
基于深度学习的人体行为检测方法研究综述*
2021-12-23 06:41陆卫忠宋正伟吴宏杰丁漪杰
计算机工程与科学 2021年12期
陆卫忠,宋正伟,吴宏杰,曹 燕,丁漪杰 ,张 郁
(1.苏州科技大学电子与信息工程学院,江苏 苏州 215009;2.江苏省建筑智慧节能重点实验室,江苏 苏州 215009;3.苏州工业园区工业技术学校,江苏 苏州 215123)
1 引言
随着智能监控需求的不断提高,监控设备在学校、街道等人员密集区域被广泛部署,给人们的日常生活带来了安全性保障。在视频监控的处理过程中难免会遇到一些棘手的问题,而如何在海量的视频数据中实现人体行为检测则是一个关键问题[1]。人体行为检测方法是视频理解的一项关键技术,也是近年来计算机视觉领域的一个研究热点,备受国内外学者的关注,其核心是结合人工智能技术、计算机视觉和模式识别等多领域知识实现对视频图像中人体运动的智能分析。
人体的行为检测要求对人的行为具备一定的认知与理解能力,便于检测其内在的异常事件。随着拍摄设备的智能化发展,视频图像也呈现多样化趋势。采集的行为数据中视频图像种类从黑白视频的USC行人检测USCD (USC pedestrian Detection)[2]数据集等变为手势识别数据集[3],从行为识别数据集UCF101[4]发展成携带距离信息的RGB-D数据集[5]。传统的行为检测方法大多采用人工提取特征的方法,借助检测器从视频图像中寻找兴趣点,然后针对兴趣点周边空间,利用算子进行特征建模,最后将特征输入到分类器,输出分类结果。这类方法不仅过程复杂,而且识别的准确率较低。而近年来,深度学习[6]在目标检测、语音识别等领域展现了其独特的魅力。基于深度学习的算法模型模拟人的大脑对数据进行处理,通过从低层特征到高层特征的有效行为进行特征提取来实现对视频图像中人体行为的非线性描述[7]。相较于传统的方法而言,基于深度学习的方法更适用于检测视频图像中的人体行为。此外,“智慧城市”“平安校园”等一系列的安全项目的提出以及智能产业发展政策的出台,意味着国家对公共安全及智能技术产业的高度重视,将进一步加大对智能安防领域的投资。因此,基于深度学习的人体行为检测方法的研究,不仅展现了智能安防监控在社会公共安全方面的应用价值,还有助于经济效益的提升。
本文旨在对基于深度学习方法的人体行为检测方法进行论述,文章的组织结构可分为4个部分:
(1)行为数据集:对4类常用的公开行为数据集进行简要说明。
(2)人体行为检测:总结近些年基于深度学习的人体行为检测方法的研究状况,对行为检测的基本流程进行了相关说明。
(3)基于深度学习的行为检测方法:分析了几种常用的基于深度学习的行为检测方法,如双流卷积神经网络CNN(Convolutional Neural Networks)、循环神经网络RNN(Recurrent Neural Network)和3D CNN等。
(4)研究难点与发展趋势展望:对人体行为检测及其数据采集模式的未来趋势进行了展望,同时从人的行为复杂性、检测方法的局限性等方面阐述了当前行为检测方法的研究难点。
2 行为检测数据集简介
目前,国内外有多个人体行为数据集可供科研人员下载和使用,可以更为便捷地验证相关算法的可行性。根据数据集的特点与获取方式的不同,可将常用于人体行为识别的公开数据集划分为4类:通用数据集、真实场景数据集、多视角数据集和特殊数据集。
(1)通用数据集。
通用数据集包含受试者在受限场景下的一系列简单动作,如KTH[8]和Weizman[9]数据集。其中,KTH数据集发布于2004年,提供了4类场景下受试者的6种动作:行走、跳跃、跑步、拳击、挥手和拍手,数据集由25位受试者参与,包含了599个视频,拍摄背景相对静止。Weizman数据集发布于2005年,由以色列Weizman科学研究所录制拍摄,包含了9位受试者的10种不同行为:行走、跑步、弯腰、前跳、侧身跳、原地跳、全身跳、单腿跳、挥单手和挥双手,共93个视频,分辨率较低,拍摄背景和视角固定,且给出了场景中运动前景的轮廓。
