
改进Faster R-CNN的多通道检测算法
2021-12-23 04:34:58殷小芳辛月兰何晓明
计算机工程与设计 2021年12期
殷小芳,辛月兰,兰 天,何晓明
(青海师范大学 物理与电子信息工程学院,青海 西宁 810000)
0 引 言
为了获得完整的图像理解,我们不仅应专注于对不同图像进行分类,而且还应精确估计每个图像中所包含对象的概念和位置。目标检测作为图像理解和计算机视觉的基石,能够为图像和视频的语义理解提供有价值的信息,并且涉及许多应用,包括图像分类[1]、人类行为分析[2]、脸部识别[3]、医疗诊断[4]和自动驾驶[5,6]等。近年来,目标检测算法从基于手工特征的传统算法转向了基于深度学习的方法[7]并得到了很大突破[8]。现有的深度学习方法可以分为两类,一类是两阶段检测方法,该方法使用区域推荐产生候选目标,随后使用卷积神经网络进行处理。目前这类方法主要有区域卷积神经网络(Region-CNN,R-CNN)[9]、空间金字塔池化网络(spatial pyramid pooling net,SPP-net)[10]、快速区域卷积神经网络(Fast Region-CNN,Fast R-CNN)[11]和掩膜区域卷积神经网络(mask regions with convolution neural network,Mask R-CNN)[12]等。此类算法虽然在平均精度上有所提高,但当光照条件不足、目标过小、目标重叠度高等情况下仍然存在误检和漏检的情况;另一类是一阶段检测方法,这类方法无需区域推荐直接回归目标物体的类别概率和位置坐标,这类方法主要有YOLO[13]、YOLOv2[14]、YOLOv3[15]、SSD[16]和RetinaNet等,此方法虽然在速度上提高了但检测精度较低,完美地完成对象检测仍然存在挑战。Ren等提出Faster R-CNN算法[17],进一步提高了Fast R-CNN的检测性能,该算法使用区域提案网络(regional proposal network,RPN),解决了Fast R-CNN的实时性检测和端到端训练测试的问题,但是准确识别不同姿态和视角下的对象仍存在挑战,同一物体不同姿态视角下仍有误检漏检或检测精度较低等情况。考虑到物体外观会根据其基本形状(例如汽车与马)以及不同的姿势和视角(例如,蹲着的人与站立的人)的不同而直接影响检测精度,本文提出一种多通道检测算法(multi-channel faster region-CNN,MC Faster R-CNN)来进一步优化检测性能。改进算法基于Faster R-CNN体系结构,在Resnet-101的网络结构上重新进行了网络训练和参数的调整,并在PASCALVOC2007[18]数据集、PASCALVOC2012[19]数据集、MS COCO[20]数据集和自己拍摄的图像上进行了大量实验验证,实验结果表明,本文算法在检测精度和速度上都有着很好的表现。
