
基于注意力掩码语言模型的隐式篇章关系识别
2022-01-01 13:10窦祖俊周国栋
中文信息学报 2022年10期
窦祖俊,洪 宇,李 晓,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
篇章分析是自然语言处理领域中一项重要的研究任务,其旨在根据语义信息、句法信息和相关领域知识等,判定相邻的文本片段(“论元”)之间的语义关系。隐式篇章关系识别对许多下游的自然语言处理任务具有广泛的应用价值,如事件抽取[1-2]、问答[3]、篇章关系分析[4-5]、机器翻译[6-7]等。
宾州篇章树库[8](Penn Discourse Treebank 2.0,PDTB 2.0)是篇章关系识别的重要语料库。将篇章关系分为四大类主关系: 对比关系(Comparison)、偶然性关系(Contingency)、扩展关系(Expansion)、时序关系(Temporal)。
隐式篇章关系分类是篇章分析的子任务,侧重在连接词缺失的情况下准确判别论元的语义关系。其难点在于,直接表征关系的显式连接词并未与论元共同出现,语义关系感知必须建立在论元语义的精确表示和理解之上。比如,例1中的两个论元(陈述句)具有隐式因果(Causality)关系(Causality是主关系“偶然性”的子类型关系),其潜在的连接词“because”被省略了。
例1:
[Arg1] Psyllium’s not a good crop.(译文: 车前草不是一个好的作物)
[Arg2] You get a rain at the wrong time and the crop is ruined.(译文: 在错误的时间下雨,庄稼会被毁了)
[篇章关系]Contingency.Causality
例2:
[Arg1]Manufacturers’backlogs of unfilled ordersrose0.5% in September to $497.34 billion(译文: 制造商未交付的订单九月份上涨0.5%,至4973.4亿美元)
[Arg2]Excluding these orders, backlogsdeclined0.3%.(译文: 除了这些订单,未交付的订货下降0.3%)
[篇章关系]Comparison
探寻论元的语义关系对于词级的关联线索有着极高的依赖作用。如例2的关联线索来自前置论元Arg1中的词项“rose”(“上升”),以及后置论元Arg1中的词项“declined”(“下降”),两者是隐含指向对比关系的关键信息。显然,感知这类词项的词义,并在论元的整体表示学习中强化它们的注意力权重,对于机器正确判定论元语义关系非常重要。然而,在实际建模过程中,难以绕过如下瓶颈:
(1) 单纯地建立关系词表并追求词义的表示学习违背了泛化原则,如实际测试样本中的对比关系可能源自“increase”(“增加”)和“decrease”(“减少”),其不同于例2的词级关系线索,且从未出现于人工建立的关系词表(甚至训练数据)。表示学习的偏差和信息遗漏,将负面地影响语义关系的有效感知。
(2) 现有基于神经网络的编码方法(如LSTM、Transformer和BERT)能够结合上下文信息建立词项的嵌入表示,提升泛化的感知能力。然而,其并非毫无前提。用于训练的数据资源是否充分,涵盖语言现象的总量高低和语用形式的多样与否,都将影响基于上下文的词义编码,进而影响基于词级关联线索的关系分类。如相比于例2,测试样本中的“increase”(“增加”)和“decrease”(“减少”)处于完全不同的上下文,小规模的训练数据集极大可能无法提供泛化学习所需的同质异构(同意但不同表述)上下文。
针对上述瓶颈,本文尝试借助预训练掩码语言模型[9]解决“上下文依赖”的词义表示学习,其不仅在大规模语言学资源中学习了大量语义和语用特征,且在自学习过程中“领教了”各类上下文的同质异构现象,具有较高的泛化感知能力。特别地,本文采用掩码重构的生成模型,专门针对篇章分析数据(PDTB中的样本)进行局部词项的随机遮蔽和“上下文依赖”的表示学习,将词项的缺失(遮蔽)视作提升论元编码表示灵活性的契机,其模拟了数据增强的基础原理。在此基础上,本文将交互注意力机制引入掩码语言模型,在进行选择词项遮蔽的过程中,增加关键词级关联线索的注意力加权。本文将上述方法称为交互注意力掩码语言模型(Interactive-Attention-based Mask Language Model, IAMLM)。在此基础上,本文将IAMLM与RoBERTa[10]分类模型结合,集成到多任务学习框架中,其中IAMLM侧重论元的泛化表示、数据增强和关联线索注意力加权,后者则作为论元整体语义表示和关系判定的模块。
本文在PDTD 2.0标准数据集上对上述方法进行测试。实验结果显示,本文方法取得了显著的性能提升,消融实验证明,关联线索交互注意力产生的性能优化明显,其与掩码语言模型形成了较好的协作关系。
1 相关工作
在Penn Discourse Treebank 2.0(PDTB 2.0)发布后,产生了大量与浅层篇章结构分析相关的工作。隐式篇章关系分类的性能目前普遍较低,许多研究者对其进行深入研究以提高该任务的性能。以往的研究主要集中在线性分类器上进行特征工程,对隐式篇章关系进行分类。Pitler[11]等的研究集中在文本跨度层面和句子层面的语言特征生成和选择。Lin[12]等在Pitler[11]等的基础上提出使用句法结构特征和依存特征构建分类器。