(2)真实场景数据集。
真实场景数据集主要由从电影或者视频中采集的数据构建,如Hollywood[10]和UCF Sports[11]数据集。其中,UCF Sports数据集源自于BBC、YouTube等,涵盖场景类型与视角区域较广,拍摄视角多样化,包含10种动作:跳水、打高尔夫、举重、踢腿、跑步、骑马、滑板、行走、平衡木和双杠,共150个视频,包含一系列子数据集,有一定的视角和场景变化。Hollywood数据集采集自32部好莱坞电影,包含8类动作:接电话、下车、握手、拥抱、接吻、坐下、坐着和起立,共计633个视频样本,样本具有一个或多个标签,可分为2部分:采集自12部电影的2个训练集和采集自剩余20部电影的测试集,2个训练集包括1个自动训练集和1个干净训练集。其中,自动训练集利用自动脚本进行行为标注,包含233个视频;干净训练集具有手动验证标签,包含219个视频;测试集也具有手动验证标签,包含211个视频。
(3)多视角数据集。
多视角数据集提供了变化视角下研究行为的旋转不变性的基准数据集,常见的有IXMAS[12]和MuHAVi[13]数据集。其中,IXMAS数据集发布自法国的INRIA(Institute for Research in Computer Science and Automation),是多视角与3D研究的校验基石。该数据集从室内的4个方向和顶部的1个方向进行拍摄,包含13种行为:看表、抱胳膊、抓头、坐下、起立、转身、行走、挥手、拳击、踢腿、指、弯腰捡和扔东西,共计180个视频。MuHAVi数据集最先是由英国工程和物理科学研究委员会EPSRC(Engineering and Physical Sciences Research Council)项目支持,目前由智力科学技术研究委员会CONICYT(COmision Nacional de Investigacion Cientificay Tecnologica)常规项目支持,包含8个视角的18种行为:来回走动、跑步停止、拳击、踢腿、强迫倒、拉重物、捡物扔、行走、摔倒、看车、膝盖爬行、挥手、涂鸦、跳跃、醉走、爬梯、打碎物品和跳过间隙,数据集由7位受试者参与,共计952个视频。
(4)特殊数据集。
特殊数据集指通过特殊技术(如运动传感器、Kinect相机等)捕捉的动作数据而形成的数据集,常见数据集有WARD[14]和UCF Kinect[15]数据集。其中,WARD数据集将无线运动传感器放置在人体腰部、左右手腕和左右脚踝5个位置,构成一个身体传感器系统,记录了20位受试者在自然状态下执行的13种动作:站着、坐着、躺着、前进走、顺时针走、逆时针走、左转、右转、上楼、下楼、跑步、跳跃和推轮椅,每种动作重复执行5次,共计1 298个行为样本。UCF Kinect数据集利用微软Kinect传感器和OpenNI平台估计骨架,采集了16位年龄在20~35岁的受试者的16种行为:平衡、上爬、爬梯、躲闪、单腿跳、跳跃、飞跃、跑步、踢腿、拳击、左右扭、前进走、后退和左右速移,每个动作重复执行5次,每帧包含15个关节点的3D坐标与方向数据,共计1 280个行为样本。
3 行为检测
3.1 基于深度学习的人体行为检测方法研究现状
人体行为检测方法的研究起步于1997年,由美国国防部高级项目研究署DARPA(Defense Advanced Research Projects Agency)赞助的视觉监控项目组VSAM(Video Surveillance and Monitoring)开始了一系列的行为分类研究[16]。波斯顿大学计算机研究室[17]、中央弗洛里达大学的视觉实验室[18]也相继对异常行为检测方法有了研究成果。