1 基本原理
1.1 Faster R-CNN 算法
Faster R-CNN的网络架构如图1所示[21],Faster R-CNN的结构主要分为3大部分,最左边的虚线框为第一部分的共享的卷积层-backbone,中间部分虚线框为第二部分的候选区域提案网络-RPN,最右边虚线框是对候选区域进行分类的网络-classifier。从图1中可以看出,目标检测所需要的4个步骤全部在CNN中实现,并且全部运行在GPU上,解决了Fast R-CNN端到端训练测试的问题。

图1 Faster R-CNN的网络架构
1.2 区域提案网络的工作原理
区域提案网络。其结构如图2所示[22],该网络以任何大小的图像作为输入,RPN是全卷积网络[23],通过端到端训练可以产生量少质优的建议区域,然后通过Fast R-CNN进行检测。RPN和分类回归网络共享第一部分的特征提取网络并与RPN一起训练,降低了网络参数量和训练所用的时间。在最后共享卷积层输出的卷积特征图中使用滑动窗口的操作方式生成区域提案框,滑动窗口的中心在原像素空间的映射点成为锚框(anchor boxes)。每个滑动窗口处会生成K个大小不同的锚边框,由于目标不可能都为正方形,所以设置多种不同面积尺寸的anchor,来得到期望的目标提案框。
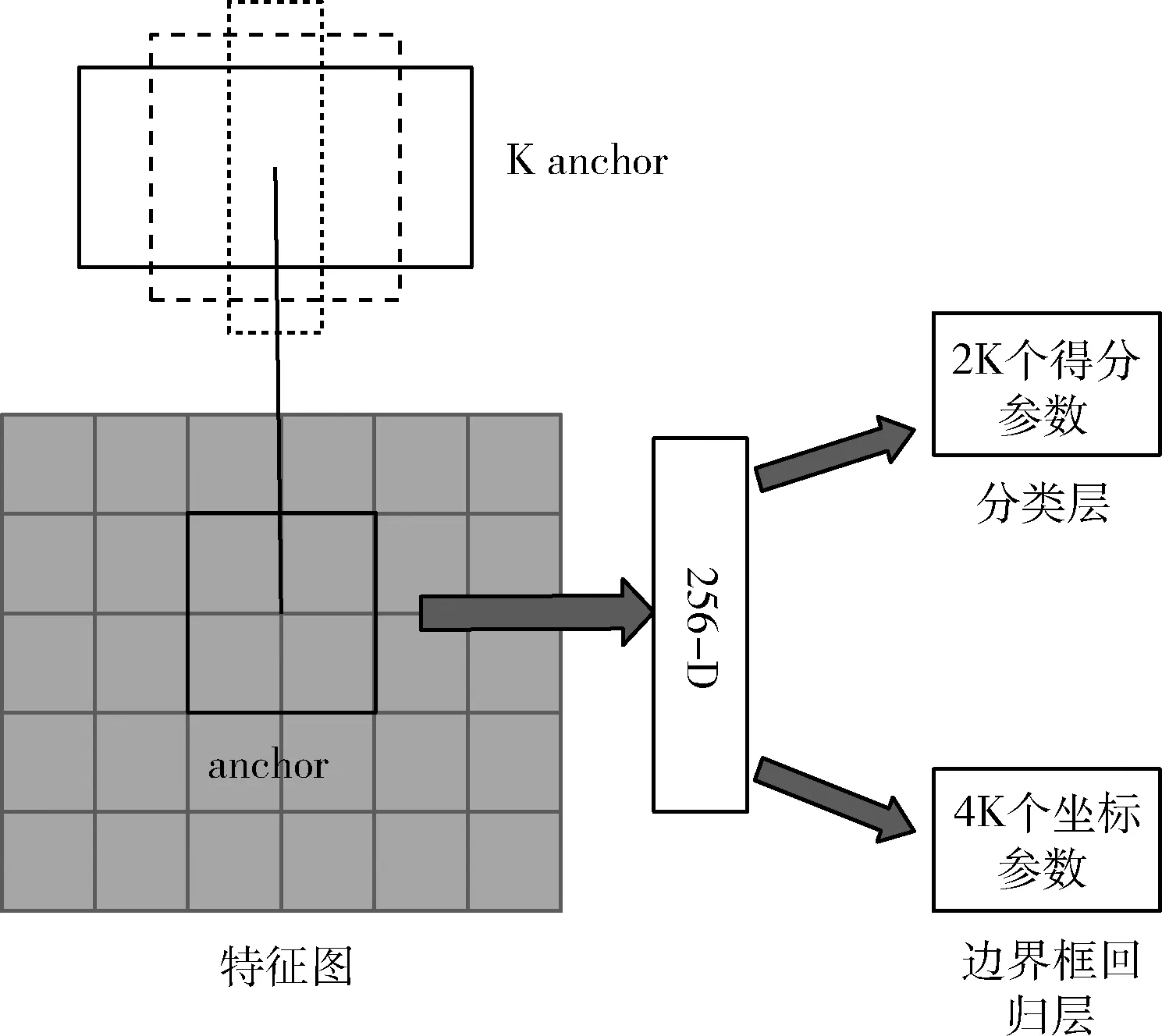
图2 区域提案网络(RPN)
RPN的损失函数和边界框回归。在训练RPN的时候,先需要对得到的W*H*k个锚框进行正负样本的划分,其中与真实的检验框(ground truth box,gt box)中具有最大交并比IoU的锚框以及gt box的IoU大于0.7的锚框作为正样本,与gt box的IoU小于0.3的锚框作为负样本,其余锚框均被忽略。对于每个锚框,后面会再接上一个softmax分类器和边框(Bounding-Box,bbox)回归器。softmax分类器用于判断锚框是否为目标概率,bbox回归器用于调整锚框的4个坐标值。因此RPN的损失函数可定义为[22]
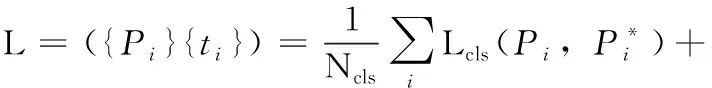
(1)
式中:参数R为smooth函数[24],表达式为
2 MC Faster R-CNN算法
由于目标检测中的物体外观会根据其基本形状以及不 同的姿势和视角的不同而有很大的差异,本文为了优化检测性能,更准确识别20种物体的外观,提出一种多通道检测算法即MC Faster R-CNN,并通过大量的实验与分析验证了该算法的有效性。
