767条数据中,患者在被确诊为乳腺癌5年后仍存活的数据200 954条,死亡数据26 813条,其比例约7.45∶1,认为存在类别不平衡问题。因此,用SMOTE算法对训练数据进行处理。
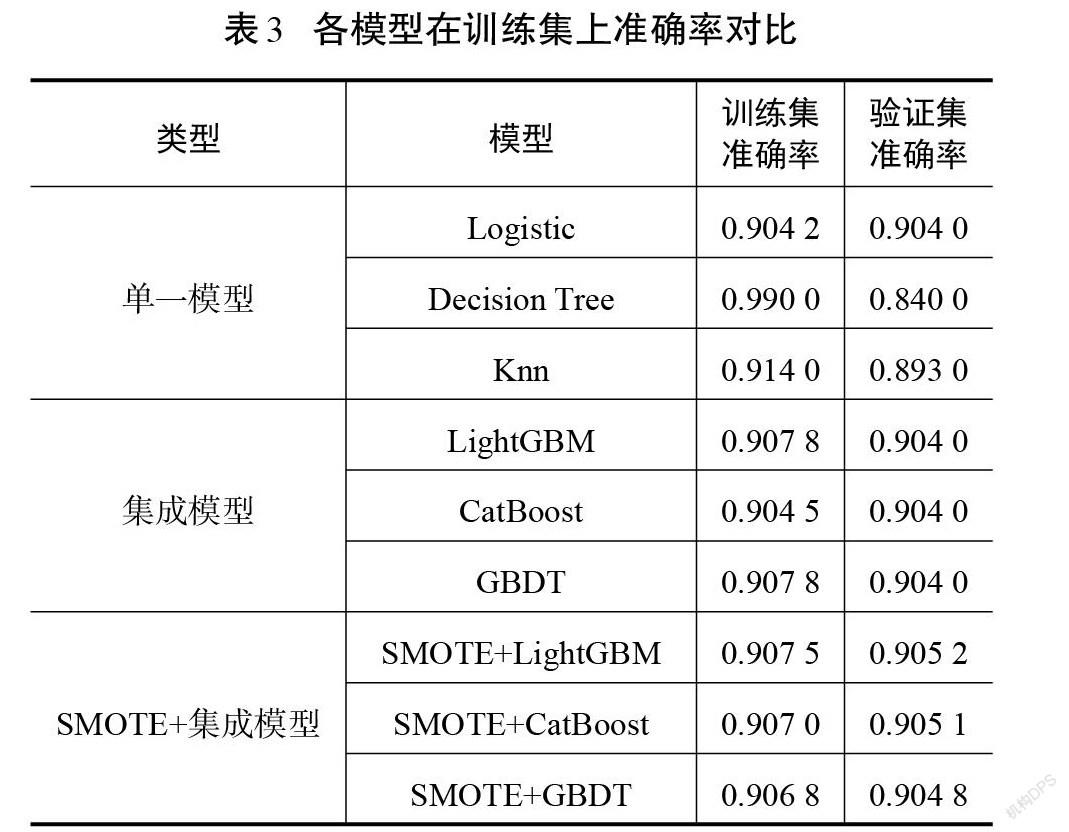
各模型在进行十折交叉验证训练后的准确率如表3所示。单一模型中决策树模型的训练准确率最高,达到0.990 0,但是验证集的准确率仅为0.840 0,相差较大,说明模型在训练集上出现了过拟合现象;集成模型中LightGBM和GBDT的训练精确度和验证精确度相同,数值分别为0.907 8和0.904 0;SMOTE方法与集成模型的组合中,LightGBM的准确率在测试集和验证集上均最高,分别为0.907 5和0.905 2。
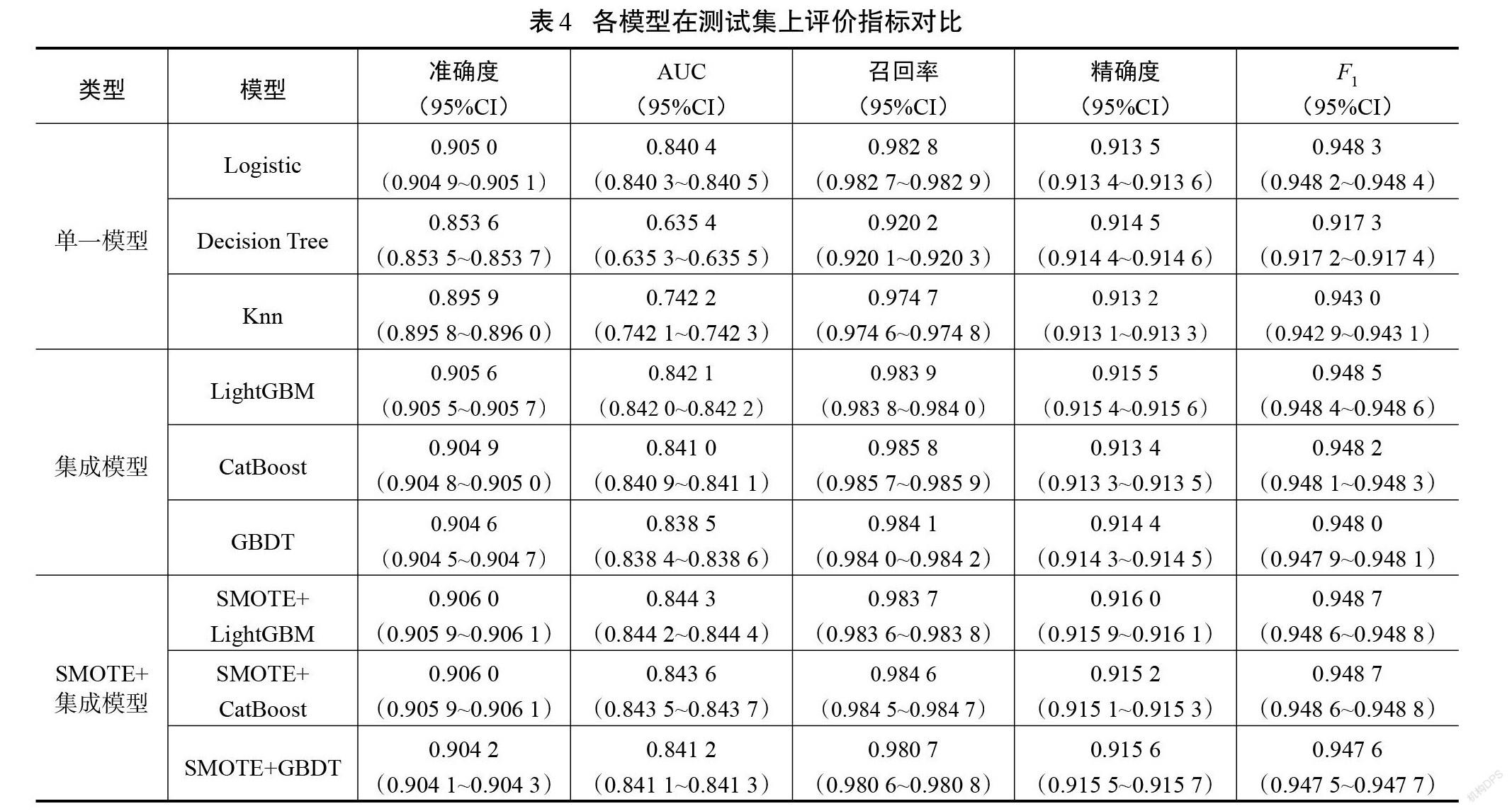
各模型在测试集上的表现如表4所示。SMOTE方法与LightGBM结合得到了最高的准确度、AUC、精确度和F1值,召回率仅比CatBoost模型低0.002 1,是所有模型中最优的。
从整体上来看,单一模型的效果没有集成模型好,SMOTE方法与集成学习的组合比仅使用集成模型在测试集上效果好。可见,SMOTE算法解决了数据类别不平衡的问题,使各个集成模型的分类能力得到了一定程度的提升。
3.2 特征重要性排序及解释
3.2.1 特征重要性排序
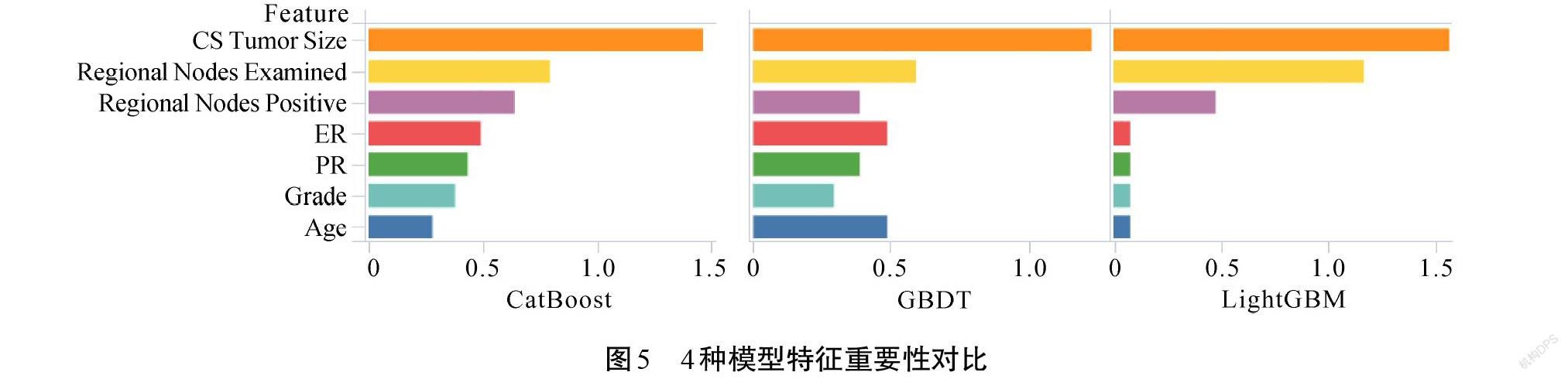
如表4所示,SMOTE与集成模型组合的预测效果较优,分别将LightGBM、CatBoost和GBDT共3个模型在做乳腺癌5年生存状态预测时的特征按重要性进行排序,发现最重要的10个特征中有7个特征是3个模型所共有的。如图5所示,共同特征为肿瘤大小、检出淋巴结数目、淋巴结转移数、孕激素受体、雌激素受体、组织学等级、年龄。同时发现,这些特征在3个模型上的重要性排序基本保持一致,最重要的特征是肿瘤大小,其次是检出淋巴结数目和淋巴结转移数。
3.2.2 SHAP特征解释
