
临床实践指南实施性促进研究之二:基于非肌层浸润性膀胱癌指南的知识图谱框架设计
2021-12-29 09:54王永博李绪辉司宜蓓陈沐坤阎思宇胡文斌靳英辉
医学新知 2021年6期
王永博,高 旷,李绪辉,黄 桥,郭 静,司宜蓓,陈沐坤,阎思宇,胡文斌,靳英辉
1. 武汉大学中南医院循证与转化医学中心 (武汉 430071)
2. 武汉大学计算机学院(武汉 430072)
3. 南京中医药大学附属医院针灸康复科(南京 210029)
4. 武汉大学第二临床学院(武汉 430071)
临床指南是基于系统评价证据,平衡不同干预措施的利弊后形成的旨在为医生和患者提供符合实际情况的推荐意见[1]。临床指南的内容不仅整合了该领域权威专家的临床指导意见,而且涵盖了基本的临床相关理论知识和科学严谨的临床诊疗建议。作为衔接循证医学和临床实践的纽带,临床指南在规范医疗行为、提高医疗质量、降低医疗成本、减少医疗纠纷等方面发挥着重要作用。指南的转化和应用是医学科技成果转化的关键环节。但是,有研究指出目前指南的传播仍然局限于文本形式,导致临床指南的内容不能被实时、准确地查览,严重阻碍了指南在临床决策和实践中的可操作性,使其难以发挥真正的价值[2-4]。
“人工智能+医疗”是指人工智能通过机器学习、深度学习、自然语言处理等技术,利用计算机算法从数据中获取信息,实现辅助诊断、疾病分诊、疗法选择、风险预测等一系列功能[5]。随着人工智能的快速发展,知识图谱已经成为知识服务领域的研究热点[6]。Google于2012年首次引入了知识图谱的概念,并将其应用于搜索引擎,以提高搜索效率。知识图谱以结构化的形式描述了客观世界中的概念、实体及其之间的关系,将互联网的信息表达以更接近人类认知世界的形式呈现,提供了一种更好的组织、管理和理解互联网海量信息的能力[7]。目前,知识图谱在医学领域拥有着广泛的应用和发展前景,如疾病风险评估、智能咨询诊疗、医疗质量控制和医疗知识问答等[8]。构建基于临床指南的医学知识图谱对辅助临床决策有着重要研究价值。
