
小麦模型WheatSM 参数调试优化方法研究
2021-12-26 06:21靳霞菲陈先冠宫志宏冯利平
农业大数据学报 2021年3期
靳霞菲 陈先冠 宫志宏 冯利平*
(1.中国农业大学资源与环境学院,北京 100193;2.天津市气候中心,天津 300074)
1 引言
农业生产系统是一个复杂的多因素动态系统,仅仅依靠传统的农业田间实验来探究基因型、环境和管理措施的相互作用相当地耗费财力、物力和人力[1,2],而在这方面作物模拟模型具有明显的优势[3],可为农业生产管理优化决策提供科学依据。随着对作物发育机理的进一步理解,并考虑光、温、水等多重因素对作物发育进程及产量等的影响,模型在作物生长及生产定量化方面也取得了一定的成就,许多的作物模型逐渐被发展应用起来[4-9]。如Richie 等[10]研制了CERES 模型,该模型广泛应用于农业气象、作物生长发育等方面。APSRU[11](Agricultural Production System Research Unit)开 发了APSIM(the Agricultural Production Systems Simulator)模型。荷兰Wageningen 农业大学和世界粮食研究中心(CWFS)共同开发了WOFOST (World Food Studies)模型[12-13],并在农业生产服务方面得到了广泛的应用。
作物模型已成为现代农业相关科学研究、教学与业务及生产管理决策中必不可少的重要工具与方法之一,但其具有参数多、变异性强和不确定大等特点,因此作物模型参数校准是模型应用的重难点。为快速、准确地调节作物模型参数,已有多种自动调参方法被提出并得到实际应用。Holland等[14]模拟自然界的生物进化规律和遗传定律的思想提出遗传算法(Genetic Algorithm,GA),其在搜索过程中因为不需要对空间的信息进行大规模的搜索,可以有效地避免局部收敛最优解,所以面对非连续、无规则的目标函数,它也可以最大可能的找到全局最优解。庄嘉祥等应用改进型遗传算法对水稻生育期模型参数进行自动估算[15]。Beven 等[16]提出了DSSAT-GLUE 参数调节优化算法,该算法继承了RSA 方法和模糊数学方法的优点,是一种度量模型参数的不确定性和评估模型参数的敏感性的智能方法。姚宁等应用GLUE 方法对不同水分胁迫条件下DSSAT-CERES-Wheat 模型进行参数校准[17]。James Kennedy 和Russell Eberhart 合作提出了粒子群优化算法[18](Particle Swarm Optimization,PSO),该算法在实际的应用中,因需要调节的参数较少、原理简单易懂等被广泛应用。奚茂龙等使用随机漂移粒子群优化算法对RZWQM 替代模型进行自动参数优化[19]。John Doherty[20]提出了PEST 优化算法。梁浩等使用PEST 参数自动优化工具对土壤-作物-大气系统水热碳氮过程藕合模型的土壤水力学参数、氮素转化参数和作物遗传参数进行自动寻优[21]。上述研究提出了多种参数自动优化方法,并应用于作物模型参数优化,目前自动调参与作物模型耦合系统的设计研究还不多见。
冯利平等在“水稻钟”模型研究基础上[22],建立了WheatSM 模型,该模型将光、温以及春化作用等影响因素与作物的生长发育相关联,具有较高的模拟精度和较好的作物生产指导意义。WheatSM 模型已在作物生产优化管理上得到一定的应用,但由于该模型参数较多,尤其是发育期参数,模型参数调试复杂。本研究在吸收国内外作物模型参数调节与验证方法的基础上,构建了一个适合WheatSM 模型参数的自动调节耦合系统,旨在为WheatSM 模型参数的自动优化提供一种便捷方法。
2 材料与方法
2.1 数据来源
试验数据来自于中国农业大学上庄试验站(北纬39.83°,东经116.42°,海拔50m),2014~2016年冬小麦播期试验,包括早播和中播两个播期处理,供试品种为农大211。
气象数据(日最高气温、日最低气温、日照时数、逐日降水量、平均风速、水汽压等)来源于中国气象数据网。土壤数据主要包括田间土地的土层深度、饱和含水量、田间持水量、凋萎含水量及容重等反映土壤理化性质的参数,试验地点表层以粉粒为主,土壤表层是具有石灰性属性,土壤表层容重在1.01~1.58g/cm3之间[23]。管理数据主要有播种日期、发育期、生物量、播种密度、灌溉日期、灌溉量、施肥日期、施肥量等,来自试验记录。
2.2 自动调参耦合系统
本研究利用Python 编程语言构建自动调参系统,把WheatSM 模型和PEST 工具进行耦合,并将PEST 参数自动优化方法应用到WheatSM 模型的参数调试寻优当中。系统可对小麦生育期和产量参数进行自动寻优,实现小麦发育期和产量参数的快速、准确地校准。
2.2.1 自动调参耦合系统设计
自动调参耦合系统主要由PEST、WheatSM 模型和Python 语言耦合程序三个模块组成,它们互为关联,共同协作完成作物发育期和产量参数的自动调节优化功能。在本研究中使用的PEST 版本为9.11,Python 版本为3.6.4,编程环境为JetBrains PyCharm 4.0.4。Python 程序主要涉及pyWheatSM 模块(程序主体模块)和Change_parameter模块(参数调节模块)两部分,其中,pyWheatSM 模块通过import 获取各个系统模块包和Change_parameter 模块。Python 编程构建的程序主体和模块中的功能函数,可实现对WheatSM 模型和PEST 的连接,在WheatSM 模型输入文件的准备基础上,用户只需调整PEST 的部分配置,即可进行系统的自动调参。
2.2.2 系统模块简介及功能原理
本研究中PEST 模块功能主要用于提供参数自动优化方法,WheatSM 模型模块功能主要用于对试验点的气象数据、土壤数据、管理数据及作物数据等进行模拟,Python 语言耦合程序主要用于耦合PEST模块与WheatSM模型模块,起到中间桥梁的作用。
2.2.2.1 PEST模块
PEST 算法基于 Gauss-Marquardt-Levenberg(GML)算法对非线性系统的目标函数求解最小值,目标函数即模型参数计算值与实际观测值的差异函数[24]。PEST 自动优化计算方法中[25],向量x 为模型的参数,向量y 为观测值,则x 与y 的关系可以用下式表示:

