
民航旅客不文明行为信息自动匹配方法
2021-12-23 04:34曹卫东
计算机工程与设计 2021年12期
曹卫东,高 德
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
文本相似度计算是众多文本处理任务中的基础,按照理解层次不同,可将其分为基于字面匹配和基于语义计算两种方法。相比之下,基于语义的文本相似度算法更加符合人类大脑的认知规律,更能反映文本的真实含义。近年来,民航旅客的不文明行为呈多元化趋势,包括辱骂机组人员、不配合安检、强闯隔离栏、偷拿航班上的救险物资等。
研究民航旅客不文明行为信息与规则的自动匹配对提升民航运输的安全和效率具有重要意义。研究民航旅客不文明行为信息与规则自动匹配的核心任务是研究文本相似度计算。
民航旅客不文明行为信息与规则自动匹配是一种特定领域的文本相似度计算。主要任务是从非结构化的民航不文明行为信息文本数据中计算出其语义信息,目的是将其语义信息与已有的规则进行匹配,便于完成不文明旅客信息的分类以及对不文明旅客的处罚。目前,民航旅客不文明行为信息与规则自动匹配主要有两个难点:一是由于涉及到特殊领域,基于传统的统计机器学习的文本相似度计算往往依赖领域语言学知识和大量的人工定义特征。二是该领域文本长短不一,有的上百字,有的只有十几个字,难以使用传统的网络结构捕获此类文本中的完整语义。
基于语义的文本相似度算法使用深度学习技术避免大量使用人工进行特征选取。目前,深度学习技术已广泛应用于情感分析、阅读理解[1]、自动问答[2]、机器翻译[3]等任务。主流神经网络模型主要包括CNN和RNN及二者的多种变体,其中卷积神经网络在池化层提取文本特征时会过滤掉一些信息。Sabour等[4]提出用一种矢量胶囊来替代传统标量神经元,即胶囊网络(capsule network)解决CNN池化层存在的问题。
1 相关研究
早期的文本相似度计算都是基于文本字符串,然后通过距离公式直接计算的。例如使用编辑距离、jaccard距离[5]和信息熵[6]。但这些方法都有很大的局限性,同一个词在不同的语境下可能代表不同的含义。例如“小米”既可以表示一种谷物,也可以表示一家科技公司。同理,相同的含义也可由不同的词表达,例如“工资”和“薪水”就可以表示同一含义。
除了基于文本字符串这种简单直接的计算方式,还有学者提出了一些基于语料库的文本相似度计算方法。词袋模型(bag of words model,BOW)认为文本所处的上下文语境相似,那么其于语义也相同。词袋模型简单的以文本出现的频率为指标来衡量文本的相似程度,这使得句子中一些无用但出现频率高的词成为了计算相似度的绊脚石。因此,有学者提出了词频-逆文档频率(term frequency-inverse document frequency,TF-IDF),该模型使得词语的重要性随着它在特定文本中出现的次数正比增加,但也会随着它在整个语料库中出现的频率反比下降,这是对词袋模型的改进。除了基于语料库的计算方法,还有基于知识库的方法研究,其中最主要的就是WordNet、《知网》(HowNet)和《同义词词林》以及维基百科、百度百科等。可利用知识库中的组织形式,如概念间的同义反义关系进行相似度计算。