相较于国外的研究情况而言,虽然国内相关研究起步较晚,但由于智能监控的普及,一系列的研究工作也相继展开。中国科学院建立了异常行为分类数据集(CASIA);Zhang等人[19]通过高斯混合模型GMM(Gaussian Mixed Model)与K均值(K-Means)聚类算法相结合的方法对目标物体进行行为分类;香港中文大学的Li等人[20]对目标进行建模并提取人体的几何特征,开发了异常行为检测系统。
近年来,随着计算资源的逐渐成熟,基于深度学习的行为分类模型发展迅速,诸多的研究机构与学者在行为分类算法研究中采用了卷积神经网络等深度学习的方法。相关研究进展如表1所示。
3.2 行为检测流程
人体行为检测的过程一般包括:目标检测与目标跟踪、特征提取和行为识别,具体如下所示:
(1)目标检测。
目标检测是行为理解、分析与识别的基础,负责从背景图像中提取感兴趣的运动前景区域,目标检测的准确与否将直接影响后续工作。目前研究较多的目标检测算法有3个:帧差法、背景差法和光流法[43]。
(2)目标跟踪。
目标跟踪研究的是如何快速、准确且稳定地对目标进行定位,常用跟踪方法有4种:基于特征的跟踪、基于区域的跟踪、基于模型的跟踪和基于主动轮廓的跟踪[44]。
(3)特征提取。
特征提取是将目标视频图像中适合的特征数据提取出来后构成特征向量来描述视频图像中人体行为状态的一种技术,常见特征主要有:外形特征、时空特征、运动特征以及两两结合的混合特征[45]。
(4)行为识别。
行为识别本质上可看作是实现对数据的归类问题,这类数据会随着时间发生变化,即比较待测目标行为特征序列与已知的特定行为特征序列的相似性,相似性高者归为一类,相似性低者归为一类[46]。常用行为识别方法有2种:基于模板匹配的识别方法和基于状态空间的识别方法。

Table 1 Research of behavior detection methods based on deep learning表1 基于深度学习的行为检测方法的研究分析
4 基于深度学习的人体行为检测方法
传统特征提取方法一般是经由人工观察,然后手工设计能够表征动作特征的特征提取方法,可分成2部分:基于人体几何或运动信息的特征提取和基于时空兴趣点的特征提取。然而,传统手工特征在处理不同的、复杂的场景中的光照、遮挡等问题时并不具备普遍性,因此使用基于深度学习的方法提取学习特征或许效果更好。基于深度学习的人体行为检测方法通过可训练的特征提取模型以端到端的方式实现对视频图像的自学习行为表征,进而实现行为分类。图1是基于深度学习的人体行为检测方法的流程示意图,常用的基于深度学习的检测方法主要有:基于双流卷积神经网络的检测方法、基于残差网络的检测方法、基于3D卷积神经网络的检测方法和基于循环神经网络的检测方法等。
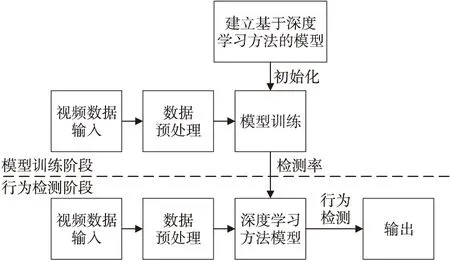
Figure 1 Flow chart of human behavior detection based on deep learning图1 基于深度学习的人体行为检测流程图
4.1 基于双流卷积神经网络的行为检测方法
视频包含时间与空间2部分信息,空间信息中每一帧表示的是场景、人体等表面信息,时间信息则指的是帧与帧之间的运动信息,包括相机与目标物体的运动信息。Ng等人[25]提出了一种基于双流网络结构的人体行为检测方法,其认为网络结构应该由2个深度网络构成,分别负责处理时间维度信息与空间维度信息。因此,双流卷积神经网络结构可分为时间流卷积神经网络与空间流卷积神经网络2部分,且两者具有相同的网络结构。时间流卷积神经网络通过计算视频图像序列相邻2帧的光流图像,可以实现对多帧堆叠的光流图像的时序信息(Temporal Information)的提取;空间流卷积神经网络则是提取RGB图像中的空间特征(Spatial Feature),然后融合2个网络的得分,最后输出分类结果。基于双流卷积神经网络的检测方法可有效提高视频中行为信息的识别率。图2是双流卷积神经网络的结构图。每个网络均由卷积神经网络CNN与Softmax构成,Softmax之后的信息融合在打分时采取了平均和训练SVM 2种方法。