膀胱癌是全球第十大常见肿瘤[9]。全球范围内,男性年龄标化发病率为9.5/10万人,女性2.4/10万人;男性年龄标化死亡率为3.3/10万人,女性0.86/10万人[9]。膀胱癌可分为非肌层浸润性膀胱癌(non-muscle invasive bladder cancer,NMIBC)和肌层浸润性膀胱癌。约75%的膀胱癌患者在初次诊断时为NMIBC[10]。近年来,针对NMIBC新的诊断、治疗方式不断涌现,为此,世界各国和地区不断制订、更新NMIBC临床指南,以指导医生的临床实践。我国也积极推进相关指南制订工作。本课题组于2018年发表了《中国非肌层浸润性膀胱癌治疗与监测循证临床实践指南(2018年标准版 )》[11]。
目前鲜有研究围绕NMIBC临床指南知识图谱设计与应用展开探讨。本文提出并构建NMIBC临床指南知识图谱框架,旨在为指南数字化、智能化提供基础,以推动指南的实施与传播。
1 知识图谱框架设计
1.1 知识图谱框架蓝图
基于NMIBC疾病特征、诊疗现状和指南特点以及临床应用常见问题,明确NMIBC临床指南的知识图谱构建目标,设计符合专业认知与实际需要的NMIBC临床指南知识图谱,图1为NMIBC知识图谱构建框架蓝图。
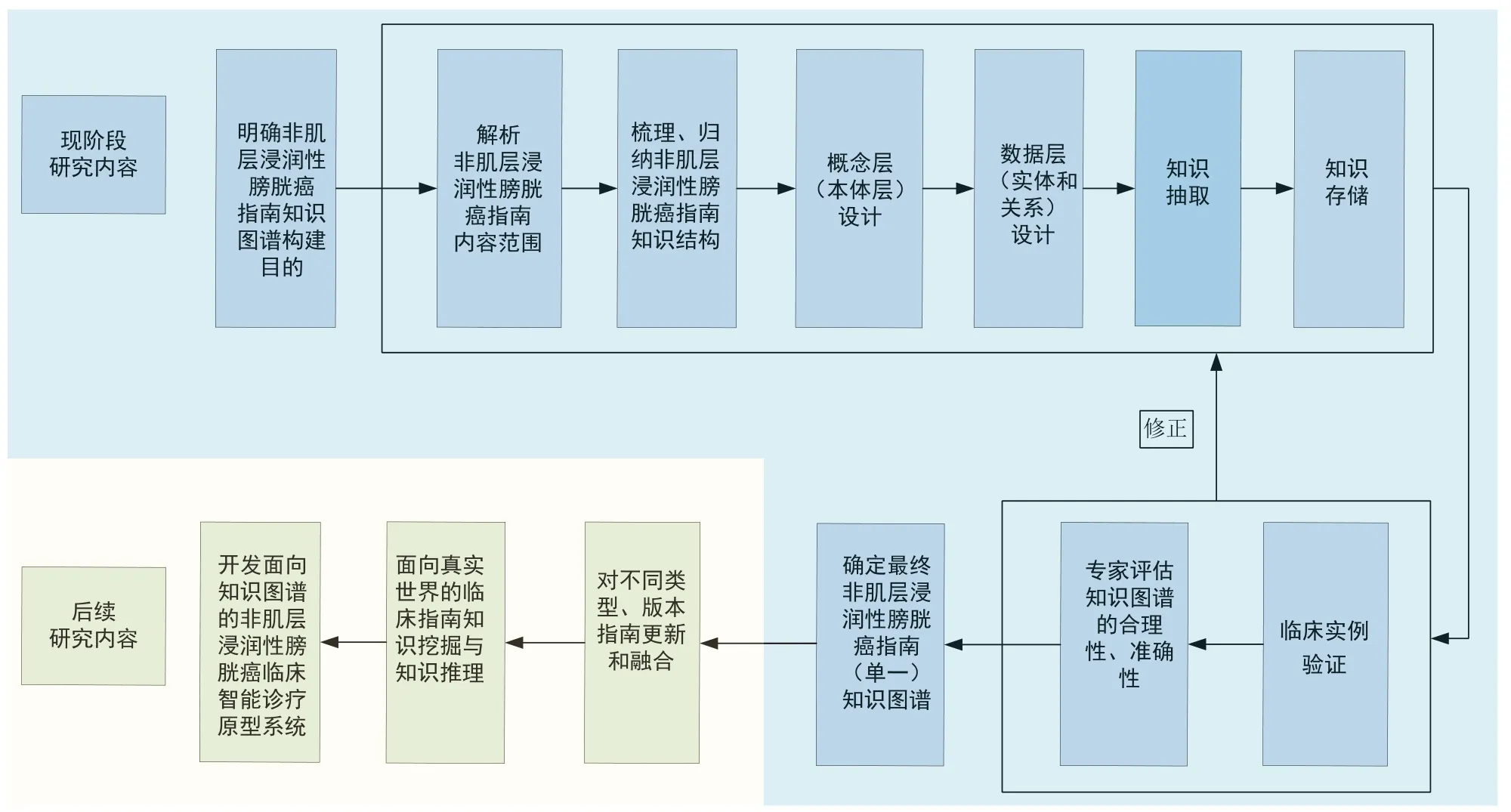
图1 NMIBC指南知识图谱构建的框架蓝图Figure 1. The framework blueprint for the construction of the NMIBC guideline knowledge graph
1.2 指南内容结构化
本研究以《中国非肌层浸润性膀胱癌治疗与监测循证临床实践指南(2018年标准版)》[11]为例。该指南共包含8项主题,分别是:NMIBC手术治疗、化疗、免疫治疗、联合治疗、NMIBC原位癌治疗、NMIBC患者行根治性膀胱切除术、NMIBC复发治疗、随访及监测。通过对指南内容进行梳理,明确该指南涵盖的基本诊治过程,如根据患者基本信息、疾病特征、诊断,提供相应的治疗、预后预测及随访流程。据此,对指南的内容范围进行解析,梳理归纳指南内容和知识结构,结合专家意见设置NMIBC中各概念间的层级关系,对指南内容进行结构化组织(图2)。
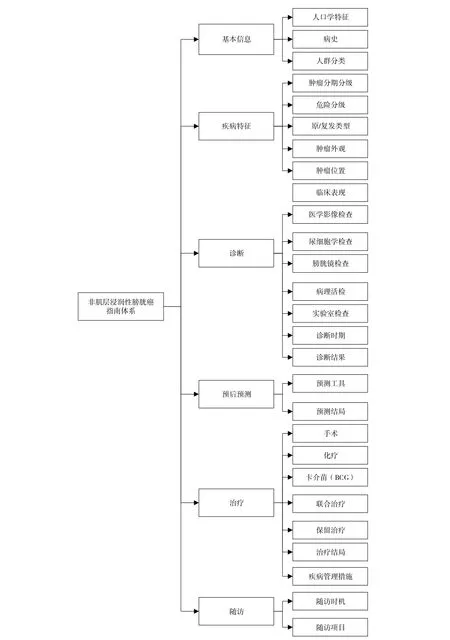
图2 NMIBC指南体系Figure 2. NMIBC guideline system
1.3 概念层(本体层)设计
1.3.1 概念结构设计