近年来,神经网络已被广泛用于文本相似度计算中,它能自动的从原始数据中提取文本特征,在很大程度提高了文本相似度计算的性能。如深度语义匹配模型(deep structured semantic models,DSSM)、树形长短时记忆网络(tree-structured long short-term memory networks,Tree-LSTM)、孪生长短时记忆网络(Siamese LSTM)和ConvNet[7-10]都是在对词语或者句子进行建模的基础上得到词向量或者句子向量,再使用距离公式进行相似度计算。
因此,利用神经网络进行文本相似度计算一般有两种思路。一是直接得到句子向量,如Ryan Kiros等[11]通过word2vec的跳字模型(skip-gram),通过一句话直接预测其前一句和后一句话。二是从词的角度出发,先得到每个词的向量表示,然后再用词向量组合出整个句子的向量表示。如Kusner等[12]先得到词的向量表示,然后最小化两个句子中词向量的全局距离,再使用经验模态分解算法来计算句子的相似度;Arora等[13]也是先得到词的向量表示,再通过加权平均的方法得到句子向量,同时采用奇异值分解和主成分分析方法进行修正,取得了较好的效果。
本文采用胶囊网络、门控循环单元(gated recurrent unit,GRU)进行文本相似度研究,胶囊网络可以更充分提取文本局部特征信息,减少传统卷积神经网络在最大池化过程中的信息损失,门控循环单元解决了传统神经网络因无法捕获长距离信息而导致的梯度消失问题,可以更好地捕获文本的全局特征。将二者融合成gru-capsule组合模型进行实验,可以获取更充分的文本特征信息,再结合距离公式,从而提高相似度计算效果。
2 组合式深度学习模型
基于胶囊网络组合模型的文本相似度计算框架如图1所示,其中句子一和句子二分别经过相同的网络结构来提取文本特征,从而进行相似度的计算。本文提出的模型包括以下4个部分:向量表示、特征提取、相似度计算以及文本分类。
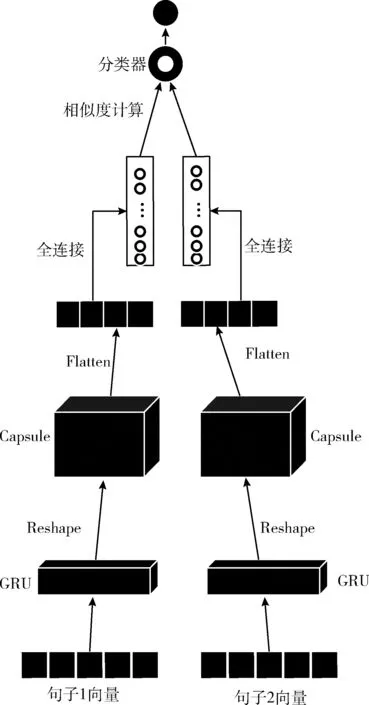
图1 集成模型框架
(1)向量表示:将文本信息向量化是自然语言处理中的一项基本任务,词向量(word embedding)一词最早由Hinton于十九世纪八十年代提出。其中经典的方法有one-hot编码,但其采用的数据稀疏存储方式在构建语言模型时会造成维数灾难,向量的表示也很难体现出两个词之间的关系。word2vec使用3层神经网络通过Embedding层将one-hot编码转化为低维度的稠密向量,使得含义相近的词语映射到词向量空间中相近的位置,解决了one-hot编码的维数灾难和词语鸿沟问题。本文使用预训练的word2vec,将原始文本序列映射为300维的词向量矩阵。