2.1 MC Faster R-CNN的网络结构
MC Faster R-CNN的网络结构如图3所示,本文的改进如图中虚线框所示,由于RPN网络能够产生量少质优的区域提案框,有高准确率和召回率且降低了网络参数量和训练所用的时间,所以该算法延用了Faster R-CNN中的RPN网络。Faster R-CNN是由每个图像卷积网络和每个RoI网络组成,图像卷积网络获取输入图像并计算每幅图像的特征图,并将该图作为下一个卷积层的输出,同时区域提案网络生成感兴趣区域(RoI)。由于区域提议网络会生成类似于目标的区域,而不是目标实例,并且不擅长处理极端比例和不同姿态与视角情况下的形状目标。所以本文算法在RoI生成方面不再使用单独的网络,而是改为由3个通道组成的网络,每个通道分别处理相应的RoI。每个通道都具有与Faster R-CNN相同的完全连接层且都带有一个RoI池化层和一组共享卷积层。通过将图像RoI的形状与标定的特有的形状类别之一进行匹配,然后进行适当的通道分配,本文分为水平延伸(H)、正方形(S)、垂直延伸(V)这3类。在测试中,MC Faster R-CNN从3个不同的通道输出3组检测结果,即边界框及其得分。得分通过精度评价式(2)[25]来计算,IoU值越大精度越高评分越高,反之,精度越低评分越低。本文将重叠标准定为0.3,然后通过非极大值抑制来精炼边界框
IoU=(A∩B)/(A∪B)
(2)
式中:A为候选框,B为原标记框,比值为1是最理想的完全重叠状态。
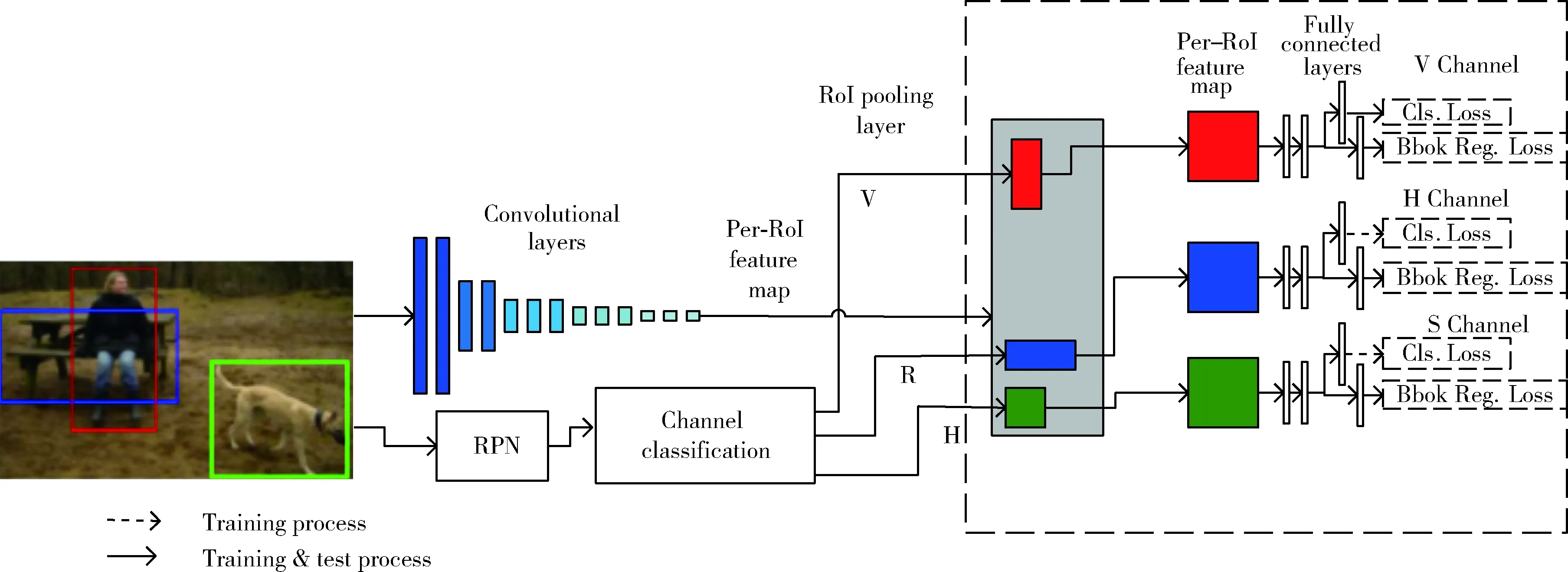
图3 MC Faster R-CNN的网络结构
2.2 通道分配
生成RoI后,本文根据目标的形状类别将每个RoI分配给相对应的通道。每个RoI的形状类别均根据其纵横比来分配,其中包括水平伸长(H)、方形(S)或垂直伸长(V)3种形状类别。用θ表示RoI的宽高比并定义为式(3)
θ=W/H
(3)
式中:W和H分别是RoI的宽度和高度。
进行训练时通道分配定义为式(4),根据此RoI分配标准,RoI可以分为多个类别,比如接近方形的水平拉长物体既能分到水平拉长通道又能分到方形通道。这样做的目的是让多个通道负责同一RoI,这些RoI可以在不同类别之间共享,同时增强了RoI训练集,可以获得更多的前景信息和背景信息及正面和负面示例,在训练阶段提供了更加丰富的信息。在测试阶段为了保证检测速度并提高检测性能强制将RoI分配给仅1个通道进行测试,将通道分配标准设置为具有不重叠的区域,并定义为式(5)
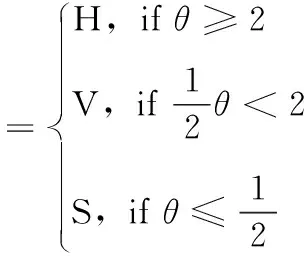
(4)
