
基于FA-TR模型的中文文本摘要生成
2021-12-23 04:34:56李大舟孟智慧
计算机工程与设计 2021年12期
高 巍,马 辉+,李大舟,于 沛,孟智慧
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.中国移动通信集团设计院有限公司 河北分公司,山西 太原 030000)
0 引 言
自动文摘技术[1]可以通过计算机对文本信息进行压缩得到简短的句子或者短文,对比人工生成摘,很大程度上节约了时间和人力。目前生成式摘要模型在生成摘要时会出现事实性错误,事实性错误是指摘要有时歪曲或捏造文本事实的问题,现有的摘要模型大多采用条件语言模型,只关注摘要的字符级准确性,忽略了摘要与文章语义级的一致性。通过研究[2]发现基于神经网络生成的摘要中有30%会出现与原文内容不相符的现象[3],例如,由于主语和谓语宾语搭配不当的问题而存在捏造事实的现象。并且,事实描述的单词比源文的其它单词多40%的可能性出现在文本摘要中,这表明了事实描述在很大程度上真正浓缩了句子的语义。因此,认为一个完整的生成式摘要模型必须具备事实性知识,才能准确地总结文章。
1 相关研究
近年来,生成式摘要模型大多都是基于序列到序列框架[4]进行研究。Chopra等[5]将注意力机制(Attention)融入到基于卷积神经网络和长短期记忆网络的序列到序列模型中,通过加入注意力机制对中间语义信息重新进行编码,将上一时刻解码器的输出与中间语义信息重新计算权重后输入到解码器中,从而编码出更为完善的语义信息。Nallapati等[6]对关键词建模获得层次结构,融入命名实体等特征来提升模型效果,在解码端引入指针机制解决未登录词问题,解决了编码不充分和解码信息不完整、重复等问题。Zeng等[7]通过循环神经网络先对源文本进行编码获得全文的语义信息,以此达到人工生成摘要时先通读原文获取原文主题信息的目的。Zhou等[8]采用选择性编码模型实现解码过程中有针对性读取源文本的目的,模型采用门控循环神经网络对输入向量的隐层重新计算权重选出文本中比较重要的部分。Li等[9]通过融入外部语义信息的方法将额外信息融入到解码器中提高生成摘要的质量。