式中,x 为含有n 个参数的向量,y 为含有m 个实测值的向量,F 表示模型参数与实测值相关联的一个非线性函数。将公式(1)线性化得:


式中,i 和j 分别是J 的行列数,利用一阶泰勒展开式对J0进行数值求解,实测值存储在向量y 中,在模型校正之前,先选定初始参数的向量模型运行结束时,模拟结果存储在向量中。模型多次迭代优化运行,PEST 则通过u(增量向量)不断地更新参数向量和向量u:

式中,k 是迭代次数,T 是转置符号,O 是m 行m 列的实测值权重矩阵,矩阵O的对角线上的元素是每个实测值在整个模型误差中的相对权重,矩阵O的非对角元素值都是零。上标“-”代表更新前的x 向量,“+”代表更新后的x 向量,通过公式(4)计算参数增量向量u0和更新后的并将存储到参数向量中,如此重复计算操作直到全部收敛。由公式(4)可知目标函数:

在本研究中,将目标函数分为出苗期、拔节期、抽穗期和成熟期四组,计算公式如下:

式中,Φ是目标函数,ps、pj、ph和pm分别是出苗期、拔节期、抽穗期和成熟期观测值的个数;Oi和Si分别代表第i 个实测值和第i 个模拟值;ωs、ωj、ωh和ωm分别是出苗期、拔节期、抽穗期和成熟期的权重系数。
2.2.2.2 WheatSM 模块
小麦生长发育模拟模型WheatSM(Wheat Growth and Development Simulation Model)是由冯利平等在大量的田间作物实验和大面积范围的数据资料分析基础上研发的[26]。小麦发育期模块是Wheat-SM 小麦模型模拟的重要内容。小麦的生长发育过程受温度、水、光等气象因素、品种类型以及土壤等环境条件的综合影响[27],并且不同的影响因子对小麦发育的不同阶段有着不同的作用。小麦发育期的理论模型可表述如下[28]:

对上式进行积分就可以得到小麦生育时期数DSI,进而模拟小麦的生长发育进程。
式中:M 为生育阶段内的发育进程;k,p,q 均为小麦的品种特性参数;TE 为温度效应因子;PE 为光周期效应因子;ECi为栽培措施影响因子;f(ECi)为栽培管理措施因子影响函数。
TE的计算公式如下:

式中,Ti为第i阶段内的平均温度;Tbi、Tmi和Toi分别是该生育阶段内小麦生长发育的下限温度、上限温度以及最适温度。
PE的计算公式如下:

式中,PLi、PLbi和PLoi分别为该生育阶段内小麦生长发育的日平均光长、最适光长以及临界光长。
在生长阶段,小麦的干物质不断积累并分配给小麦籽粒,最终形成产量,其基本模型如下:

式中,YD 为小麦经济产量,单位为kg/hm2;de为截止到小麦抽穗期时的天数;D 为全天生育期数;Tr1为抽穗前茎鞘存储物向籽粒的转运效率;Tr2为抽穗后光合产物向籽粒的转运效率;η为由g/m2换算成kg/hm2的系数。
2.2.2.3 Python模块
本研究中Python 语言耦合程序的主要数据包包括Numpy、Win32 API(Application Program Interface)、Time、Datetime、OS(operate system)以 及Change_parameter 等。本研究中,Numpy模块主要用于对数据进行分析和存储处理,将实验结果存入矩阵中,进行处理后输出至输出文件中。Win32API 是较为重要的模块之一,是为实现PEST 和WheaSM 模拟程序进行组合的桥梁,最终目的是将WheaSM的模拟实验结果调取给PEST 进行分析,同样将PEST 调整后的参数重新传给WheaSM 程序,进行再次模拟实验,实现自动调参功能,Win32API 主要功能是对Windows 平台的文件操作。研究中使用的time 模块对程序进行延时操作和日期格式转换功能实现,在进行Python 程序运行中,当调用WheaSM 程序时,需要等待WheaSM 程序运行完毕后,再通过Python 程序中的Win32API 模块调取WheaSM 程序的结果和参数,最终获取结果矩阵。Datetime模块主要是将一定格式的日期进行数字化处理,以便于对数据的运算。os 模块是对于程序文件的操作,对于自动化调参,会产生较大量的数据结果,会使程序运行缓慢,会对调参文件获取结果造成困难,os模块应用于清理多余的结果文件,保障每一次获取数据的结果无异常。Change_parameter:Change_parameter 模块为 自定义的模块,为主要程序提供部分功能,其中有两个方法:调取WheaSM 参数文件并修改的方法xiugaicanshu(hang,canshuzhi),主程序通过调用xiugaicanshu()方法来修改WheaSM 软件参数,其中方法中hang 和canshuzhi 代表一个函数的两个输入参数,通过hang来定位修改的第几个参数值,通过canshuzhi 来确定修改的参数的实际值,由于WheaSM模拟软件的参数与PEST 软件的参数差距较大,放在主程序不易阅读和理解,所以建立自定义模块进行单独的处理。通过调用Caltime(date1,date2)方法,对模拟实验结果的数值进行计算,运算后再通过主程序赋值给PEST 的结果文件中,通过PEST 进行分析后自动调参。Change_parameter 模块在PEST 与WheaSM 模型耦合过程中起着关键性的作用,为参数的自动调节优化操作提供了重要途径和便捷操作。
2.2.3 系统功能模块实现
自动调参耦合系统的功能需求主要包括模拟所需的PEST 初始参数设置(参数个数、参数取值范围等)、PEST优化调整次数设置、实测结果设置(发育期各个阶段结果、产量结果等)、WheatSM 模型输入文件及准备环境设置等。
2.2.3.1 系统环境
本研究中硬件环境:CPU 为2.50GHz 或以上,内存为8G,硬盘为1T,分辨率为1920*1080;软件环境:操作系统为Windows 10,系统类型为64位操作系统,运行环境为NET framework 4.0及以上。
2.2.3.2 系统参数估计方案
系统参数估计的主要措施如下:
第一,确定WheatSM 小麦模型要估计的发育期各阶段(出苗期、拔节期、抽穗期、成熟期)和产量需要输入的参数、参数的取值范围以及初始值,如表2所示。
第二,建立WheatSM 小麦模型运行所需的准备文件:控制文件(*.dat)、管理文件(*.txt)、作物参数文件(*.txt)、土壤数据文件(*.soil)、气象数据文件(*.txt)等。
第三,建立PEST 自动优化模块运行所需的控制文件(*.pst)、指令文件(*.ins)和模板文件(*.tpl)。
第四,利用Python 软件工具将WheatSM 小麦模型与PEST 自动优化模块耦合后,在DOS 窗口下,运行WheatSM 小麦模型与PEST自动优化模块,在发育期和产量参数取值范围内,PEST 自动优化模块根据WheatSM 小麦模型所模拟的输出结果不断优化小麦发育期和产量参数,直至模拟值与实测值趋于一致。
第五,研究中PEST 自动优化过程设置固定优化次数,根据最终小麦发育期和产量参数的率定结果,对WheatSM 小麦模型发育期及产量参数进行验证并研究分析。
2.2.3.3 系统输入文件
耦合系统的输入文件主要包括实测值文件,PEST 的控制文件(*.pst)、指令文件(*.ins)和模板文件(*.tpl)的,WheatSM 模型的作物参数文件(*.txt)、天气文件、管理文件以及模型模拟结果文件(*.txt)等文件。
2.2.3.4 系统运行流程
系统输入文件准备完毕后,在DOS 窗口下启动运行PEST,将调用Python应用程序内部模块把PEST运行生成的作物参数文件转换输出为WheatSM 模型的作物参数文件,之后再次通过Python 应用程序内部模块启动运行WheatSM 模型并将模型模拟的实验结果文件转换输出至PEST,PEST 经过分析处理后对参数进行不断的调节优化,直至得出最优参数,并输出相应的结果文件。在整个系统运行过程中,无需人工操作处理,只在系统运行开始时启动PEST 直至运行结束获得输出结果即可。
2.2.3.5 系统输出文件
耦合系统的输入文件主要包括自动调节优化后的作物参数文件(*.par)、自动调节优化后的模拟结果文件(*.dat)、PEST运行记录文件(*.rec)、参数统计矩阵文件(*.mtt)、参数敏感性文件(*.sen)及残差和权重系数文件(等(*.res)文件。