近年来,为了从样本中学习更丰富的语义信息,用来增强编码表示,研究者们做了很多工作。如Zhang[13]等提出了更灵活的深层神经架构,使用了浅层卷积神经网络对隐式篇章关系进行分类。Chen[14]等采用门控机制来捕获论元词对之间的语义交互,并使用池化层来聚合这些交互表示,以选择信息最丰富的交互。Qin[15]等更深入地挖掘现有的数据,通过预测隐含连接词用于多任务框架中,得到额外的显著特征。最近,注意力机制[16]被广泛应用于自然语言处理任务中,这是一种模仿人类选择性关注部分信息的阅读习惯的方法。Guo[17]等对论元表示进行交互注意力计算,以从论元对中挖掘出最相关的词对,并将其整合到双向长短期记忆网络[18]产生的论元表示中。同时,提出了张量神经网络(Neural Tensor Network)来探索更重要的成对模式,以充分识别篇章关系。Bai和Zhao[19]使用不同粒度的词向量对论元进行表示,并使用卷积及注意力机制获得最终表示。Nguyen[20]等在Bai和Zhao[19]的基础上,将关系表示和连接词表示映射到同一空间中来实现知识迁移,缓解了隐式篇章关系语料稀疏问题。Varia[21]等引入词对卷积,以捕获显示或隐式关系分类的论元之间的相互作用。He[22]等使用多级编码器挖掘论元关系实例的潜在几何结构信息,进一步利用论元的语义特征来辅助篇章理解。Ruan[23]等提出堆叠式注意力机制,使用双通道网络开发了一个传播性注意力学习模型,同时利用自注意力机制和交互注意力机制来增强编码,产生更易识别的表示。Liu[24]等研究表明,不同层次的表征学习对隐式篇章关系分类都很重要,于是使用融合了多头注意力和门控机制的模块来深入理解文本,模型得到显著的性能提升。
2 基于交互注意力掩码语言模型
本节首先介绍模型的总体结构,随后详细描述模型各个模块的内部结构以及模块之间的联系。
2.1 总体结构
图1示了模型的整体框架。本文提出的基于交互注意力掩码语言模型主要分为四个部分: ①首先,混合表示层将每个单词映射到字符和单词级的嵌入表示,并在编码层通过RoBERTa编码Arg1和Arg2,增强词嵌入的表示能力。②在论元表示上进行交互注意力权重计算,以得到一个注意力矩阵,代表Arg1每个词对应Arg2每个词的权重;然后,将其用于计算Arg2所有词对应Arg1每个词的权重之和,根据权重之和,选择Arg1中权重前30%大的词进行遮蔽;同理,选择Arg2中权重前30%大的词进行遮蔽。③将被遮蔽关键词的Arg1和Arg2拼接送入和编码层同一个RoBERTa编码,用于进行预测关键词任务,并将该模型集成到一个多任务学习框架中,借助于遮蔽关键词来将语义空间倾向对应的隐式篇章关系。④将最先计算的注意力表示输入全连接层进行非线性变换,然后送入softmax层得到关系分类结果。
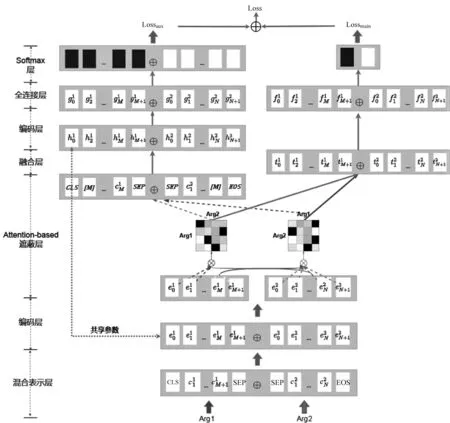
图1 基于交互注意力掩码语言模型框架图
2.2 编码层
对于论元中的每个单词,本文先通过RoBERTa的Byte-level Byte-Pair Encoding对其进行分词,并将分词结果映射到向量表示,如(1)、式(2)所示。
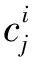