知识图谱主要有自顶向下、自底向上及综合法三种构建方式,本研究采用综合法。该方法首先需定义大量重要概念,然后将它们分别进行恰当的归纳和演绎,并与一些中级概念关联起来。
首先,为知识图谱定义概念层与数据层模式,并将实体与关系加入知识库。概念是指具有同种特性的实体构成的集合。本体是结构化知识库的概念模板,通过概念层设计而形成的知识库不仅层次结构较强,且冗余程度较小。概念层是数据的模式,是对数据层的提炼。数据层主要由一系列的事实组成,而知识将以事实为单位进行存储,即数据层是具体的数据。概念层构建在数据层之上,是知识图谱的核心,需依据其来管理和组织数据层。
本研究参照OMAHA Schema(当前版本更新于2021年8月20日)进行概念层提取[12]。OMAHA Schema旨在为中文医学领域的知识图谱构建、数据挖掘、语义分析等提供可参考和可扩展的数据定义和描述规范。在Schema的构建过程中,充分研究和参考了国内外成熟的知识图谱Schema(UMLS语义网络、Schema.org、cnSchema等),同时也考虑了中文医学知识的特点,是一套符合中文环境的医学知识图谱。NMIBC指南体系的大部分内容都符合OMAHA Schema规范,对临床指南中OMAHA Schema未包含的概念层,本研究通过反复讨论进行补充,整理出的NMIBC本体二级概念结构,如表1所示。
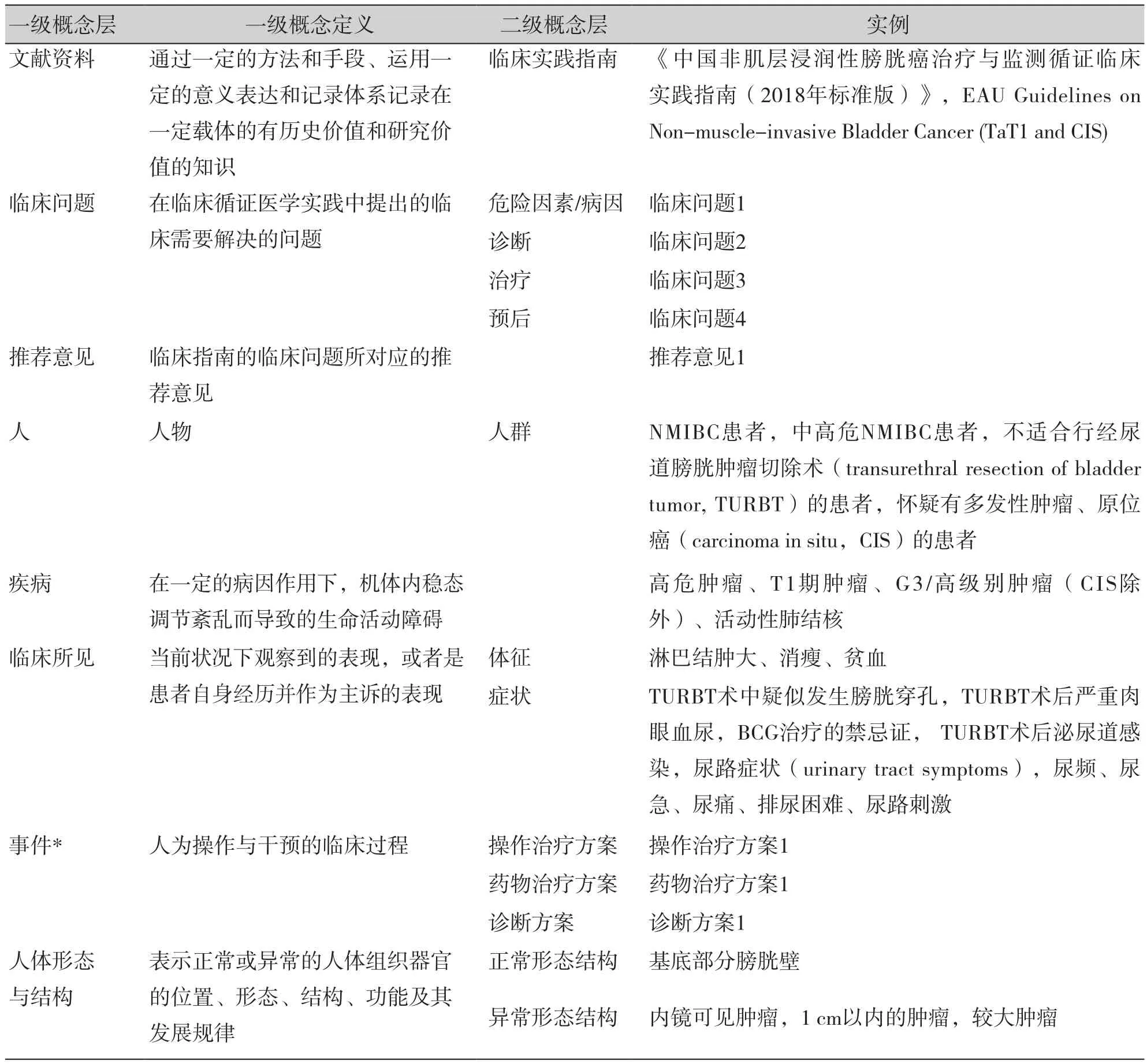
表1 NMIBC指南本体概念结构(部分)Table 1. Conceptual structure for NMIBC guideline (part)

续表1
1.3.2 实体语义关系设计
为实现指南结构的概念整合,其中一个重要的步骤是使这些概念层在语义上形成关联,以构成一个完整的指南结构体。本研究团队根据OMAHA Schema设计了一张以NMIBC知识图谱为使用对象的实体语义关系表(表2,图3),不同疾病知识图谱的概念关系可在此表的基础上进行设计并使用,也可对特定关系进行补充。

图3 NMIBC指南本体设计中实体语义关系图(部分)Figure 3. Entity semantic relation diagram in NMIBC guideline ontology design (part)
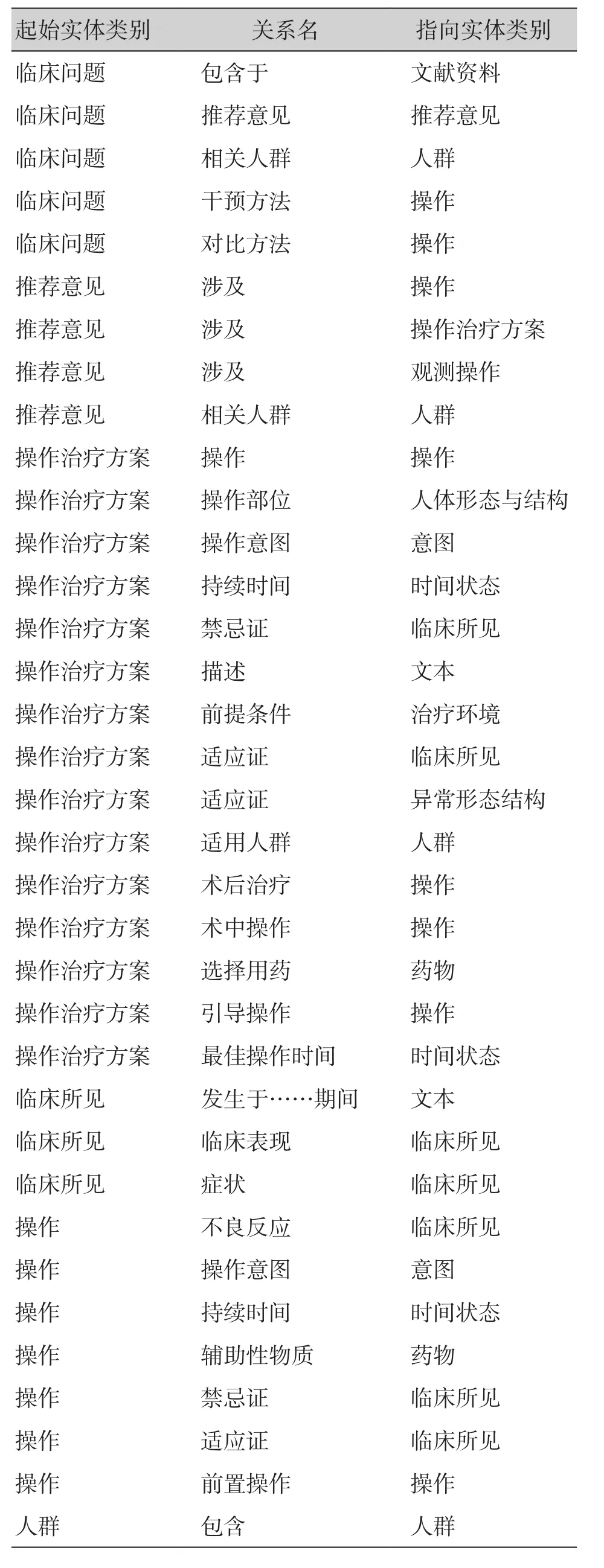