图1 系统运行流程图Fig.1 The chart system operation flow
2.3 参数校准与验证
在模型模拟过程中,参数的调节与优化要严格按照取值范围的要求进行操作处理,否则容易出现验证结果错误或者验证结果符合但与小麦实际生长发育情况不符的现象。本研究参考郭其乐等的研究结果[29],订正后的WheatSM 小麦模型待校准优化的参数见表1。研究采用冬小麦小麦田间试验数据应用试错法和PEST 自动优化算法进行参数调节,结果见表1。利用2014~2015年冬小麦田间数据进行参数校准,利用2015~2016 年冬小麦田间试验数据进行参数验证。
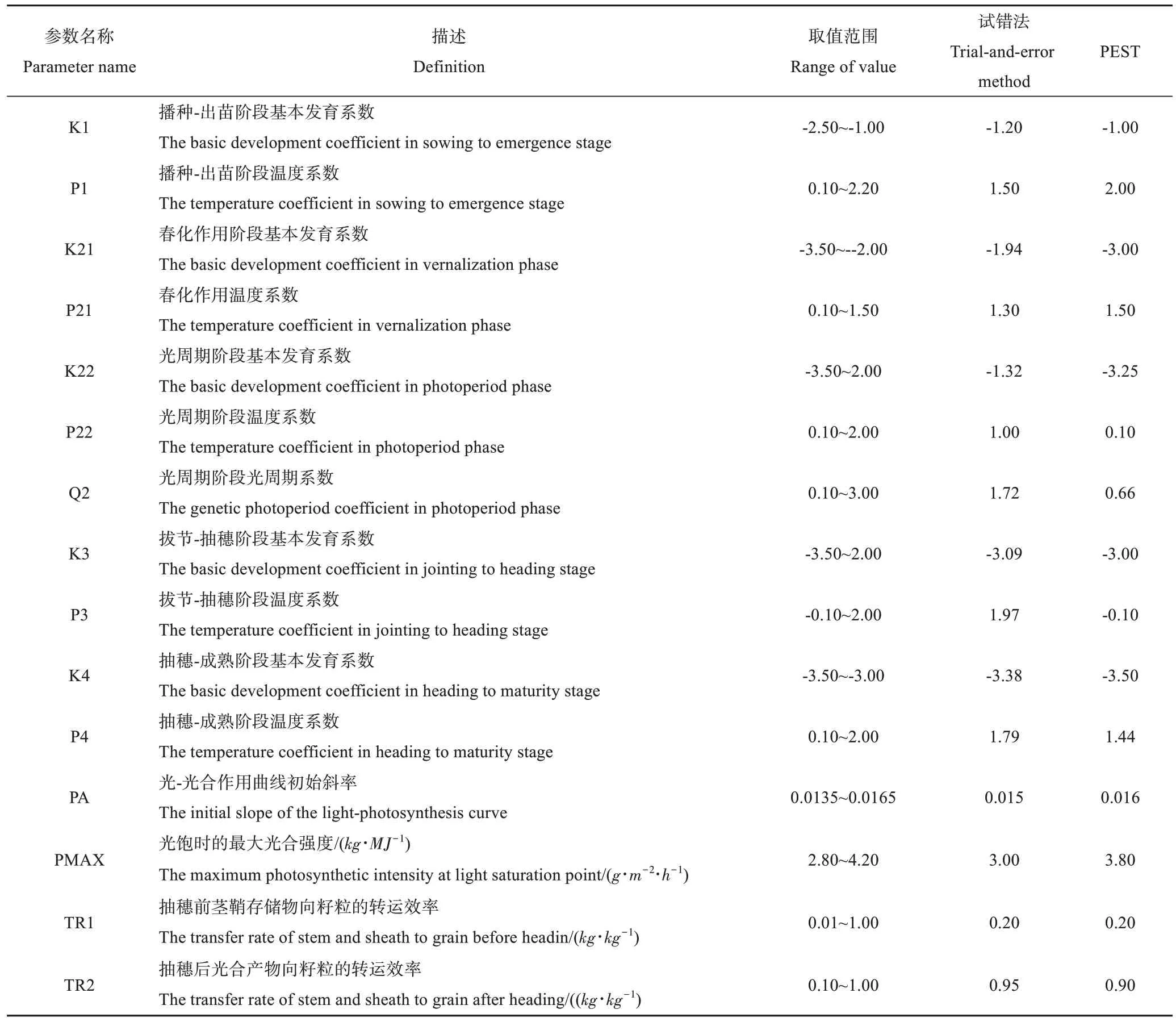
表1 WheatSM模型小麦生长发育及产量相关参数Table 1 The related parameters of the growth and yield of wheat in the WheatSM model
3 结果与分析
3.1 发育期参数校准与验证
如表2 所示,PEST 法调参结果显示,模型模拟早播处理的出苗期比实测日期早3 天,拔节期比实测日期晚3天,抽穗期比实测日期晚3天,成熟期比实测日期晚4 天;模型模拟中播处理的出苗期比实测日期早5 天,拔节期与实测日期一致,抽穗期比实测日期晚1天,成熟期比实测日期早1 天。试错法调参结果显示,模型模拟早播处理的出苗期比实测日期早3 天,拔节期比实测日期早2天,抽穗期比实测日期晚8天,成熟期比实测日期晚4 天;模型模拟中播处理的出苗期比实测日期早5天,拔节期比实测日期早3天,抽穗期比实测日期晚7天,成熟期比实测日期早1天。