其中,SEP是一种特殊的标记词嵌入,用来表示句子连接的边界。
在此基础上,本文将Arg1和Arg2拼接而成的词向量表示作为RoBERTa网络的输入,以得到论元对的上下文表示[e0,e1,…,eM+N+2,eM+N+3]。
接着,该模型将论元对的上下文表示分割成两个论元,如(4)、式(5)所示。
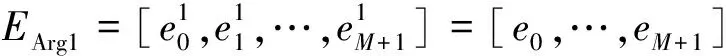
(4)
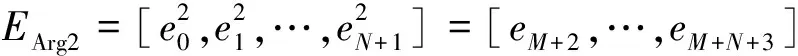
(5)
2.3 多头交互注意力
为了有效地捕捉论元间特征与特征之间复杂多样的关系,本文将使用多头交互注意力机制[14]。

多头注意力允许模型共同关注来自论元不同位置的不同表示。复杂的篇章关系通常不容易从论元对的表面特征中导出,因此,本文将定义一个多头注意力来表示两个论元之间的交互注意力,如(7)、式(8)所示。
multi-head(Q,K,V)=concat(h1,…,hh)Wo
(7)

(8)

本文将分别以Q设为EArg2,K、V设为EArg1,生成交互注意力表示t1,如(9)~式(11)所示。
同理,以Q设为EArg1,K、V设为EArg2,生成交互注意力表示t2。
一方面,该模型将t1和t2对应的交互注意力矩阵送入Attention-based遮蔽层中,用于选择论元中权重高的词语进行遮蔽,将被遮蔽关键词的论元对重新通过同一个编码层,并进行预测关键词任务。另一方面,该模型将t1和t2送入融合层中更新论元表示,用于隐式篇章关系分类任务。
2.4 融合和预测
编码层得到的论元对经过第2.3节提到的交互注意力模型,本文得到了论元对的交互注意力表示t1和t2,这种注意力机制使模型能够关注两个论元相关联的特征,这对于识别篇章关系至关重要。然后,该模型连接t1和t2,以获得论元对表示Tpair=[t1,t2]。此时,论元对融合交互信息,将更新后的论元对表示进行隐式篇章关系的预测,如图1右侧部分所示。
最后,本文将论元对向量Tpair进行层归一化,并使用全连接层对其进行降维,将降维后的特征向量送入softmax层,该层为分类任务,输出论元对类别标签的概率。本文选择softmax层的输出和真实类别标签之间的交叉熵损失[25]作为该模型主任务的损失(Lossmain)。
2.5 交互注意力掩码语言模型
第2.4节提出的模型本身可以实现隐式篇章关系识别。然而,与深度学习中的许多模型相似,该任务的一个大问题是缺乏标记数据,且类别分布十分不平衡。因此,本文提出一个基于交互注意力掩码语言模型,通过将上述模型集成到一个多任务学习框架中,借助于大量的未标记的数据来进行掩码语言模型的自监督任务,将预训练的语义空间倾向该实验的任务数据。图1左侧显示了论元对在得到交互注意力表示后,基于交互注意力进行掩码、预测词项任务的网络传输流程。