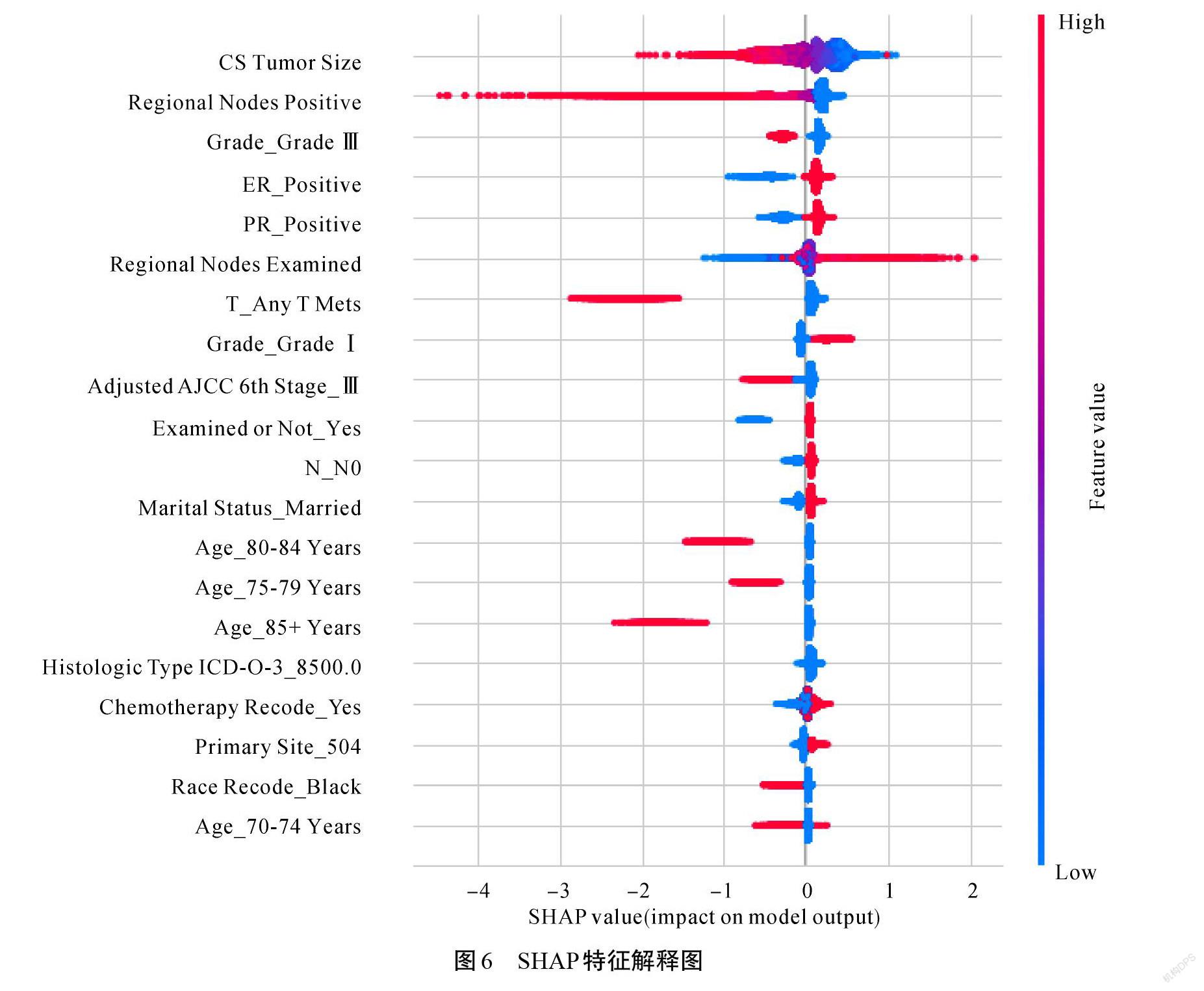
如图6所示,肿瘤大小增加,患者5年内死亡的风险也会升高。淋巴结转移数越多,患者5年内死亡的风险越高。随着检出淋巴结数目的增加,患者五年内死亡的风险降低。由此可见肿瘤大小和淋巴结转移对乳腺癌5年生存状态影响很大,转移淋巴结的切除能够降低死亡风险。同时发现组织学分级越高,患者在5年内死亡的风险也会越高。孕激素和雌激素受体成阴性时,患者5年内死亡的风险升高。年龄越大,患者5年内死亡的风险也越大。
4 讨论
在“数字医学”背景下,利用大数据辅助医生进行医学决策越来越受到重视。基于大量历史数据,依据数据特征采用合适的算法来预测特定人群、疾病的未来趋势是医疗大数据的特点之一。本研究利用SEER数据库中2004—2010年乳腺癌相关数据,通过Boosting集成学习算法的3种经典模型来预测乳腺癌5年生存状态并分析其影响因素,可为个性化医疗制定合理的治疗计划提供参考。
本研究的数据是连续变量和分类变量的混合体,其中大部分是多分类变量,这一类型的变量在建立模型时易出现维度灾难等问题。Boosting集成模型是一种基于树的模型,可基于类别变量的划分规则去创建树,能够有效解决维度灾难问题[19]。此外,该类模型可根据变量在树结构中的位置深度对变量的重要性进行排序,使模型具有较好的可解释性[13]。本文通过特征重要性排序发现,肿瘤大小、检出的淋巴结总数、淋巴结转移数、雌激素受体、孕激素受体、组织学等级等均是乳腺癌患者5年生存情况的重要影响因素。同时发现淋巴结转移数越多、肿瘤越大,患者5年内死亡的风险越高;随着检出的淋巴结总数的增加,预后越好;组织学等级越高,雌激素受体和孕激素受体为阴性时预后越差。这些结果均与已有研究[23-27]结论相吻合。