Amplayo等[10]研究指出先验知识可以更好的帮助模型理解源文本,通过识别文本主题提高解码质量。Cao等[11]从文本中提取关系信息,并将其映射到序列中,作为对编码器的额外输入。Xie等[12]提出了一个基于双重注意力机制的序列到序列模型,采用句子排序算法提取文本的事实关系,将提取到的事实关系与源文向量相结合,解决事实性错误。谷歌团队[13]提出Transformer模型,该模型完全采用Attention机制构成,摒弃了CNN和RNN等网络结构。Transformer模型改善了RNN网络不能并行计算的能力,解决了CNN网络在计算两个位置之间的关联时所需要的操作次数随距离增长而增多的缺点。王侃等[14]在文本预处理阶段引入先验知识到Transformer模型中,采用ELMo(embeddings from language models)动态词向量作为训练文本的词表征,解决了生成的摘要存在不通顺、准确率较低的问题。Gunel等[15]使用实体感知的transformer结构来提高生成式摘要中的事实正确性,采用Wikidata知识图提取实体。
以上工作通过增强编解码能力有效提高了生成的摘要质量,这些研究在自动摘要领域已取得了很好的成果。然而,这些模型存在生成摘要与源文信息事实不一致的现象。针对生成的摘要出现事实性错误的问题,本文提出将事实感知融入到Transformer模型的FA-TR模型。FA-TR模型提取出文本的事实性信息作为特征向量融入到Transformer模型中,通过基于大规模中文短文本数据集LCSTS[16]进行实验,结果表明该模型减少了与事实不符的假摘要并提高了生成摘要的质量。
2 基于事实感知的FA-TR模型的构建
FA-TR是基于Transformer框架构建的模型,将源文本输入该模型后,输出是目标摘要。FA-TR模型由堆叠的编码器和解码器连接而成,将源文本输入到模型后,得到上下文语义向量,再经解码器解码得到目标摘要,FA-TR模型的宏观图如图1所示。
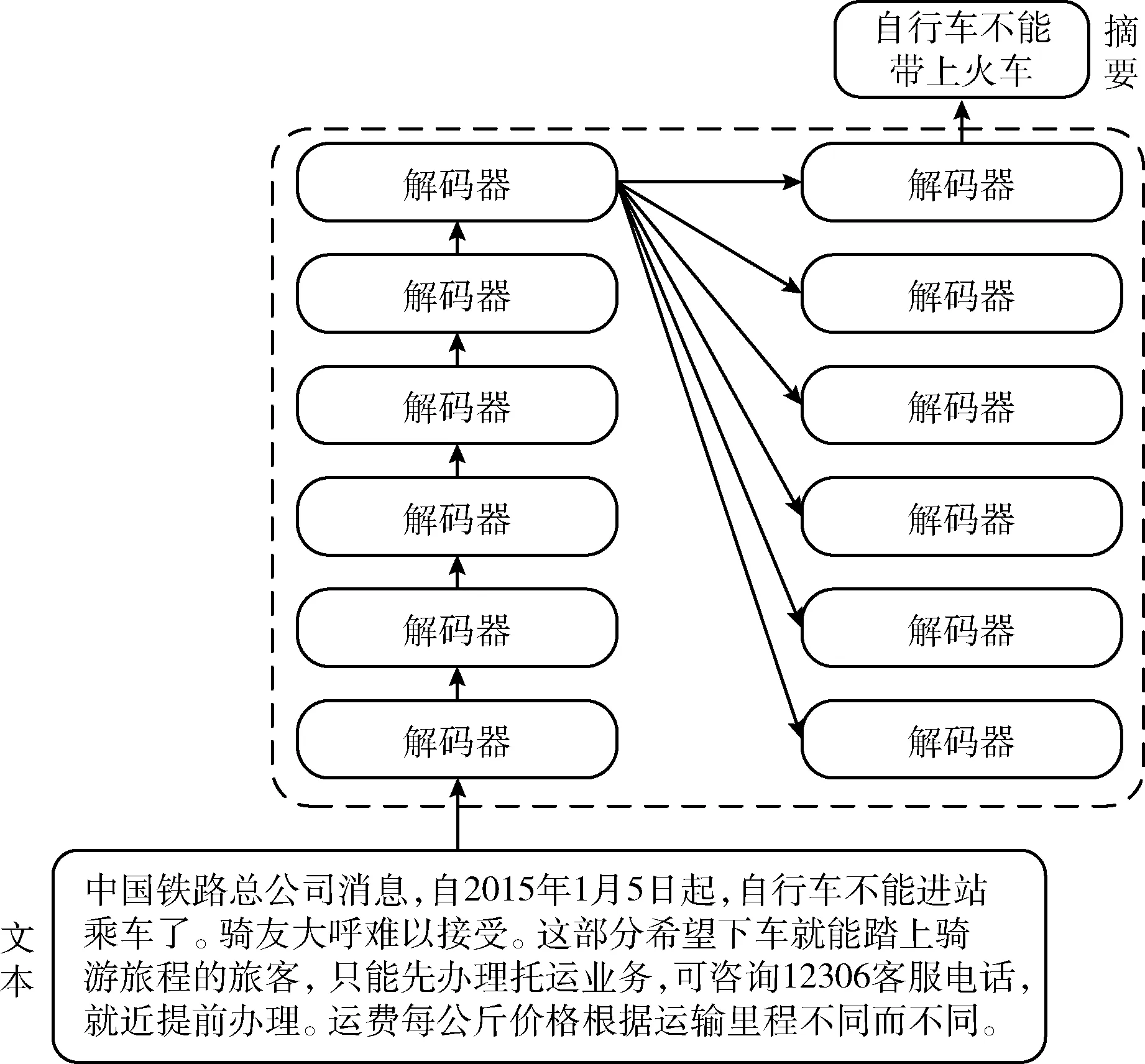
图1 FA-TR模型宏观图