为了在屏蔽关键词的情况下仍希望模型能很好地学习上下文的表示,本文使用第2.3节得到的两个交互注意力表示t1、t2,得到其对应的交互注意力矩阵,分别代表Arg1中每个词、Arg2中每个词,以及Arg2中每个词对Arg1中每个词的影响权重大小,将其送入Attention-based遮蔽层中用于选择论元词遮蔽。以t1为例,本文将计算Arg2中所有词对Arg1中每个词的权重之和,得到Arg1中每个词对Arg2影响的权重向量,计算过程如图2所示。根据得到的权重向量,将Arg1中的前30%大的权重对应的词进行遮蔽,即,Arg1 中选出的词用[mask]进行替换。同理,使用得到的权重向量,对Arg2中的前30%大的权重对应的词进行遮蔽。
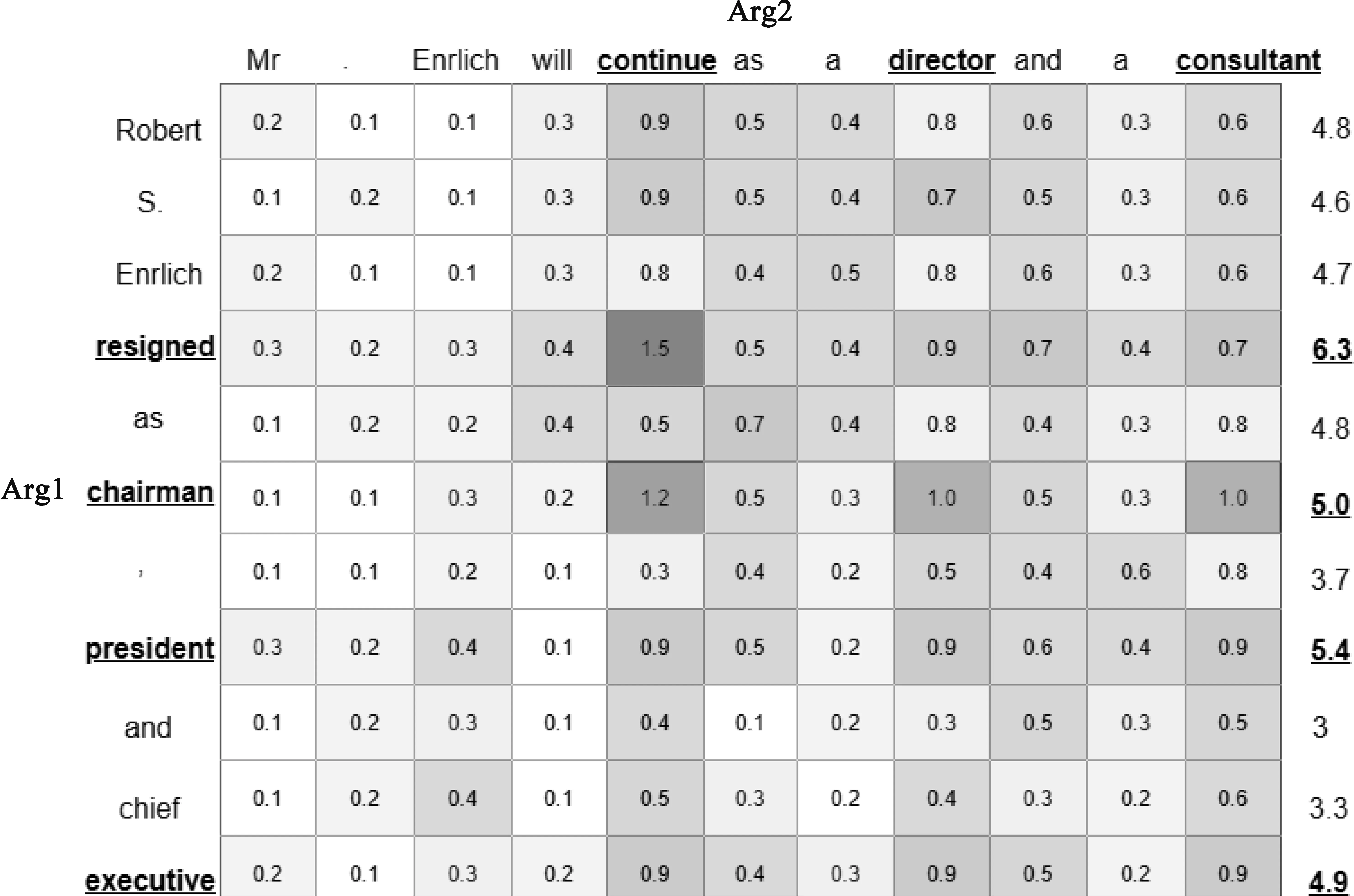
图2 基于交互注意力选择关键词示意图(V为Arg1为例)
最后,本文将遮蔽关键词后的Arg1、Arg2拼接,送入和编码层同一个RoBERTa中,得到论元对的上下文表示,并使用全连接层进行升维,将升维后的特征向量送入softmax层进行单词预测。这里,该模型选择softmax层的输出和原始单词之间的交叉熵损失作为辅助任务的损失(Lossaux)。
关于从辅助任务到主任务的知识共享策略,如图1最顶端连接操作所示,本文将联合右侧主任务和左侧辅助任务,给主任务和辅助任务赋予不同的权重,如式(12)所示。
其中,α∈(0,1]是一个权重参数。显然,α值越低意味着辅助任务的重要性越低。
3 实验
本节首先介绍了隐式篇章关系的实验数据以及常用的评价指标,随后描述了多组实验设置和参数设置,最后对实验结果等方面进行分析。
3.1 实验数据
本文在PDTB 2.0数据集上进行了实验。为了进行比较,本文采用Sec 02-20作为训练集,Sec 00-01作为开发集,Sec 21-22作为测试集。其中,具体四大篇章关系Comparison(Comp.)、Expansion(Expa.)、Contingency(Cont.)和Temporal(Temp.)的语料分布情况如表1所示。
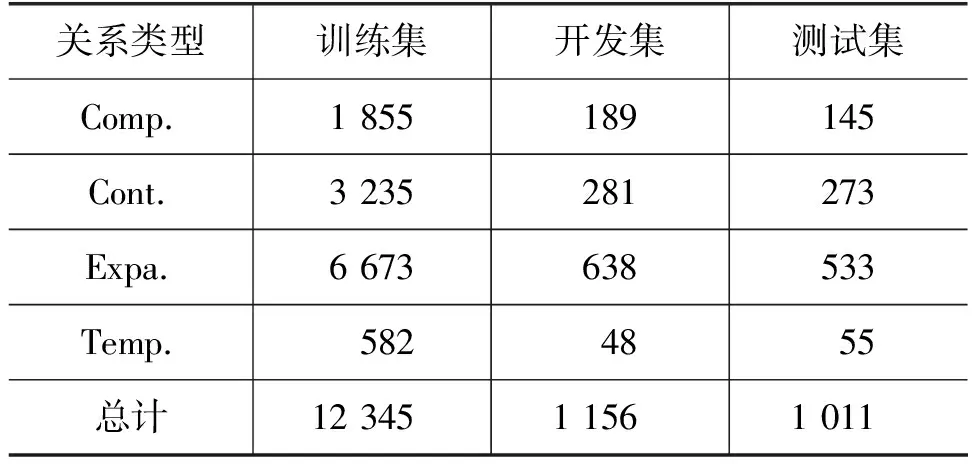
表1 PDTB隐式篇章关系数据分布
由表1可知,各个关系类别上的数据分布不均衡,其中,时序关系(Temporal)的样本数量远小于其他任一种关系。因此,用所有数据直接训练模型并进行测试的方法难以判定实例为样本数量小的类别。由于在每个关系类别上,其训练集正负例分布不均衡(正例个数远小于负例)。本文除了在四分类模型上用宏平均F1值(Macro-averagedF1)评估该任务的模型,还针对每个关系类别,对负例随机抽样来构造平衡数据,并用其训练一个二分类器,使用F1值(F1-score)作为性能评价标准。
3.2 实验设置
本节针对所提模型基于交互注意力掩码语言模型设计了消融实验,来展示所提模型不同部分对分类性能的影响。在实验过程中,所有对比模型的参数设置与本文所提的模型保持一致。