为了解决乳腺癌数据因较高特异性生存率而产生的类别不平衡问题,本研究采用SMOTE上采样方法来处理训练集,结果发现平衡后的数据建模效果更优。与此同时,冉霞[28]采用下采样的方法平衡数据后进行乳腺癌预后预测也取得较好结果。可见,面对类别不平衡问题,通过重采样技术能够在一定程度上提升模型的性能。但是,本研究中Boosting集成模型在采用SMOTE處理后,各个模型在测试集上的表现提升较小,可能的原因有:Boosting集成模型在处理数据时,主要通过拟合残差的方式逐步减小误差来找出树的最佳节点和分枝方法[3],该过程与数据类别是否平衡无关,因此,受类别不平衡因素的影响较小。未进行SMOTE上采样时,Boosting集成模型的AUC已较优,在平衡数据后仅有较小提升。
利用单一机器学习模型进行乳腺癌生存情况预测存在一定不足,虽然最优模型可获得较高AUC,但准确度较低[9-11]。相比之下,集成学习模型具有更好的性能。一方面,集成学习模型中最优模型的AUC与单一机器学习模型相当,但准确度和召回率等指标均达到0.9以上;另一方面,集成学习模型能更加灵活地处理乳腺癌生存率等复杂性数据。SEER数据库中的变量主要来自于先前的临床知识,大多与生存结果线性相关[3]。Logistic模型作为一种广义上的线性模型,能够较好地处理变量之间的线性关系,这也进一步说明本研究采用Logistic模型测试数据集时,其性能较好,仅略低于集成模型。然而,实际情况是:影响乳腺癌生存率的特征不仅存在线性相关关系,还可能存在非线性关系[29]。相较于Logistic模型,集成模型没有线性关系的限定,可能不会受到变量间非线性关系的影响,因而在本研究中展现出更好的性能,这也侧面反映了本研究结果存在一定的科学性与准确性。
5 结论
本文从SEER数据库提取乳腺癌相关数据,使用集成学习模型构建乳腺癌5年生存状态的预测模型。研究结果表明,肿瘤大小、检出淋巴结数目、淋巴结转移数、孕激素受体、雌激素受体等特征是乳腺癌5年生存状态最重要的特征;同时,从各模型的表现来看,LightGBM模型各项指标均较优,可作为一个工具辅助临床医生为乳腺癌患者做出更好的治疗决策。但本研究也存在未进行外部验证,缺少自身心理状况数据[30]等不足,因此,需进一步寻找外部数据进行更深入的研究。
参考文献