FA-TR模型分为3部分,分别是输入层、编码器层和解码器层。首先,构建FA-TR模型的输入层。提取文本的事实感知并建立对应的分布式向量表示,将事实性描述特征向量与源文本的分布式向量融合在一起后,再加入位置编码得到输入序列的最终向量表示。其次,将由输入层构建的含有事实性和位置信息的文本向量输入到编码器中进行编码,编码器部分包含6个小的编码器,每个小编码器的输入是上一个小编码器的输出。最后,解码器部分包含6个小的解码器,每个小的编码器输入不仅包含上一个小解码器的输出还包含编码器部分的输出以及位置编码。FA-TR模型整体框架如图2所示。
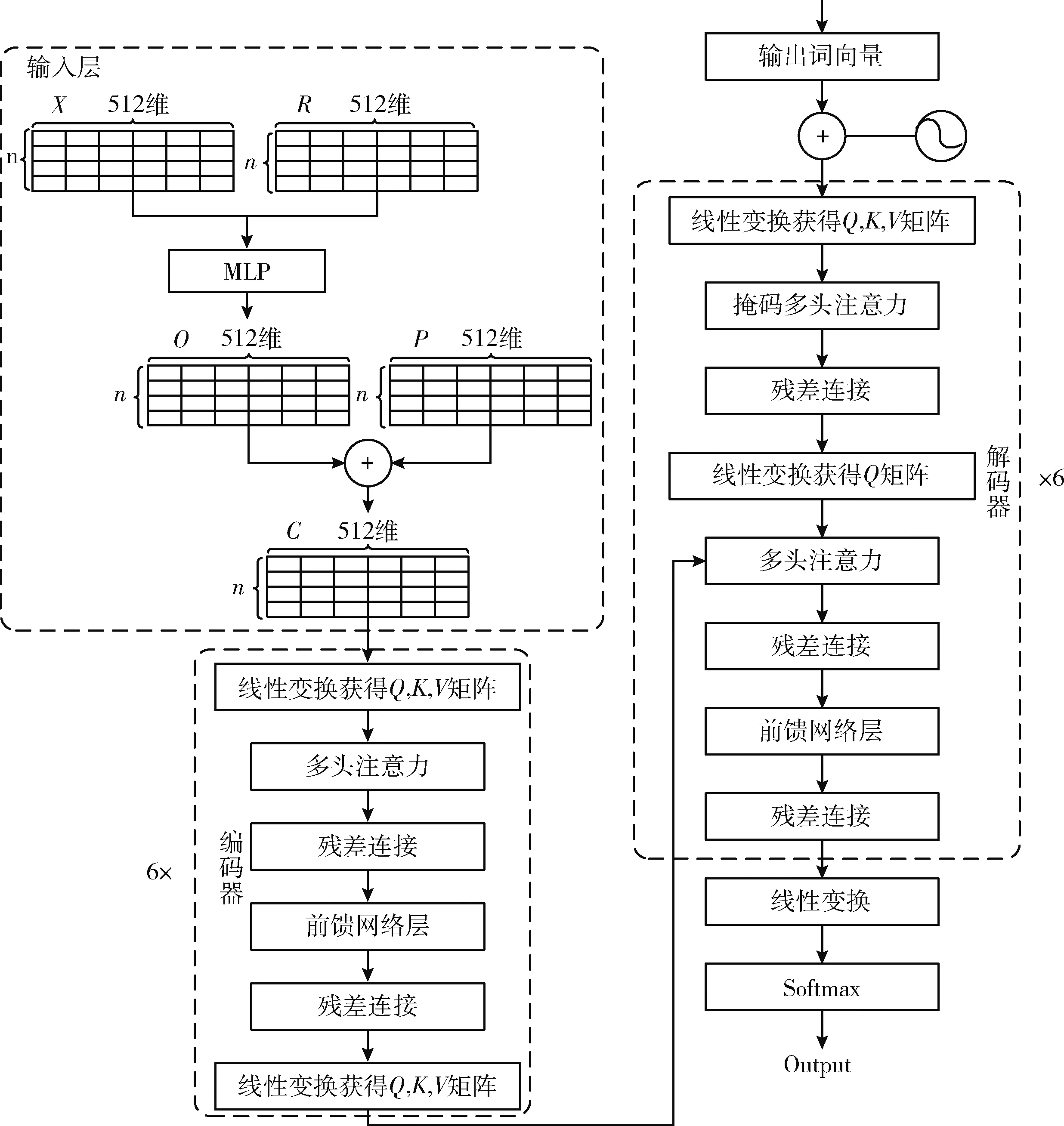
图2 FA-TR模型整体框架
2.1 构建事实感知
为了让模型能够感知事实,需要从从源文本中提取、表示和集成事实知识到摘要生成过程中。本文采用开放信息抽取工具(open information extraction,OpenIE)抽取出原文的事实。OpenIE[17]是由斯坦福大学提出的,它可以从文本中提取结构化关系元组。首先,OpenIE可以从每一个句子中提取出一对三元组(主语,谓语,宾语),那么一篇文章就会得到一系列的三元组;其次,将每一对三元组信息转换成文本表示“主语+谓语+宾语”,这段文本就是该三元组的事实描述;最后,我们使用标识符“|||”将所有事实描述拼接起来得到该文章的事实描述。一个句子可以提取多组元组来表示该句子的事实性,见表1。

表1 不同粒度下的句子元组表示
从表1可以看出,一个句子在不同的粒度下会有不同的元组表示相同事实,为了去除冗余和保证事实的完整性,如果一个元组关系的所有单词都被另一个元组关系的单词覆盖,则删掉这个元组。对于一段文本,“我们安静地坐在山顶上,我看见一轮红红的太阳从海平面升起。”用标识符“|||”将事实性描述拼接在一起,可表示为“我坐在山顶上|||我看见太阳从海平面升起”。
2.2 位置编码
在自然语言处理领域,词语在句子中的位置不仅表述一个句子的语法结构是否合理,更是表达句子语义的重要概念。词语在句子中的排列顺序不同,整个句子的语义也有所不同。FA-TR模型采用注意力机制取代传统自动摘要模型中的序列学习等基本模型,因此FA-TR模型失去了词序信息,无法确定词语在文本中的相对位置和绝对位置。为了解决这一问题,在FA-TR模型中添加位置编码来达到具备学习词序信息的能力。位置编码根据词的位置信息对文本序列信息中的每个词进行二次表示,再将得到的词序信息与文本词向量结合在一起生成新的包含位置信息的输入序列。