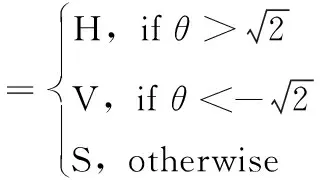
(5)
2.3 学习网络
本文通过最小化正则函数R(W)和3对损失函数之和L(W)来优化权重为W的网络,3对L(W)分别连接到网络中对应的通道上进行优化。对于每个通道c,分别将softmax损失函数Lsoftmax和smoothL1损失函数Lsmooth用于对象分类和边界框回归,本文将损失函数定义为[11]
(6)
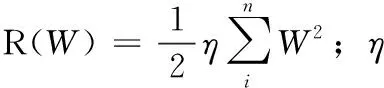
2.4 多批次迭代
为了优化3个通道,本文选择每次准备3批迭代,每个批次均由两个图像构成,每个图像贡献了64个随机选择的RoI。对于每个通道,仅选择与其关联的形状类别匹配的RoI进行训练。根据RoI和ground truth边界框之间的重叠标准(IoU),每个RoI会被标记为正例或负例,其中IoU等于或大于0.5的RoI被标记为正例,IoU在0.1到0.5之间的RoI被标记为负例。对于每一批,正例和负例样品之间的比例固定为1∶3。
3 实验与分析
3.1 实验设计
通过第2节中的所有分析,本文使用基于Resnet-101的Faster R-CNN构建的MC Faster R-CNN。本文所有实验均在Windows10 1909系统下进行,其中深度学习框架为tensorflow1.14,硬件环境为Intel Corei5-8400 2.81 GHz CPU,NVIDIA GeForce GTX 1080Ti GPU,显存为11 GB。软件环境为Python 3.6,Keras 2.2.5,CUDA 8.0。
为了验证本文算法的有效性,采用PASCALVOC2007、PASCALVOC2012和MS COCO这3个数据集和自己拍摄的图像进行测试。都是先使用训练集进行检测算法的网络模型训练,然后在测试集上对训练好的模型进行验证。实验中对所有数据集采用K折交叉验证法[26],本文将训练集S分成5个不相交的子集,5个子集中的一个作为测试集,其它4个作为训练集,并把训练出的模型用来测试得到相应的检测精度。最后计算5次求得的检测精度的平均值,作为本文模型真实检测精度。
本文算法实验结果与Faster R-CNN和YOLOv3进行对比,实验中均使用40k次迭代训练所有方法,基本学习率设置为0.001,经过30k次迭代后降至0.0001。其次,根据高斯分布(均值为0和标准偏差为0.01)随机选择它们来初始化分类层权重。对于边界框回归层,初始化了从高斯分布中随机选择的权重,均值和标准差分别为0和0.001。
3.2 多通道性能检测