表2 NMIBC指南本体设计中实体语义关系(部分)Table 2. Entity semantic relation in NMIBC guideline ontology design (part)
1.4 数据层(实体和关系)设计
实体是指具有可区别性且独立存在的某种事物。实体是知识图谱中最基本的元素,不同的实体间存在不同的关系。关系用于刻画实体和实体之间的联系。
构建指南数据层的目的是从不同格式的临床指南中提取医学知识,并将医学知识转换为可被计算机处理的数据格式。本研究基于三元组数据模型构建数据层,揭示指南内各类医学实体间的关联,并通过若干个组合的临床指南知识点,形成临床指南知识网络。
如表3所示,对于临床问题1“NMIBC患者行TURBT的适应证”,推荐意见为“对怀疑为NMIBC的患者,推荐TURBT作为诊断和初始治疗的方法”。首先,根据PICO原则对该问题进行拆分,即人群为“NMIBC患者”、干预方法为“TURBT”,另外添加问题的主题为“手术治疗”。其次,提取实例“临床问题1”与“推荐意见1”,两者分属“临床问题”和“推荐意见”概念层,概念“临床问题”与“推荐意见”的关系为“推荐意见”;提取实例“NMIBC患者”为人群,概念“推荐意见”与“NMIBC患者”的关系为“相关人群”;提取“TURBT”为操作,概念“推荐意见”与“TURBT”的关系为“涉及”;提取实例“NMIBC患者”与“TURBT”的关系为“适应证”;提取“推荐”为文本,概念“推荐意见”与“推荐”的关系为“倾向”。临床问题1的主题为“手术治疗”,提取“临床问题1”与“手术治疗”,两者关系为“主题”。问题2—4的数据层(实体和关系)设计如表4所示。
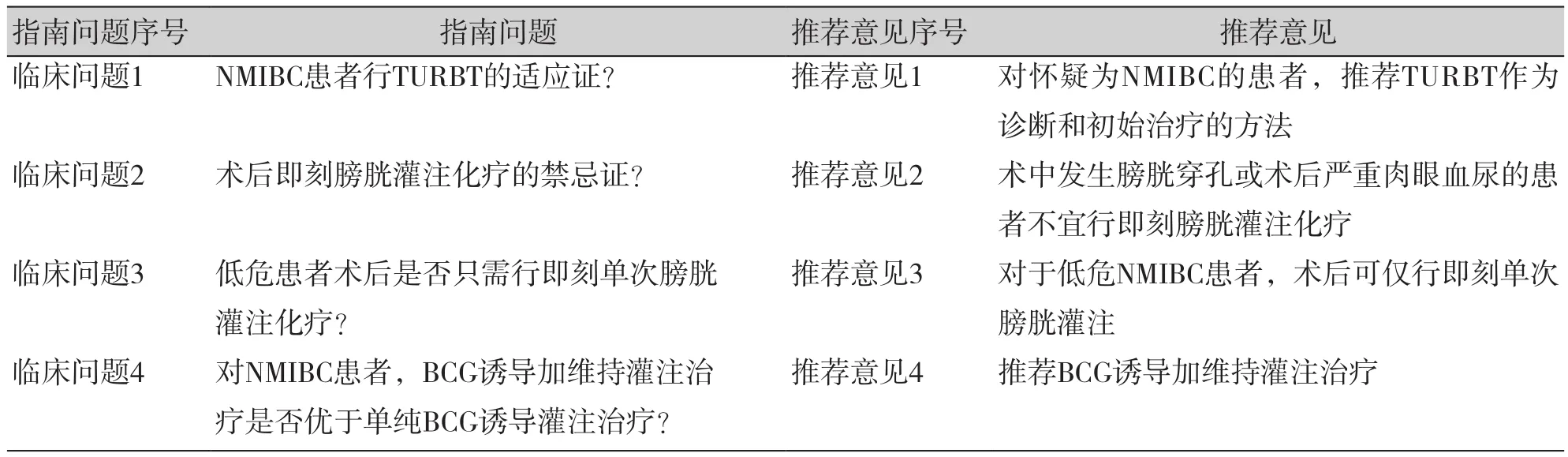
表3 指南部分问题及推荐意见Table 3. Several questions and recommendations of the guideline

表4 三元组关系示例Table 4. Examples of triplet relation
1.5 知识抽取