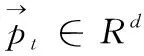
(1)
(2)
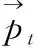

表2 位置编码
2.3 构建输入层
FA-TR模型的输入层由3部分构成,分别是原文编码、事实描述编码和位置编码。用X{x1,x2,…,xn} 表示原文词向量,词向量维度为m(本文m为512)。用R{r1,r2,…,rn} 表示事实描述词向量,用P{p1,p2,…,pn} 表示位置向量。
首先,将原文词向量和事实描述词向量联合在一起。采用多层感知机(Muti-Layer Perception,MLP)将两个词向量加权求和结合在一起,计算过程如式(3)~式(4)所示
gt=MLP(xt,rt)
(3)
ot=gt⊙xt+(1-gt)⊙rt
(4)
MLP将两个词向量压缩为一个特征向量gt, 符号⊙表示对应元素相乘,ot表示最后得到的含有事实描述的文本向量。其次,将含有事实性描述的文本向量与位置向量结合在一起作为输入层的最终输入向量。采用加权求和的方式求取最终特征向量,计算过程如式(5)所示
ct=ot⊕pt
(5)
符号⊕代表向量相加,ct为包含了位置信息的含有事实性描述的文本特征向量,得到最终的输入向量C{c1,c2,…,cn}。
2.4 FA-TR模型的编码器
将输入层得到的文本向量输入到编码器中。编码器部分由N个小的编码器栈式堆叠而成,本文的N取值为6。每个小的编码器由多头自注意力机制和前馈神经网络两部分组成。文本向量输入到多头注意力机制后得到含有上下文语义信息的向量,再将上下文语义向量与文本向量归一化后作为前馈神经网络的输入,前馈神经网络的输出是下一个编码器的输入。
2.4.1 多头注意力模型
多头注意力事实上是对h个不同且独立的单头注意力进行集成,提高了模型可以共同注意来自不同位置的不同表示子空间信息的性能,本文h取值为8。多头注意力在扩展模型关注不同位置能力的同时也防止了模型过拟合,单头注意力机制计算过程如图3所示。