(2)特征提取:将上述词向量矩阵作为门控循环单元的输入,再将其输出矩阵经过形状变换(reshape)后作为胶囊层的输入,其中胶囊层有16维,每一维有10个胶囊,动态路由的次数是3次。经过这一系列操作,就可以提取到较充分的文本特征信息。
(3)相似度计算:一般的距离公式有欧氏距离、jaccard距离、编辑距离和余弦相似度(cosine similarity)等,前三者比较适合于标量的计算,而余弦相似度更适合做向量的计算,神经网络中的数字传递使用向量形式。本文通过一层全连接层提取到句子一和句子二的文本特征向量,再使用余弦相似度进行计算。
(4)文本分类:文本分类一般分为二分类、多分类和多标签分类。二分类输出层激活函数一般采用sigmoid,多分类采用softmax,多标签分类也采用sigmoid,其实多标签分类的本质就是作用在每个标签上的二分类问题。由于文中数据集都是单标签数据集,并且是二分类问题,所以输出层使用sigmoid分类器。
2.1 门控循环单元
门控循环单元属于循环神经网络的一种,其采用两个门控取代长短时记忆(long short term memory,LSTM)网络的3个门控,减少了模型训练参数,提升了训练效率,同时GRU解决了传统循环神经网络因无法捕获长距离依赖信息而导致的梯度消失问题,并且在数据较少的情况下的性能表现良好。门控循环单元结构如图2所示。
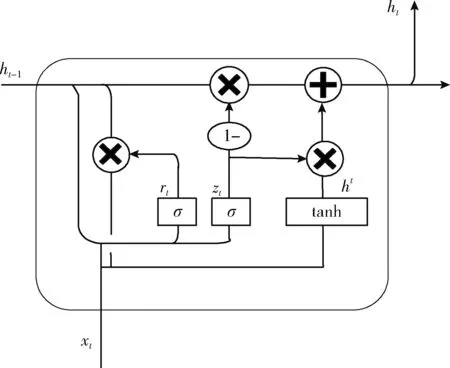
图2 门控循环单元结构
为了保持较远距离的信息传递,为了保持较远距离的信息传递,GRU采用两个门控。分别是重置门rt和更新门zt。如图2所示,重置门是第一个门控,其作用是将xt和ht-1中的部分信息组合起来影响ht。ht-1和xt先经过一次线性变换,再相加输入σ激活函数,再输出激活值。重置门的计算公式为
rt=σ(Wrxt+Urht-1+br)
(1)
式中:Wr代表重置门输入变量的权值矩阵,Ur代表重置门隐藏状态的权值矩阵,br是重置门的偏置矩阵,σ代表sigmoid激活函数。ht的计算公式为
ht=tanh(Whxt+rt·(Uhht-1)+bh)
(2)
式中:Wh、Uh和bh的含义同上式,tanh是激活函数。
GRU第二个门控是更新门,决定“遗忘”ht-1中多少信息,以及“记忆”ht中多少信息,计算公式为
zt=σ(Wzxt+Uzht-1+bz)
(3)
式中:xt是第t个时间步的输入向量,xt与ht-1分别经过一次线性变换,相加后输入σ激活函数,再输出激活值,Wz代表更新门的输入变量权值矩阵,Uz代表更新门的隐藏状态权值矩阵。由以上公式可知:重置门和更新门都由xt和ht-1决定。最后,GRU单元当前时刻隐藏状态的值ht可以表示为
ht=(1-zt)·ht-1+zt·ht
(4)
通过这种门控机制,GRU解决了序列信息的长期依赖问题。