医学临床指南中含有大量医学术语,临床指南的知识抽取就是从临床指南中抽取与概念层设计相匹配的实体和关系,并将其整理成实体库和三元组关系库。针对NMIBC临床指南用语相对规范统一、内容结构较为明晰、句法搭配相对固定等特点,本研究选择人工抽取的方式。后续系列文章中会涉及到不同类型、不同版本指南的更新和融合,以及真实数据的挖掘过程,拟采用远程监督算法进行抽取。远程监督算法是一种半监督算法,可基于一个标注好的小型知识图谱,给外部文档库中的句子标注关系标签,以实体识别为基础完成关系抽取,远程监督关系抽取类似于多实例问题(multiple instance problem),借助多实例学习和远程监督算法可以快速完成知识的提取和展示。
针对临床问题1—4的问题和推荐意见,实体抽取旨在获取如表5所示的结果。关系抽取参照表2和表4进行。若实体间的关系需要补充,则通过专家讨论协商。

表5 知识抽取示例Table 5. Examples of knowledge extraction
1.6 知识存储及生成知识图谱
明确了所有实体以及实体间的关系后,需设计数据的物理模型对知识进行存储,形成知识图谱。与传统的关系型数据库不同,图形数据库基于图理论,以非结构化的方式存储关联的数据,将图形抽象为节点、边等基本元素,其中一个节点代表一个实体,节点间的边代表实体间的关系,在关联表示方面具有高效的处理能力。为表示多样化、复杂化的医学实体关系,本研究组选用Neo4j图数据库作为存储体系。基于抽取的三元组数据模型,设计并导入医学节点和关系节点,考虑到疾病临床指南整理的数据为中等规模以及数据可实时插入,以CSV文件为主对数据进行存储。
将实体与关系整理成CSV格式的文件,导入Neo4j desktop 1.4.9数据库,输入cypher语句,生成知识图谱:
LOAD CSV WITH HEADERS FROM "file:///Neo4j_Load.csv" AS line
WITH line WHERE line.entityID is not Null and line.valueId is not Null
match (from:entity{id:line.entityID}),(to:entity{id:line.valueId})
merge (from)-[r:rel{property:line.property}]->(to)
其中,entityID为起始实体ID,valueID为指向实体ID,entity为起始实体,value为指向实体。