表2 2014~2015年份北京上庄试验点调参阶段小麦发育期的实测值与模拟值Table 2 The values of measured and simulated of the growth period of the wheat of Shangzhuang,Beijing site during the parameters’adjusting from 2014 to 2015
如表3 所示,PEST 法验证结果显示,模型模拟早播处理的出苗期比实测日期早4 天,拔节期比实测日期晚2 天,抽穗期与实测日期一致,成熟期比实测日期早7 天;模型模拟中播处理的出苗期比实测日期早6 天,拔节期比实测日期晚了1 天,抽穗期比实测日期早2 天,成熟期比实测日期早7 天。试错法验证结果显示,模型模拟早播处理的出苗期比实测日期早4 天,拔节期比实测日期早4天,抽穗期比实测日期晚5天,成熟期比实测日期早6 天;模型模拟中播处理的出苗期比实测日期早6 天,拔节期比实测日期早6天,抽穗期比实测日期晚2 天,成熟期比实测日期早8 天。相比与试错法,PEST 方法在发育期参数率定方面较优。

表3 2015~2016年份北京上庄试验点参数验证阶段小麦发育期实测值与模拟值Table 3 The values of measured and simulated of the growth period of the wheat of Shangzhuang,Beijing site during the parameters’ verifying from 2015 to 2016
3.2 产量参数校准与验证
如表4 所示,应用PEST 自动优化算法的产量调参结果显示,早播处理模拟产量比实测产量高827.94 kg·hm-2,中播处理模拟产量比实测产量高7.67 kg·hm-2。应用试错法的产量调参结果显示,早播处理模拟产量比实测产量高868.43 kg·hm-2,中播处理模拟产量比实测产量高92.33kg·hm-2。