2.2 胶囊网络
传统卷积神经网络通过卷积操作来处理文本,通过控制词窗滑动和词窗的大小来获取局部的文本特征信息,再经过最大池化层进行降维,虽然最大池化层可以有效减少模型参数,在一定程度上提高训练效率,但同时也会造成一定的信息损失,因为最大池化层只关注了最重要的信息,忽略了有可能也起关键作用的其它信息。胶囊网络使用capsule的向量输出(vector)取代了传统神经元的标量输出(value),由输出向量的多个维度替代一个输出维度。神经元是侦测某一个具体模式,但是capsule是侦测某一类模式,它输出的向量的每一个维度代表该模式的特性,向量的模长代表某一类的模式是否存在。
由于文本中存在着诸多例如停留词、标点符号、特殊字符等众多与相似度计算无关的词语,下层胶囊中不可避免的会产生很多噪音胶囊,这无疑会对相似度计算产生一定的影响,而胶囊网络采用动态路由机制(dynamic routing),下层胶囊通过该机制将计算结果传给上层胶囊。与CNN的最大池化层相比,胶囊不再是简单的舍弃除某些值,而是在计算过程中为下层胶囊动态分配归一化的权重,从而有效减少信息的损失。虽然这样会增加计算量,但可以通过权值共享策略简化该过程。动态路由算法如图3所示。
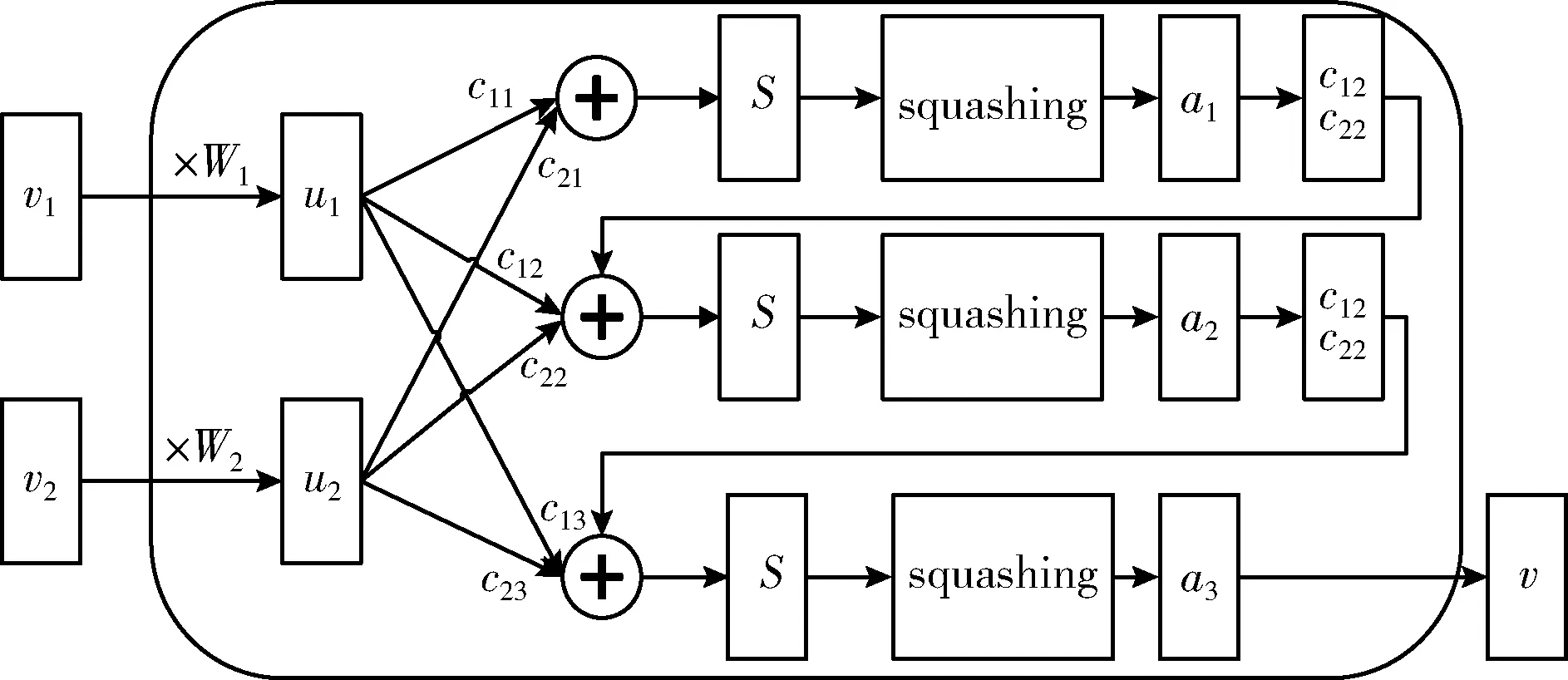
图3 动态路由过程
其中涉及的公式描述如下
ui=Wivi
(5)
(6)
(7)
其中,vi代表下层胶囊的输出,也即是当前胶囊层的输入,Wi为上下两层之间的权值矩阵,通过矩阵运算得到ui,cij是动态得到的,它决定了底层胶囊的信息有多少能传递下去,经过运算得到中间量,sj是中间量,它通过挤压函数可以得到aj,aj将参与到bij计算,bij计算再用来更新cij,直到计算出本层的矢量输出v,其中b初始值设置为0,挤压函数squashing及更新bij的计算公式如下
(8)
bij=bij-1+uj|iaj
(9)
其中,aj代表上层胶囊的输出,胶囊输出向量的模长代表类别的概率值大小,bij-1代表上一轮动态路由时的b值,挤压函数只会改变sj的长度,不会改变向量的方向,从式(8)可以看出,当sj很大的时候,得到的aj就会趋向于1,当sj很小的时候,aj就会趋向于0,从而把向量的模长限定在(0,1)区间,输出向量的模长越大,代表文本所属该类的概率就越大。
2.3 模型集成
门控循环单元可以捕获较长距离的文本特征信息,胶囊网络在提取文本局部特征时可以减少卷积神经网络最大池化操作中的信息损失。本文采用的组合模型结合门控循环单元和胶囊网络各自的优势,可以多层次,全方位的提取文本的特征信息,从而提高相似度计算的效果。
3 实验与分析
3.1 实验数据