输入cypher语句:
MATCH (n) RETURN n
可得到可视化结果,即NMIBC指南知识图谱全貌,如图4A所示。
若想获取所有和“临床问题1”相连接的实体及相应的关系,则输入cypher语句:
match p=(:临床问题{name:'临床问题1'})--()return p
4个临床问题相连接的实体及相应的关系如图4B—E所示。其中推荐意见采用绿色圆形表示,其颜色深浅和节点圆形的大小分别表示推荐意见不同的证据等级和推荐强度,使知识图谱节点展示更清晰直观,查询或搜索时更加方便快捷。
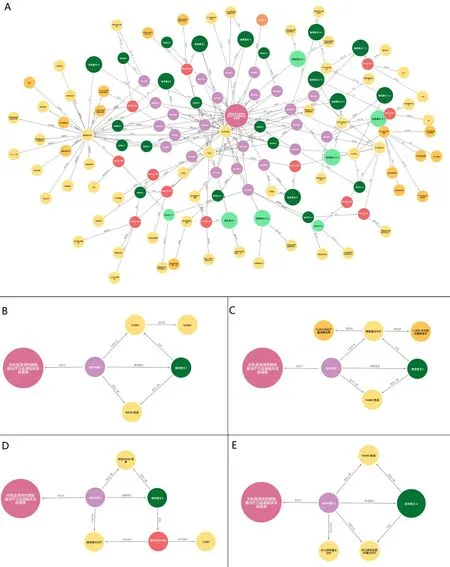
图4 NMIBC指南知识图谱Figure 4. NMIBC guideline knowledge graph
2 临床实例验证
NMIBC知识图谱可实现搜索与推荐功能,应用于临床辅助决策。随着图数据规模的日益增大,大图上的子图搜索问题变得极为重要[13]。以临床问题1—4为例,通过后台代码演示数据库检索过程,以验证检索的准确性。
2.1 查询某操作的适应证
对于临床问题1:“TURBT的适应证?”,该问题的问题类型为查询某操作的适应证,查询元路径:(a:操作)-[:适应证]->(b:疾病/临床所见)。
输入cypher语句:
match (a{name:'TURBT'})-[:适应证]->(b) where b:临床所见 or b:疾病 return b
则可得到图5A的结果,即TURBT的适应证为“NMIBC”。

图5 NMIBC指南知识图谱临床实例验证Figure 5. Validation of clinical examples of the NMIBC guideline knowledge graph
2.2 查询某操作的禁忌证
对于临床问题2:“术后即刻膀胱灌注化疗的禁忌证?”,该问题的问题类型为查询某操作的禁忌证,查询元路径是:(a:操作)-[:禁忌证]->(b:疾病/临床所见)。
输入cypher语句:
match (a{name:'即刻膀胱灌注化疗'})-[:禁忌证]->(b) where (b:临床所见 or b:疾病) return b
则可获取图5B的结果,即术后即刻膀胱灌注化疗的禁忌证为“术中发生膀胱穿孔”和“术后严重肉眼血尿”。