表4 2014~2015年份北京上庄试验点参数验证阶段小麦产量实测值与模拟值Table 4 The values of measured and simulated of the yield of the wheat of Shangzhuang,Beijing site during the parameters’verifying from 2014 to 2015
如表5 所示,应用PEST 自动优化算法的产量验证结果显示,早播处理模拟产量比实测产量高228.63 kg·hm-2,中播处理模拟产量比实测产量高40.90 kg·hm-2。应用试错法的产量验证结果显示,早播处理模拟产量比实测产量高288.88 kg·hm-2,中播处理模拟产量比实测产量低41.86 kg·hm-2。
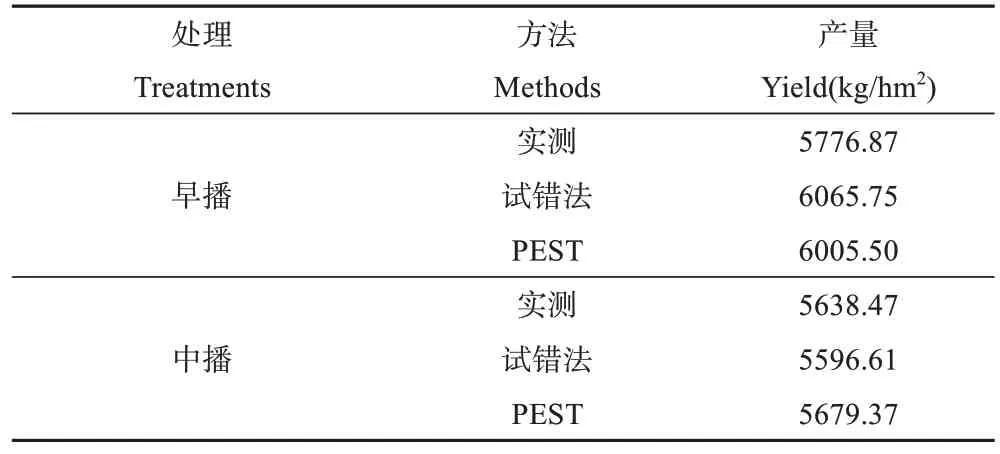
表5 2015~2016 年份北京上庄试验点参数验证阶段小麦产量实测值与模拟值Table 5 The values of measured and simulated of the yield of the wheat of Shangzhuang,Beijing site during the parameters’verifying from 2015 to 2016
4 讨论
WheatSM 模型已在农业及气象领域得到应用,并取得了较好的效果,本研究在WheatSM 模型中增添了自动调参优的功能模块,简化了WheatSM 模型的调参工作,为模型的广泛应用奠定了良好的基础[30]。在本研究中,应用PEST 方法使用2 台计算机对2014~2015 年北京上庄试验点的数据同时进行处理,程序迭代次数设置为30 次,调用WheatSM 小麦模型上百次得出参数的率定结果,最终用时约1 天。采用PEST 方法对模型参数进行调节优化的过程中,在计算机数量允许的前提下,一个研究者可同时对多个地区、多年、多个品种及处理方式等的所有参数同时进行调节优化,进行批量处理操作。
在算法应用方面,具有自组织、自学习等特征的智能算法,实现了模型参数的自动率定,改进了传统的试错法中人工调参的主观性和随意性[31],提高了参数调节与验证的效率,避免了参数率定过程中工作量大、耗时长、模拟精度低等的缺点。然而,由于自动算法优化策略和复杂程度的差异,在优化过程中容易出现局部的极值可能最优、参数不能明确收敛方向、算法需要设定的参数较多等现象,这些都会导致其迭代的运算量变大,收敛速度变慢,收敛值偏差等问题,仍待进一步解决。
总之,在模型参数率定上,利用PEST 方法可批量、可复制性的数据处理功能,减少了参数率定的工作量,节省了模型的操作时间,简化了工作的复杂度和提高了工作效率,尤其是在处理多个地区多年多参数的数据时,更加明显地体现出PEST 方法的高效性和操作便利性等优点。
5 结论
本研究基于PEST 方法构建了WheatSM 模型参数的自动调节耦合系统,并对WheatSM 模型的发育期和产量参数进行了自动寻优。利用2014~2016 年北京上庄试验点的冬小麦不同播期试验数据进行对模型进行参数的调节优化与验证,基于PEST 方法的模型参数调节精准度较高,与试错法相比具有耗时少、可同时批量处理数据、高效快捷等优点,为WheatSM 模型参数的自动优化提供了一种辅助工具,也可为其他作物模型自动调参提供参考。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2021年8期)2021-11-28
金桥(2021年10期)2021-11-05
古今农业(2021年2期)2021-08-14
今日农业(2021年13期)2021-08-14
今日农业(2020年20期)2020-12-15
今日农业(2020年17期)2020-12-15
今日农业(2020年24期)2020-03-17
现代农业科技(2019年7期)2019-09-06
现代农业科技(2018年19期)2018-12-21