[1] 徐盼玲.基于SEER数据库的三阴型乳腺癌脑转移预后及影响因素研究[D].合肥:安徽医科大学,2019.
[2] 陈茂山,李芳芳,杨宏伟,等.基于SEER数据库分析142007例乳腺癌诊断时婚姻状态与预后的关系[J].重庆医科大学学报,2020,45(11):1567-1572.
[3] DU M,HAAG D G,LYNCH J W,et al.Comparison of the tree-based machine learning algorithms to Cox regression in predicting the survival of Oral and Pharyngeal cancers:analyses based on SEER database[J].Cancers,2020,12(10):1-17.
[4] 徐良辰,郭崇慧.基于集成学习的胃癌生存预测模型研究[J].数据分析与知识发现,2021,5(8):86-99.
[5] 安晓宁,王智文,张灿龙,等.基于隐马尔可夫模型的人脸特征标注和识别[J].广西科技大学学报,2020,31(2):118-125.
[6] 孫金芳,王智文,王康权,等.基于主成分降维及多层感知神经网络的辛烷值预测分析[J].广西科技大学学报,2021,32(3):67-73.
[7] DELEN D, WALKER G, KADAM A. Predicting breast cancer survivability:a comparison of three data mining methods[J]. Artificial Intelligence in Medicine,2005,34(2):113-127.
[8] BELLAACHIA A,GUVEN E.Predicting breast cancer survivability using data mining techniques[C]//Proceedings of the 6th SIAM International Conference on Data Mining,Bethesda,MD,USA,2006.