文中的实验数据是民航旅客不文明行为信息数据集、支付宝花呗借呗问答数据集和LCQMC问答数据集,第一个数据集来源于中国航空运输协会,第二个数据集来源于蚂蚁金服,最后一个是哈尔滨工业大学整理的网上的问答数据,三者都是单标签数据集。其中,每条数据都包括3部分,分别是两个句子和一个标签,标签有两个类别,即标注两个句子相似还是不相似,相似用1表示,不相似用0表示。为了验证方法的有效性,本文采用准确率(precision):所有数据中正确匹配的数据所占的比重,衡量模型的优劣。
3.1.1 民航数据集标注
两个公共数据集已经是实验需要的形式,民航旅客不文明行为信息数据集需要人工标注句子是否相似。中国航空运输协会目前公布了392条记录,按照每条都能与其它一条形成相似和不相似的情况,在经过去重复,共可得到76 636条数据,但由于人工成本较大,在保证得到的是一个平衡数据集的情况下,只随机得到3000条数据。数据标注规则如下:①行为相似的为相似,标1;②行为不相同的为不相似,标0。
标注好的数据见表1。

表1 民航数据集标注
第一组数据两个行为都是在航班上违规使用电子设备,因此相似。第二组数组虽然都没有听工作人员劝阻,但是第一个行为殴打他人,安全隐患较大,性质更加恶劣,因此二者不相似。第三组数组两个行为都是属于造谣,虽然发生地点不同,但都属于传播虚假信息,造成恶劣的影响,因此二者相似。第四组数据两个行为虽然都发生在安检时,但是明显第一个口角和肢体冲突对机场正常秩序影响更大,后者只是不配合,因此二者不相似。
3.1.2 各数据集统计
花呗借呗问答数据集一共有102 477条数据,两句子相似的数据只有18 685条,是一个不平衡的数据集,为了得到好的实验效果,对原数据集进行了筛选,对LCQMC问答数据集进行同样的操作。最终实验数据信息统计见表2。
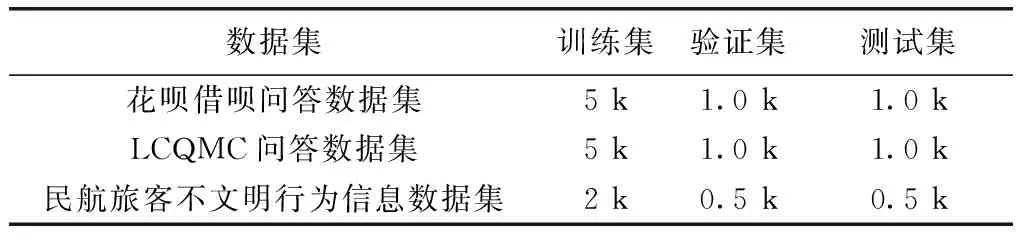
表2 数据集统计
3.2 实验参数设置
本文实验基于keras深度学习框架实现,在本实验中,为了得到相对稳定的实验结果,实验重复进行了50次。具体参数设置见表3。
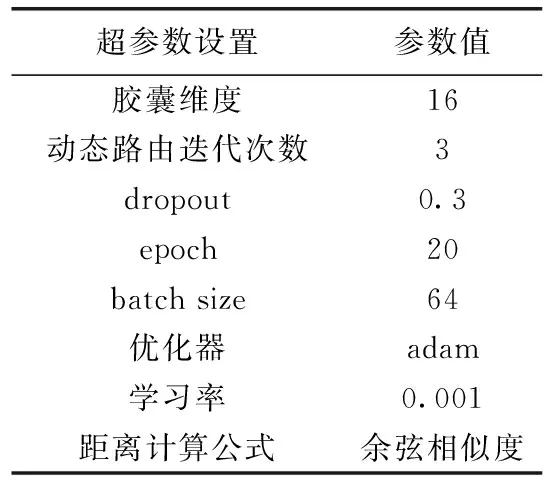
表3 实验参数设置
3.3 实验结果与分析
3.3.1 gru-capsule与其它模型的实验结果对比
为了验证文中提出的gru-capsule组合网络模型的有效性,本文在两个公共数据集和民航旅客不文明行为信息数据集上分别进行实验,且均在同一实验条件下进行,本文对比实验选取比较主流的几个基线模型:cnn、lstm、gru。另外,还将上述基线模型分别与胶囊网络集成cnn-capsule、lstm-capsule等组合模型进行实验,实验结果见表4。
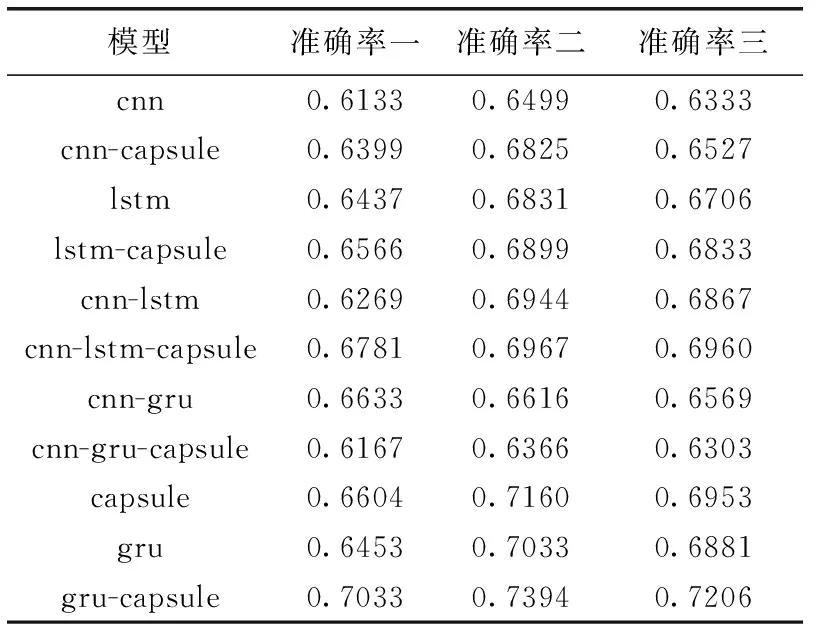
表4 准确率结果对比
其中准确率一是在花呗借呗问答数据集上的准确率,准确率二是在LCQMC问答数据集上的准确率,准确率三是在民航旅客不文明行为信息数据集上的准确率。