(1)RoBERTa-base(基准模型):将通过RoBERTa的Byte-level Byte-Pair Encoding分词后的Arg1和Arg2,拼接后作为RoBERTa的输入,以得到论元对的上下文表示。最后,将其输入全连接层进行关系分类。
(2)交互注意力机制(Interactive-Attention):通过RoBERTa得到论元对的上下文表示,使用式(7)计算出Arg1和Arg2的交互注意力表示,将其拼接并作为全连接层的输入来进行关系分类。
(3)随机掩码语言模型(Random-based Mask Language Model,RMLM): 通过RoBERTa得到论元对的上下文表示,将其直接作为全连接层的输入来进行关系分类。同时,随机遮蔽论元30%的词,将被遮蔽词的论元对作为RoBERTa的输入,得到论元对的上下文表示后,进行预测词任务,将其作为辅助任务。
(4)RMLM+Interactive-Attention:通过RoBERTa得到论元对的上下文表示,使用式(7)计算出Arg1和Arg2的交互注意力表示,将其拼接并作为全连接层的输入来进行关系分类。同时,随机遮蔽论元30%的词,将被遮蔽词的论元对作为RoBERTa的输入,得到论元对的上下文表示后,进行预测词任务,将其作为辅助任务。
(5) 交互注意力掩码语言模型(IAMLM): 通过RoBERTa得到论元对的上下文表示,使用式(7)计算出Arg1和Arg2的交互注意力表示,将其拼接并作为全连接层的输入来进行关系分类。同时,使用Arg1和Arg2得到的交互注意力矩阵,选出权重前30%大的关键词进行遮蔽(见2.5节),将被遮蔽词的论元对作为RoBERTa的输入,得到论元对的上下文表示后,进行预测词任务,将其作为辅助任务。
3.3 参数设置
本文使用RoBERTa-base作为该模型的上下文表示层,并设定RoBERTa的每个隐藏层维度d为768。论元的长度统一设置为126(M=N=126),论元对表示的长度设置为256(252加4个分隔符)。在训练过程中,批(Batch size)大小为8,交互注意力的权重矩阵维度dmodel为128。辅助任务损失权重α设置0.5。本文使用包含一个隐藏层的全连接层,其隐藏层神经元个数为256,为了避免过拟合,该模型在每层之后使用了dropout,其比率设置为0.2。本文使用交叉熵损失作为模型的损失函数,并使用Adam[26]优化器对参数进行更新,其学习率设置为0.000 05。
3.4 实验结果和分析
本文针对所提模型进行消融实验,检验了四种主要关系类型的二元分类性能,包括Comparison(COM)、Contingency(CON)、Expansion(EXP)和Temporal(TEM)。在PDTB四大类关系上,基准模型RoBERTa-base、Interactive-Attention、RMLM、RMLM+Interactive-Attention和IAMLM的分类性能如表2所示。