图3 单头注意力计算过程
构建单头自注意力机制。首先,对于输入序列C{c1,c2,…,cn}, 分别乘以3个不同权重矩阵Wq,Wk,Wv来捕捉更丰富的特征,得到3个不同的矩阵Q,K,V这3个权重矩阵是随机初始化权重方阵。如式(6)~式(8)所示
Q=[c1,c2,…,cn]T·Wq
(6)
K=[c1,c2,…,cn]T·Wk
(7)
V=[c1,c2,…,cn]T·Wv
(8)
则整个输入序列得到Q(q1,q2,…,qn),K(k1,k2,…,kn),V(v1,v2,…,vn)。 其次,计算自注意力向量,自注意力分数是Q与各个词向量的K点积的结果,再将结果分别除以K向量维度的平方根让梯度更加稳定。过程如式(9)所示
(9)
得到注意力得分后,对得分矩阵进行softmax运算将分数标准化,得到n×n的权重矩阵A, 计算过程如式(10)所示
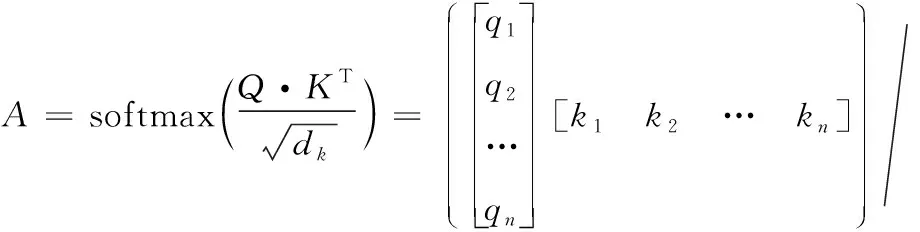
(10)
其次,为了保持想要关注的单词的值不变,需要掩盖掉不相关的单词。将向量V与权重矩阵A相乘得到特征矩阵Z, 计算过程如式(11)所示
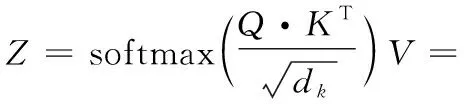
(11)
最后,计算多头注意力机制。多头注意力机制是多个单头自注意力机制的集成,FA-TR模型使用8个注意力头,则需要8次不同的权重矩阵运算得到8个不同的特征矩阵Z。8个不同的权重矩阵都采用随机初始化得到,多头注意力机制的运算过程如式(12)所示
(12)
MultiHead(Q,K,V)=Concat(head1,head2,…,head8)WO
(13)
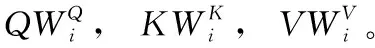
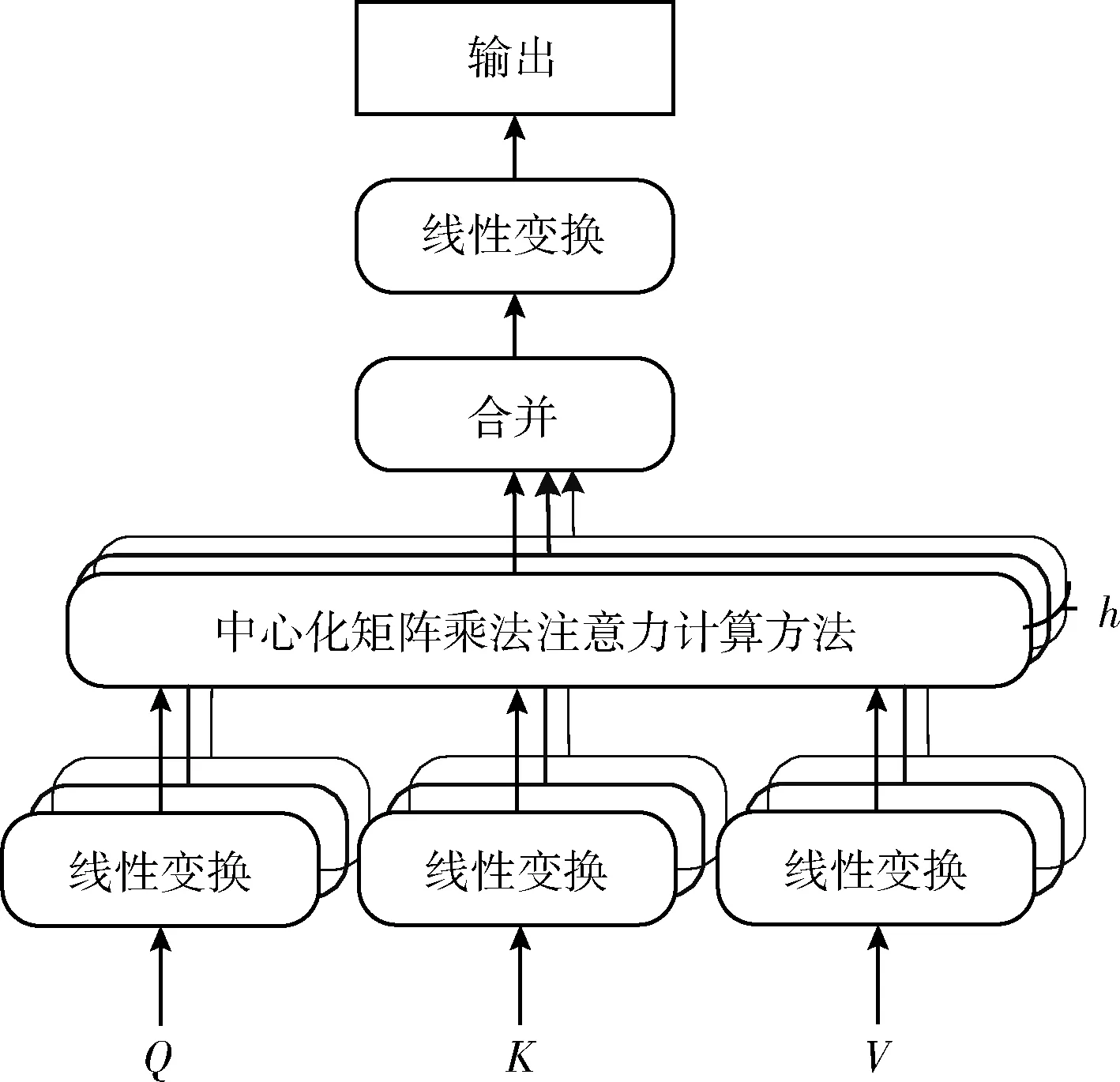
图4 多头注意力计算过程
2.4.2 前馈神经网络
前馈神经网络的输入是多头注意力模型得到的最终输出矩阵Z。前馈神经网络有两层,第一层的激活函数是Relu,第二层是线性激活函数,线性函数的公式如式(14)所示