[9] 刘雅琴,王成,章鲁.基于神经网络的乳腺癌生存预测模型[J].中国生物医学工程学报,2009,28(2):221-225.
[10] 章鸣嬛,张璇,郭欣,等.基于SEER数据库利用机器学习方法分析乳腺癌的预后因素[J].北京生物医学工程,2019,38(5):486-491,497.
[11] 章鸣嬛,陈瑛,郭欣,等.利用Logistic回归和神经网络分析乳腺癌的预后因素[J].计算机与数字工程,2020,48(3):617-622.
[12] 周波.基于集成学习的不平衡数据分类的研究及应用[D].大连:大连理工大学,2014.
[13] JIANG J Z,PAN H,LI M B,et al.Predictive model for the 5-year survival status of osteosarcoma patients based on the SEER database and XGBoost algorithm[J].Scientific Reports,2021,11(1):1-9.
[14] WOLPERT D H. Stacked generalization[J].Neural Networks,1992,5(2):241-259.
[15] 陈雨桐.集成学习算法之随机森林与梯度提升决策树的分析比较[J].电脑知识与技术,2021,17(15):32-34.
[16] SUH S,LEE H,LUKOWICZ P,et al.CEGAN:classification enhancement generative adversarial networks for unraveling data imbalance problems[J]. Neural Networks,2021,133:69-86.
[17] 秦静,左长青,汪祖民,等.基于堆叠分类器的心电异常监测模型设计[J].计算机应用,2021,41(3):887-890.