实验结果表明,相较于基准模型RoBERTa-base,Interactive-Attention在F1值上有所提升,其原因在于多头交互注意力机制能够捕捉论元对之间的交互信息,并使用这一信息对论元表示进行增强,可获得含有交互信息的论元特征。同时,RMLM相较于基准模型在四大类关系上的分类性能均有所提升,其原因在于掩码语言模型能够在理解上下文的基础上“重构掩码区域语义表示”,用遮蔽词项来提升论元编码表示的灵活性。但是由于随机遮蔽的词项之间存在非关键信息,训练时容易包含噪声,会学到部分与任务相关性不大的上下文表示。而IAMLM可以针对论元对之间关联性强的关键词来进行遮蔽、掩码重构,从而形成更有针对性的数据增强。此外,IAMLM在四大类关系上的分类性能均优于基准模型,尤其在Contingency和Temporal关系上,其F1值相对于基准系统分别提高了 6.46%和6.56%。

表2 消融实验结果 (单位: %)
本文与其他前沿工作在四分类和四种主要关系的二分类任务上进行了对比。宏平均F1值(Macro-averagedF1)和准确率(Accuracy)是四分类的主要性能评价指标,F1值(F1-score)用于评估对于二分类每个类别的性能,具体性能如表3所示。
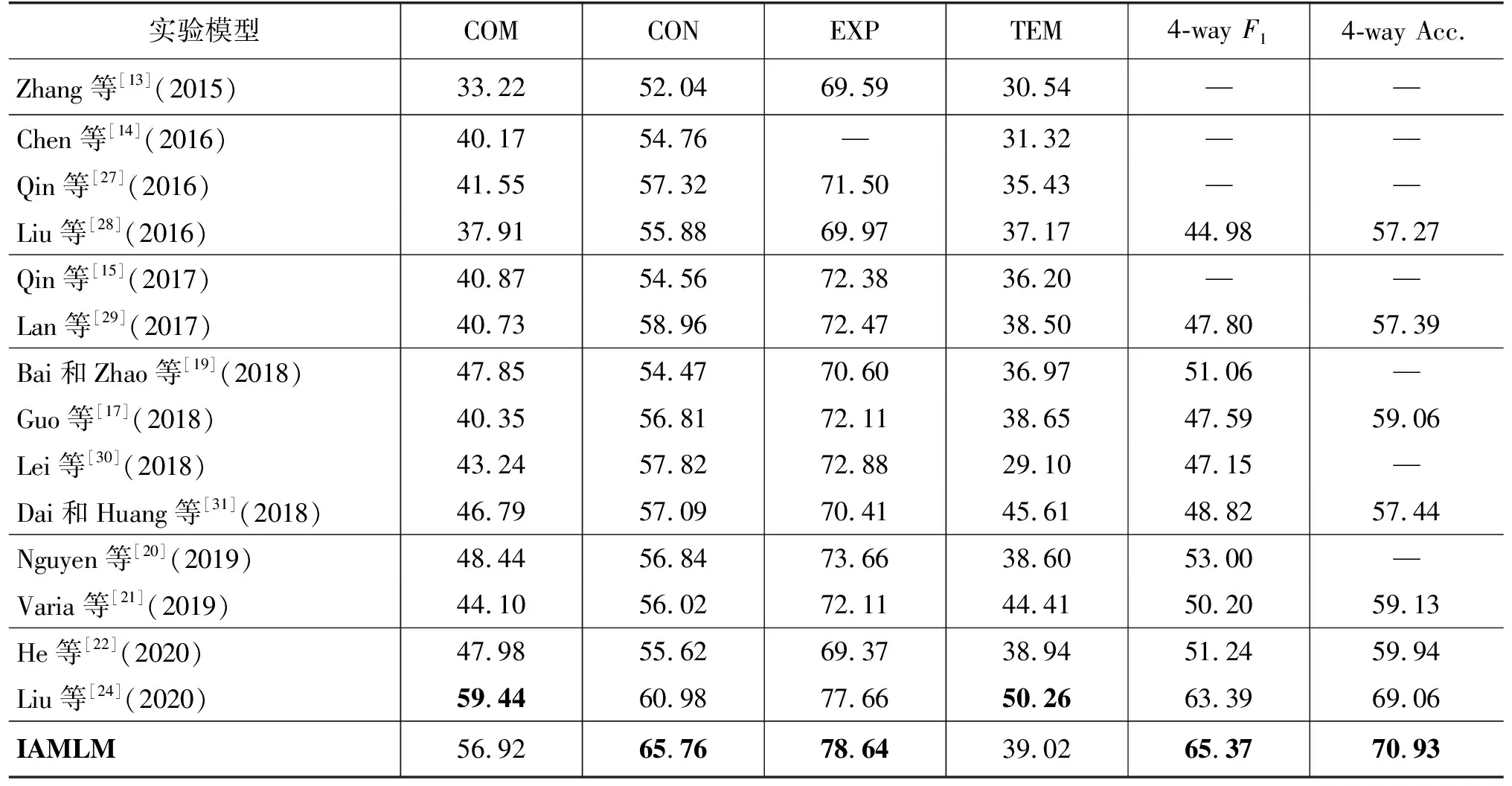
表3 与最先进模型的比较结果 (单位: %)
本文首先评估该任务的四分类模型,其在所有隐式篇章关系分类设置上取得了最好的性能和实质性的改进。接着,在二分类场景(一个关系类和其他关系类)中,它具有与Liu等[24]使用基于RoBERTa-base的上下文感知多视角融合模型相当的性能。与此前最佳的模型相比,在Contingency上提升了4.78%,在Expansion上提升了0.98%。然而,Liu等[24]的工作在Comparison和Temporal上均超过该模型性能,他们采用RoBERTa对论元对进行编码,使用多视角余弦相似度匹配论元,将新的论元表示输入到有门控单元的多头注意力,得到论元的交互特征矩阵,且对其使用了卷积操作。相较之下,本文所提的基于交互注意力掩码语言模型在模型与论元表示上较为简单。尽管如此,本文所提方法,仍能在Contingency和Expansion关系上超越该方法。Varia等[21]在Temporal关系上也优于本文模型,这是因为Varia等[21]使用了扩展语料,其捕获了显式及隐式关系分类的论元之间的相互作用。而本文所提出的模型并没有使用其他的语料进行辅助训练。
此外,为了显示辅助任务权重α大小对模型性能的影响,本文对不同α的取值进行实验,在该任务的二分类模型上进行评估,实验结果如图3所示。实验结果表明,辅助任务权重α大小过低或过高都会使得模型性能退化,当α取0.5时,模型综合表现最好。
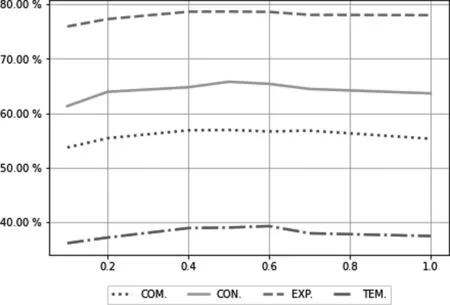