FFN(Z)=max(0,ZW1+b1)W2+b2
(14)
其中,W1和W2是可学习的权重矩阵,b1和b2是随机偏置矩阵。
2.5 FA-TR模型的解码器
FA-TR模型的解码器同编码器一样由N个小的解码器栈式堆叠而成,本文的N取值为6,每个小的解码器由掩码多头自注意力层、编码-解码注意力层和前馈神经网络层这3层构成。解码器每个时间步都会输出一个输出序列的元素,直到解码到一个特殊的终止符号或者达到设置的摘要长度。
掩码多头自注意力层的输入是目标序列,并添加位置编码来表示每个单词的位置。掩码多头自注意力对后文进行遮挡,如预测t时刻的元素,则只能对t-1时刻及以前的元素进行Attention计算来求解,将计算结果输入到编码-解码注意力层。
编码-解码注意力层的输入由两部分构成,分别是编码器的输出和掩码多头自注意力的输出。编码器的输出作为K、V矩阵,掩码多头自注意力的输出作为Q矩阵,对这3个矩阵进行Attention运算,得到的输出结果输入到前馈神经网络层。
前馈神经网络层的输入为编码-解码注意力层的输出,计算过程同编码器的前馈神经网络层。前馈神经网络层的输出经线性变换投射到对数几率的向量里,再经过softmax层将得到的分数变为生成每个词语的概率,选取概率最高单元格所对应的词语作为该时间步的输出。
3 实验与分析
3.1 数据集
本文采用从新浪微博获取的新闻摘要数据集LCSTS,该数据集是由B.Hu收集整理得到的大规模、高质量的中文短文本数据集。该数据集共有200多万个新闻-摘要数据对,并分为3部分,见表3。
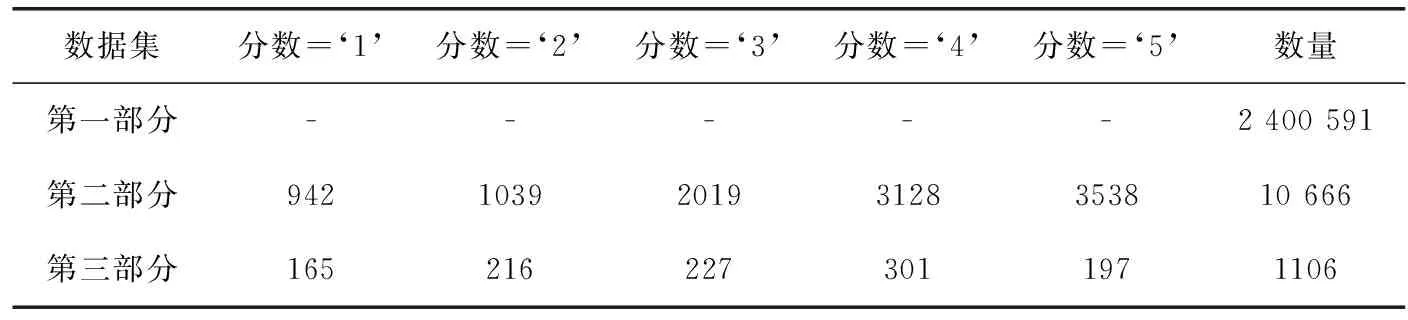
表3 LCSTS数据集介绍
第一部分数据是数据集的主要部分用来训练本文的生成摘要模型,这一部分没有对其进行打分,所以用“-”符号表示;第二部分是人工标注摘要,从第一部分数据集中随机抽取10 666个新闻-摘要数据对,并对每个样本进行打分,分数为‘1’的样本代表摘要和源文本的相关性最弱,分数为‘5’代表相关性最强;第三部分数据独立于第一部分和第二部分由3个人同时对1106个新闻-数据对进行打分,作为本文的测试集。
3.2 评价指标