MC Faster R-CNN中的多通道所包含的全连接层数量比Faster R-CNN多3倍,这带来了内存效率问题。为验证跨层共享对多个通道的影响,文中选取均值平均精度(mean average precision,mAP)作为实验结果的评价指标,mAP值越高精确度越高,检测性能越好。计算方法为式(7)[27],AP(average precision)即PR曲线下覆盖的面积,PR曲线是以召回率(Recall,R)作为X轴,精确度(Precise,P)作为Y轴来绘制,对于连续PR曲线,式(7)中AP计算公式为式(8)
(7)

(8)
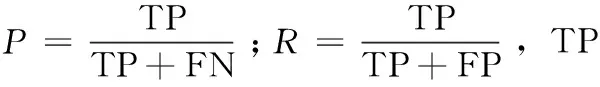
本文中多个通道之间的全连接层是共享的,与优化卷积层相似,共享全连接层是通过将基本学习速率乘以1/3来优化的。使用3个不同的结构变化进行检测时,当多通道算法没有共享层、共享fc6层和fc6&fc7层的mAP值分别为:73.5%、74.6%、72.9%。可以得出3个通道共享fc6层可以更好地提高检测性能并节省内存空间。单通道和多通道的消融对比结果见表1,可以看出即使没有扩充训练数据集,MC Faster R-CNN的检测性能也要优于单一通道网络。当多通道网络训练数据集为PASCALVOC 2007和PASCALVOC2012时相比扩充训练数据集后的Faster R-CNN平均检测精度分别提高了0.9%和2.4%。
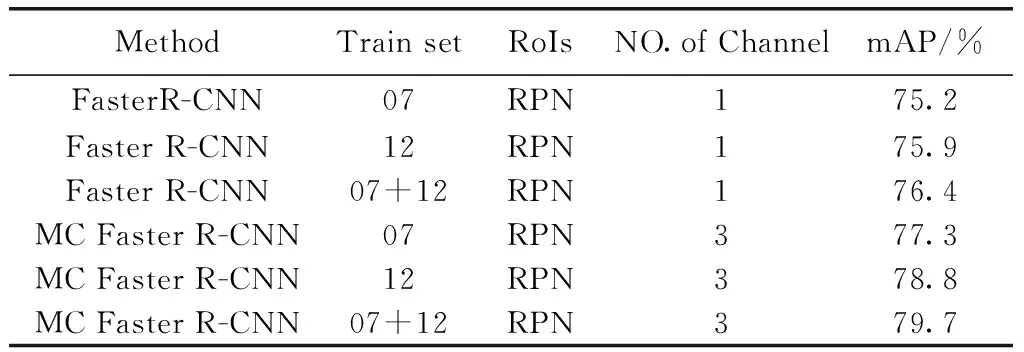
表1 单通道和多通道的消融实验结果对比
3.3 3个通道之间的比较
为了分析每个通道的综合能力,不考虑RoI形状类别的情况下使用3个通道中的一个来得到检测结果。通过实验得出由3个独立通道的均值平均检测精度值,H、S、V这3个通道均值平均检测精度分别为69.1%、75.4%、64.9%。可以看出S通道明显优于H和V通道,这与扩充训练集之后的Faster R-CNN所得到的均值平均检测精度76.4%相当。由通道分配定义式(4)可知,S通道在训练阶段不仅可以发现方形的对象,而且能分配到近似于方型的其它两类形状目标,这样S通道就会训练更多的形状类别使得它检测另外两种形状类别的对象表现较好。当在MC Faster R-CNN的统一网络设置中使用这3个通道时,均值平均精度可以提高到79.7%(见表1)。
图4显示了不同通道检测每种物体类别的均值平均检测精度。当一个物体类别包含具有特定形状类别时,负责该类别的通道将获得最佳的检测精度。例如,H通道在检测火车、公交车和飞机等水平拉长物体方面表现最佳,而V通道在大多为垂直拉长形状的物体类别中表现最佳,如人、瓶子和马等。S通道整体检测效果较好,因为方形通道在训练阶段得到了更丰富信息。整体看来,使用多通道检测算法检测性能表现较好。