[18] VALIANT L G.A theory of the learnable[J].Communications of the ACM,1984,27(11):1134-1142.
[19] 李想.Boosting分类算法的应用与研究[D].兰州:兰州交通大学,2012.
[20] LUNDBERG S M,LEE S I.A unified approach to interpreting model predictions[C]//Conference on Neural
Information Processing Systems,Long Beach,CA,USA,2017:4765-4774.
[21] 章鸣嬛,陈瑛,汪城,等.美国国立癌症研究所SEER数据库概述及应用[J].微型电脑应用,2015,31(12):26-28,32.
[22] YEO I K,JOHNSON R A. A new family of power transformations to improve normality or symmetry[J].Biometrika,2000,87(4):954-959.
[23] 宋效清,谢裕赛,邱雪杉.乳腺癌患者预后评估模型的构建[J].大连医科大学学报,2021,43(1):29-37.
[24] 王哲.阳性淋巴结比例预测乳腺癌患者预后的价值研究[D].天津:天津医科大学,2020.
[25] TAUSCH C,TAUCHER S,DUBSKY P,et al.Prognostic value of number of removed lymph nodes,number of involved lymph nodes,and lymph node ratio in 7502 breast cancer patients enrolled onto trials of the Austrian breast and colorectal cancer study group(ABCSG)[J].Annals of Surgical Oncology,2012,19(6):1808-1817.
[26] VINH-HUNG V,BURZYKOWSKI T,CSERNI G,et al.Functional form of the effect of the numbers of axillary nodes on survival in early breast cancer[J].International Journal of Oncology,2003,22(3):697-704.
[27] 张振伟,孙家和,张立功,等.乳腺癌骨转移患者危险因素及预后因素分析[J].临床外科杂志,2021,29(3):243-247.
[28] 冉霞.基于机器学习组合模型的乳腺癌生存预测[D].济南:山东大学,2020.
[29] 尹玢璨,辛世超,张晗,等.基于SEER数据库应用贝叶斯网络构建亚洲肿瘤患者预后模型——以非小细胞肺癌为例[J].数据分析与知识发现,2017(2):41-46.
[30] 唐铃丰,严萍,舒秀洁,等.基于SEER数据库构建转移性乳腺癌患者的生存预测模型[J].中国普外基础与临床杂志,2021,28(3):309-315.
Breast cancer survival prediction based
on ensemble learning
ZHANG Jijie1, QIN Qinghong2, LIU Xueping*3, WANG Kangquan1, WEI Wei1
(1.College of Science, Guangxi University of Science and Technology, Liuzhou 545006, China;
2.Affiliated Cancer Hospital, Guangxi Medical University, Nanning 530021, China;
3.Medical School, Guangxi University of Science and Technology, Liuzhou 545005, China)
Abstract: The research is conducted to predict the 5-year survival status of breast cancer and analyze the influence factors. Firstly, the breast cancer related data from 2004—2010 were selected from the SEER database, and the selected featured data were preprocessed. Secondly, in terms of data, SMOTE algorithm was used to oversample the data to solve the imbalance of data categories; in terms of algorithm, the advantagess and disadvantages of lightgbm, catboost and gbc in predicting the 5-year survival status of breast cancer were compared. Finally, the influencing factors of breast cancer 5-year survival status were analyzed by SHAP value after ranking. The 5-year survival prediction model of breast cancer constructed in this paper has better performance than a single model. The accuracy rate, AUC, recall rate, precision rate and F1-score are 0.906 0, 0.844 3, 0.983 7, 0.916 0 and 0.948 7 respectively; and it shows that the 5-year survival status of breast cancer is closely related to tumor size, examined lymph nodes, positive lymph nodes, ER status, PR status, and age. The model can provide prognosis prediction for the clinic with its excellent performance and the selected important features consistent with the current clinical results.
Key words: SEER database; breast cancer; ensemble learning; prognosis prediction
(責任编辑:黎 娅)
猜你喜欢
中国典型病例大全(2022年7期)2022-04-22
中国药学药品知识仓库(2022年1期)2022-03-23
恋爱婚姻家庭·养生版(2021年3期)2021-05-08
婚育与健康(2019年11期)2019-12-09
祝您健康(2018年5期)2018-05-16
祝您健康·文摘版(2018年1期)2018-05-14
女士(2017年11期)2017-12-12
健康博览(2017年8期)2017-12-05
妇女生活(2017年2期)2017-02-15
恋爱婚姻家庭·青春(2016年8期)2016-08-23