图3 模型在不同辅助任务权重大小下的表现
最后,为了显示不同遮蔽论元比例对模型性能的影响,本文对根据交互注意力权重来选词遮蔽的比例取值进行了实验,在该任务的二分类模型上进行了评估,实验结果如图4所示。本文对照不进行遮蔽论元的实验组,在选词遮蔽比例在0%~20%的情况下,模型性能和基准模型性能相当,这是因为在遮蔽词比例较小的情况下,对关键词的遮蔽存在较大的偶然性,模型学习到的语义信息并不完整。而随着比例的增加,模型的性能在30%处达到峰值,而后比例在35%~45%时,模型性能开始退化,说明了遮蔽词数量过多,反而会让模型引入噪声,无法正确重构掩码区域语义表示,从而降低模型分类的性能。最终,本文选择性能综合表现最好的遮蔽词比例30%作为最终取值。
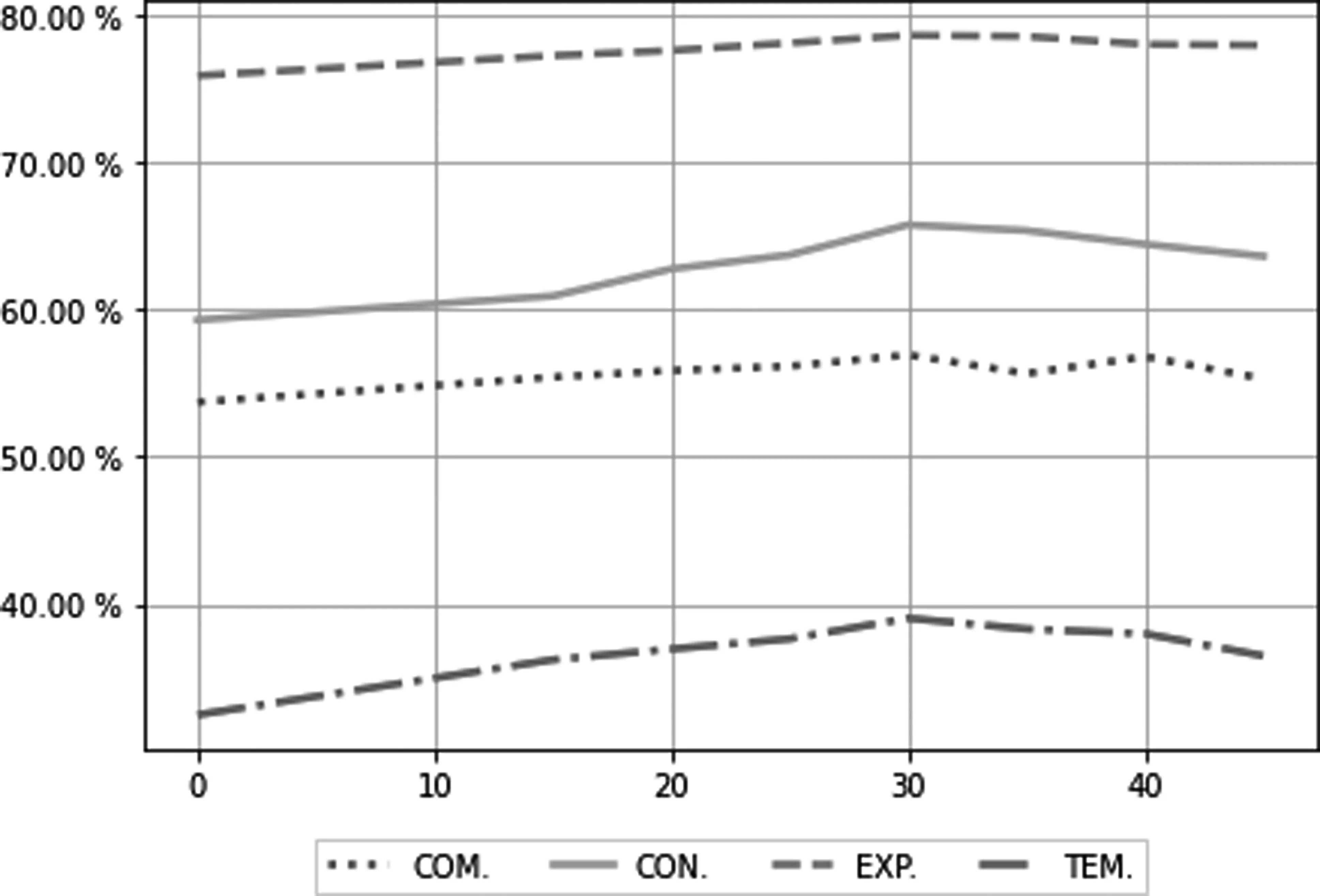
图4 模型在不同遮蔽比例下的表现
3.5 显著性检验
为了验证本文模型能够显著提升性能,并且排除偶然性的影响,本小节进行了显著性检验分析[32],即重复进行多次实验(本文5次),计算使用RMLM、IAMLM与其基准模型RoBERTa在测试集上F1值指标的p值。本文采用Johnson[33]的建议,将阈值设置为0.05。在显著性检验中,当p值小于阈值时,认为结果存在显著差异,否则差异不明显。实验结果如表4所示,本文提出的IAMLM在PDTB 2.0测试集上多个类别计算出的p值远小于0.05,结果存在着显著提升。
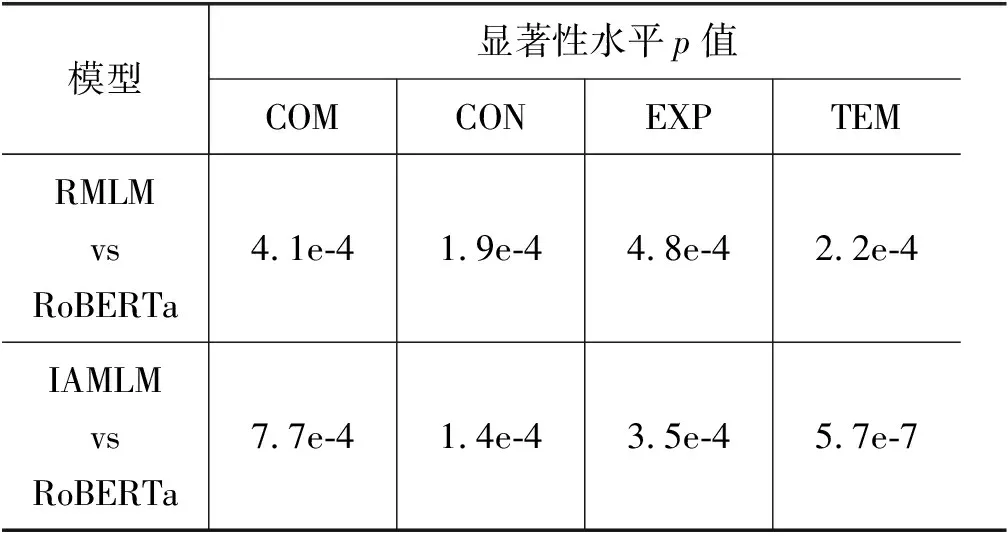
表4 显著性检验结果
4 结论
本文旨在研究隐式篇章关系分类任务,并提出了基于交互注意力掩码语言模型的隐式篇章关系识别方法。该方法无需外部语料,通过上下文的表示来预测交互注意力选出的关键词,以此得到更好的语义空间。实验结果表明,本文所提方法在基准模型的基础上有所提升,取得了与目前最优的模型相当的性能。
数据分析表明,PDTB语料中,同一个论元对可能伴随着两种不同的关系。因此,在下一步的工作中,我们将设计一个上下文感知的对抗模型,以选择性地为中心论元分配注意力权重。同时,因为训练数据的缺乏,目前的分类方法在Temporal等类别上的性能仍然不高。为此,我们将借鉴元学习等方法从少量数据中提高模型的判别能力。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机技术与发展(2022年5期)2022-05-30
心理学报(2022年5期)2022-05-16
密码学报(2021年2期)2021-05-15
当代陕西(2020年17期)2020-10-28
网络安全和信息化(2019年7期)2019-12-22
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
长江学术(2016年4期)2016-03-11
电脑知识与技术(2015年12期)2015-07-18