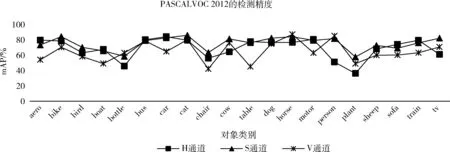
图4 不同通道检测每种物体类别的平均检测精度
3.4 定性分析
本文在实验结果中选取的数据集均为PASCALVOC2012,为了更加直观展示实验的效果,将本文算法的实验结果与两阶典型算法Faster R-CNN和一阶典型算法YOLOv3算法进行了对比,从中选取了部分代表性的结果如图5~图7所示,从图中可以看出不论是单目标图像还是多目标图像,本文提出的算法比Faster R-CNN和YOLOv3算法更有优势。具体表现为:①通过多通道算法检测可以更好的将不同形状的目标准确识别,而且在雾天或者较暗光照的情况下仍然有着很好的表现,例如图6中的飞机和轮船;②对Faster R-CNN和YOLOv3未能检测的目标,本文算法可以识别且精度都比较高,例图6中的轮船和图7的企鹅;③对同样都能识别出来的目标,本文算法的检测效果更好得分更高,该得分由式(7)计算得来,图5~图7均有体现;④对重叠度比较高的或者较小目标其准确度更高,修正了Faster R-CNN和YOLOv3算法检测时出现的漏检问题如图6中含有多个目标的人;⑤在有遮挡或目标重叠的情况下,本文算法可以准确识别,例如图6中的人、图7中的企鹅和猫。同时,相对Faster R-CNN算法,本文算法可以更好地识别不同姿态下的同一对象,比如图5中站着的人和蹲着的人,本文算法都给予很好的修正。
此外,我们将自己拍摄的图像也用3种方法进行了测试如图8所示,通过图8可以看出本文算法在检测精度上相比前两种算法有着很好的表现,例如图8中的人和马。本文算法在目标框的定位上明显优于其它对比算法且得分较高,对不同姿态同一对象的识别精度也有所提高,例如图8中荡秋千的人和正在行走的人。该算法检测的结果几乎接近Ground Truth值。对于包含较小目标且有重叠或遮挡时,改进算法同样有着很好的表现,例如图8中的出租车。

图5 对单一目标的检测结果

图6 对多目标的检测结果
3.5 定量分析
为了进一步分析本文算法的检测性能,表2展示了该算法和其它算法在PASCAL VOC2012数据集中识别20类目标的平均检测精度对比,Faster R-CNN算法和本文算法都使用ResNet-101网络,YOLOv3算法使用DarkNet网络进行检测。表2可以看出,本文算法在检测bike(自行车)、bus(公交)、person(人)等多个类别的检测精度上优于YOLOv3和Faster R-CNN,本文算法的平均精度为78.8%,比YOLOv3提高了2.9%,比同一系列Faster R-CNN算法提高了2.4%。如表3所示,本文算法在MS COCO数据集上的检测结果同样表现优越,通过表3可以看出同为ResNet-101的网络下,相比Faster R-CNN算法本文的检测精度提高了1.2%,比RetinaNet提高1.4%。网络结构同为VGG16时,本文算法精度比YoLov2提高了4.3%,比SSD提高了2.5%。综合看来该算法在精度上具有一定的优势。