从表中实验结果可以看出,相比于其它基线模型,本文提出的gru-capsule组合模型在两个三个数据集上均取得了最高的准确率。其中在花呗借呗问答数据集上的准确率达到了70.33%,在LCQMC问答数据集上的准确率达到了73.94%,在民航旅客不文明行为信息数据集上也达到了72.06%。同时可以看到,由于capsule采用了动态路由机制,解决了cnn在最大池化操作中存在的信息损失问题,因此,在两个公共数据集上的准确率都有所提高,同时,在民航旅客不文明行为数据集上准确率由cnn的63.33%提高到了capsule的69.53%;
在两个公共数据集和民航数据集上,cnn-capsule的准确率相比于cnn也均有所提高,原因是数据只经过卷积层就输入胶囊网络层,并未经过最大池化操作,因此不存在池化过程中的信息损失;在花呗借呗问答数据集上lstm-capsule的准确率从lstm的64.37%提高到了65.66%,在LCQMC问答数据集上lstm-capsule的准确率从lstm的68.31%提高到了68.99%,在民航旅客不文明行为信息数据集上lstm-capsule的准确率从lstm的67.06%提高到了68.33%;相比于cnn-capsule,lstm-capsule在3个数据集上的准确率也有所提高,原因是lstm虽然训练比较耗时,但能获取序列化的文本信息,这在文本处理上非常重要;甚至在花呗借呗问答数据集上cnn-lstm-capsule模型的准确率都从cnn-lstm的62.69%提高到了67.81%,LCQMC问答数据集从69.44%提高到了69.67%,在民航旅客不文明行为信息数据集上cnn-lstm-capsule模型的准确率都从cnn-lstm的68.67%提高到了69.60%;在本文3个数据集上所有集成了胶囊网络的模型中,只有cnn-gru到cnn-gru-capsule准确率降低了,原因是随着模型深度的增加,信息经过卷积层和门控循环单元之后有所衰减,胶囊网络层不能充分利用原始文本中的有效信息。另外,从表中数据可以看出,本文实验中LCQMC问答数据集上的准确率要普遍略高于花呗借呗问答数据集和民航旅客不文明行为信息数据集,原因是后者包含很多专用词汇,给词向量的构建带来一些噪音。通过在这3个数据集上的实验结果可以验证胶囊网络在文本相似度计算领域具有很大的潜力,并且适用于民航旅客不文明行为信息这一特殊领域的数据集,同时验证了gru-capsule组合模型的有效性。
3.3.2 网络参数对模型的影响
网络参数的设置对模型的实验效果有明显的影响。针对本文民航旅客不文明行为信息数据集,本组实验采用3种优化器进行评估。分别是自适应梯度下降(adagrad)、自适应矩估计(adam)和随机梯度下降(sgd)。每个优化器分别进行了50次重复实验,实验结果如图4所示。
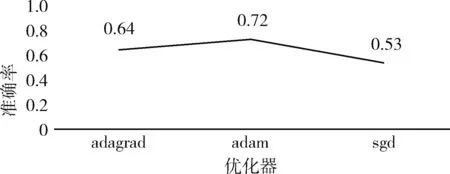
图4 不同优化器准确率比较
由图4可知,在该数据集上自适应矩估计优化器表现最好,自适应梯度下降优化器的表现也明显优于随机梯度下降优化器。相比于批量梯度下降法,虽然随机梯度下降优化器训练速度变快,但由于是随机抽取,因此不可避免产生误差,由于其随机性,可能会被困在局部极值,并且随机梯度下降优化器不能自适应学习率,因此其准确率最低。