基于双流卷积神经网络的检测方法结合了时空信息,多帧密集光流有助于检测性能的提升,在UCF 101和HMDB-51 2个数据集上具有较好的性能表现。虽然该方法的识别率较高,但需要预先提取视频中的光流图像,并且2个网络是分开训练的,耗时久,无法达到实时性的效果。
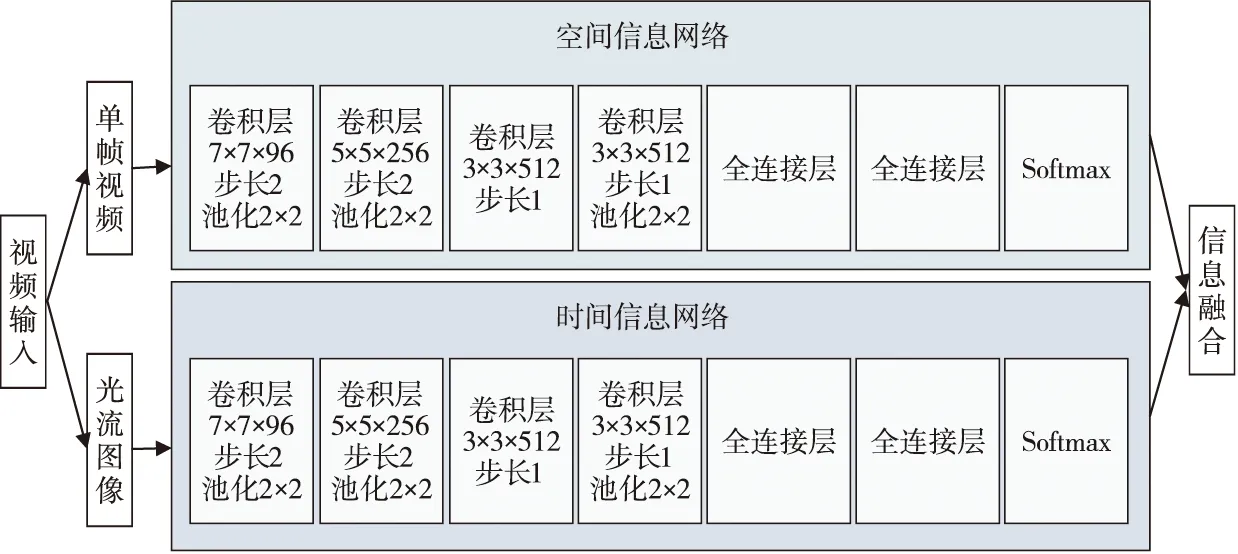
Figure 2 Structure of two-stream CNN图2 双流卷积神经网络结构图
4.2 基于残差网络的行为检测方法
在数理统计学中,残差指实际观察值与拟合值(估计值)间的差,在集成学习中可通过基模型来对残差进行模拟,从而提高模型的准确度,而在深度学习中则有人通过使用层次结构拟合残差来提高深度神经网络的性能。残差网络可实现信号分流至下层,残差块则是构成残差网络的重要元素,将多个残差块首尾相连即可构成残差网络,其基本结构如图3所示。针对深度学习中梯度消失和梯度爆炸的问题,传统的解决方法是初始化、正则化数据,这样虽解决了梯度问题,却加深了网络的深度,影响了网络性能,而利用残差则易于训练深度网络,可以有效解决梯度问题。通过将网络梯度流从后期网络层连接到早期网络层,可提升网络性能,进而增强行为检测的效果。

Figure 3 Basic structure of residual network图3 残差网络基本结构
对一个由几何堆积而成的堆积层结构,假设输入为x,则学习的特征为H(x);若其学习到残差F(x)=H(x)-x,则原始学习特征为F(x)+x。图3表示在残差网络中第2层进行线性变化激活前,F(x)加入了该层输入值x后再激活后输出,该操作称作直连(shortcut)。
此外,Feichtenhofer等人[47]受到残差网络在图像识别领域的应用启发,提出了将残差网络与双流卷积神经网络相结合的行为识别方法,实验表明,利用残差网络的2D卷积神经网络的识别效果很好,但在处理大规模数据集时,3D残差神经网络的性能较2D残差神经网络更佳。
4.3 基于3D卷积神经网络的行为检测方法
卷积神经网络通过利用权值来解决普通神经网络中参数膨胀的问题,在前向计算时用卷积核对输入进行卷积操作,并通过非线性函数将结果作为卷积层的输出,而卷积层之间又有下采样层,用于获取局部特征的不变性,降低特征空间尺度[42]。最后则用一个全连接的神经网络进行行为识别。
当前大多数研究使用基于2D的卷积神经网络学习单帧图像的CNN特征,却忽略了连续帧之间的联系,有丢失关键信息的可能,所以基于3D的卷积神经网络则成为新的选择,利用3D卷积神经网络学习视频行为表征是人体行为检测的一个重要研究方向。图4显示了2D卷积神经网络与3D卷积神经网络的差异。基于3D卷积神经网络的行为识别最先是由Ji等人[48]提出的,在KTH数据集上识别率较高,高达90.2%,其特点是从视频图像数据中提取时间特征与空间特征,捕捉视频流的运动信息,进而实现行为检测。3D卷积神经网络的构成要素是:1个硬连接层、3个卷积层、2个下采样层和1个全连接层。硬连接层产生3个通道信息:灰度、梯度和光流,再在每个通道进行卷积操作及下采样操作,最后将全部的通道信息串联起来实现最后的行为表征。

Figure 4 2D CNN and 3D CNN图4 2D CNN与3D CNN
