
基于机器学习的“软助”证书挂科生分类预测研究
2021-12-30 01:26何雪锋
河北软件职业技术学院学报 2021年4期
何雪锋
(四川信息职业技术学院 软件学院,四川 广元 628017)
0 引言
软件助理工程师(简称“软助”)认证考试是某高校软件专业大二学生必须参加的考试,获取“软助”证书也是毕业的基本条件之一。每一届有300人左右参加考试,约40人不能拿到该证书。如果能根据学生大一的各科成绩,提前预测可能挂科的学生,将更有利于提前为这些学生发出预警信息,也方便教师有针对性地进行指导,从而尽可能减少不及格的人数,保证学生顺利毕业。通过挖掘相关数据,分析数据背后的运行规律,及时给学生发出警告,对课程的及格率、证书的通过率、学生的毕业率等均有积极地促进作用。
目前,已有专家、学者对学生的成绩预警做出了相关努力和贡献。樊一娜等人[1]选择作业分数、提问回答、登录次数、学习时长、课程资源访问频率五个因素作为依据,通过构建贝叶斯概率预测模型来预测未来学生成绩的概率分布情况。贾靖怡等人[2]收集某门课程的17个指标数据,构建基于AdaBoost算法的MOOC学习者学习成绩预测模型。刘爱萍[3]采用k平均和knn算法完成高校学生的预测模型。叶泽俊[4]采用基于C5.0算法的决策树分类方法建立决策树分类模型,对四级通过概率进行预测。张燕[5]提出一种基于朴素贝叶斯的英语成绩预测模型,对英语四级考试成绩进行预测。其他研究包括采用支持双路注意力机制[6]、向量机[7-8]、决策树[9-10]、降采样的堆模型[11]、Logistic[12-13]、神经网络[14-15]、随机森林[16]、XGBOOST[17]等算法构建模型,完成分类预测。
上述研究成果的应用已在成绩预警方面取得了较好的表现,但是仍然存在如下几点不足。第一,很多研究在数据量较小的情况下,采用标准差的方式进行数据的标准化是不够科学合理的。标准差标准化数据适合趋于正态分布的数据,教育数据只有在数据量足够大的时候,数据分布才接近于正态分布。第二,教育数据有一个显著的特点,就是数据不平衡,不及格学生一般占比10%左右,而大部分机器学习算法都是基于数据基本平衡的前提,因此这样会导致预测不够准确。第三,部分研究通过单一机器学习构建预测模型,缺乏模型的对比,以准确率为衡量标准,缺乏考虑数据的实际意义,需要根据正类预测为正类和负类预测为负类的混淆矩阵综合进行判断。第四,针对学生资格证书类考试预测的研究相对较少,没有对软件助理工程师考证挂科生分类的相关研究。
针对以上不足,本文收集了某高校软件专业的学生成绩,经过清洗后,采用离差标准化数据,通过SMOTE(Synthetic Minority Oversampling Technique)+Tomek Links算法对不平衡数据进行过采样处理,并应用XGBoost算法构建成绩模型,对学生进行分类预测,通过预测结果的准确率、回调率、精度、混淆矩阵进行模型评估。该方法在预测“软助”不及格学生方面取得了较好的效果,对相关证书的通过率预测能起到积极的参考作用。
1 数据来源及清洗
1.1 数据来源及概况
某高校某学院包括网络、信安、软件技术等专业,“软助”证书是软件技术专业学生在大二上学期必须考取的证书,但是该学院学生在大一结束后,学院内部会有大量的专业调整,为了较准确地预测“软助”证书的挂科情况,本文选取了整个学院2018、2019级共24个班的学生第一学年的22门课程成绩作为研究数据,从教务处获得2018、2019级的“软助”证书的考试分数表,其中两届软件技术专业学生共515人参加考试。
1.2 数据预处理
数据预处理的合理与否在一定程度上决定了最终数据预测的上限值,再好的模型都只是在无限地接近这个上限值,因此数据的预处理是开始构建模型之前较为重要的环节。
1.2.1 数据清洗
清洗数据是建模的必要步骤,只有干净、有效的数据才能发挥较好的作用。针对学生成绩数据,数据清洗主要包括字段的统一、空值的处理、数据的合并、无意义数据的删除等,具体如下:
重命名列名:每个班的成绩是一个excel表,导致某一门课在不同班级命名不一致。
空值处理:部分字段存在缺失值,例如英语、高数、体育大一上学期存在少部分空值,通过填充大一下学期对应学科的成绩来处理。其他课程少部分数据缺失,通过填充该门课程的均值来处理。
合并数据:把22门课程的成绩数据与“软助”考试的成绩合并成一个文档。
删除处理:有少部分外学院转入的学生,缺少多门专业基础课程,为了避免干扰模型的训练,通过删除处理该数据。
1.2.2 确定特征
通过分析数据,英语、高数、体育在大一上下学期的分数高度相关,因此这三门课大一上下学期分别合并成一个字段,并以上下学期的均值填充。军事训练、军事理论、形式与政策等八门课程的学生成绩几乎一样,无明显差距,这种数据对建模毫无意义,进行删除处理。最终得到13个指标(其中第一个字段score取值为True表示“软助”成绩及格,后面的字段是相关课程的成绩)、505条学生成绩的源数据,如图1所示。