评价指标采用自动文摘评价方法ROUGE进行评价。ROUGE基于面向N元词汇召回率的方法,统计生成摘要与参考摘要的N元词(N-gram)的共现信息对模型进行评价。ROUGE包括ROUGE-N(N=1,2,3,4等自然数)和ROUGE-L等一系列评价准则,其中的N代表N元词,L代表最长公共子序列。如式(15)~式(18)
(15)
(16)
(17)
(18)
本文选择ROUGE-N(N=1,2) 和ROUGE-L作为本文的评价指标,公式中的X表示生成摘要,Y表示参考摘要,Cmatch(N-gram) 表示生成摘要与参考摘要相匹配的N-gram 个数。Rlcs表示召回率,Plcs表示准确率, LCS(X,Y) 表示生成摘要与参考摘要的最长公共子序列的长度,len(m) 和len(n) 分别表示参考摘要和生成摘要的长度。
3.3 实验环境与参数设置
本文实验环境见表4。
表4 实验环境
本文参数设置见表5。
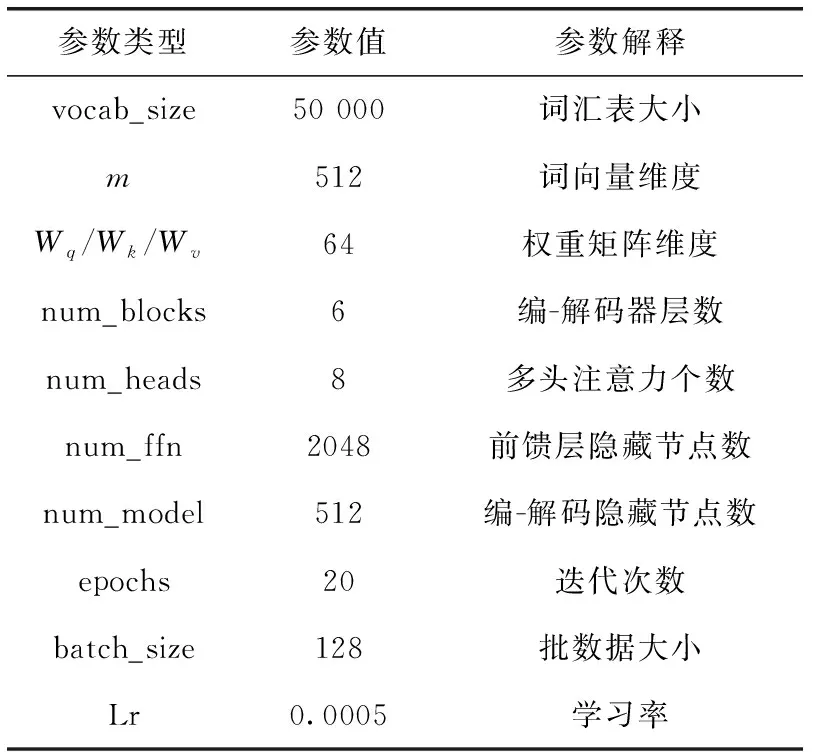
表5 参数设置
3.4 实验过程与结果分析
本文FA-TR模型的输入是文本,输出是文本摘要。将LCSTS短文本数据集的第一部分作为模型的训练集,第三部分作为模型的测试集。首先,清洗数据集,将文本切分成词,本文采用Word2vec预训练模型将分词表示成分布式向量;其次,将融合了事实感知和位置编码的文本向量作为FA-TR模型的编码器输入;最后,编码器的输出作为解码器的输入,解码器的输入还包括上一个解码器的输出和位置编码,获得到解码器的输出文本摘要。该模型的训练集迭代次数与测试集的迭代次数与损失值变化关系如图5所示。
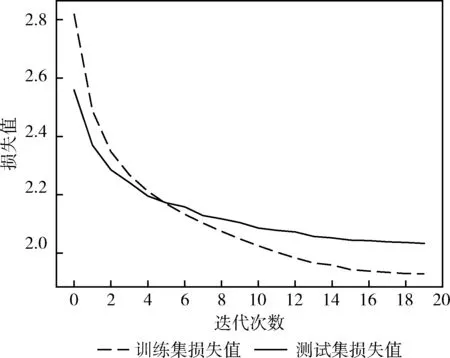
图5 FA-TR模型训练集与测试集损失值变化关系
为了验证本模型的有效性,本文从近年相关工作中选取4种具有代表性的基线模型与本模型进行对比与分析。分别是采用融入了注意力机制的序列到序列模型,编码器采用卷积神经网络,解码器采用神经网络语言模型的ABS模型[1]、在ABS基础上加入了一些人工特征,采用循环神经网络作为编解码器的ABS+模型[2]、以序列到序列模型为基础框架,加入一些特征来加强编码,引入指针机制提高解码能力的Feats2s模型[3]、以Transformer为框架,在文本预处理阶段引入先验知识的DWEM模型[11]。本文模型与其它4个模型的实验结果评分见表6。