3D卷积神经网络对连续帧组成的立方体进行特征提取,同时捕捉时间与空间维度的特征信息,一次处理多帧图像,运行速度较快,但计算开销较大,且对硬件的要求也很高。因此,为进一步增强效果,目前研究人员开始考虑结合双流网络的思想,利用光流图像来提升性能。
4.4 基于循环神经网络的行为检测方法
传统神经网络(包括CNN)的输入与输出是相互独立的,在深度学习领域虽然进展不错,但随着研究的深入,传统神经网络对视频、声音等信息进行表征时无法学习到当前信息的逻辑顺序,会忽略整体与部分的关联,丢失一些有价值的信息。故引入循环神经网络RNN。基于循环神经网络的行为检测方法能有效利用相邻视频帧之间的时间相关性对视频数据的人体行为的时序特征建模,但检测效果不太理想,准确率还有待提高。RNN的网络结构如图5所示。Xt∈Rx表示t时刻的输入,x是维度,表示该层的神经元数量;Ht∈Rh表示t时刻隐藏层的输出,假设该层有h个神经元;Ot∈Ro表示t时刻的预测输出,o表示输出数据的维度。时间步t的隐藏变量计算由当前时间步的输入与上一时间步的隐藏变量共同决定。

Figure 5 Structure of RNN 图5 RNN网络结构图
虽然在时域动态特征建模和特征学习2个方面RNN具有很好的效果,但普遍存在梯度消失的问题,为解决该问题,研究人员对普通RNN进行扩展,提出了长短时记忆型RNN模型-LSTM[49],LSTM单元结构如图6所示。
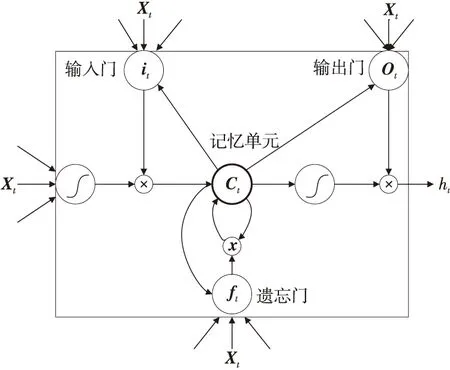
Figure 6 Structure of LSTM unit图6 LSTM单元结构图
Donahue等人[24]将CNN与LSTM相结合,提出了长时递归卷积神经网络LRCN(Long-term Recurrent Convolutional Network)。该网络的输入是单独的图像或视频中的一帧,通过对视频数据进行特征提取,得到一个定长向量,用于表示数据特征,然后将其放到LSTM中学习,最后得到视频数据的行为特征,实现对目标行为的检测,在UCF101数据集上获得了82.92%的平均检测准确率。基于循环神经网络的检测方法能够很好地利用相邻帧之间的时间相关性对视频中人体行为的时序特征进行建模,但识别率有待提高,除了可与CNN结合来提升性能,还可考虑与双流网络相结合。Wu等人[34]提出的双流网络与LSTM相结合的混合学习框架,将时间流与空间流提取的卷积特征作为LSTM网络的输入,以此对长时时序进行建模,在UCF 101数据集上具有较好的检测效果,准确率高达90.1%。
5 发展趋势与研究难点分析
人体行为检测是一个多学科融合的研究领域,涉及诸多的技术环节,应用范围也较广,其发展趋势一方面受到如深度学习方法等相关技术发展的推动,另一方面又面临着不断变化的实际应用需求所引发的如大范围监控环境下的群体行为识别等问题。
5.1 发展趋势分析
(1)行为检测发展趋势。
人体行为检测在各类生活场景中具有非常重要的应用价值,相关技术的应用领域与研究范围也在日益扩展,行为检测方法正逐渐从满足理想与半理想的假设环境向现实环境进行延伸。尽管近年来人体行为检测研究领域取得了极大的进步,但仍需要开展大量的研究工作,其未来的研究方向可以考虑以下2个方面:
①结合语音信息的识别研究。
行为检测在人体行为识别方面的分析不单是理论研究,将进一步贴近社会实际需求,并在感知、网络和算法等方面进行更为广泛的研究。此外,人类交流过程中的语音也十分重要,语音信息内容丰富但易受距离与环境影响。而现阶段人体行为理解研究由于信息的缺乏只能局限于有限的特定姿势识别,一旦姿势视角有了变化,机器便难以理解。虽然目前语音与视频图像分析相对独立,但有效结合语音与视觉方便机器理解进而更好地实现行为的识别将是未来的一个趋势和挑战。