而自适应梯度下降优化器能够实现学习率的自动更改。如果某次梯度大,那么学习速率就衰减的快一些,如果某次梯度小,那么学习速率就衰减的慢一些,因此它表现的比随机梯度下降优化器效果好。自适应矩估计优化器也是一种自适应学习率的优化器,与自适应梯度下降优化器相比,它更适合于较为稀疏的数据,民航旅客不文明信息数据集是一个比较稀疏的数据集,因此它的表现优于自适应梯度下降优化器。
虽然自适应梯度下降优化器和自适应矩估计优化器能够自适应学习率,但针对特定数据集,模型中初始学习率的设定对实验仍具有一定的影响,本组实验固定使用自适应矩估计优化器,仍在民航旅客不文明数据集上进行实验,学习率分别设置为0.0005、0.001和0.002进行实验,实验分别进行50次,每次都迭代100轮,实验结果如图5所示。
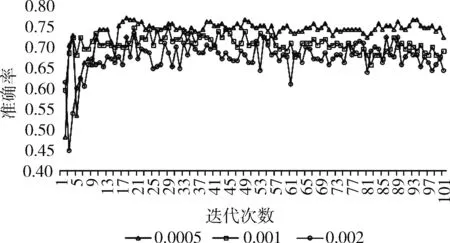
图5 不同学习率准确率比较
从实验结果可以看出,在该数据集上,当学习率设置较小的时候,模型收敛速度变慢,但是准确率有所提高,当学习率设为0.002时,准确率明显低于学习率为0.0005时,学习率设为0.001时的准确率介于二者之间。该组实验验证了在针对本文数据集使用自适应学习率优化器时,初始学习率的设置会对实验结果产生影响。
4 结束语
本文针对民航旅客不文明行为信息匹配这一特定领域的文本相似度计算任务,提出了gru-capsule组合网络模型,将其用于民航旅客不文明信息相似度的计算。该模型中的胶囊网络在提取文本特征信息的时候可以有效地减少传统卷积神经网络在池化过程中的信息损失,其中的动态路由过程可以使得重要的信息得到加强,不重要的信息给以削弱。同时使用门控循环单元解决了传统循环神经网络因无法捕获长距离依赖信息而导致的梯度消失问题。有效地提升了相似度的计算性能,提高了分类的准确率,相比于传统的网络模型,文本的语义信息也得到充分利用,在民航旅客不文明行为信息数据集上取得了较好的实验效果。另外,本文模型在计算相似度时,统一的使用了余弦距离度量,还没有将网络模型与其它距离公式结合实验。因此,作者将在本文的基础上,继续探索不同的距离算法对实验效果的影响。同时,相较于LCQMC问答数据集,在民航旅客不文明行为信息数据集上模型准确率普遍偏低的情况,将对数据集设置专用词典,进一步实验,建立一个针对民航旅客不文明行为信息数据集准确率更高的网络模型。
猜你喜欢
小哥白尼(趣味科学)(2021年3期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
中国交通信息化(2018年5期)2018-08-21
故事大王(2018年3期)2018-05-03
数学物理学报(2017年5期)2017-11-23
空中之家(2016年1期)2016-05-17