2.3 查询某人群的操作治疗方案中的术后操作及术后操作数量
对于临床问题3:“低危患者术后是否只需行即刻单次膀胱灌注化疗?”,该问题的问题类型为查询某人群的操作治疗方案中的术后操作及术后操作数量,查询元路径:(a:人群)-...-(:操作治疗方案)-[:术后操作]->(b:操作))。
输入cypher语句:
match (:人群 {name:"低危NMIBC患者"})-[*..3]-(c:操作治疗方案)-[:术后治疗]-(:操作{name:'即刻膀胱灌注化疗'})
return
case size((c)-[:术后治疗]->())
when 1 then true
else false
end
则可得到图5C的结果,其中第一行代码检索术后治疗为即刻膀胱灌注化疗的操作治疗方案。随后检索操作治疗方案有几种术后治疗,检索结果是只有一个,所以回答是“true”。
2.4 查询指南推荐的操作方式
对于临床问题4:“对NMIBC患者,BCG诱导加维持灌注治疗是否优于单纯BCG诱导灌注治疗?”。该问题的问题类型为操作对比。
输入cypher语句:
match (a:临床问题)-[:干预方法]-(b:操作), (a:临床问题)-[:对比方法]-(c:操作)where (b.name='BCG诱导加维持灌注治疗' and c.name='BCG诱导灌注治疗') or (b.name='BCG诱导灌注治疗' and c.name='BCG诱导加维持灌注治疗')
match (a)--(:推荐意见)-[:涉及{倾向:'推荐'}]-(d:操作)
return d.name
则可得到图5D的结果,其中第一行代码检索是否存在有将这两种操作方法互为对比的临床问题。随后寻找该临床问题对应的推荐意见。检索结果是“BCG诱导加维持灌注治疗”。
本研究后续会通过规则匹配的方法,实现NMIBC系统的后台操作代码。当用户点击某种治疗方式或预后因素时,系统会根据NMIBC知识图谱接收搜索条件内容,通过规则匹配,最后将其转换为Cypher语句并在Neo4j中查询答案。
本研究采用专家咨询法,邀请专家对设计的NMIBC知识图谱进行评估以验证知识图谱的科学性与合理性,并基于专家意见对知识图谱进行修改与补充,确定最终版NMIBC(单一)指南知识图谱。
3 讨论