图1 确定特征后的数据源
1.2.3 标准化处理
常用的数据标准化方法有三种:第一是标准差标准化数据,该方法非常适合数据在整体上趋向于正态分布的情况;第二是离差标准化,该方法适合数据在一定范围内分布的情况;第三是四分位距标准化,该方法适合数据集中包含多个异常值,此时使用标准差、离差等方法会有较大的误差。限于数据集的数量不够大,不符合正太的分布,但是所有字段值都集中在一定范围内,因此本文采用离差标准化方法标准化数据。

其中,xrc是学生成绩的原始数据(r表示样本行,c表示特征列),xmin是第c个特征的最小值,xmax是第c个特征的最大值,是归一化后的数据。
1.2.4 不平衡处理
解决不平衡的数据,通常会使用过采样的方法达到正反数据的平衡,其方法包括随机过程采样、SMOTE方法、SMOTE+Tomek Links的综合采样。过采样之后,结合决策树算法,对比不同采样后构建模型的效果,如表1所示。
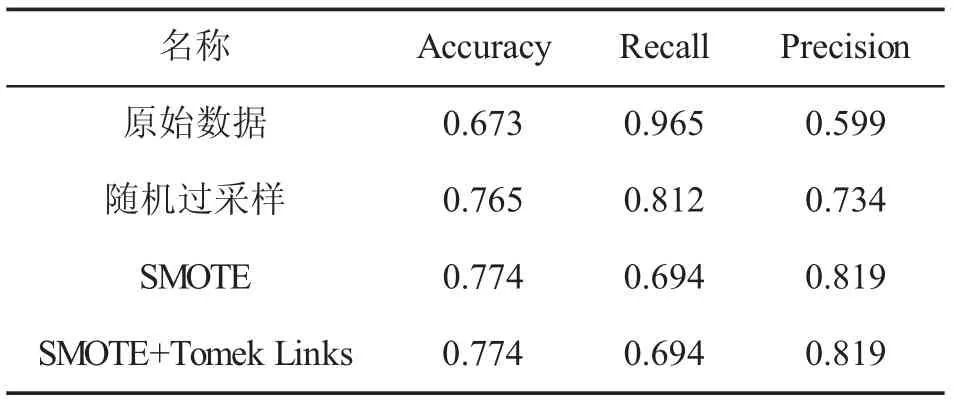
表1 采用后的效果对比
从表1可以看出,未经过处理的不平衡数据,效果较差,相对而言,SMOTE+Tomek Links的综合采样效果较好,文中采用SMOTE+Tomek Links综合采样的方法处理不平衡数据。
2 模型
本文采用XGBoost模型来预测“软助”证书的挂科生,XGBoost是Gradient Boosting算法的一个优化版本,通过正则化项防止过拟合,标准GBM(Gradient Boosting Machine)的实现没有像XGBoost这样的正则化步骤。GBM采用贪心算法进行剪枝,遇到负损值就会停下,而XGBoost在减枝的时候即便遇到负损值也会继续分裂,以最大深度为限制,最后才返回进行剪枝,从而得到综合评价最好的结构树。
XGBoost模型的优化目标函数:

其中,(lyi,)表示当前模型的预测值与真实值的残差,f(txi)表示新增的树的优化值,Ω(ft)表示正则化惩罚项。该模型就是需要找到f(txi)使得目标函数最优。为了方便计算,使用泰勒展开公式来近似地表达上述目标函数。
泰勒展开公式:

其中,遍历x相当于目标函数的yi,△x相当于目标函数的ft(xi)。
定义:
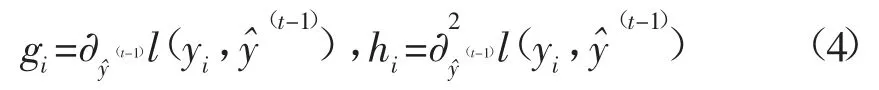
将目标函数按照泰勒公式展开:

式(6)中,T表示叶子的个数,i表示学生样本,j表示叶子节点,因此上式是把对所有学生样本的遍历,转换成对所有叶子节点的遍历。因叶子节点包含了所有的样本,因此两个的遍历是等价的。
定义:

因此,目标函数被简化为:
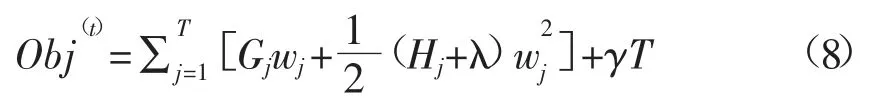
如何让上述目标函数的取值最小,即通过计算变量wj,使得目标函数的值最小。只有当该函数对wj的偏导为0时,获得最优解。
对w求偏导数:
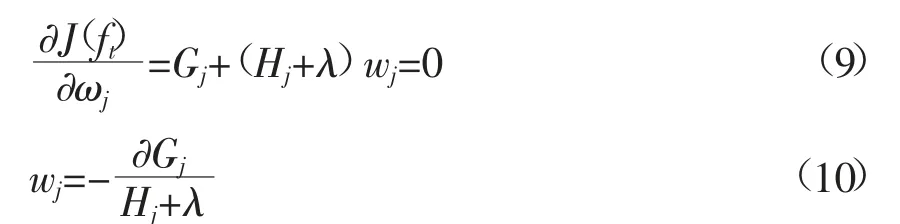
最终目标函数被简化为:
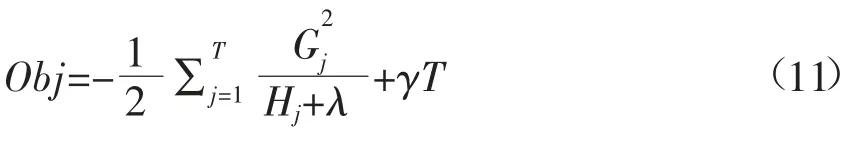
可以认为Obj代表树的结构分值,其取值越小,代表该树的结构越好。因此在构建最优树的过程中,依据上述目标函数进行增益值的判断:

3 实验结果与分析
基于处理后的数据集,采用10折交叉验证和网格搜索的形式,分别采用决策树、逻辑斯蒂回归、随机森林、XGBoost构造了四种“软助”预测模型,通过分析准确率(accuracy)、召回率(recall)、精度(precision)以及混淆矩阵4个指标,对“软助”证书挂科生分类预测模型进行全面评估,其中四种模型的预测结果如表2所示。

表2 四种模型的预测结果
由表2可以看出,随机森林和XGBoost构建的预测模型效果最佳,为了进一步选出在“软助”证书挂科生分类预测中最好的模型,我们进一步通过混淆矩阵来判断两个模型的好坏。
混淆矩阵如表3所示。

表3 混淆矩阵
混淆矩阵的基本概念如下:
(1)False Negative(假负):表示把未通过“软助”的学生预测为未通过。
(2)False Positive(FP)(假正):表示把未通过“软助”的学生预测为通过。
(3)True Positive(真正):表示把通过“软助”的学生预测为通过。
(4)True Negative(真负):表示把通过“软助”的学生预测为未通过。
随机森林和XGBoost的混淆矩阵如表4所示。

表4 随机森林和XGBoost的混淆矩阵
从表4中可以看出,数据源的20%测试集中,共89个未通过的学生,85个通过的学生,随机森林构建的预测模型,正确预测未通过的学生是83个,而XGBoost构建的预测模型,正确预测未通过的学生是87个。在两个模型的准确率、召回率、精度基本相当的前提下,需要选择能更多地预测出可能挂科的学生的模型,其中有两个原因,其一,作为考前辅导,应该尽可能把容易挂科的学生找出来进行辅导;其二,每一年批改试卷的教师不同,有的教师批改较松,会把接近及格的成绩给成及格,因而误将部分通过的学生预测为未通过是较合理的。综上所述,XGBoost构建的“软助”证书挂科生分类预测具有最佳的效果。
4 结语
本文针对某高校软件专业部分学生无法一次性通过“软助”考证的现状,通过采集2018-2019级两届学生大一上下学期22门课程的所有成绩,结合离差标准化、SMOTE+Tomek Links过采样、XGBoost(Extreme Gradient Boosting)算法等,构建了“软助”挂科生分类预测模型。该方法在“软助”挂科生预测中取得了较理想的效果,准确率达到了90.6%,并能最大限度地找出容易挂科的学生。该实验证明,采用XGBoost算法构建的模型比其他算法构建的模型效果更好,对预测可能挂科的学生提前预警,教师有针对性地进行指导具有非常重要的指导意义,进而保证了该证书的通过率。另外,该方法对其他证书的通过率、挂科生分类预测等也具有一定的参考意义。
猜你喜欢
大众标准化(2022年20期)2022-11-07
黄河之声(2022年10期)2022-09-27
林产化学与工业(2022年3期)2022-07-07
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
草原与草坪(2022年1期)2022-05-11
中学生数理化·高二版(2022年4期)2022-05-09
中华老年多器官疾病杂志(2022年1期)2022-03-09
口腔护理用品工业(2021年4期)2021-11-02
中华老年多器官疾病杂志(2020年1期)2020-02-06