②高层次人体行为理解研究。
目前,单人行为检测虽已取得突破性进展,但人体的非刚性和特征的高位复杂性等问题仍难以克服。此外,人体行为的理解还停留在简单行为与标准姿势的识别分析上,而如何将行为检测算法优化至能够实现对人体行为进行高层次的理解与描述也是当前的研究难点。
(2)数据采集的大数据化趋势。
随着技术的不断进步,诸多的新型人体运动感知设备也不断出现,使得人体运动数据的多源与多样化采集方式有了可能,采集的数据形式不仅包含了从2D空间的RGB图像、3D时空的图像序列到4D时空的RGBD图像序列,还综合考虑了采集时的人体姿势视角、环境光照等采集条件。再加上用作训练的行为数据的质量与规模均对行为检测算法的结果优劣有着重大的影响,尤其是深度学习方法的应用更进一步强化了识别算法对数据的依赖程度,出现了数据的大数据化采集需求。由此不难发现,数据的大数据化采集与数据的自标注将是行为识别领域的研究趋势之一。
(3)模型性能与算法效率并行的趋势。
根据行为检测算法的性能分析可发现,相较于自定义特征表示模型而言,多特征融合和基于学习特征的表示模型的识别效果更好。但是,在搭建复杂性更高的模型进行行为识别时将难以避免算法效率的降低,所以从发展的角度看,二者并行提升将是顺应技术发展的必然趋势,具体可表现为低延时的高性能算法设计和基于融合特征模型的高效率识别算法设计2方面。
5.2 研究难点分析
人工智能技术的发展极大促进了行为检测领域的发展,人体行为检测则是当前异常行为检测的主要发展趋势。近些年,机器学习方法的应用虽然在行为检测中获得了较好的进展,但就整体而言,仍存在不少问题有待解决。
(1)利用视频图像进行行为检测,不仅要考虑背景的复杂性与多样性,还需考虑光照强度、遮挡物等因素,以及图像分辨率等数据质量问题。
(2)人是一个高复杂性的研究目标,行为多样且不一,对于复杂度较高的行为的定义与分类难以明确。此外,人的年龄不同、性别不同、文化程度不同、心理变化不同以及不同的身体实际状态都会对行为产生一定的影响,而这些差异对用于识别的数据库却是十分重要的。
(3)基于深度学习的行为检测方法因GPU与CPU的限制无法实现在模型中对整幅视频图像提取特征,只能利用连续帧之间的信息冗余性提取部分帧代替,或是利用整幅视频图像平均提取特征,无法很好地区分运动信息,可能丢失关键行为信息。
(4)缺乏统一的、大规模的、高质量的行为数据库,现有的数据集中的动作类不一,难以评价不同检测方法的性能优劣。有限的行为类与样本数量是当前的一个局限性所在,而且现有的数据集采集时所用相机的拍摄视角受限度较大,大多视角单一且固定,且拍摄的场景较为理想,难以实现复杂场景下的多个人体目标的群体行为检测。
6 结束语
人体行为检测的研究最初仅是对人体行为信息的简单分析,之后逐步发展到对规则行为与特殊行为的检测,最终提升至现在的从高层次角度理解行为信息。结合当前的研究状况可知,人体行为检测方法的分析与研究目前还停留在理论研究的层面,仍需深入研究感知、网络和算法等,并尽量贴合人类行为的真实需求。从未来的发展趋势来看,对人体行为检测而言,基于深度学习的检测方法无疑是一个很有效的手段。随着技术的不断发展与进步,今后人体行为检测应该向适用范围广、可靠性强、便捷实用、辨识度高和抗干扰性强的方向发展,并融入交通服务、智慧城市建设和智能家居等社会领域,从而在社会公共安全等方面发挥重要作用。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
基层中医药(2021年5期)2021-07-31
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
特别健康(2018年3期)2018-07-04
北京航空航天大学学报(2018年1期)2018-04-20