本研究基于领域专家共识并参照OMAHA Schema,设计NMIBC领域的顶层本体,提出并构建了NMIBC临床指南的知识图谱框架,其二级概念架构及数据层(实体和关系)设计方法也可为其他疾病临床指南知识图谱的建设提供参考。本课题组考虑到过多的层数会使概念层庞杂而冗余,增加运营与维护成本,且过多的层数会使概念类别数量呈指数增加,为实体抽取带来负担。另外,由于实体提取算法的训练依赖于标注数据,而少量标注数据无法覆盖过多概念类别。因此,本课题组在实际操作中用二层概念层初步构建了该知识图谱,发现其可以合理表达指南中的概念与语义关系。
本研究的知识图谱构建方法着重从知识源头对知识进行优化,设计并调整概念间的关系结构,对实体与实体间的关联进行细化完善,并验证其可行性。对于指南中临床问题和推荐意见缺少的实体,本研究进行了补充,以使知识图谱节点更清晰,查询或搜索时更方便快捷。另外,在综合考虑指南数据存储以及为后续大量指南知识提取提供参考等情况后,本课题组对临床问题根据PICO原则进行拆分,然后由临床问题指向推荐意见,从而确保指南信息存储的完整性。对指南的制订过程与方法、推荐意见中的操作说明和证据概述的补充,以及对不同类型/版本指南的更新和融合将在本系列其他文章展示。
本研究仍存在一定局限。首先,参照OMAHA Schema的语义结构规范虽然可以保证输入知识图谱的数据质量,但仍需临床工作者和工程师对临床指南进行整理和总结,对Schema中缺失的语义类型、属性关系进行补充。其次,非结构化文本指南中有确定性知识和不确定性知识两种,不确定知识的选择和划分也是难点之一。更好的方法是引入多种知识表达方式以增强知识图谱的语义表达能力。
综上所述,本文提出的NMIBC指南的知识图谱框架设计不仅为指南数字化、智能化提供了基础,同样可以用于辅助临床决策,有利于指南的实施、推广与传播。本研究提出的框架设计不仅适用于NMIBC的知识图谱构建,对于其他医学专业或通用医学知识图谱的构建也可以提供思路。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
电视指南(2016年12期)2017-02-05
领导科学论坛(2016年9期)2016-06-05
Coco薇(2015年12期)2015-12-10
中国报道(2009年12期)2009-01-15