图7 多种形状类别的检测结果

图8 实地拍摄图像的检测结果对比

表2 本文算法和其它算法在PASAL VOC2012 数据集上的检测结果
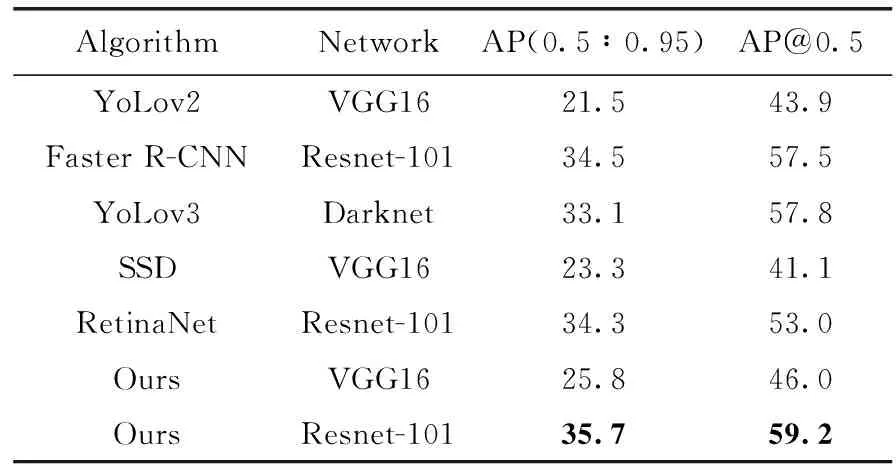
表3 本文算法和其它算法在MSCOCO 数据集上的检测结果
为了分析利用“多通道算法”的计算开销,本文将MC Faster RCNN的训练、测试时间与Faster R-CNN进行了比较,如表4所示,Faster R-CNN算法比本文算法的训练时间少用了3 h,测试时间上本文算法与Faster R-CNN算法相差仅为0.006 s。所以尽管MC Faster R-CNN比Faster R-CNN需要更多的时间进行训练,但使用多通道算法进行测试所需时间与Faster R-CNN算法相当。

表4 训练和测试Faster R-CNN和 MC Faster R-CNN的时间开销
4 结束语
本文提出一种多通道检测算法并通过大量的实验验证了它的有效性,解决了其它算法存在的误检和漏检问题,当目标都能被检测出来时多通道检测算法相比其它算法检测性能更好。在RoI生成方面的改进使得目标定位更加准确得分更高,同时对于光照不好和雾天情况下有着很好的边框修正效果。在PASCALVOC2012数据集和MS COCO数据集以及自己拍摄的图像上通过实验得出无论是在时间还是精度上所提算法都较Faster R-CNN算法有所提升的结论。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25 07:43:16
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
新世纪智能(英语备考)(2018年11期)2018-12-29 10:56:52
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小学生学习指导(低年级)(2016年10期)2016-12-01 06:10:42
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电视技术(2014年19期)2014-03-11 15:38:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