表6 不同模型实验结果
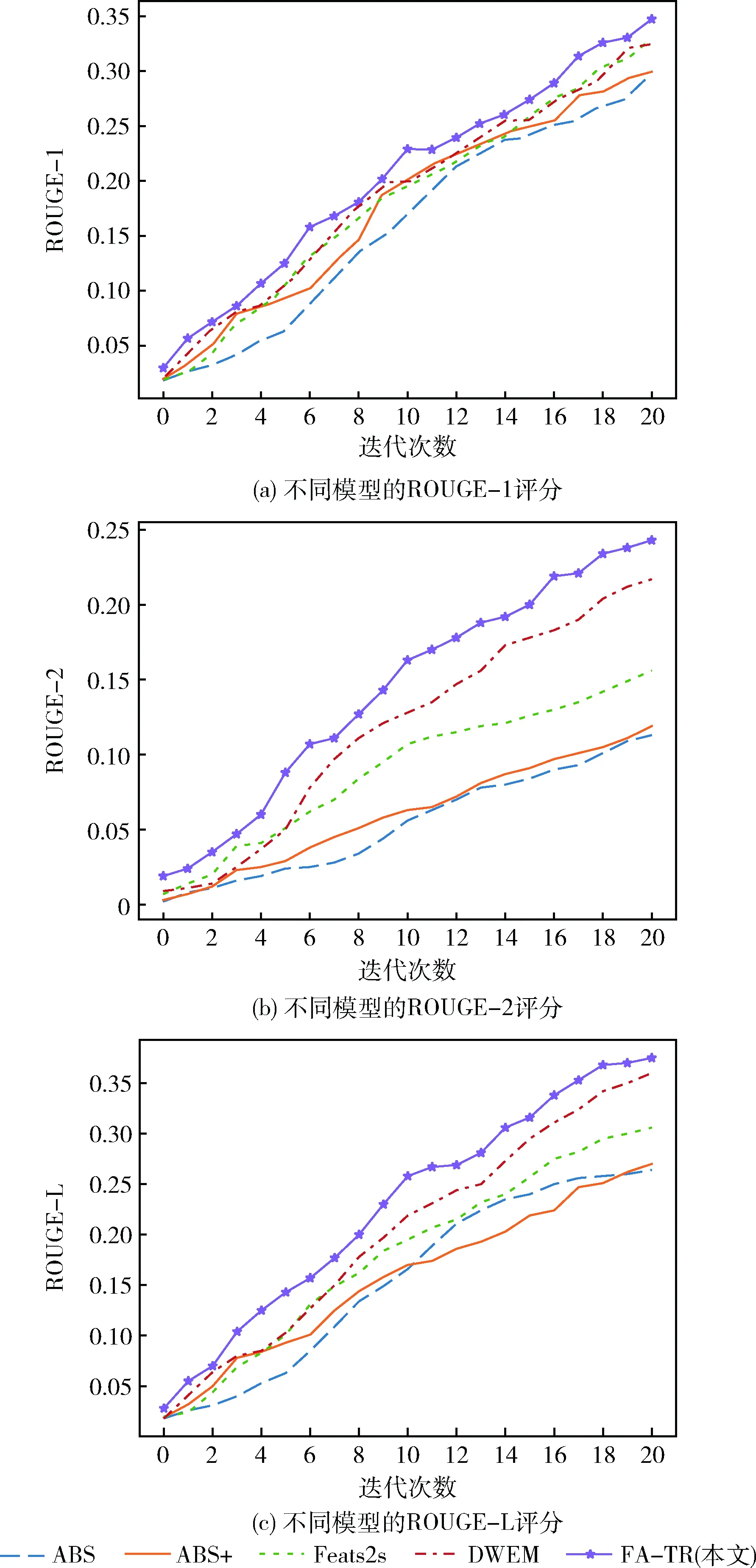
图6 不同模型的ROUGE评分
从表6和图6中可以看出,FA-TR模型虽然以抽取源文本事实性为目的来解决捏造事实的问题,但是本模型的ROUGE评分对比其余4个模型都有所提高,这是因为提取的事实描述本身已经是一个适当的总结。为了能够更加直观说明本模型的有效性,从测试集中抽取了本模型与其它4种模型所生成的摘要实例,表7展示了各个模型在LCSTS数据集上生成的摘要结果,其它4种模型生成的摘要,虽然在内容上与源文本的非常相似,但是并没有表达出源文本的关键信息,而且还出现了事实性错误。FA-TR模型能够较为完整表达出源文本的主要信息,而且更贴近原文事实,其生成的摘要与标准摘要更加具有可比性。可见生成的摘要效果更好,从而验证了FA-TR模型的有效性。
4 结束语
本文对生成式文本摘要方法进行研究,提出了将事实感知融入到Transformer模型中的FA-TR模型,解决了传统生成式摘要模型生成的摘要存在捏造事实的问题,同时也改善了长期依赖不能并行处理语义信息的问题。基于LCSTS数据集的实验结果表明,本模型获得的摘要更符合源文本信息,而且,由于事实描述通常浓缩了句子的语义,融入事实感知也带来了摘要质量的显著提高。但是,目前没有一种好的方法来自动评估文章的事实性,只能通过人工的方法进行评测,所以接下来会对如何评价摘要的事实准确性进行研究。

表7 各个模型摘要生成结果
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
传媒评论(2017年3期)2017-06-13 09:18:10
电子设计工程(2017年20期)2017-02-10 03:39:29
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电子器件(2015年5期)2015-12-29 08:42:24
